摘要:脉冲神经网络(Spiking Neural Networks, SNNs)由于其低功耗和生物可解释性等特性,被认为在高能效计算方面具有巨大潜力。然而,在图像生成任务中对 SNN 的探索仍然非常有限,目前尚未有一种统一且有效的 SNN 生成模型结构被提出。为此,本文提出了一种新的基于脉冲神经网络的扩散模型体系结构。我们使用 Transformer 替代了主流扩散模型中常用的 U-net 结构,从而在较低的计算成本和更短的采样时间下生成质量更高的图像,旨在为基于 SNN 的生成模型研究提供一个实证性的基准。基于 MNIST、Fashion-MNIST 和 CIFAR-10 数据集的实验表明,与现有的 SNN 生成模型相比,我们的工作在性能上具有很强的竞争力。
1. Intro
之前的SNN图像生成,如Spiking-GAN、FSVAE、SDDPM之类的工作普遍没有达到ANN的水平。
这篇工作提出基于RWKV注意力的Diffusion Transformer模型,并且引入了重构模块,旨在补充Neuron触发后丢失的信息。
2. Preliminary
RWKV Attention:
对于位于时间步的输入向量,首先进行线性变换:,其中 , , 是线性变换矩阵。是通过加权原始输入和前一个时间步的输入(称为 token-shift)得到的。被称为接收矩阵,其中的每个元素表示接收到的过去信息。和类似于自注意力中的键(Key)和值(Value)矩阵。
其中,是第行的向量,是第行的向量,是 Hadamard 积(逐元素乘积),是一个可学习的位置衰减向量,防止退化。
然后进行Time Mixing:
和Channel Mixing:
其中,和 是线性变换,是作用于的 Sigmoid 函数。通过对应用 Sigmoid,可以消除不必要的历史信息,充当一个“遗忘门”,从而获得输出。
时间混合可以简单地看作是标准自注意力的替代,而通道混合可以看作是前馈网络(Feed-Forward Network, FFN)层的替代。
3. Proposed Method
A. Overview of SDiT Architecture
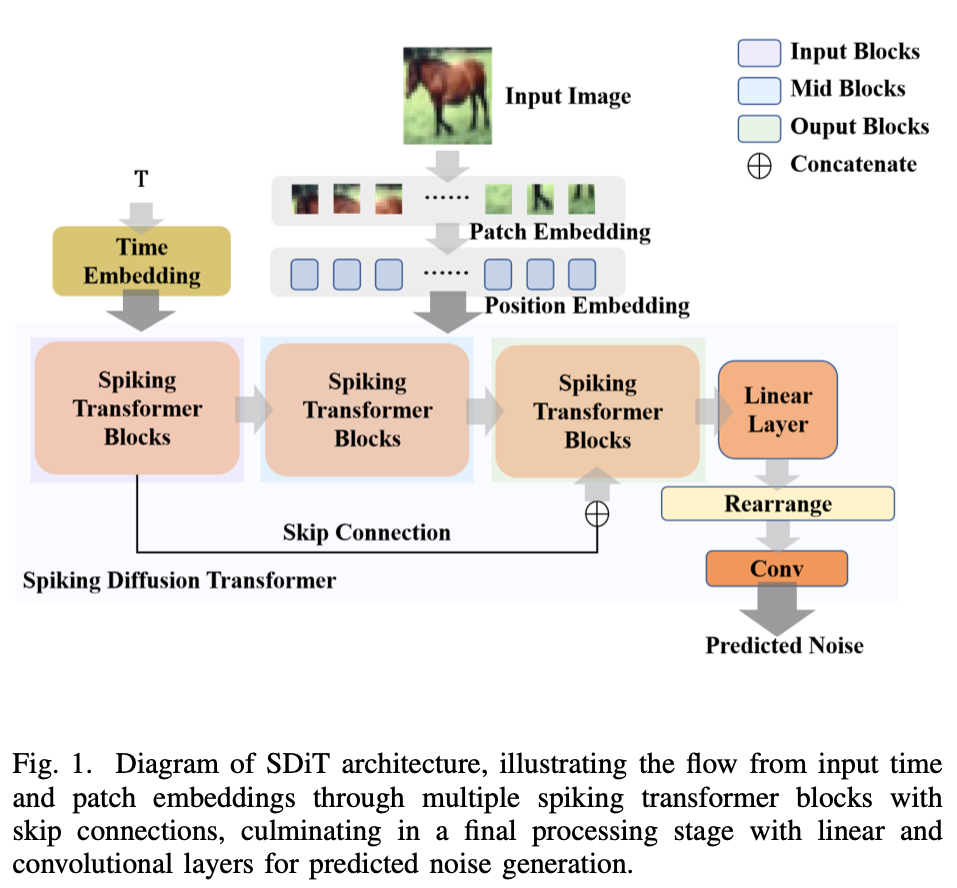
如图 1 所示,网络架构概览如下:输入图像在进入模型前,首先经过 Patch Embedding,然后进行位置嵌入(Position Embedding)。去噪时间步通过时间嵌入(Time Embedding)输入模型。受 U-ViT [6] 启发,模型由三个阶段的 Spiking Transformer Blocks 组成。第一阶段的输入块(Input Blocks)将输出分为两条路径——一条直接连接到下一块,另一条作为跳跃连接到输出块(Output Blocks)的对应块。Spiking Transformer Blocks 的输出将被输入最终层(Final Layer),并映射回原始图像大小。经过 Patch 重构和卷积层后,最终生成的噪声预测图像被输出。
B. Embedding
划分Patch + Conv映射到高维 + Position Embedding。
C. Spiking Transformer Block
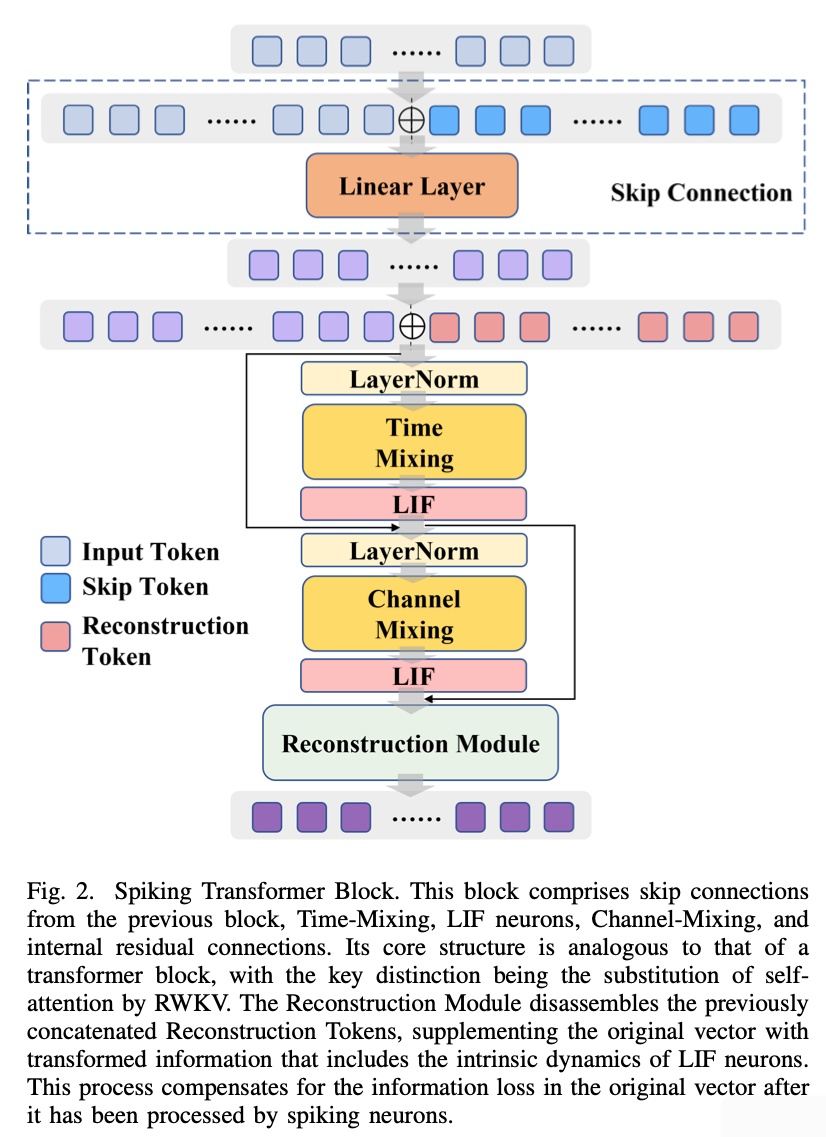
给定输入向量,其中是批量大小, 是 Patch 序列长度,是特征维度。
定义用于跳跃连接的函数 F 如下:
其中,表示拼接操作,是线性变换矩阵。对于输入块和中间块,为 None;对于输出块,是来自对应输入块的输出。
引入一个重构 Token,记为,并在拼接之前进行平铺操作:
其中,表示克罗内克积,是全 1 向量。
拼接后的依次输入时间混合(Time-Mixing)和通道混合(Channel-Mixing)模块。经过 Leaky Integrate-and-Fire (LIF) 神经元后,添加残差连接:
其中, 表示 LayerNorm。
最终,通道混合的输出进行以下操作:
其中,表示重构模块中的操作。
D. Reconstruction Module
为弥补这种损失,我们设计了重构 Token 和重构模块。重构 Token 由可学习参数组成。通过嵌入后,重构 Token 可以表示脉冲神经元的内在动态信息。在重构模块中,原始输出被重新调整,以减轻通过脉冲神经元时的信息损失。在第 IV 节中展示了其有效性。
对拼接向量计算后,嵌入的重构 Token 从输出向量中分离:
其中 表示向量分离操作。
由于重构 Token 的维度与输入相同,其特征维度首先线性变换以匹配 Patch 数量:
其中 。
然后交换 Patch 和特征维度,并再次线性变换以匹配特征维度:
其中。
最终,将获得的向量与分离向量逐元素相乘并相加,以作为补充信息:
其中表示 Hadamard 积。
E. Final Layer
沿特征维度做线性变换,匹配原大小,然后将Patch重建,并且过一个3*3 conv提升图形质量。
4. Experiment
A. Experiment Settings
评估指标 :我们使用 Fréchet Inception Distance (FID)评估生成图像的质量,并使用 Inception Score (IS)评估样本的多样性。在计算 FID 时,从数据集中采样 50,000 张图像,并生成 50,000 张图像用于计算两者之间的 FID。在计算 MNIST 和 Fashion-MNIST 数据集的 IS 时,由于这些数据分布与最初用于提出和验证 IS 的 ImageNet 存在显著差异,因此 IS 分数的对比意义有限。 实现细节 :我们将 MNIST、Fashion-MNIST 和 CIFAR-10 的输入图像统一标准化为 28×28 的尺寸。对于 MNIST 和 Fashion-MNIST,模型架构包括 2 个输入块(Input Blocks)和输出块(Output Blocks),1 个中间块(Mid Block),隐藏维度为 384。对于 CIFAR-10,则扩展为 4 个输入块和输出块、1 个中间块,隐藏维度为 512。优化器使用 AdamW,学习率为,MNIST 和 Fashion-MNIST 的模型训练 1600 轮,CIFAR-10 的模型训练 2000 轮。我们的 SNN 模型基于 SpikingJelly 框架实现,实验在 4×NVIDIA 4090 GPUs 上进行。
B. Comparisons
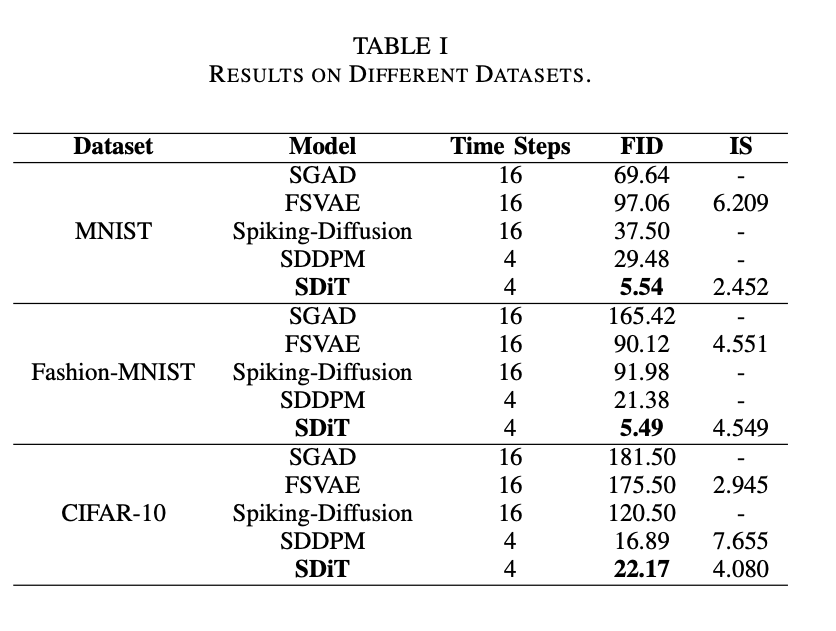

CIFAR10上比SDDPM差一些。
C. Ablation Study
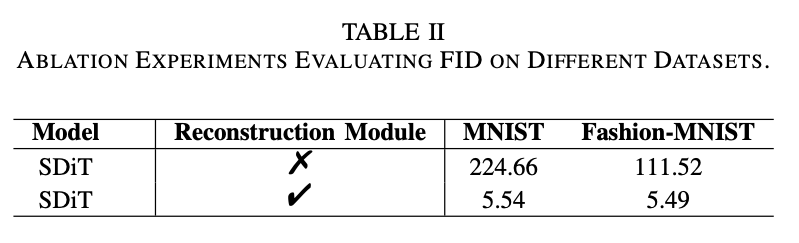
有无Reconstruction Module。
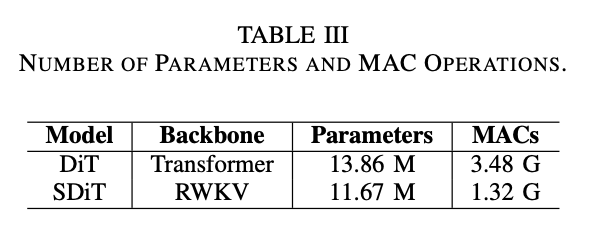
RWKV的AC数比纯Transformer Backbone的更少,参数量上有优势。
5. Discussion
尽管 SDiT 表现相对强大,但仍然存在一些局限性。SDiT 在 MNIST 和 Fashion-MNIST 数据集上的性能显著超越其他方法,但在 CIFAR-10 数据集上的结果未能达到最新技术水平。我们将这种不足部分归因于 Vision Transformer 在有限数据上训练的效率较低。MNIST 和 Fashion-MNIST 的图像编码相对简单的视觉信息,而 CIFAR-10 图像的内在复杂性和较低分辨率掩盖了 SDiT 学习表示中的细粒度边缘细节。 关于自注意力机制与 SNNs 的集成,我们计划在未来工作中引入更细粒度的方案,以进一步减少自注意力在 SNN 框架中的信息损失。 另一个局限性是 SDiT 的嵌入组件未完全基于 SNN 实现。目前的 SDiT 由 ANN 和 SNN 的混合架构组成。当图像尺寸增加时,ANN 模块的参数和计算量也会增加,从而削弱 SNNs 的低功耗特性。未来的研究将探索完全基于 SNN 框架的设计,尝试构建纯 SNN 架构的模型。
6. Conclusion
在本研究中,我们提出了一种新型生成脉冲神经网络架构 SDiT,它结合了 SNNs 的低功耗特性与卓越的生成能力。作为在 SNN 领域中引入 Transformer 作为扩散模型骨干的全新尝试,SDiT 在生成图像质量方面提升了当前技术水平,并在多个数据集上表现出色。我们希望该研究能够为 SNN 生成模型领域提供新视角,并推动未来相关领域的发展。
超级短的文章,感觉就只是发在Arxiv上占个坑。Reconstruction Module感觉就是插入了一个捕捉高维信息的旁路,一路跟着推完一边之后把这个旁路的信息fuse到原有的信息中,相当于对原信息做一个补正。