摘要: 最近,基于标准卷积神经网络模块构建的 ConvNeXt 在各种图像应用中都取得了极具竞争力的性能。本文在经典 UNet 的基础上提出了一种高效模型,用于医学图像分割,能够在较少参数量的情况下获得令人满意的结果。受 ConvNeXt 的启发,我们将该模型命名为 ConvUNeXt,旨在减少参数量的同时,依然保持出色的分割性能。具体而言,我们首先通过使用大卷积核和深度可分离卷积来显著减少参数量;随后,在编码器和解码器中都添加了残差连接,并通过采用卷积方式进行下采样来替代池化操作;在跳跃连接(skip connection)时,我们设计了一种轻量化的注意力机制,过滤低层语义信息中的噪声并抑制不相关特征,从而使网络能够更加关注目标区域。与标准 UNet 相比,我们的模型参数量减少了 20%,同时在不同数据集上的实验结果表明,无论数据量有限还是充足,该模型都展示出优异的分割性能。代码将发布于 https://github.com/1914669687/ConvUNeXt。
1. Intro
就是ConvNext的内容,然后讲了一下医学图像处理里面小目标比较多,结构比较复杂,一般喜欢用UNet,因为它的跳跃连接可以融合不同层次的特征。
文章结构也是仿照UNet的写法,按改变的内容 - 对性能的影响组织,讲怎么把一个UNet一步步改成ConvNext形态。
2. Related Work
2.1. Enhanced Feature Fusion
UNet 通过跳跃连接在上采样过程中融合低层与高层语义信息,但直接连接低层语义信息可能不是最佳方式。因此,许多方法被提出以增强特征融合。例如,Attention UNet通过在 UNet 中加入注意力模块,在编码器的输出与解码器的对应分辨率特征进行连接前对特征进行调整。该模块生成门控信号,用于控制不同空间位置上特征的重要性,抑制输入图像中不相关的区域,同时突出特定局部区域的相关特征。
2.2. Add residual structure
ResNet 的网络结构已成为最成功的深度学习模型之一,其残差结构被广泛应用于后续方法中。为了解决医学图像分割问题,Xiao 等人将残差结构引入 UNet,并提出了一种加权注意力机制。通过采用该机制,模型不仅能够聚焦于目标感兴趣区域,还能有效剔除不相关的背景噪声。
2.3. Improved skip connection
UNet++ :UNet 的直接连接过于粗糙,可能导致连接的两个卷积层输入之间存在较大的语义差异,同时增加网络学习的难度。为了缓解语义差异,UNet++ 在 UNet 的直接连接基础上增加了一种类似密集结构的卷积层。同时,将同一密集块的前一卷积层输出与下一级密集块的上采样操作融合。这种设计使编码特征的语义层次更接近解码器中的特征图语义水平。密集跳跃连接的优点在于确保所有前层特征图均通过密集卷积块的跳跃路径累积到当前节点。 UNet3+ :低层特征图可以捕获丰富的空间信息并突出目标边界,高层语义特征图则反映目标的位置信息。然而,这些细节信号在下采样和上采样过程中可能逐渐丢失。为了解决该问题,UNet3+ 设计了全尺度跳跃连接,将不同尺度特征图的高层与低层语义直接结合,旨在捕获多尺度的细粒度细节和粗粒度语义信息。
2.4. Combined with traditional methods
2.5. Other variants
UNeXt :UNeXt 遵循 UNet 的设计理念,分为两个阶段:(1)卷积阶段;(2)Tokenized MLP 阶段。输入图像首先通过三个标准卷积块,然后通过两个 Tokenized MLP 层。编码器和解码器对称,Tokenized MLP 是对标准 MLP 的改进,借鉴了 Swin Transformer。具体步骤包括:首先移动特定通道的轴;然后通过全连接层映射到高维空间;再执行深度可分离卷积;最后通过全连接层将高维空间映射回原始空间并恢复通道。UNeXt 大幅减少了参数量和计算量,因此可以在 CPU 上高速运行。然而,过于轻量化的设计通常会导致特征表示能力不足,从而影响模型的精度。 Double UNet :Double UNet 是两种 UNet 架构的集成。输入图像被输入到修改后的第一个 UNet 中生成预测掩码,该掩码逐元素与输入图像相乘,作为后续第二个 UNet 的输入。第二个 UNet 的解码器在解码时结合了第一个 UNet 每个阶段的编码器输出,最终将两个 UNet 的输出拼接为最终结果。双重编码与解码可以更好地融合高层和低层语义信息,从而实现更高的精度。然而,双 UNet 堆叠结构会导致参数量和计算量增加两倍以上。
3. Method
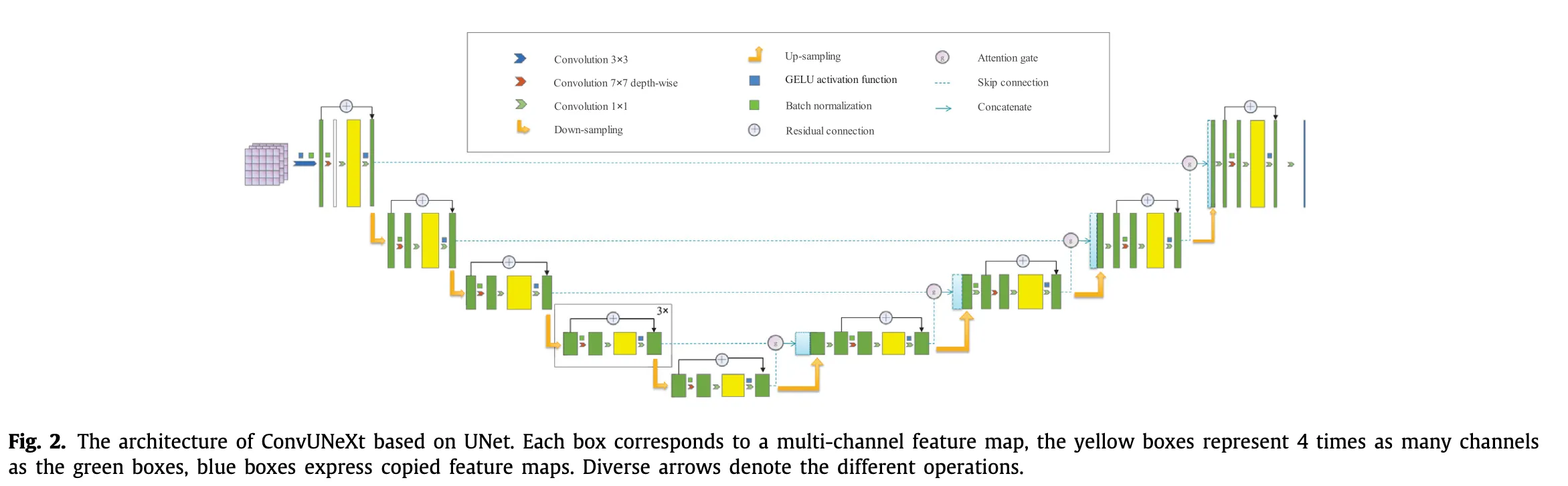
3.1. Changing convolution blocks
换7*7卷积核,加depth-wise separable convolution,“倒置瓶颈”,换GELU,这些都是和ConvNext一样的操作。这篇文章在把batchnorm换成layernorm之后发现效果不好。如果真的效果不好的话对SNN实现来讲是好事。
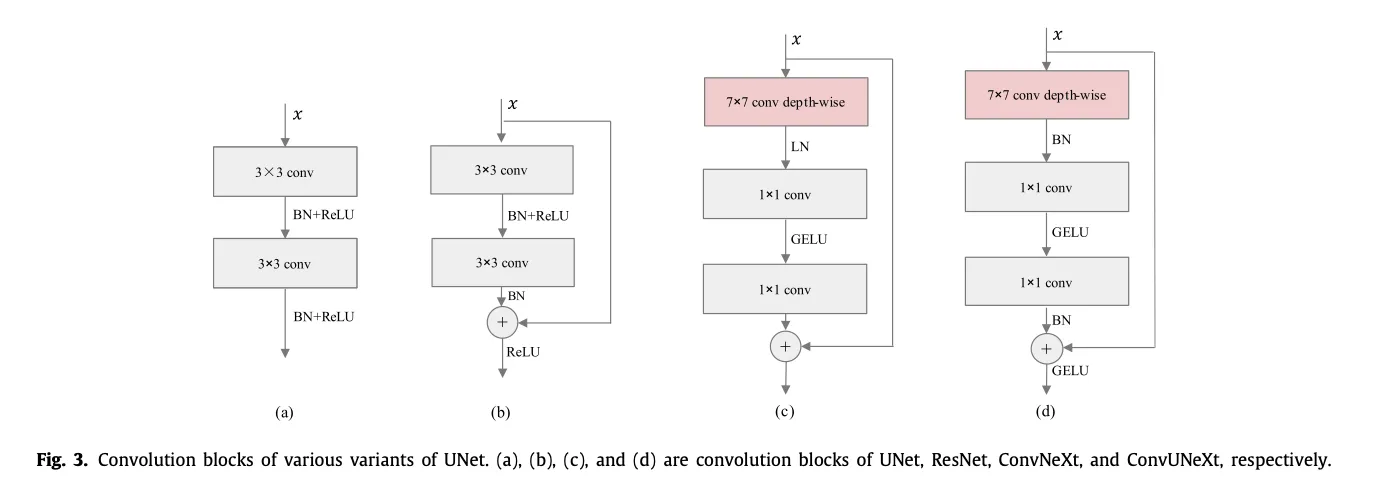
ResNet是先相加然后过activation,ConvNext是直接相加不过activation,文章认为在医学影像任务上resnet这种模式更好。
3.2. Abandoned pooling and applied convolutoin for down-sampling
尽管池化可以有效减少特征图大小、参数量和计算量,但通常会导致 CNN 的某些细节丢失。通过实验验证,采用核大小为 2、步幅为 2 的卷积来减少特征图大小会略微增加计算量和参数数量,但效果更佳。此外,我们也遵循 ConvNeXt 的设计逻辑,在空间分辨率变化前添加归一化层以稳定训练过程。
3.3. Skip Connection
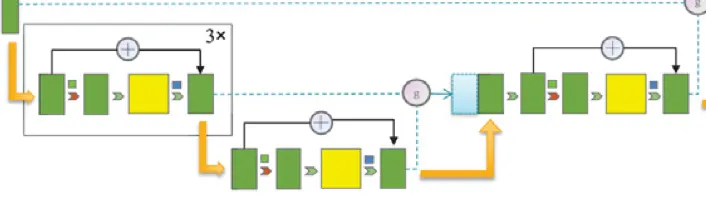
结构图里面的一些细节,可以看到UNet的Decoder环节同时接受低一层的Feature和同一层的Feature,然后过一个轻量化的Attention Gate。这个模块模仿LSTM设计:
在 Attention Gate 中,高层语义信息 在上采样后通过线性层生成三个独立通道:
然后将其均分为 :
接着,和低层语义信息 相加后通过线性层得到,并通过激活函数活,再与按元素相乘,得到:
类似地,和按元素相乘后,分别通过 sigmoid 和 tanh 激活函数,得到:
最后,和相加后通过线性层生成,并与拼接:
这种方法可以过滤低层语义信息中的噪声并抑制无关背景特征,从而使网络更加专注于目标区域。
3.4. Changing stage compute ratio
换成1:1:3:1。
4. Experimental results
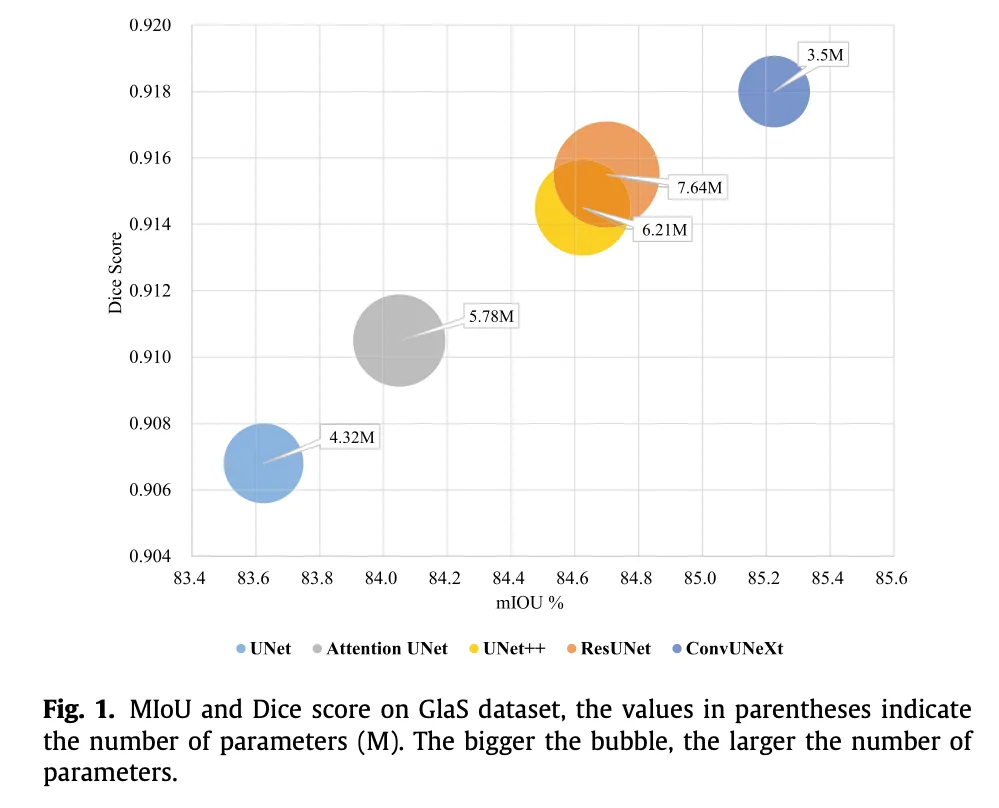
在一些医学数据集上做测试,感觉医学数据集的情况一般都很小,没有那种超大规模的数据集。
5. Conclusion and discussion
在本文中,我们通过改进 UNet 的卷积模块,大幅减少了总参数量。具体而言,我们引入了残差结构,放弃了池化操作并采用卷积进行下采样。同时,我们提出了一种门控机制来增强特征融合,并将阶段计算比从 1:1:1:1 修改为 1:1:3:1。所设计的模型在实现轻量化设计的同时,提升了分割性能。与其他现有的最先进方法相比,实验结果表明,我们的模型在 DRIVE、GlaS、HRF 和食管癌四个公开数据集上的表现高效且优越。该模型采用了大卷积核,但由于 PyTorch 对大卷积核的支持有限,导致显存占用增加。此外,MLP 层也增加了显存的开销。在未来的研究中,我们的模型仍有改进的空间。
发在一个不咋样的期刊上,但是citation特别多。最重要的收获可能是发现有人用LayerNorm效果不好,后面还需要手动做一下实验,看看ConvNext本体如果换掉LayerNorm改用BatchNorm,效果怎么样。
暂时还没想明白UNet这种结构怎么引入Memory Bank。