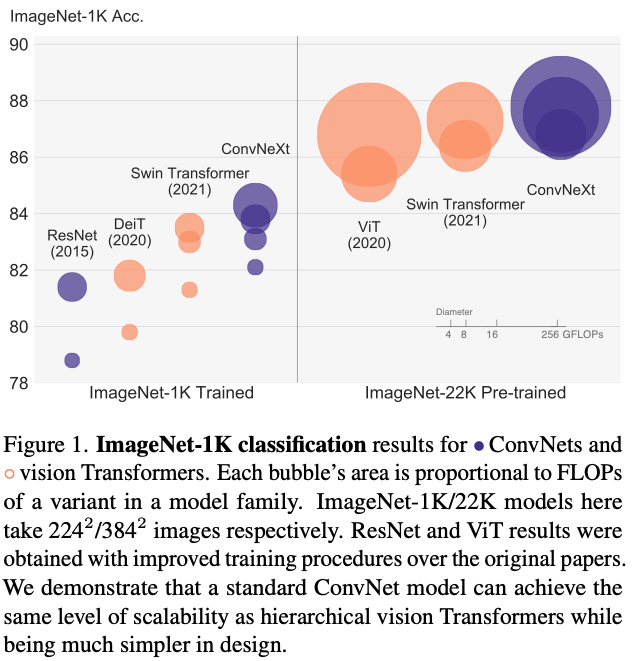
摘要: 视觉识别的”咆哮的20年代”始于Vision Transformers (ViTs)的引入,它迅速取代了ConvNets成为最先进的图像分类模型。然而,普通的ViT在应用于诸如目标检测和语义分割等通用计算机视觉任务时面临困难。层次化Transformers(例如Swin Transformers)重新引入了几个ConvNet的先验,使Transformers作为通用视觉骨干网络变得切实可行,并在各种视觉任务中展现出卓越的性能。不过,这种混合方法的有效性仍然主要归功于Transformers的内在优越性,而非卷积的固有归纳偏置。在本研究中,我们重新审视了设计空间,并测试了纯ConvNet所能达到的极限。我们逐步将标准ResNet”现代化”,使其向vision Transformer的设计靠拢,并在此过程中发现了几个导致性能差异的关键组件。这次探索的成果是一系列被称为ConvNeXt的纯ConvNet模型。ConvNeXt完全由标准ConvNet模块构建,在准确性和可扩展性方面与Transformers相媲美,在ImageNet上达到了87.8%的top-1准确率,并在COCO检测和ADE20K分割任务上超越了Swin Transformers,同时保持了标准ConvNets的简洁性和效率。
1. Introduction
CV领域从AlexNet开始,不断设计基于Convolution的网络,因为“滑动窗口”和特征的局部性、平移不变形这些先验在图像领域都是重要的归纳偏置。而Transformer和ViT的兴起又在“重新发明卷积”。
然而,这些尝试是有代价的:滑动窗口自注意力的简单实现可能很昂贵;通过循环移位等高级方法,速度可以得到优化,但系统在设计上变得更加复杂。另一方面,几乎具有讽刺意味的是,ConvNet已经以一种直接、简单的方式满足了许多这些期望的特性。ConvNet似乎失去动力的唯一原因是(层次化)Transformer在许多视觉任务中超越了它们,而性能差异通常归因于Transformer的卓越扩展行为,多头自注意力是其关键组件。 为此,我们从一个使用改进程序训练的标准ResNet(例如ResNet-50)开始。我们逐步将架构”现代化”,直到构建一个层次化视觉Transformer(例如Swin-T)。我们的探索由一个关键问题引导:Transformer中的设计决策如何影响ConvNets的性能?在这个过程中,我们发现了几个导致性能差异的关键组件。因此,我们提出了一系列被称为ConvNeXt的纯ConvNets。我们在各种视觉任务上评估了ConvNeXts,如ImageNet分类、COCO上的目标检测/分割和ADE20K上的语义分割。令人惊讶的是,完全由标准ConvNet模块构建的ConvNeXts在准确性、可扩展性和鲁棒性方面与Transformer在所有主要基准测试中表现相当。ConvNeXt保持了标准ConvNets的效率,其全卷积特性使其在训练和测试时都非常容易实现。
2. Modernizing a ConvNet: a Roadmap
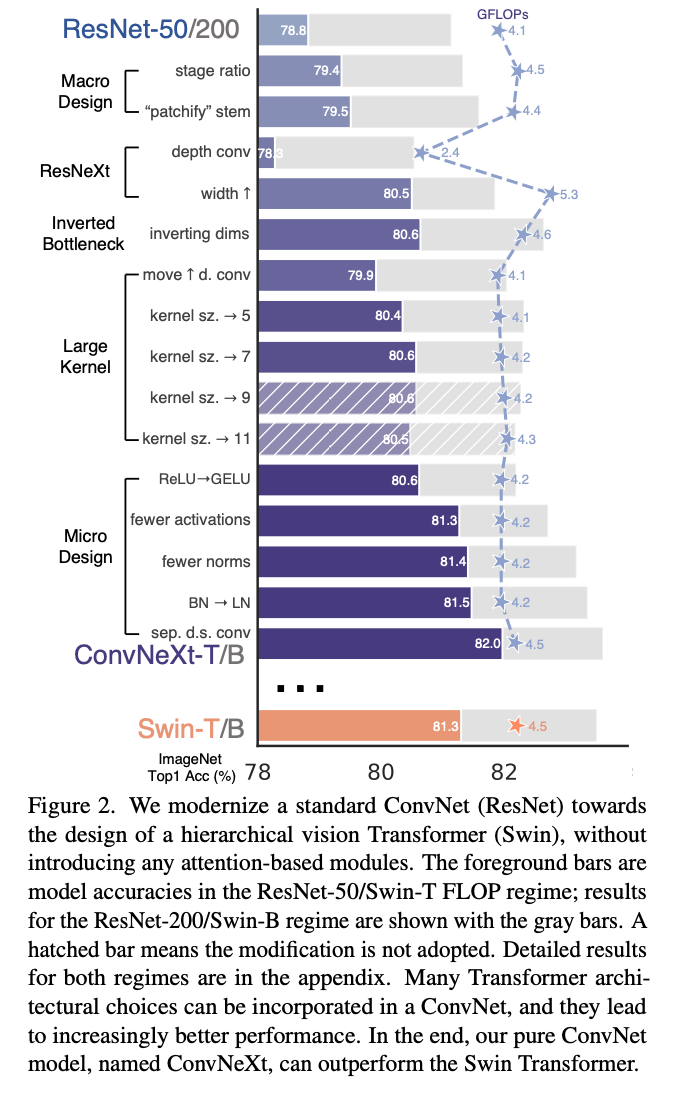
一步一步爆改ResNet50和ResNet200,文章没有讲什么理论方面的东西,就是一步一步加上现代ViT常见的Trick和结构,就得到了一个performance相当好的模型。Fig2是ConvNext一步一步改造的路线图。
2.1. Training Techniques
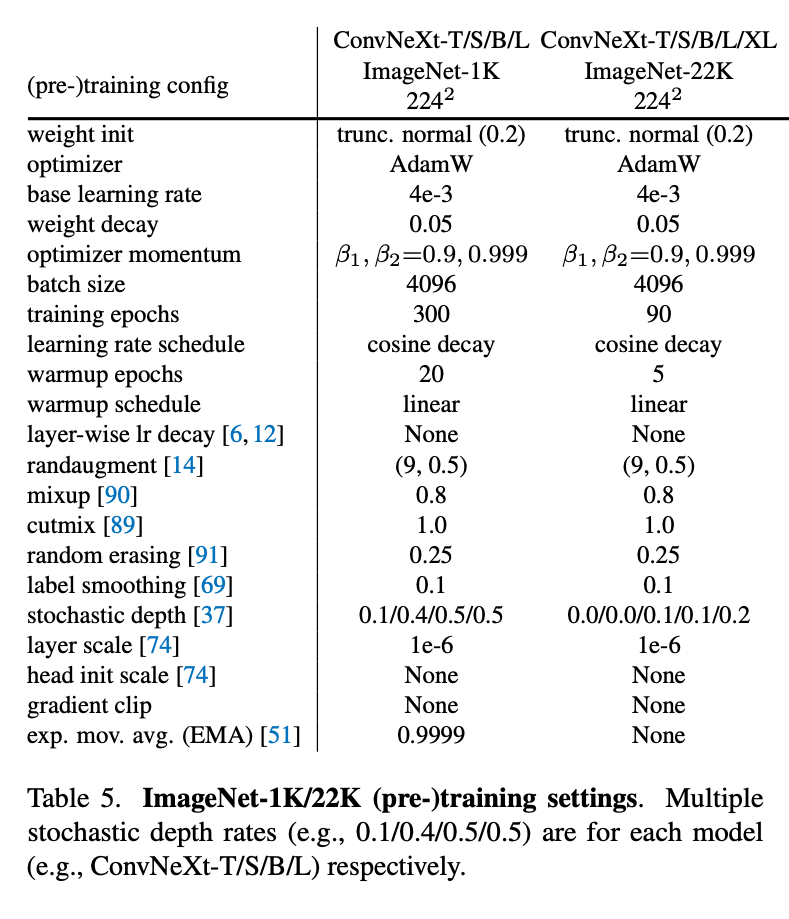
使用AdamW优化器,使用Mixup,Cutmix,RandAugment,Random Erasing,以及包括stochastic Depth和Label Smoothing这些正则化方案,将训练从90个epoch延长到300个epoch。完整的训练超参:
引入了一整套完整的现代化的训练技术。采用了这种现代的训练方法之后,ResNet的性能从76.1%上升到了78.8(+2.7%)。
Optimizer
Adam优化器的更新:
- 计算梯度:
- 更新偏置校正的一阶矩估计:, 其中
- 更新偏置校正的二阶矩估计:, 其中
- 更新参数:
在Adam中,权重衰减通常通过在损失函数中添加L2正则化项来实现:
AdamW在参数更新步骤中直接应用权重衰减:,其中 是权重衰减系数。
数据增强
- Mixup:将两个随机样本线性混合,标签也按相同比例混合,创造新的训练样本;
- CutMix:将一个图像的一个区域换成另一个图像的对应区域,标签也对应替换,比Mixup保留了更多的信息;
- RandAugment:从一组预先定义好的变换中随机选择一些然后应用;
- Random Erasing:随机选择一个区域,用随机值或者平均值替换,模拟遮挡;
正则化
- Stochastic Depth:训练的过程中随机跳过一些layer,类似dropout但是作用于整个layer而不是neuron;
- Label Smoothing:将one-hot编码转为软编码,相当于原本是的编码变为,减少了模型的过度自信,提高了泛化能力;
2.2. Macro Design
Changing stage compute ratio
ResNet中各阶段计算分布的原始设计在很大程度上是经验性的。较重的”res4”阶段旨在与目标检测等下游任务兼容,其中检测器头部在14×14特征平面上操作。另一方面,Swin-T遵循相同的原则,但阶段计算比例略有不同,为1:1:3:1。对于更大的Swin Transformer,比例为1:1:9:1。遵循这一设计,我们将每个阶段的块数从ResNet-50中的(3,4,6,3)调整为(3,3,9,3),这也使FLOPs与Swin-T保持一致。这将模型准确率从78.8%提高到79.4%。 值得注意的是,研究人员已经彻底研究了计算分布,可能存在更优的设计。
Changing stem to “Patchify”
将传统ConvNet的下采样(如stride=2的7*7卷积)换成更加激进的patchify策略,如14 * 14的非重叠卷积。文章用patchify层替换了ResNet风格的stem cell,该层使用4×4,步长为4的卷积层实现。准确率从79.4%变为79.5%。
2.3. ResNext-ify
遵循ResNext的设计,使用分组卷积。指导原则是“use more groups, expand width“。在减少FLOP的同事,可以扩大网络的宽度弥补减少的信息容量。
使用depthwise convolution,这种卷积类似self attention中的加权操作,只在channel维度上混合信息。遵循ResNeXt提出的策略,将网络宽度增加到与Swin-T相同的通道数(从64增加到96)。这将网络性能提高到80.5%, 同时FLOPs增加到5.3G。
2.4. Inverted Bottleneck
Transformer块中一个重要的设计是它创建了一个倒置瓶颈,即MLP块的隐藏维度是输入维度的四倍。有趣的是,这种Transformer设计与ConvNets中使用的扩展比为4的倒置瓶颈设计相连。这个想法在MobileNetV2首先知名,随后在几个先进的ConvNet架构中得到了应用。
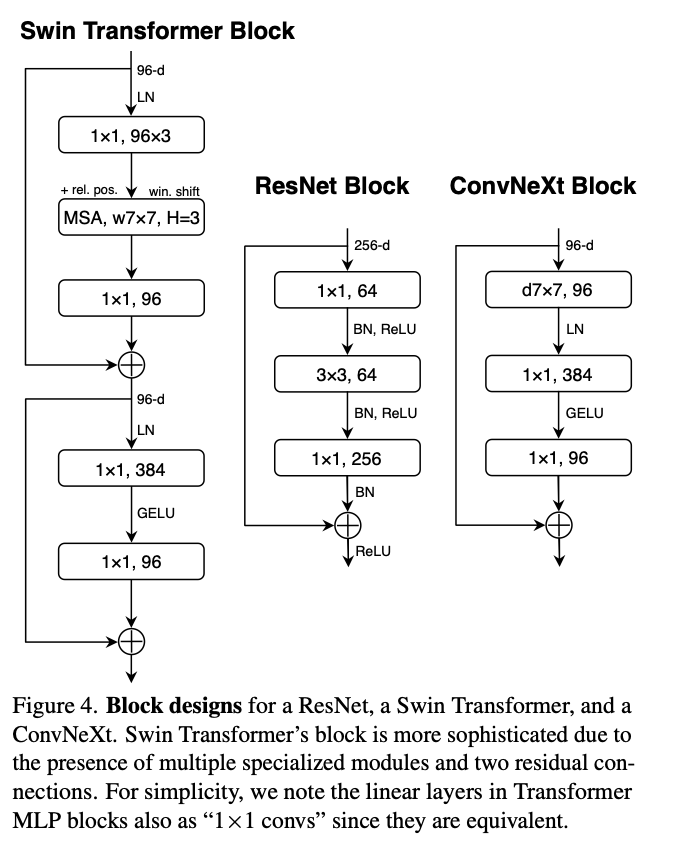
尽管引入的这种1*1 depthwise conv增加了FLOPs,但由于下采样残差块的快捷连接1×1卷积层的FLOPs显著减少,这一变化将整个网络的FLOPs降低到4.6G。有趣的是,这导致性能略有提高(从80.5%到80.6%)。 在ResNet-200/Swin-B级别,这一步带来了更多的收益(从81.9%到82.6%),同时也减少了FLOPs。
2.5. Large Kernel Size
Moving up depthwise conv layer
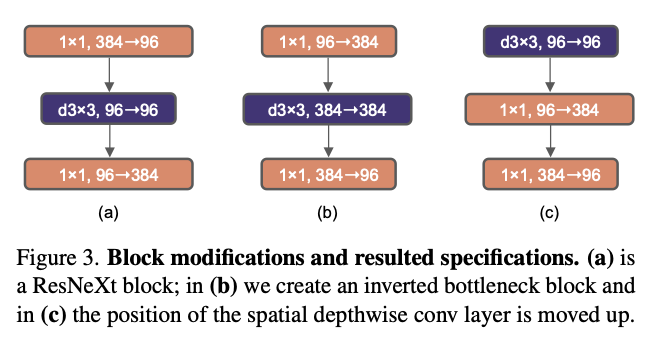
Swin-Transformer中的kernel基本是7 * 7,意味着它具有更大的感受野。同时模仿Transformer中的架构设计。在Transformer中,MLP在Attention之后,所以Fig3中的设计要进行修改,先经过depthwise convolution,然后经过其他的卷积。这样使得更加复杂的模块(MSA,大Kernel卷积)作用在更小的channel数上,而inverted bottleneck中间很多通道的层就给了计算密集的1*1 conv。这一中间步骤将FLOPs降低到4.1G,导致性能暂时下降到79.9%。
Increasing the kernel size
经过所有这些准备,采用更大内核尺寸卷积的好处是显著的。我们实验了几种内核尺寸,包括3、5、7、9和11。网络的性能从79.9%(3×3)提高到80.6%(7×7) ,而网络的FLOPs基本保持不变。此外,我们观察到更大内核尺寸的好处在7×7处达到饱和点。我们在大容量模型中也验证了这一行为:当我们将内核尺寸增加到7×7以上时,ResNet-200级别的模型不会表现出进一步的收益。
2.6. Micro Design
Replacing ReLU with GELU
GELU可以看做是ReLU的一个更加平滑的变体,换了之后精度没变,但还是换了。
Fewer activation functions
如Fig4,现在只有在中间的bottleneck之后才过一个激活函数,模仿Transformer只在MLP中间有一个激活函数的做法。这个过程将结果提高了0.7%,达到81.3%,实际上与Swin-T的性能相当。
Fewer normalization layers
如Fig4,删了两个BN。
这进一步将性能提升到81.4%,已经超过了Swin-T的结果 。请注意,我们每个块的归一化层甚至比Transformer还少,因为经验上我们发现在块的开始添加一个额外的BN层并不能改善性能。
Substituting BN with LN
之前的人不用LayerNorm替换对网络可能有不利影响的BatchNorm是因为跑起来效果不好,但是ConvNext改了这么多之后试了一下,发现替换之后没有任何问题,性能提升到81.5% 。
Separate downsampling layers
ResNet中,降采样是通过stride = 2的3*3卷积在每个阶段开始实现的。Swin Transformer中则是有一个单独的降采样层。
我们探索了类似的策略,使用步长为2的2×2卷积层进行空间下采样。这一修改出人意料地导致了训练发散。进一步调查表明,在空间分辨率发生变化的地方添加归一化层可以帮助稳定训练。这包括Swin Transformers中也使用的几个LN层:每个下采样层之前一个,stem之后一个,以及最后的全局平均池化之后一个。我们可以将准确率提高到82.0%,显著超过Swin-T的81.3%。
Closing remarks
我们完成了第一次”探索”,发现了ConvNeXt,这是一个纯粹的ConvNet,在这个计算量级中可以在ImageNet-1K分类任务上超越Swin Transformer。值得注意的是,到目前为止讨论的所有设计选择都是从视觉Transformers中借鉴的。此外,这些设计在ConvNet文献中甚至不是新颖的 - 它们在过去十年中都已被单独研究过,但从未被集体研究。我们的ConvNeXt模型与Swin Transformer具有大致相同的FLOPs、参数数量、吞吐量和内存使用,但不需要特殊模块,如移位窗口注意力或相对位置偏置。
3. Empirical Evaluations on ImageNet
一些模型配置:
- ConvNeXt-T: C = (96, 192, 384, 768), B = (3, 3, 9, 3)
- ConvNeXt-S: C = (96, 192, 384, 768), B = (3, 3, 27, 3)
- ConvNeXt-B: C = (128, 256, 512, 1024), B = (3, 3, 27, 3)
- ConvNeXt-L: C = (192, 384, 768, 1536), B = (3, 3, 27, 3)
- ConvNeXt-XL: C = (256, 512, 1024, 2048), B = (3, 3, 27, 3)
Training细节见2.1中的表。
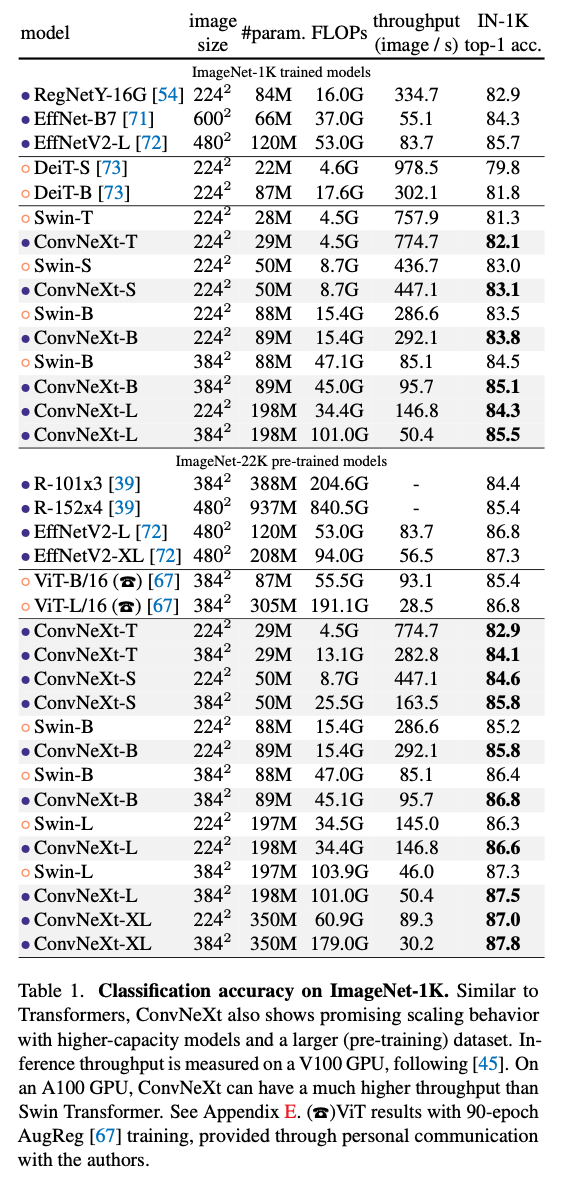
结果证明性能很好并且可以Scale。在ImageNet1k上EfficientNetV2-L取得了最佳,但是ConvNext系列的模型通过在ImageNet22K上进行预训练打败了它,证明大规模训练的重要性。
3.3. Isotropic ConvNext vs. ViT
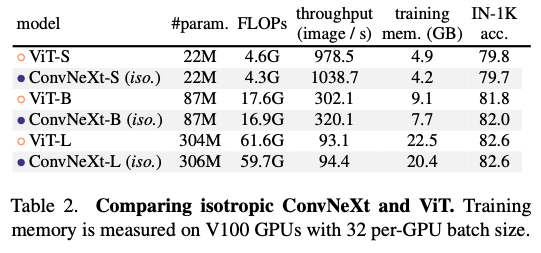
去除下采样层,并且和ViT保持相同的特征维度,从而匹配两者的FLOP。两者的精度基本相同,证明ConvNext Block在非层次化的模型中也有竞争力。
4. Emperical Evaluation on Downstream Tasks
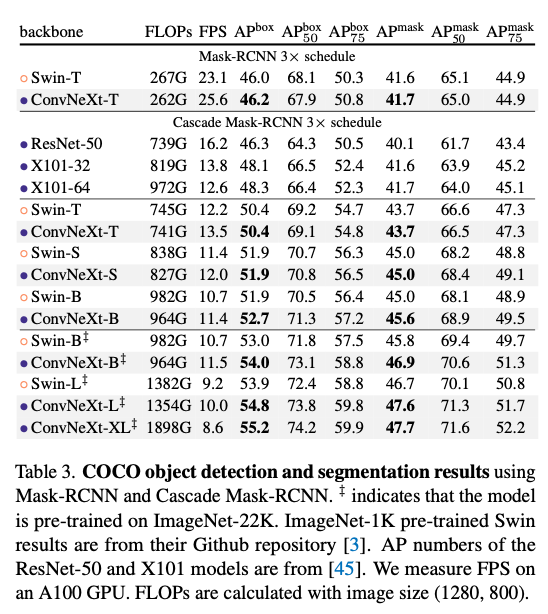
Objext detection and segmentation on COCO
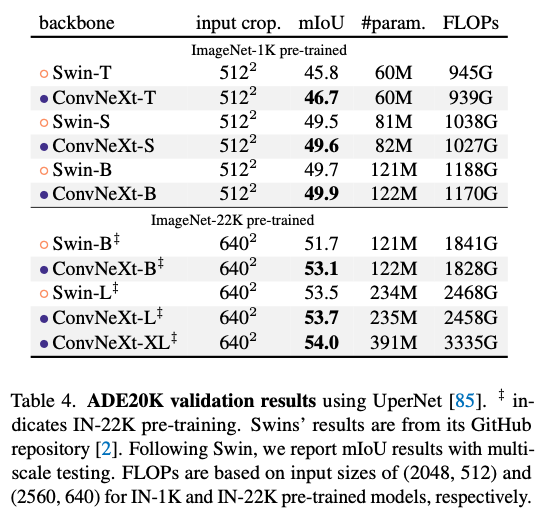
Semantic segmentation on ADE20K
Remarks on model efficiency
训练中相比Transformer相比占用更小的显存,同时推理的过程中throughput相当。
5. Related Work
Hybrid models
在ViT之前和之后的时代,结合卷积和自注意力的混合模型一直被积极研究。在ViT之前,重点是用自注意力/非局部模块增强ConvNet,以捕获长程依赖。原始ViT首次研究了混合配置,随后大量后续工作集中在将卷积先验重新引入ViT,无论是以显式还是隐式的方式。
Recent convolution-based approaches
Han等人表明局部Transformer注意力等价于非均匀动态深度可分离卷积。然后,Swin中的MSA块被替换为动态或常规深度可分离卷积,实现了与Swin相当的性能。同期工作ConvMixer证明,在小规模设置中,深度可分离卷积可以用作有前景的混合策略。ConvMixer使用更小的patch大小来实现最佳结果,使吞吐量比其他基线低得多。GFNet采用快速傅里叶变换(FFT)进行token混合。FFT也是一种卷积形式,但具有全局内核大小和循环填充。
6. Conclusion
在2020年代,视觉Transformers,特别是像Swin Transformers这样的层次化模型,开始超越ConvNets成为通用视觉骨干网络的首选。普遍认为,视觉Transformers比ConvNets更准确、更高效、更可扩展。我们提出了ConvNeXts,这是一个纯ConvNet模型,可以在多个计算机视觉基准测试中与最先进的层次化视觉Transformers进行有利竞争,同时保持了标准ConvNets的简单性和效率。在某些方面,我们的观察令人惊讶,而我们的ConvNeXt模型本身并不完全新颖 - 许多设计选择在过去十年中都已被单独检验过,但没有被集体检验。我们希望本研究报告的新结果将挑战几个广泛持有的观点,并促使人们重新思考卷积在计算机视觉中的重要性。
叠加了所有现代工具的ResNet50性能也能超越Swin Transformer,但是DepthWise Convolution的硬件亲和/SNN亲和还需要验证。但文章证明了ViT并没有杀死CV,传统的Convolution也有很多工作可以继续做,甚至可以说之前的很多Convolution工作之所以被超过,是因为他们没有受益于现在的先进训练技术和大规模预训练。