摘要: 深度卷积神经网络(CNN)在诸如视频姿态估计、视频目标检测等多种视频识别任务上已取得显著进展。然而,由于需要对稠密视频帧逐帧处理,CNN 在视频上的推断计算代价十分高昂。本文提出一种名为 循环残差模块(Recurrent Residual Module,RRM)的框架,用以加速视频识别任务中的 CNN 推断。该框架通过利用两帧之间中间特征图的相似性,大幅减少冗余计算。与既有方法相比,本方法的一大特色是能够对每一帧的特征图进行精确计算。实验表明,在保持几乎相同识别性能的前提下,RRM 对常用 CNN(如 AlexNet、ResNet、深度压缩模型)平均实现了约 2× 的速度提升(若结合高效推断引擎,则较原始稠密模型快 8–12×);对某些二值网络(如 XNOR-Net)更是实现了 9× 的加速(相当于较原模型 500× 的总体提速)。我们进一步在视频姿态估计与视频目标检测任务中验证了 RRM 的有效性。
1. Intro
一个颇具吸引力的递归公式为:,其中是一个只关注差分的浅层快速网络。
2. Related Work
- Network weight pruning
- Network quantization
- Low rank acceleration
- Filter optimization, 感觉和剪枝差不多
- Sparsity
3. Recurrent Residual Module Framework
循环残差模块的核心思想是利用视频中相邻两帧之间的相似性 来加速模型推断。具体而言,我们首先提升每个线性层 (即卷积层与全连接层)的输入稀疏度,然后借助稀疏矩阵-向量乘法加速器 (SPMV)进一步加速前向传播。
3.1. Preliminary
定义对应的投影(projection):
则:
所以可以通过计算缓存 + delta的做法提高稀疏度然后进行加速。
3.2. Recurrent Residual Module for Fast Inference
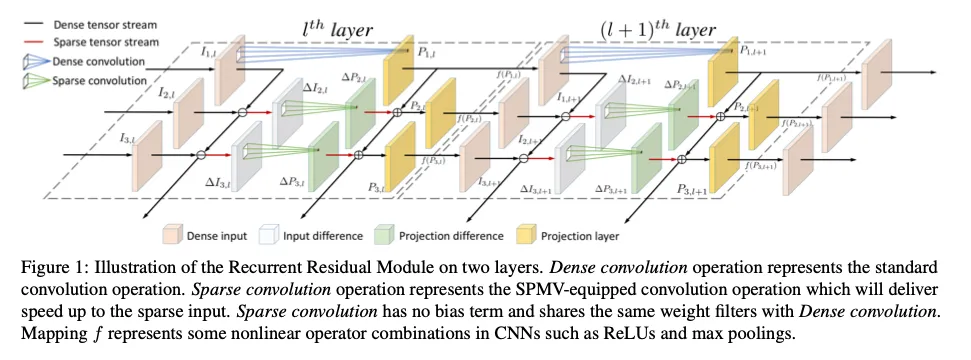
为保存前一帧信息、实现式 (1) 中的快速网络 GG,我们对每个线性层缓存:
- 上一帧输入张量
- 对应投影张量
处理新帧时:
- 取当前层输入 ,与缓存的 相减得 ——高稀疏。
- 对稀疏 采用 SPMV(卷积或 FC)获得增量输出。
- 将增量输出与 相加,得到与常规前向完全一致的完整张量。
- 施加非线性映射 ,推至下一层。
其本质上利用了乘法对加法的分配律,将密集计算转化为稀疏更新 。
RRM 需要上一帧的快照,故整段视频无法完全并行推断。可将视频划分为若干子序列(chunks),对各子序列并行执行 RRM-加速的 CNN 以弥补这一限制。
3.3. Analyzing computational complexity
| 层类型 | 复杂度 |
|---|---|
| 卷积层 | |
| 卷积层 + SPMV | |
| 全连接层 | |
| 全连接层 + SPMV |
带稀疏的计算:
是稀疏度
3.4. Improving Sparsity
做截断有利于加速推理,截断累积值几座:
则误差精度:
用一个四次多项式进行拟合,当误差大于threshold的时候重置一次计算,降低误差的累积。
3.5. Efficient inference engine
Dynamic Sparse Matrix-Vector Multiplication, DSPMV,动态稀疏矩阵向量乘法。
当执行矩阵W和稀疏向量a之间的乘法时,扫描向量a并应用前导非零检测节点(LNZD节点)来递归地寻找下一个非零元素。一旦找到,EIE将及其索引广播到以CSC格式保存权重张量的处理元素(PE)。然后,所有PE中具有相应索引j的权重列将乘以,结果将累加到相应的行累加器中。这些累加器最终输出结果向量b。
4. Experiments
4.1. Results on the Sparsity
稀疏度计算公式:
结果:
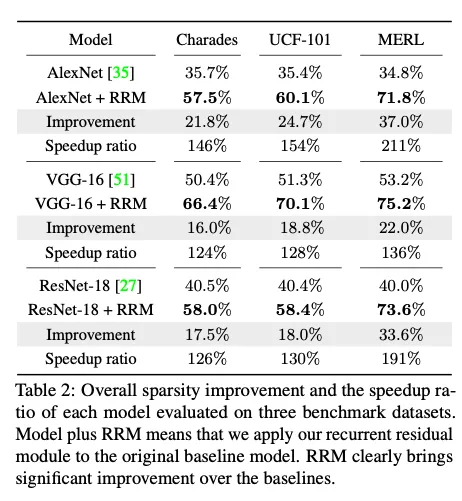
加速比计算公式:
4.2. Trade-off between accuracy and speedup
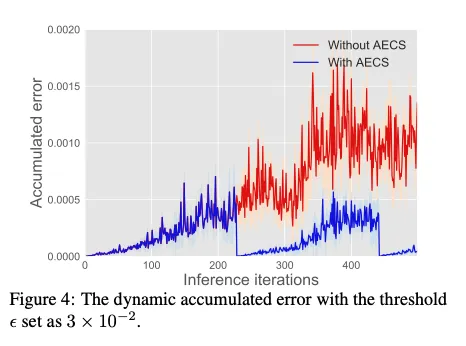
24FPS上的误差累积,主要是想证明提高了稀疏度的同时并且没有很明显的稠密计算,从而取得了加速(见上表)。
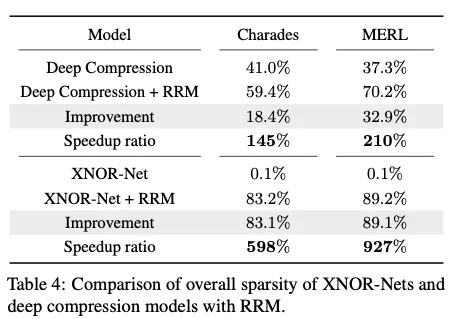
4.3. Speed up deeply compressed models
4.4. Video pose estimation and object detection
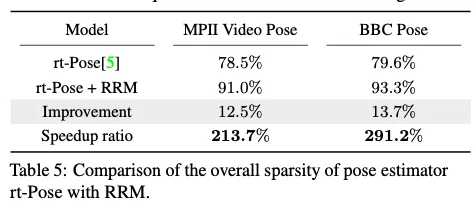

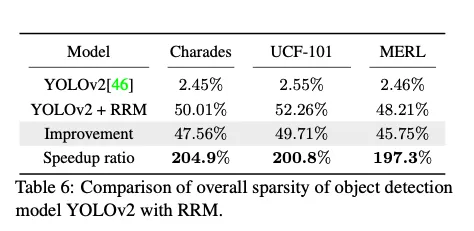

4.5. Discussion
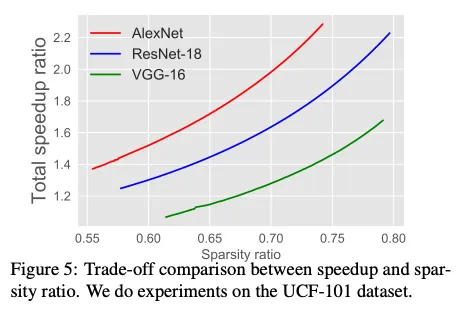
理论加速比与实际加速比。 设计硬件来评估实际加速比超出了当前工作的范围,但根据[22]中的表III,实际加速比可以通过EIE引擎上权重和激活的稀疏性很好地估计。从[22]中的表III可以看出,层的密度(权重%×激活%)和层推理的加速比(FLOP%)之间的关系接近线性。因此,可以推断,使用精心设计的硬件,这些理论数字与实际应用中的数字之间不会有显著的性能差距。 批归一化。 几项研究表明,线性层计算只占总推理时间的一部分,一些其他非线性层也很耗时,特别是BN层。因此,我们在图5中比较了AlexNet(无BN)、VGG-16(无BN)和ResNet-18(有BN)之间的总加速比(考虑所有开销)和稀疏率之间的权衡。
5. Conclusion
我们提出了用于视频快速推理的循环残差模块。我们已经展示了不同CNN模型的整体稀疏性可以通过我们的RRM框架得到普遍改善。同时,将我们的RRM框架应用于一些已经加速的模型,如XNOR-Net和深度压缩模型,它们可以实现进一步的加速。实验表明,所提出的RRM框架加速了用于实时视频理解的视觉识别系统YOLOv2和rt-Pose,在不损失识别精度的情况下实现了令人印象深刻的加速。
文章有点太老了。