摘要: 脉冲神经网络(Spiking Neural Networks, SNNs)由于其基于脉冲的激活方式而具有高度效率,天然地产生按位稀疏(bit‑sparse)的计算模式。现有的 SNN 硬件实现利用这种稀疏性来避免对零值的浪费性计算,但这种方法仍未能充分发挥 SNN 的潜在效率。本文提出了一种新的稀疏范式——乘积稀疏性(Product Sparsity,简称 ProSparsity),该范式通过挖掘矩阵乘法运算中的组合相似性来重用内积结果,从而减少冗余计算。与传统按位稀疏(bit sparsity)方法相比,ProSparsity 在保持原始计算结果完全一致的前提下显著增强了 SNN 的稀疏性。例如,在 SpikeBERT SNN 模型中,ProSparsity 将密度降低到 1.23 %,计算量减少 11 ×;而传统按位稀疏的密度仍为 13.19 %。为高效实现 ProSparsity,我们提出了硬件架构 Prosperity,能够实时识别并消除冗余计算。与此前的 SNN 加速器 PTB 及 NVIDIA A100 GPU 相比,Prosperity 分别取得了 7.4 × 与 1.8 × 的平均速度提升,以及 8.0 × 与 193 × 的能效提升。Prosperity 的代码已开源于 https://github.com/dubcyfor3/Prosperity。
1. Intro
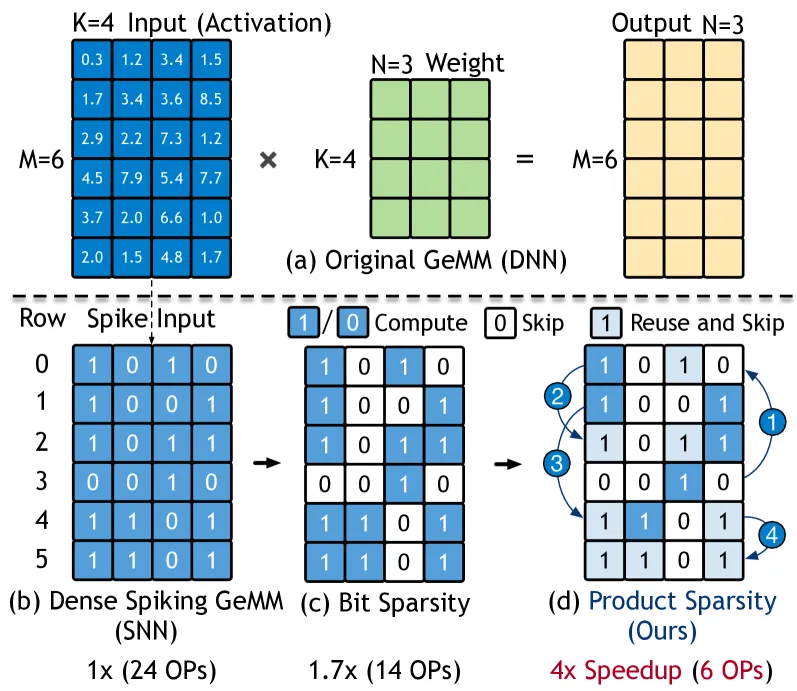
核心在于矩阵乘法内积的组合相似性 :SNN 的多个脉冲矩阵行往往包含相同的二值子组合,乘以相同权重矩阵时得到相同内积。只需计算一次并在包含此子组合的行间复用,即可消除重复计算。
Challenge:
- 直接搜索合适的复用方案耗时特别高
- 计算的先后关系对复用效率有影响
- Spike Activation是动态的
Contribution:
- 提出乘积稀疏,利用 SNN 激活中的组合相似性,显著提升稀疏度并减少计算。
- 针对高复杂度与依赖问题,提出 Prosperity 架构,在线性复杂度 内高效识别与利用乘积稀疏。
- 设计高效流水调度,将稀疏处理与矩阵运算重叠,实现零开销稀疏计算。
- Prosperity 能加速多种 SNN,在速度和能效上均大幅领先基线。
2. Background
- SNN
- Spiking CNNs and Spiking Transformers, 主要是讲核心计算都可以转换为GEMM,而ASIC难以支持不同Spiking Transformer中各自不同的注意力机制
- SNN Accelerators,
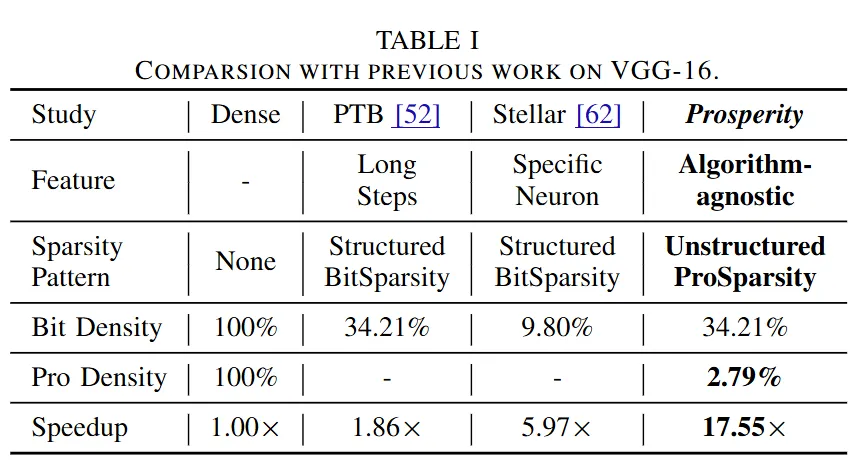
3. Product Sparsity
3.1. Definition
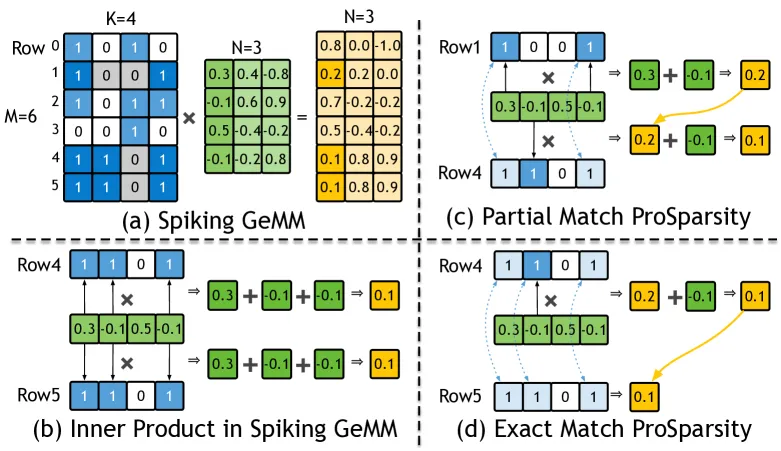
图 2(a) 展示了一个脉冲 GeMM:给定 的脉冲矩阵、 的权重矩阵及 的输出矩阵,其计算可分解为多次基于比特稀疏的内积(图 2(b))。由于输入为二值,内积可视为对多条权重值的累加;这些权重由脉冲矩阵当前行中值为 1 的位置“选中”。根据矩阵乘法规则,脉冲矩阵第 列始终“选中”权重矩阵的第 行。若两行脉冲矩阵在若干列上同为 1,则形成一个公共二值子组合;当它们与同一权重矩阵相乘时,该子组合产生相同的内积结果。例如图 2(b):第 4 行与第 5 行完全相同(1101),因此可复用同一结果。若仅对一次公共子组合计内积,再将结果复用于包含该子组合的所有行,便可显著减少冗余计算。我们将这种借助内积组合相似性 来跳过计算、复用结果的范式称为乘积稀疏(ProSparsity) 。
这种复用式的稀疏提升依赖于计算中的时空关系:
- 空间关系 - 如何高效识别安排行间相似性
- 时间关系 - 如何安排处理顺序最大化复用
3.2. Spatial Relationship
考虑总共行,需要找到一个行的sub-combination,朴素的直接对比方法是的(假设,找到这种sub-combination的计算也需要次。将一行spike写作一个集合:
注意到的时候复杂度是不可接受的,因此这篇文章只讨论的情况,且也已经足够满足SNN加速的稀疏度了。
当的时候,有:
- ,则可以直接复用的计算结果之后额外剩余的数值(PM)
- ,直接复用(EM)
- ,没有包含关系的复用难度太高,本文不考虑。
3.3. Temporal Relationship
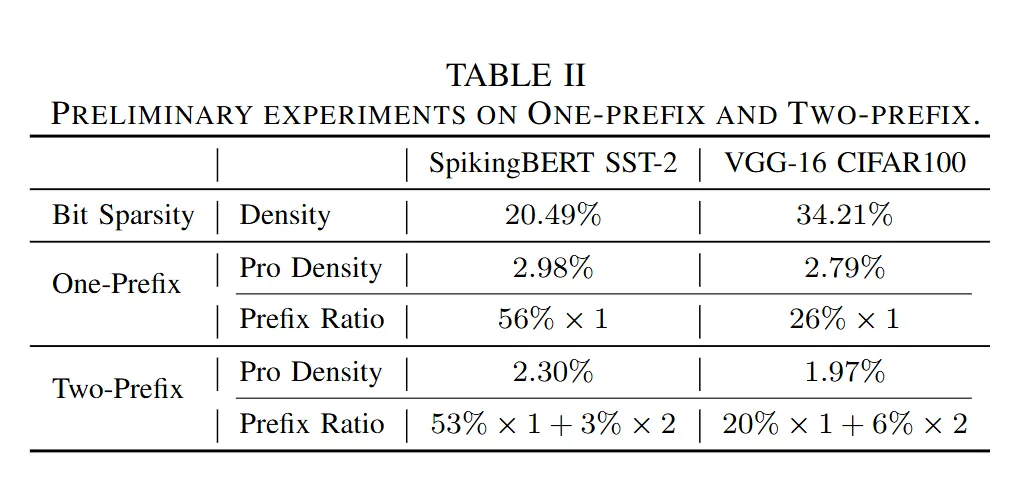
用Prefix和Suffix描述Spike串。
- EM:行索引较小者为 Prefix 。
- PM:元素更少(真子集者)为 Prefix,被复用者为 Suffix 。
3.4. Efficient Design Space Exploration
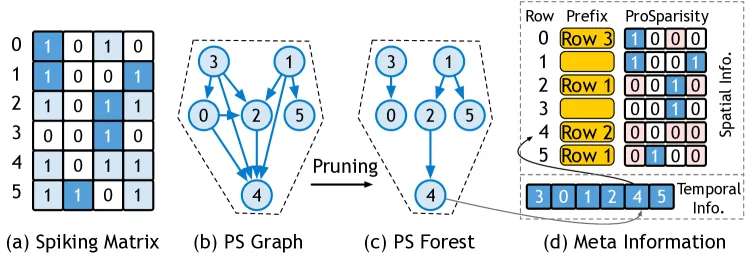
将脉冲矩阵的空间‑时间关系建模为有向图(b)的做法开销太大在硬件上不好做,所以退化成单前缀的做法。
4. Prosperity Overview
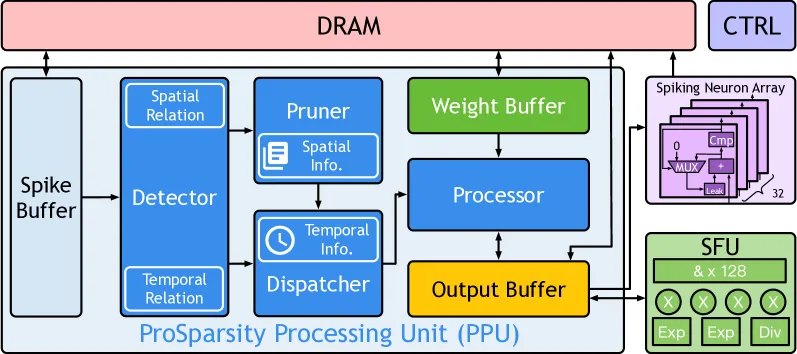
Prosperity 逐层推理 SNN,由 ProSparsity 处理单元(PPU)、脉冲神经元阵列与 特殊功能单元(SFU) 组成。PPU 负责关系检测、修剪、元信息生成与 ProSparsity 计算四阶段;结果进入神经元阵列产生下一层脉冲。SFU 用于 softmax、层归一化中的指数与乘法,使架构兼容各类脉冲 Transformer
5. ProSparsity Processing Unit
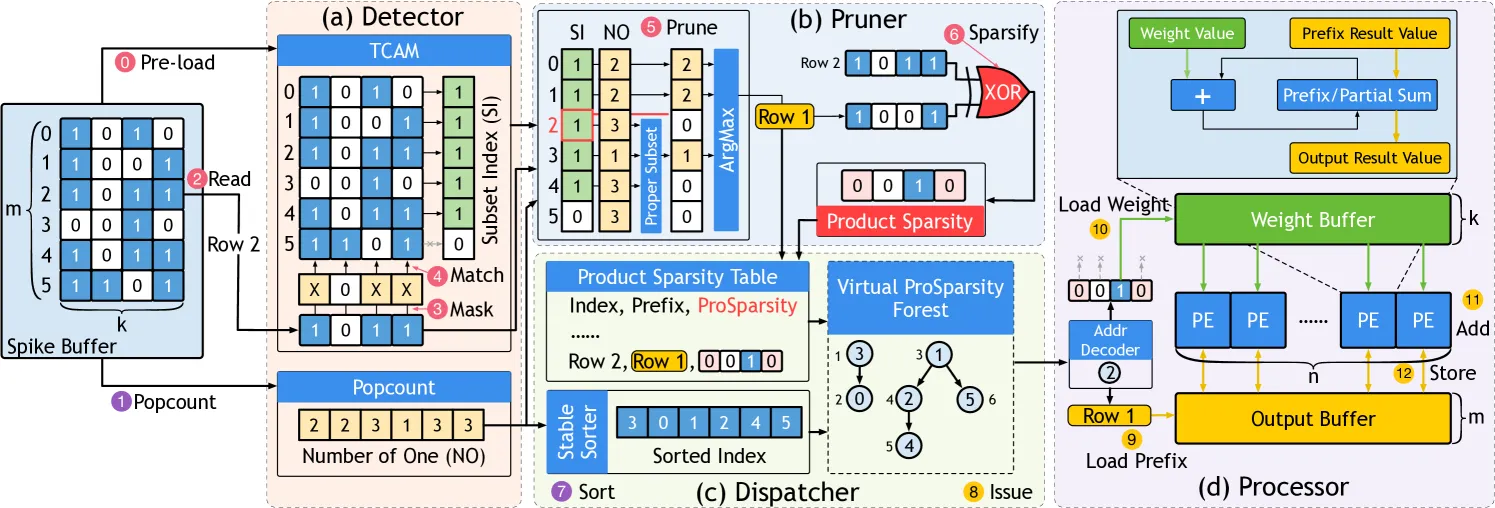
5.1. Spiking GeMM Tiling
分成的分块,注意到非常小的下前面的复用方法失效,非常大的会导致buffer开销太大,而
5.2. ProSparsity Detector
利用三态 TCAM 并行匹配子集:
-
将 mmm 行脉冲子矩阵加载至 mmm 条 TCAM 表项。
-
读取待查询行(如 Row 2),把其“1”位掩为 “X”。
-
TCAM 单周期返回所有子集行索引(Subset Index, SI)。
总复杂度
时间信息先用popcount做初步统计。
5.3. ProSparsity Pruner
没有仔细看,大概意思是通过XOR判断是PM还是EM然后根据ArgMax和TCAM中维护的数据取计算结果。
5.4. ProSparsity Dispatcher
收集空间信息写入 Pro 表 ,并通过稳定排序 生成执行序:
- 规则① PM:前缀 NO 更小
- 规则② EM:NO 相同则索引更小为前缀
采用并行 Bitonic Sorter ,时间复杂度 ,与 Detector/Pruner 并行运行。生成的“虚拟”Product稀疏树无需存储 Suffix,空间降至。随后按序派发指令与数据至 Processor。
5.5. Product Sparsity Processor
行‑并行数据流
按调度序依次处理脉冲行:
- 先从输出缓冲读取前缀行结果,置于 PE 阵列部分和寄存器。
- 使用 位扫描 找到 Pro 模式中的首个“1”,解码权重行地址,翻转该位;
- PE 阵列累加权重行至部分和;
- 重复步骤 2‑3 直至模式全零,把结果写回输出缓冲。
该设计跳过所有零位,天然支持非结构化稀疏。
6. Pipeline Scheduling
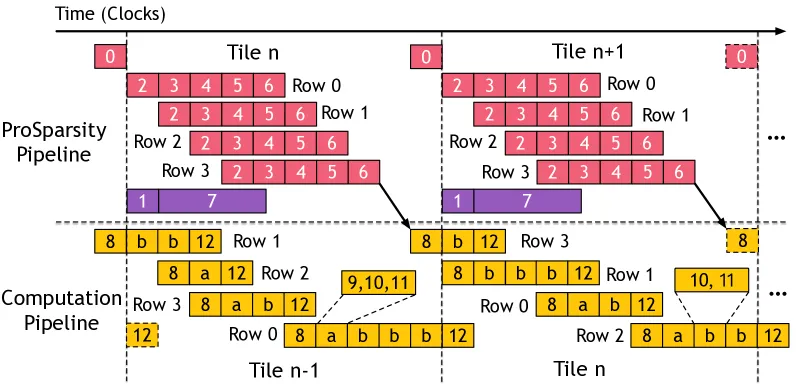
6.1. Intra-phase Pipeline
Detector、Pruner 与 Dispatcher 中的步骤 2–6 完全流水化,构成 5 级流水 ,吞吐率为 1 行/周期 。因此处理 m 行脉冲子矩阵仅需 m + 4 个周期 。
6.2. Inter-phase Pipeline
为重叠两阶段,采用双缓冲 Product Sparsity Table :
- Tile n 的 ProSparsity 处理与 Tile n − 1 的计算并行。
- 由于 ProSparsity 阶段周期始终短于计算阶段,其延迟被完全隐藏;仅第一 tile 有微小影响。
7. Evaluation
7.1. Methodology
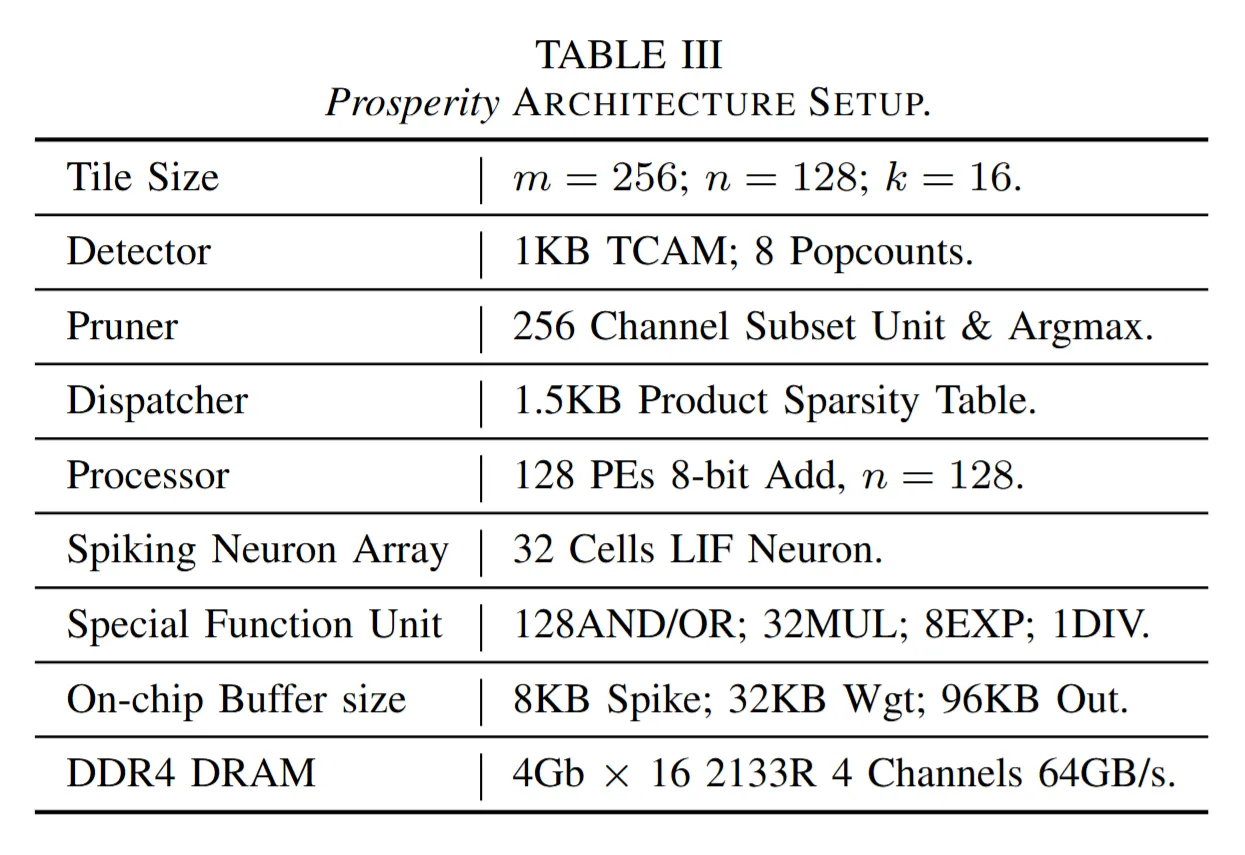
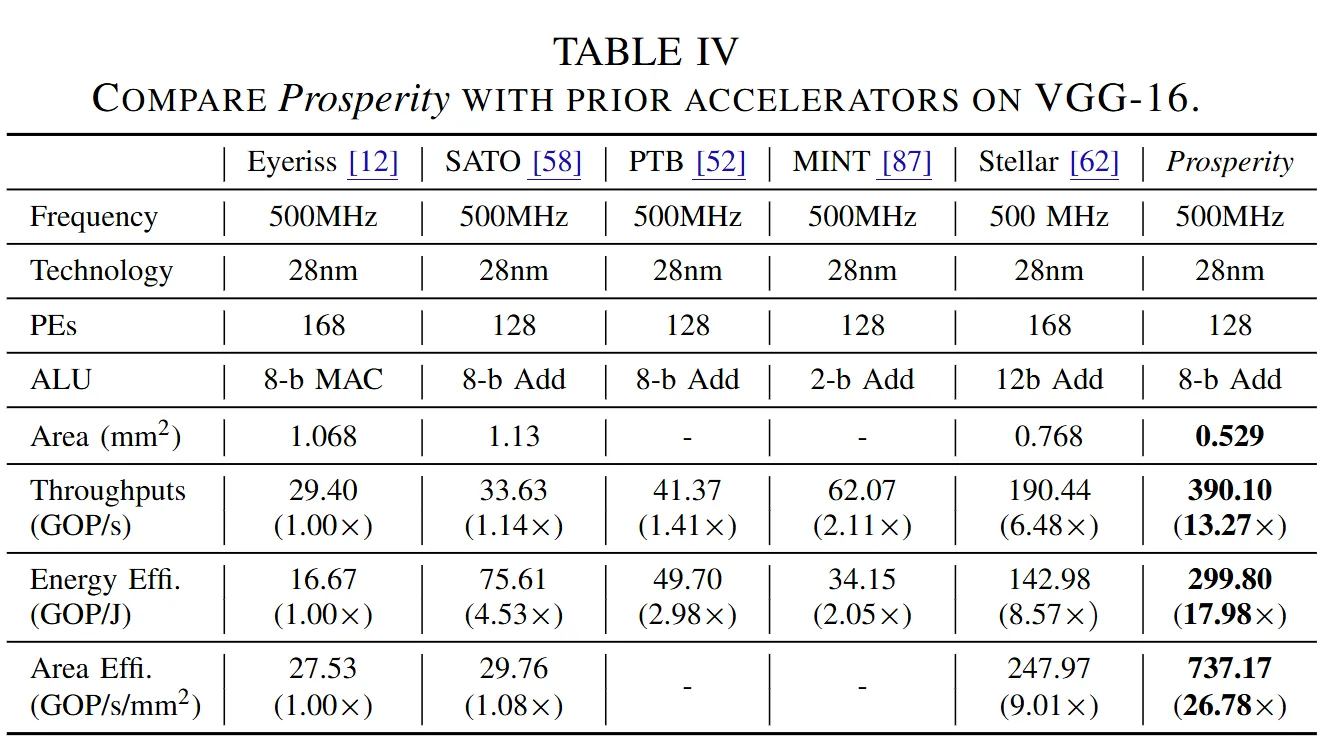
7.2. Tiling Exploration
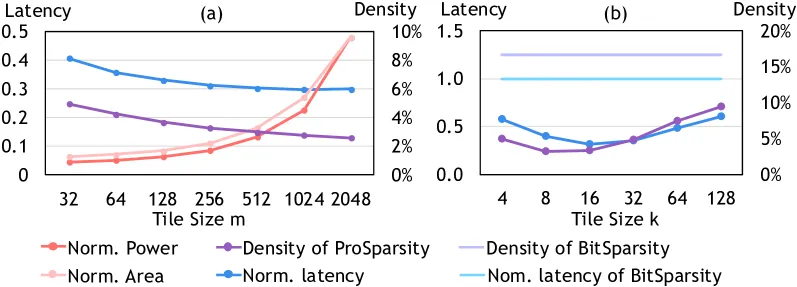
不同 tile 大小对延迟与密度的影响(延迟相对 BitSparsity 基线)。
-
m 维度 :增大 m 提高稀疏度,但缓冲区与 TCAM 面积/功耗超线性增加。
-
k 维度 :过大 k 使行集复杂、难找前缀;过小又导致行脉冲太少。
综合折中,选定
7.3. End-to-End Performance Analysis
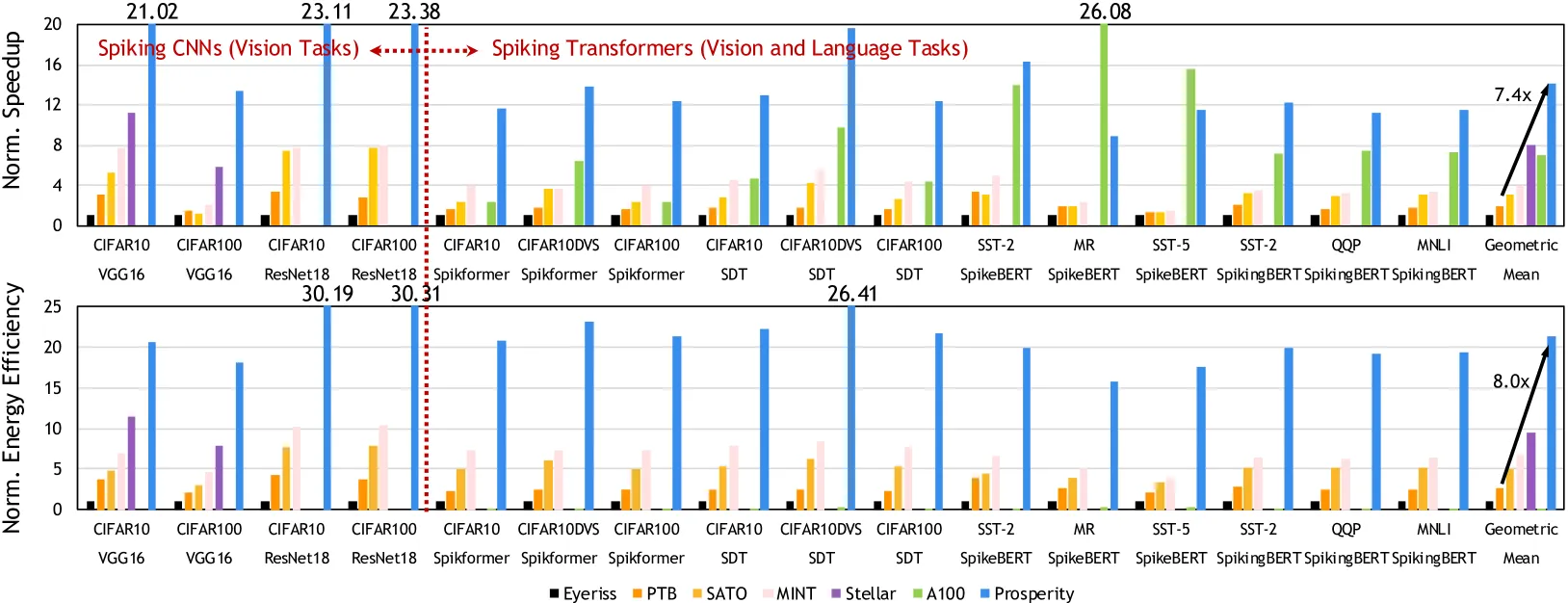
7.4. Ablation Study: Speedup Analysis

7.5. Area and Power Analysis
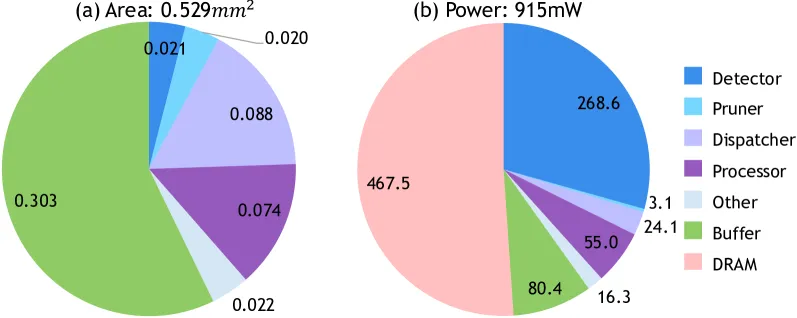
7.6. Sparsity Analysis
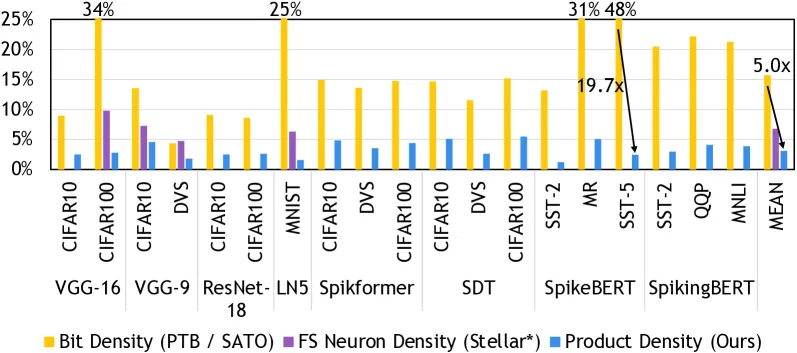
ProSparsity 相对位稀疏平均密度 ↓5 × ,相对 FS 神经元 ↓3.2 × ;无论稠密或稀疏模型均 < 5 %。
7.7. Cost Trade-off Analysis in Prosperity
ProSparsity 处理开销主要来源于 TCAM 位运算 。一次浮点加法≈45 × TCAM 位开销。
- 当增量稀疏度 时,本方法收益 > 成本。
8. Discussion and Related Works
8.1. Architecture Scalability
- PPU 内并行 :同层节点(无依赖)可并发至多个 PE。
- PPU 间并行 :多 PPU 处理不同 tile,实现模型分割并行。
8.2. SNN Accelerators
SpinalFlow, SATO, SATA, MINT, LoAS等是在Bit Sparsity上,而本文的方法与它们正交。
8.3. Efficient DNN
- Quantization and Sparsity
- Redundancy Removal
9. Conclusion
本文提出 ProSparsity ——一种全新的 SNN 稀疏范式,利用脉冲矩阵的组合相似性,在无精度损失 下比传统位稀疏显著减少计算。为实时、高效地利用 ProSparsity,我们设计了 Prosperity 架构:
- 通过启发式降维,空间/时间复杂度均降至 ;
- 管线调度实现 零开销 稀疏处理;
- 对比 PTB 与 A100,平均获得 7.4 × / 1.8 × 速度提升,** 8.0 × / 193 ×** 能效提升。
Prosperity 拓展了 SNN 加速边界,为多样化 AI 应用提供了高效算力支撑。