前两篇笔记里尝试验证一个问题:既然 AsyncT 把 attention 里的 softmax 换成了更局部、更简单的 gate,那么它在 GPU 推理上是不是应该天然比 softmax attention 更快?但仔细思考可以发现:去掉 softmax 并不会自动让整个推理更快。
Async真正改变的是 attention 内部的依赖结构:softmax attention 每一行都要做全局归一化,而 Async attention 的每个 K-block 输出可以更独立地累加。这个性质只在“被 softmax/reduce 依赖卡住的地方”才会变成 wall-time 收益。profile 显示,有些地方异步的收益兑现了,比如 split-K decode 和 sparse-P;有些地方它没有兑现,比如 dense prefill 的多级 pipeline;还有一些瓶颈根本不在 attention 里,比如新增的 post-attention UClipNorm 上。
1. Asynchronous Attention
我们回顾标准的Softmax Attention:
在分块的情况下,为了防止整个落到HBM内,Flash Attention这样的基于Online Softmax的做法需要给每一段产生一段partial output,但不同tile的output不能直接相加,因此合并partial结果的过程中还需要携带一段row max & row mean构成的统计信息、把不同block的输出rescale到相同的归一化尺度下。
Async Attention的情况则不同:
也就是说,在产生的过程中,不再需要依赖整行的所有结果、不需要等到rescale结束之后才能继续往后做。对 Async Attention 来说,不同 K-block 的 P @ V可以直接相加;对 softmax 来说,不同 K-block 的 partial output 需要 LSE merge / rescale 之后才能合并。这是我们一直讨论的异步性质在Attention中最直接的体现。
1.1. Async Attention Kernels
借助vLLM的metadata + dispatch机制,我们分别优化了prefill kernel和decode kernel,以适应两者极其不同的workload情况。
1.1.1. Prefill
K/V 是从 paged cache 读的:vLLM 为了省显存、支持变长,把每个序列的 K/V
切成固定大小的 block 散在显存里,block_table[请求]记录第几个逻辑 block 落在哪个
物理 block。kernel 要读某个 token 的 K/V,得先查 block_table 找物理地址——这是个间接
寻址。
生产里 prefill 的主力 shape 是 continuous-batching 下 1K–2K context 的请求。对这类 shape,最终用的不是直接在 paged cache 上跑上面的 kernel,而是一条叫 super-page dispatch 的路径:
- 把这个请求散在各 block 的 K/V,先重排进一段连续的 buffer(super-page);
- 如果是纯 prefill(prefix 为 0,K/V 是这一步刚算出来的),重排的同一趟里顺手把 paged KV cache 也写了(fused write)——这样 K/V 只从显存读 / 写一遍;
- 然后在这段连续 buffer 上做attention。
早期 prefill 的一大笔开销是:K/V 算出来 → 写进 paged cache → kernel 又从 paged cache 通过 block_table 把同样的 token 读回来,等于一来一回多读一遍 HBM。上面这个方案把”写 cache”和”喂 kernel”合并成一趟连续访存,砍掉了这次重复读。对 1K–2K这种有界 shape,重排的成本能被摊掉;对超长或超短的 prefill,重排摊不动(要么计算时间太短开销占比太大,要么需要重排位置的kv cache内容太多开销增加),所以针对不同的workload length做调度:1K–2K 走 super-page dispatch,其余的直接在 paged cache 上跑 WGMMA kernel(一个更接近FA3版本的Kernel)。
1.1.2. Decode
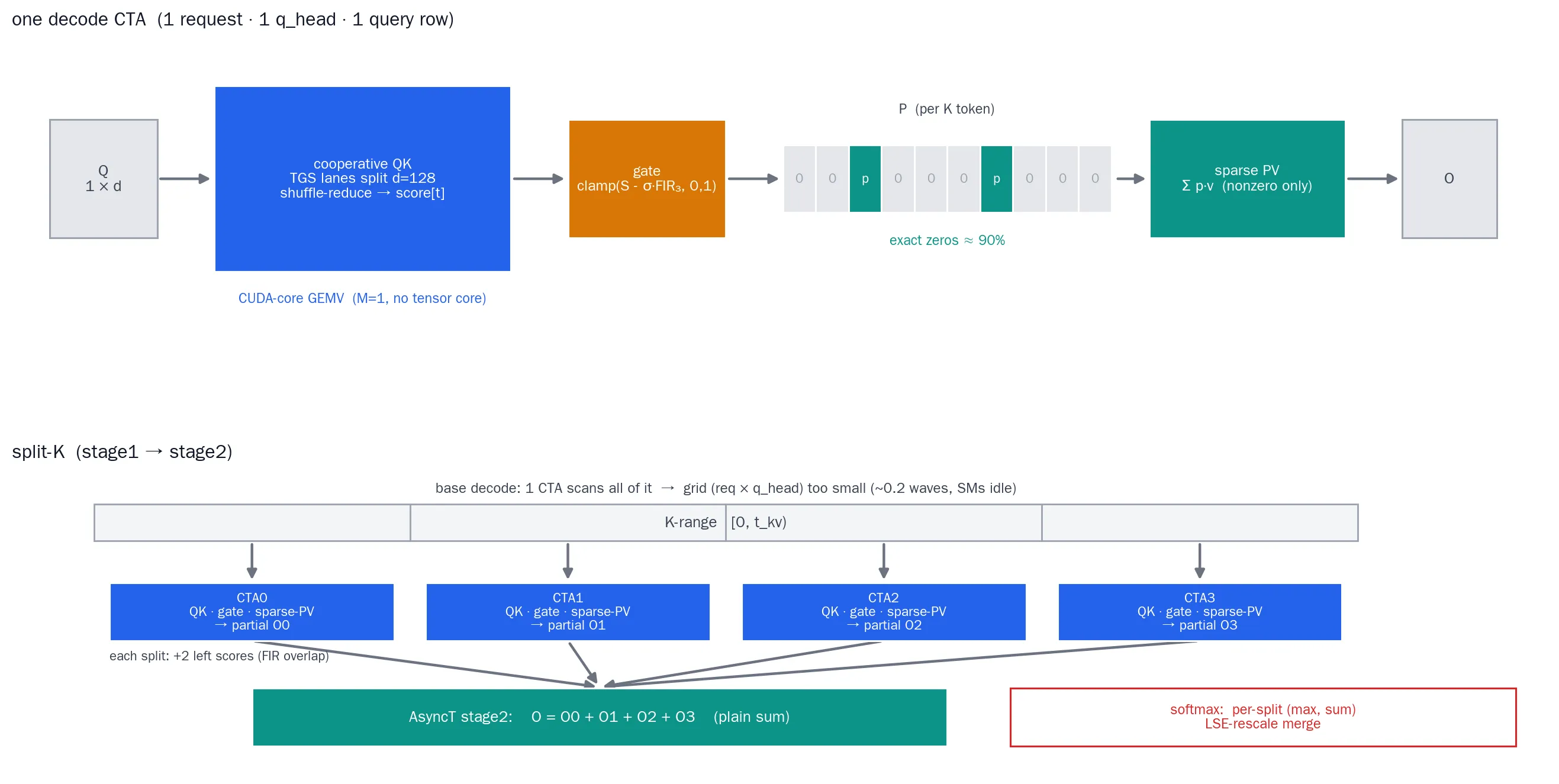
decode 一个请求一次只算 1 个 query token,难以利用tensor core。Decode Kernel的结构是:每个 (请求, q_head)一个 CTA,进行:
载入 Q (1 行, head_dim=128) 到 shared
for 每个 K token:
一组线程协作算 Q·K 的点积 # cooperative QK
应用 gate → 得到这一行的 P
PV: 只遍历 P 非零的位置累加 # sparse-P
写回 O- Cooperative QK:
head_dim=128的点积由一个thread group (8 或 16 个线程)分摊,每个线程算一段,再用 warp shuffle 求和。一个 token 一个 token 这样扫 K; - Sparse P:gate 出来的 P 里有大量精确 0。算完gate 后先构造一个 “非零位置下标表”(每个非零位置用
atomicAdd写回),PV 阶段只遍历这些位置,跳过零项的 V 载入和乘加。 这个稀疏可以获得约30%-40%的提速。
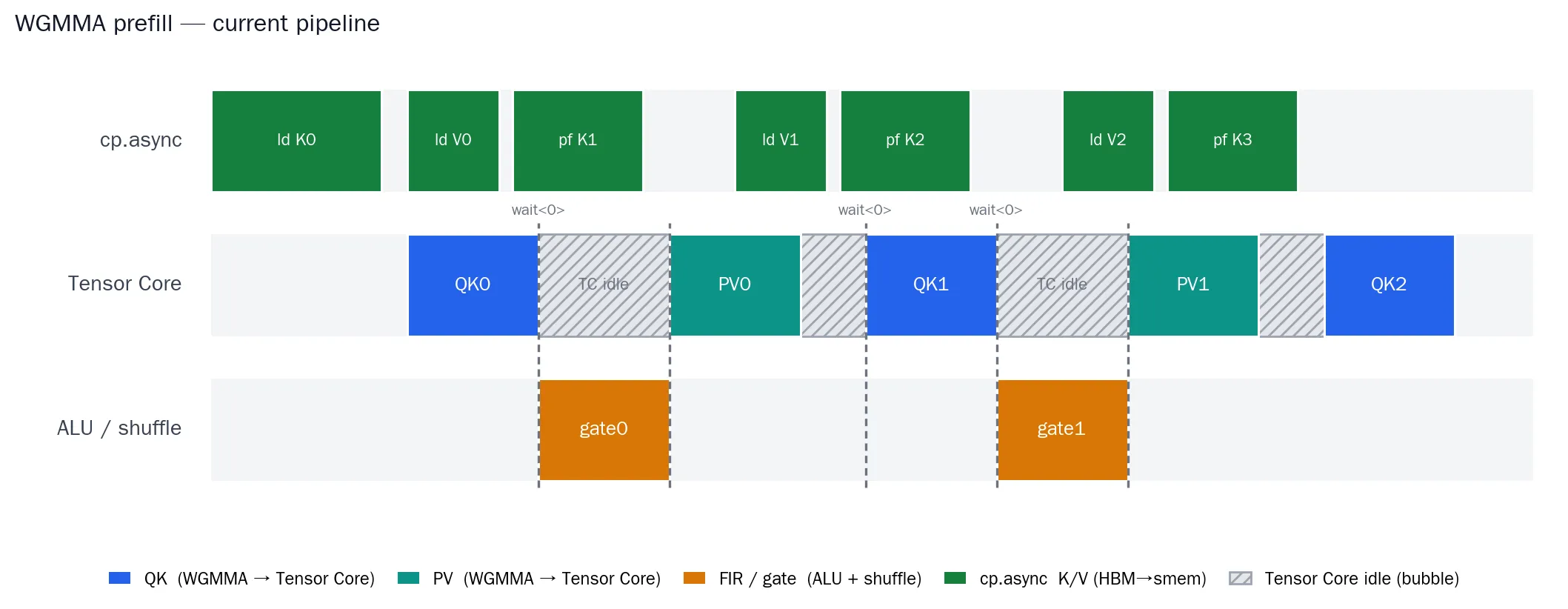
对于一些长context、batch较小的场景,GPU上大部分SM都空闲,而一个CTA却要处理非常多的。此时Kernel是Occupancy/Latency受限,实际上资源/算力还有非常多。为了解决这个问题,我们采用split K的方法:把一个请求的 K-range 切成 S段,stage1的 grid = (q_head, 请求, split),每个 CTA 在自己那段上做QK→Gating→PV的操作、产出一个 partial output(只多读左边界 2 个 score 接上Avgpooling窗口);stage2的 grid = (q_head, 请求),把各段的 partial 加起来。CTA 数量翻 S倍,GPU 喂满了。
在这个场景下,AsyncT的无Synchronization性质再次体现:Softmax Attention的如果想要合并,每个CTA还需要携带自己的max, mean等统计信息,在合并前整体做一次rescale。而AsyncT只需要一次加法即可合并,大幅度节省了实现难度1。
2. Results
在做最后一段优化之后,与Qwen3同Size Config的1.7B模型恰好训练好了,最终得到的结果是:
| Scenario | AsyncT | softmax/FA3 | Delta | AsyncT / FA3 |
|---|---|---|---|---|
long_prefill_b4 | 0.0615 s | 0.0621 s | −0.58 ms | 0.991× |
prefill_heavy_b16 | 0.1288 s | 0.1253 s | +4.77 ms | 1.038× |
decode_heavy_b32 | 0.6375 s | 0.6484 s | −10.86 ms | 0.983× |
long_decode_b32 | 1.0168 s | 1.0042 s | +12.57 ms | 1.013× |
可以看到,我们在所有的Benchmark上,全部做到了与FA3差距小于5%的水平,基本可以说我们的模型现在在vLLM上拥有了与Flash Attention3匹敌的吞吐。
看差距最大的prefill_heavy_b16上的breakdown:
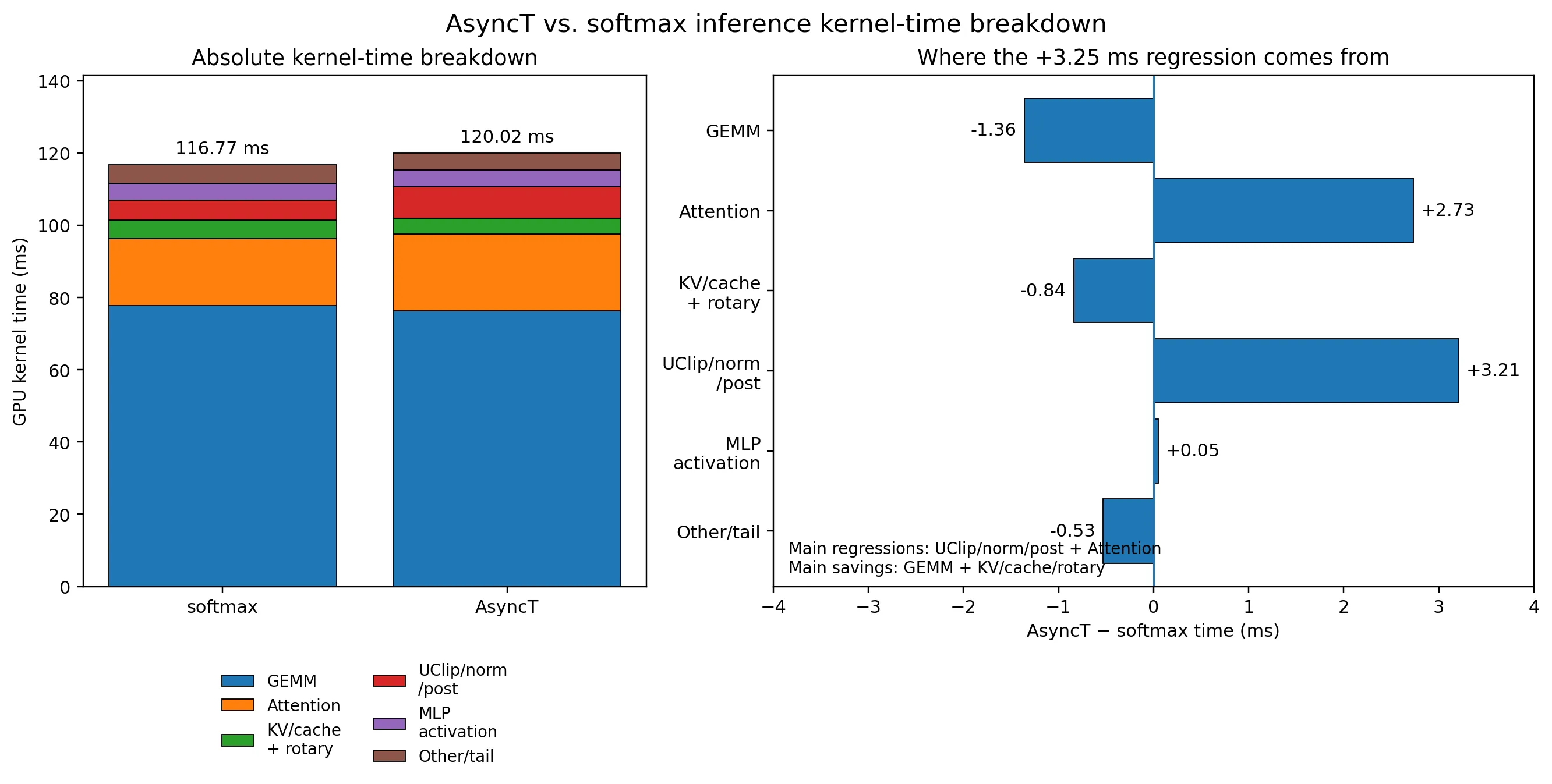
可以看到差距主要在Attention & Normalization上,甚至normalization拖累的还更严重。进一步检查,发现Normalization主要多在AsyncT结构内在Attention之后新加的Peri-LN Style UClip上。在之前的改进中,此Kernel已经和Residual Addition融合到了一起。用ncu详细profile,发现此kernel运行中DRAM Utilization 75%,属于非常明显的Memory Bandwidth Bound。
| Kernel | Time | SM | DRAM | DRAM read/write |
|---|---|---|---|---|
uclip_norm | 40.38 us | 58.5% | 58.1% | 67.1 / 48.1 MB |
fused_add_uclip_norm | 66.21 us | 32.8% | 74.7% | 134.2 / 108.5 MB |
hp1_post_attn_pre_mlp_uclip_out | 65.89 us | 49.3% | 75.5% | 134.3 / 110.2 MB |
hp1_qk_uclip_norm_ | 76.45 us | 83.2% | 46.4% | 100.7 / 73.7 MB |
从详细的Kernel Level Profile情况看,单个Prefill kernel grid 是 128 blocks,384 threads/block;SM throughput 只有 20.64%,DRAM throughput 5.39%,L1/TEX throughput 45.84%,168 registers/thread,dynamic smem 164 KB/block,achieved occupancy 13.37%,waves/SM 只有 0.97。
这说明,现在我们的Attention Kernel,并不是 tensor core 已经打满、只差一点 overlap 就能大幅度提升的状态,更像是受限于 L1/instruction/occupancy/resource pressure。此时再去做“并发 PV WGMMA”“更深 pipeline”“像 FA3 那样 ping-pong hide gate”,不一定能省 wall time,因为 tensor pipe 本来就没被喂饱。
这和 FA3 的语境不同。FA3 的 producer/consumer warp specialization 和 ping-pong,是为了隐藏 softmax exp/rescale 等非 tensor core 工作,让 tensor core 更持续地工作。但 AsyncT 的 gate 比 softmax 便宜,没有 MUFU exp,也没有 online LSE rescale;这本来是好事,却也意味着“需要被 hide 的东西”更少。若 kernel 的主要问题已经变成 smem/register/occupancy,那么继续模仿 FA3 的 pipeline 形态,可能只是把复杂度加到错误位置上。
如果还有下一代Kernel,优化工作一定是集中到如何降低整体的寄存器/smem占用、提高occupancy,进一步发挥异步优势,提高SM & Tensor Core的利用率。
3. Discussions
3.1. 并发PV
前面的讨论中我们提到,由于之间不再有复杂的Scaling Factor依赖,理论上我们的计算可以同时发送多条指令在Tensor Core内排队、大幅度提高利用率:
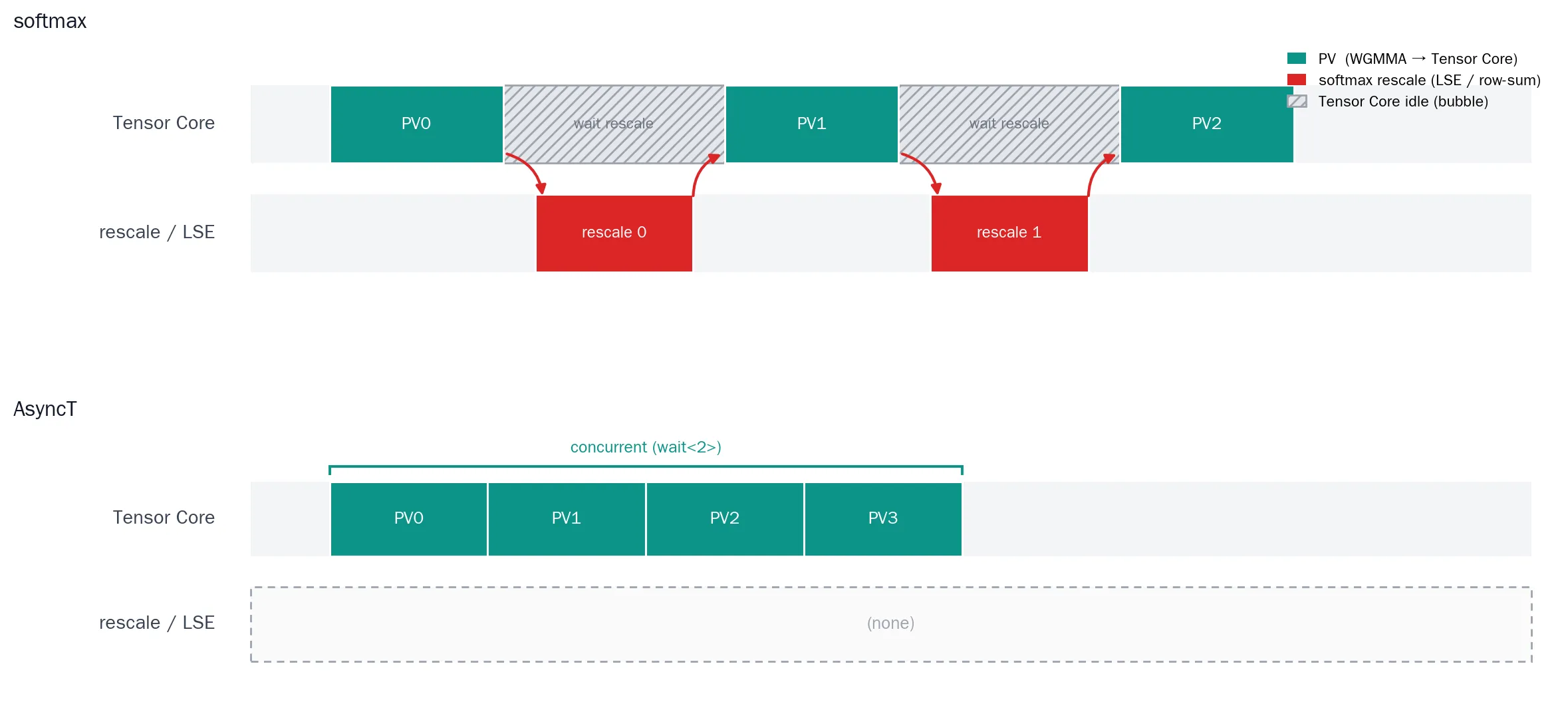
但实际上这样做非常难,因为是一组WGMMA产生的结果寄存器P[64],在当前、保持BF16的情况下,产生的是FP32的,而并发还需要多组驻留在单个CTA中,大幅度超过了当前GPU硬件支持的范围。因此这样做在目前的约定下反而导致了Occupancy进一步降低、速度下降。
但在实验中我们发现,模型对的数值精度似乎并不敏感,我们之后也许能把全部FP8化、大幅度降低寄存器和Shared Memory压力,从而实现更好的并发?
3.2. Ping-Pong Pipeline
在Flash Attention3的论文中他提出了ping pong pipeline的做法,尝试通过两组交替占用Tensor Core进行计算的Consumer来掩盖上面提到的rescale、softmax进行指数运算等一系列操作的开销:
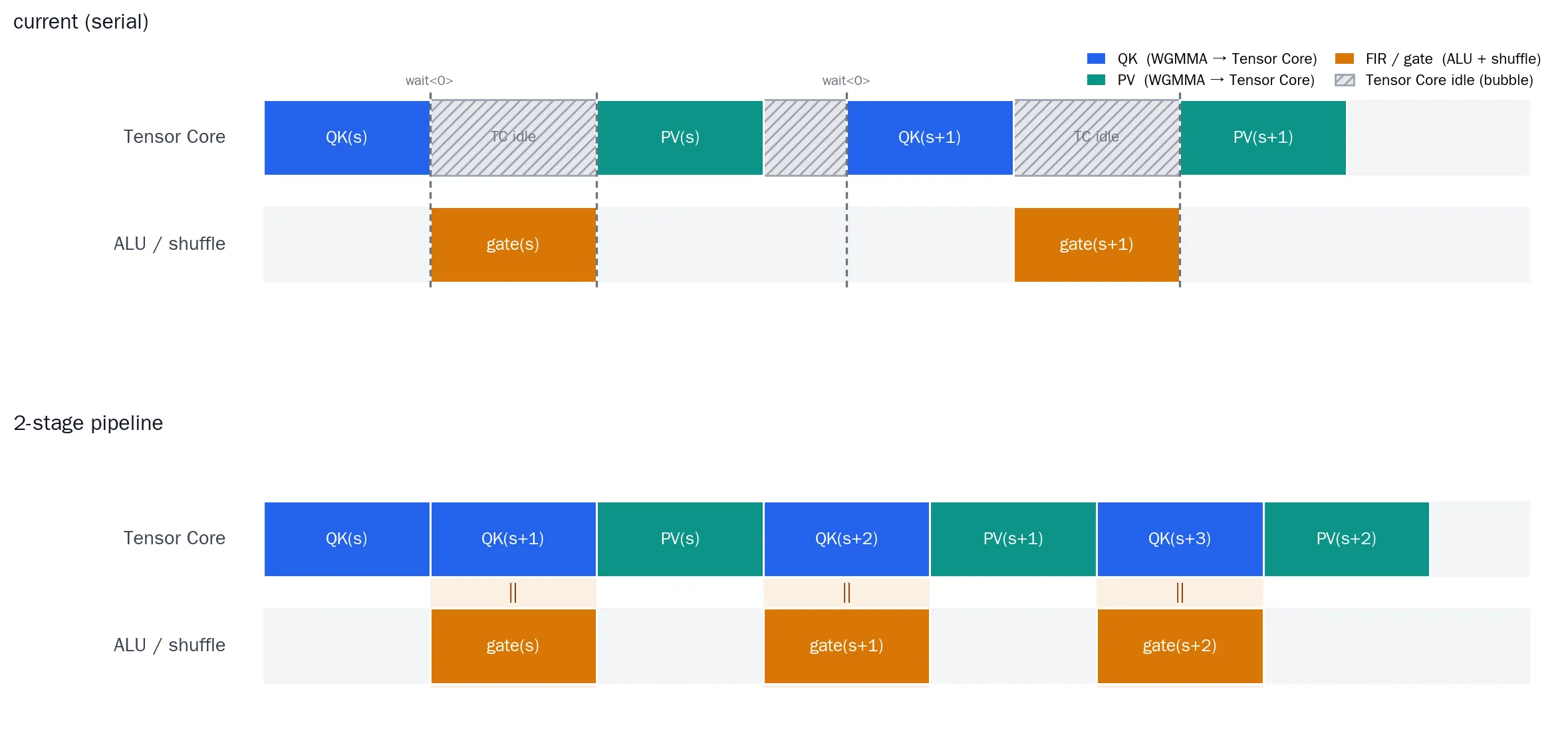
但实际上,要实现Ping Pong Pipeline还需要额外引入一组named barrier、通过更加复杂的调度实现和流水优化才能恰好地掩盖ALU工作的时间。而一些实验结果2也指出,在诸如H200这样的机器上,由于Tensor Core算力大幅度提升,导致实际上ALU等非TC计算的时间其实并不好被掩盖。因此,与其花大时间去做复杂的流水调度,直接用简单的两个Consumer各算各的的影响不会超过2%。但如果之后我们需要在H20上适配?在其他的GPU上适配?将Gating Hide起来的需求可能就会变大了。
3.3. Sparsity
现在虽然在Decoding中做了深入的Sparsity利用并且取得了比较大的收益,但在prefill上稀疏的利用还相当难做,因为prefill侧的block level稀疏度基本只有1%。
即使在decode侧,稀疏attention中常见的侧的sparsity也缺乏挖掘。对的稀疏优化难点有三:
- gate 看 AvgPooling 窗口,要判一段会不会全零得先有它的 score,也就是得先算 QK、得先 读 K;要”先跳过”必须有一个不算 QK 的保守 predictor,既不能误跳非零块、又要够 tight;
- 块全零会造成严重负载不均,得配一个 work-stealing 的 scheduler 来重分配;
- 跳过引入的误差不能大到影响正确性。
3.4. post-attn norm epilogue化
现在结构里,Attention output通过一个linear proj,然后输入到post-attn norm + residual中,按理来说可以通过Hopper的epilogue做法把这个简单的算子融合到前面的GEMM后处理过程中。然而,简单地设计一个算子等待nvcc/triton自行融合, 会破坏前一个算子的nvjet,导致SM利用率从85%骤降到55%。正确的做法应该是自己管理这个GEMM,理论上说可以获得比较大的norm加速。但这样做工程实现上需要的时间不少,暂时留到后面再看吧。
3.5. FP8化
在实验中我们发现,由于模型中处处充满着Clamp,使得这个模型的数值范围极其受限、量化特别友好?起码不需要dynamic amax pass。
不过Hopper上FP8 * FP8的WGMMA输出的结果一定是FP32的,这个寄存器开销剩不下来,主要是Gating链条上的寄存器和FMA吞吐能再提一点,估计没有质的飞跃?在Blackwell上说不定有机会,AsyncT没有exp也不用处理FA4那个近似的问题,P量化也能做的更激进一点,效果应该会好一点。
3.6. 其他有可能有希望的方向
- Long Context,长到需要在推理时做Context Parallel的模型在推理时有:
- 稀疏度优势,长上下文的稀疏现象更明显;
- 在单卡 kernel 里,softmax 的 normalization 未必是主瓶颈;但是一旦 context 被切到多个 GPU / 多个节点上,softmax 的跨分片协议就变麻烦了。多机做Context Parallel的时候不需要做rescale,sync-free真正出现在开销很大的coordination场景下;
- KV Cache存在分层/驱逐这种的场景,如投机解码,之前的投机解码工作拒绝之后涉及到复杂的重算,但AsyncT前面算出来的结果还能继续保留(因为是加性的),更像MEDUSA这种比较简洁的投机解码工作;
Footnotes
-
当然FlashDecoding等Decode加速算子也会是这样做的,只是在AsyncT上做起来简单很多。实际上这个kernel是直接fork了
paged_attention_v2的代码、删掉它的rescale部分的东西作为参考的 ↩ -
Pingpong Schedule并不是万能钥匙 - Anonymous的文章 - 知乎https://zhuanlan.zhihu.com/p/1935338652726204054 ↩