摘要: 受大脑精妙结构的启发,脉冲神经网络(Spiking Neural Networks, SNNs)已成为人工智能领域的变革性技术,能够逼真地模拟生物神经网络的复杂动态。虽然 SNN 在专用稀疏计算硬件上显示出极高的能效,但其实际训练通常仍依赖普通 GPU,这与传统人工神经网络(ANNs)相比往往导致更长的计算时间,进而为 SNN 研究的深入推进带来了显著阻碍。为应对这一挑战,本文提出了一种新颖的时间融合(temporal fusion)方法,用以加速 SNN 在 GPU 平台上的传播动态,可作为现有 SNN 深度学习任务处理方案的增强补充。通过在真实训练场景和理想化条件下的大量实验验证,该方法已被证实在单 GPU 及多 GPU 系统上均具备高效性和良好的适应性。与多种现有 SNN 库/实现相比,我们的方法在 NVIDIA A100 GPU 上取得了 5×–40× 的加速效果。实验代码已公开:https://github.com/EMI-Group/snn-temporal-fusion。
1. Intro
尽管 SNN 具备诸多潜在优势,引入时间维度常导致训练速度显著降低。许多研究通过截短网络时间长度来缓解此问题,但这既削弱了 SNN 的时间特性,也使其更像 ANN。
2. Related Work
2.1. GPU Acceleration for Deep Learning
Nvidia的CUDA以及相关技术栈。
2.2. Neuromorphic Computing Infrastructures
BindsNET, Norse, snnTorch, SpikingJelly, cuSNN, GeNN, …
2.3. Spiking Neurons
LIF.
3. Method
3.1. Parallelism of LIF Spiking Neurons
假设:是Neuron i在个timestep的膜电位,是对应的spike输出,设静息电位为,衰减系数为,则有:
输出的spike为:
训练的时候有:
上面的式子都是彼此独立的且element wise的。
3.2. Temporal Fusion on a Single GPU
时间步展开等价于层展开 ——若每层在所有时间步完成计算后再进入下一层,则可在时间维度上进行优化,尤其当所有时间步的初始状态已知时更为有效。
就是Layer-By-Layer。
依此思路,本文提出时间融合(temporal fusion) :
- 为每个神经元分配独立 GPU 线程;
- 在单一 GPU kernel 内,将同一层所有时间步的读/写与运算一次性合并,显著减少频繁的显存访存开销。

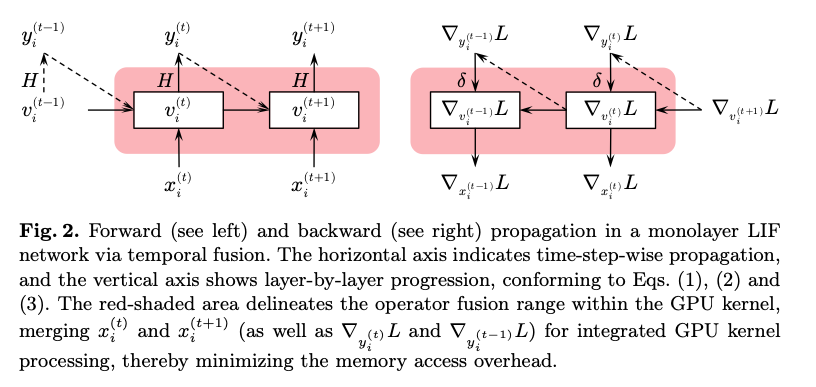

3.3. Temporal Fusion across Multiple GPUs
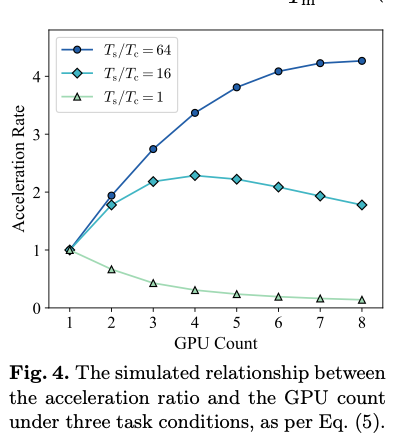
时间步越长,采用多 GPU 的收益越高。
4. Implementation
import torch
import temporal_fusion_kernel
# 定义用于调度自定义 CUDA kernel 的 Function
class FusedLIF(torch.autograd.Function):
@staticmethod
def forward(ctx, x, args):
ctx.args = args
# 调用时间融合的前向 CUDA kernel
return temporal_fusion_kernel.fusedForwardLIF(x, args)
@staticmethod
def backward(ctx, grad_y):
args = ctx.args
# 调用时间融合的反向 CUDA kernel
return temporal_fusion_kernel.fusedBackwardLIF(grad_y, args)
# 定义可插拔的 LIF 层模块
class LIFLayer(torch.nn.Module):
def __init__(self, args):
super().__init__()
self.args = args
def forward(self, x):
# 在前向过程中应用时序融合算子
return FusedLIF.apply(x, self.args)
# 定义超参数并组装模型
args = ... # 超参数配置
model = torch.nn.Sequential(..., LIFLayer(args), ...)
实现要点
- 高性能内核编译 :借助 CUDA 预编译机制,确保前向与反向传播的时间融合算子在 GPU 上达到最优性能。
- 与 PyTorch 无缝集成 :通过自定义
autograd.Function,将时间融合算子插入到标准torch.nn.Module中,使其可与常见的卷积、线性等 ANN 运算透明协同。 - 单/多 GPU 支持 :在单 GPU 设备上即可实现时序算子融合;在分布式训练环境中,可配合 PyTorch 的管线并行或
torch.distributed框架,将时间维度切分至多张 GPU,充分发挥并行加速优势。
5. Experiment
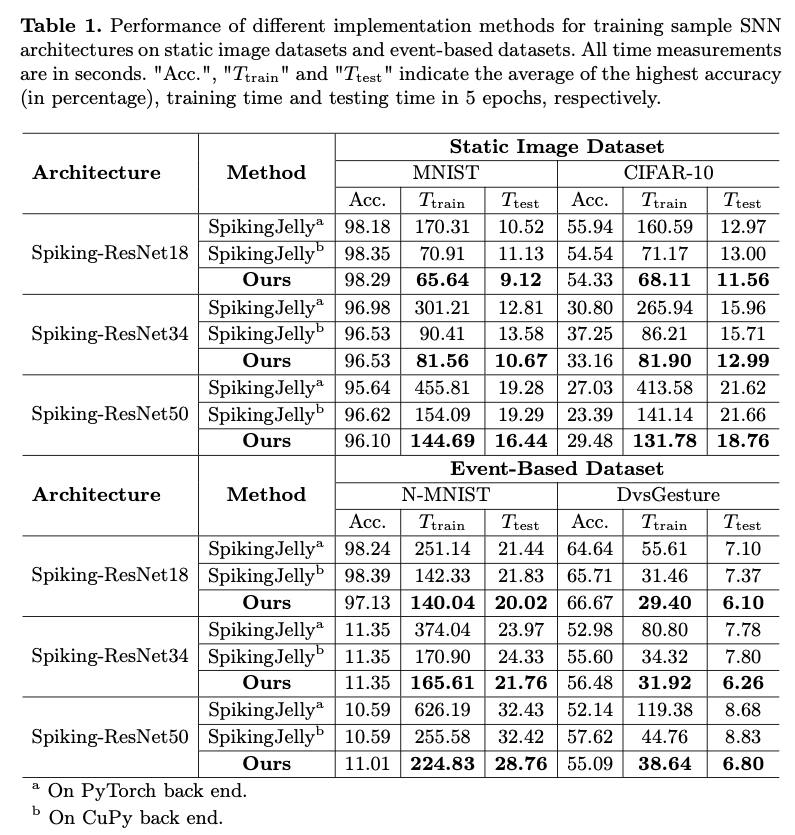
感觉没什么好写的
6. Conclusion
本文提出了一种名为“时间融合”的方法,专为高效的 GPU 加速 SNN 训练而设计。为便于该方法的实际应用,我们基于 CUDA 开发了完整的实现,并提供了详尽的编程模型。该实现已与主流深度学习框架 PyTorch 无缝集成,使用户能够在各类 SNN 研究与开发项目中轻松采用并应用本方法。我们还针对时间融合方法开展了一系列全面的基准测试,这些测试精心评估了方法在不同 SNN 架构和训练场景下的适应性,以及对训练整体效率的影响。实验结果充分证明,本方法在提升训练效率方面具有显著效果,且具备广泛的适用性。