摘要: 在2020年代初期,得益于架构的改进和更好的表示学习框架,视觉识别领域经历了快速的现代化和性能提升。例如,以ConvNeXt为代表的现代卷积神经网络在各种场景中展现出强大的性能。虽然这些模型最初是为使用ImageNet标签进行监督学习而设计的,但它们也可能从自监督学习技术(如遮蔽自编码器MAE)中受益。然而,我们发现简单地将这两种方法结合会导致性能欠佳。在本文中,我们提出了一个全卷积遮蔽自编码器框架和一个新的全局响应归一化(GRN)层,可以添加到ConvNeXt架构中以增强通道间特征竞争。这种自监督学习技术和架构改进的协同设计产生了一个名为ConvNeXt V2的新模型系列,该系列在各种识别基准测试上显著提高了纯卷积神经网络的性能,包括ImageNet分类、COCO检测和ADE20K分割。我们还提供了各种规模的预训练ConvNeXt V2模型,从一个高效的370万参数的Atto模型(在ImageNet上实现76.7%的top-1准确率),到一个6.5亿参数的Huge模型(仅使用公开训练数据就达到了88.9%的最先进准确率)。
1. Intro
ConvNext是针对来源于NLP中的Transformer,对Convolution Network进行改造。ConvNext V2则是对NLP中应用的很好的Mask Autoencoder方法改进到ConvNext V1中。这种改造主要遇到了以下几个问题:
- MAE是设计给Encoder-Decoder的Transformer使用的,patch seq的计算范式和ConvNext的基于卷积的方法不兼容;为了解决这个问题,ConvNext V2在训练过程中使用类似稀疏卷积的方式实现,但在微调时可以切换回标准的密集层;
- 直接用MAE+ConvNext训练起来非常困难,尤其是MLP层可能出现特征崩溃;为了解决这个问题,提出了Global Response Normalization layer。
2. Related Work
ConvNets
传统的监督学习为主,自监督的工作慢慢出现;重新吹了一下ConvNext。
Masked Autoencoders
以MAE为代表的遮蔽图像建模是最新的自监督学习策略之一。作为神经网络预训练框架,MAE对视觉识别产生了广泛影响。然而,由于其非对称的编码器-解码器设计,原始的遮蔽自编码器不能直接应用于ConvNets。像这样的替代框架尝试调整该方法以用于ConvNets,但结果好坏参半。MCMAE使用几个卷积块作为输入标记器。据我们所知,目前还没有预训练模型显示自监督学习可以改进最佳的ConvNeXt监督学习结果。
3. Fully Convolutional Masked Autoencoder
在原来的输入上随机生成mask,然后让模型根据上下文预测缺失的部分。
Masking
随机遮罩,比例为0.6。在最后阶段(特征图最小的时候)生成mask,然后做上采样。采用minimal的数据增强,只包含随机的resized cropping。
Encoder design
使用ConvNext作为Encoder。在传统的NLP模型中,因为输入是一个sequence,让模型看不到被masked的位置很简单;但是对于图片输入而言,要保证空间结构的同时mask一些内容,如果处理不好就会让模型学到本来看不到的内容。
ConvNext V2学习3D点云卷积,新见解是“稀疏数据视角”看待masked image。Pretrain的过程中,将标准卷积换成submanifold sparse convolution,然后在做微调的时候换回普通的卷积。也可以直接用卷积+二进制mask的方法,计算量会更大,但是对GPU等芯片更加友好。
Decoder design
用了一个简单的ConvNext块作为Decoder,构成了一个非对称的Encoder-Decoder结构。尝试了更加复杂的Decoder,但是这个简单的方案表现就很好,并且训练需要的时间很短。
Reconstruction target
计算生成图像和原图的MSE,只在masked的部分计算。
FCMAE
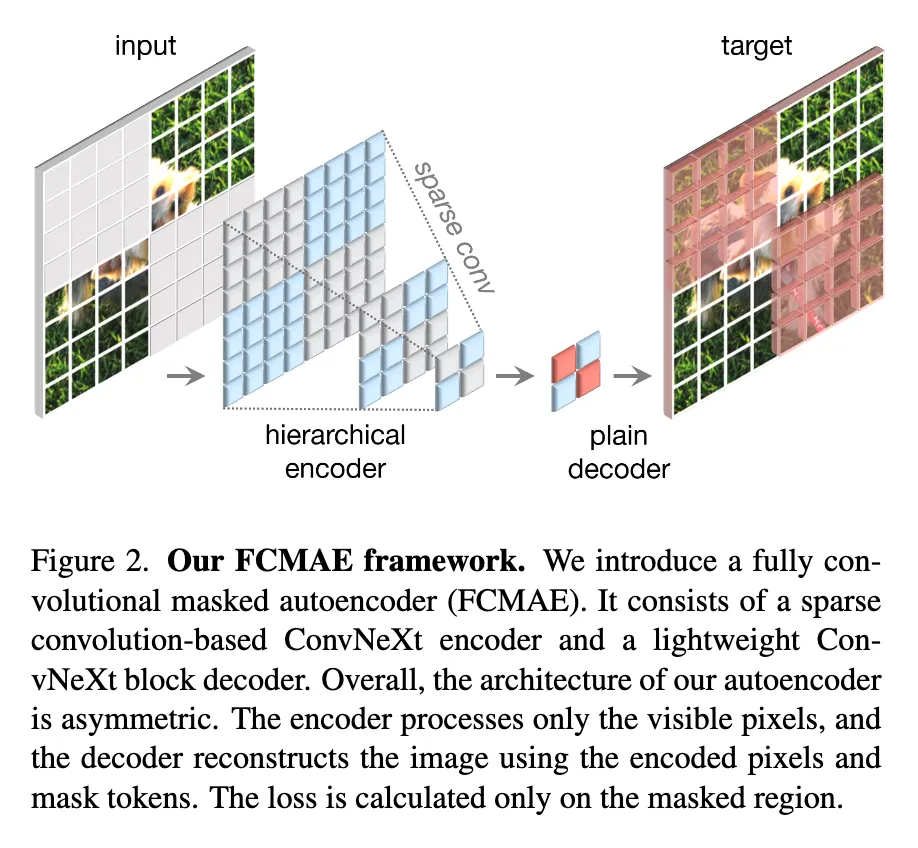
在ImageNet-1K上分别做800个epoch的pretrain和100个epoch的finetuning。
- 不使用Sparse Conv的Acc是79.3,使用后为83.7,减少信息泄露很重要;
- 训练100/300个epoch的全监督模型的精度是82.7和83.8,性能已经基本比得上全监督的模型了;

4. Global Response Normalization
Feature collapse

在ConvNext V1中,可以看到很多通道都是饱和(发放太多)的或死亡(不发放)的,导致产生了太多冗余信号。这种现象主要在MLP层发现。
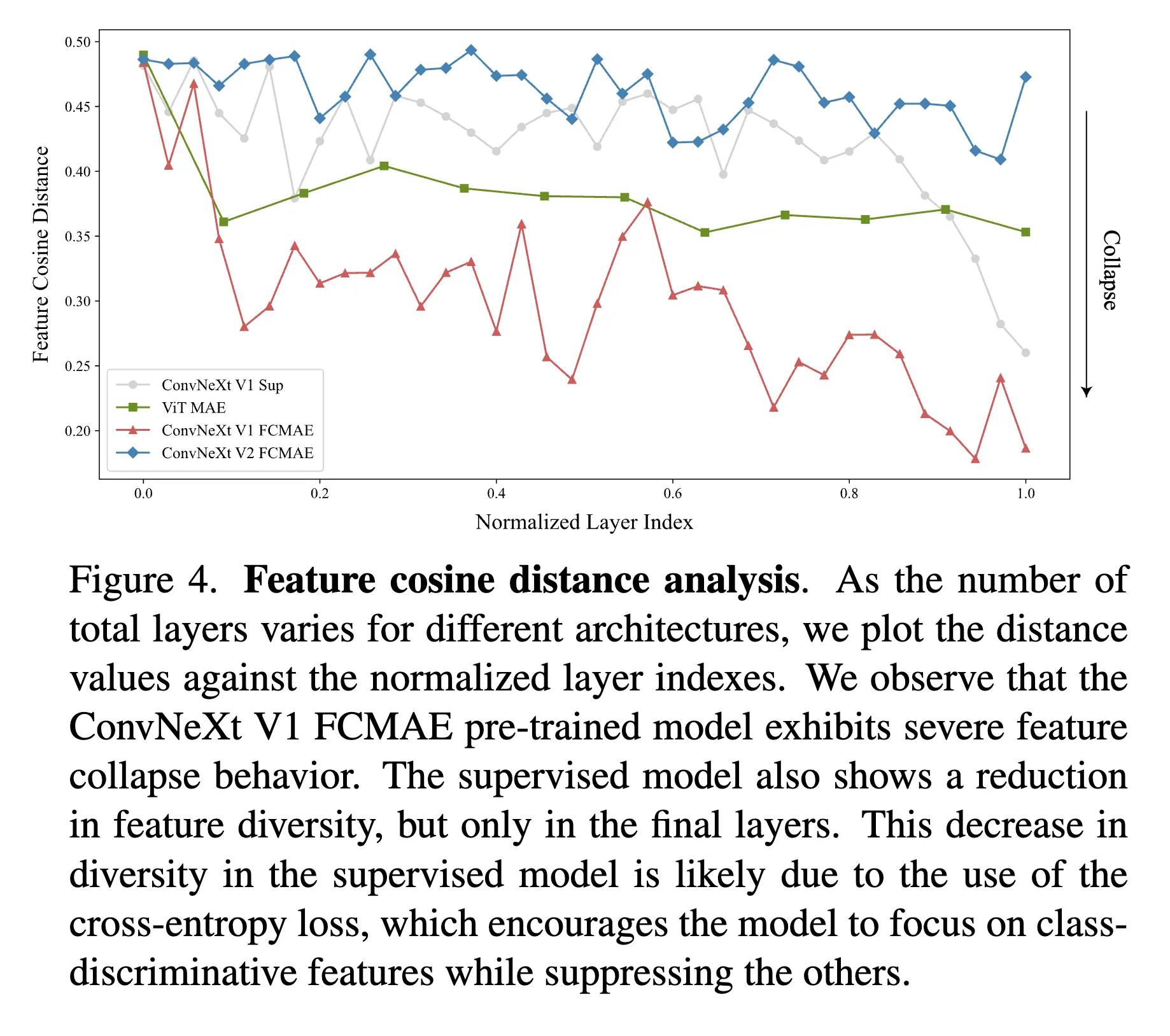
Feature cosine distance analysis
对feature collapse做定量的观察。给定一个activation是第个通道。在通道之间计算average pair-wise consine distance by ,更高的值说明feature之间有更多的diversity。可以看到实验结果表明V2的diversity比V1更好,符合可视化中的insight。
Approach
灵感来源于大脑的侧抑制机制。过程:
1. global feature aggregation
将聚合成一个vector 通过:

a中尝试了不同的函数,最后采用了L2范数。
2. feature normalization
做归一化,b中有不同的尝试,最后做了简单的除法归一化。
3. feature calibration
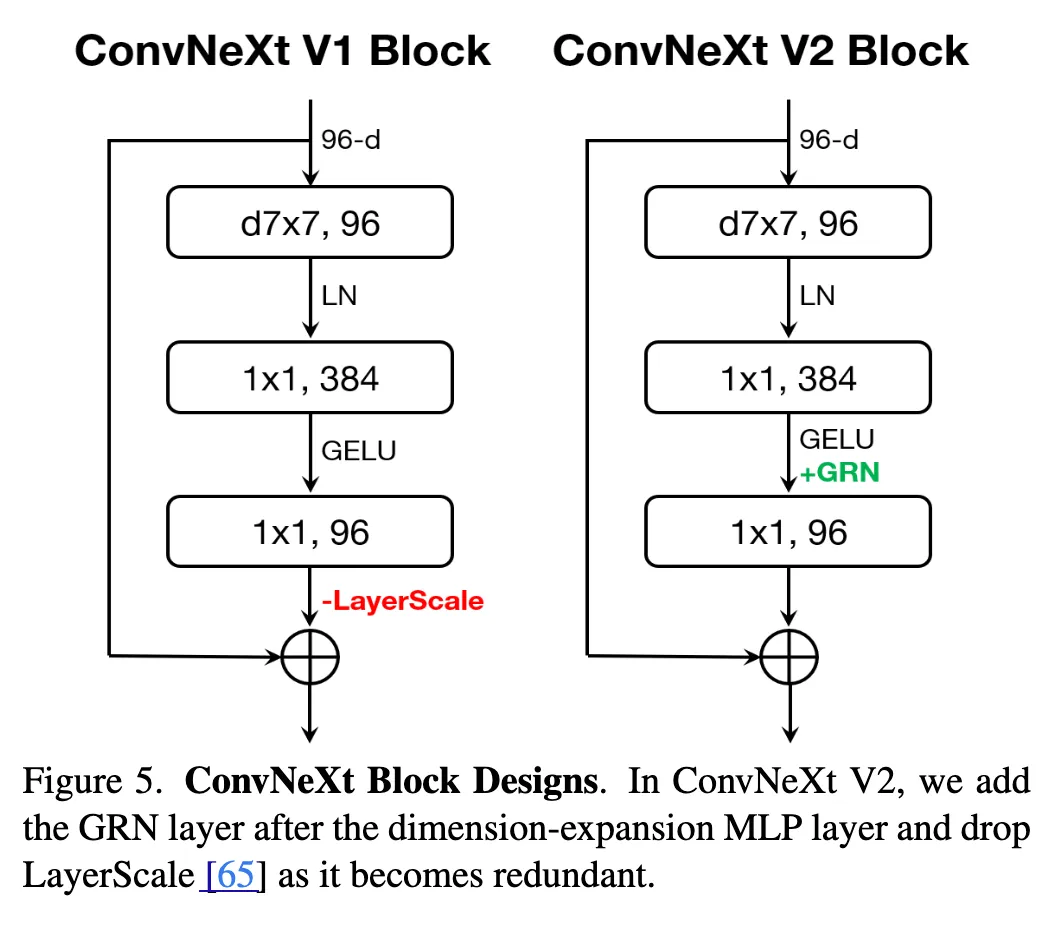
上面这个流程完全不需要学习,为了简化优化的过程还加入了两个课学习的参数,写作
两个参数一开始都设成0。这种类似残差连接的设计让模型可以慢慢引入GRN层。
ConvNextV2
加入GRN就形成了ConvNeXt V2 Block。
Impact of GRN
从上面那个feature余弦距离的图可以看出来。V2 + FCMAE的精度继续提高到84.6,超过了全监督的baseline。
Relation to feature normalization methods
Table 2D。
Relation to feature gating methods
Table 2E。GRN更简单。
The role of GRN in pre-training/fine-tuning
Table 2F。
5. ImageNet Experiments
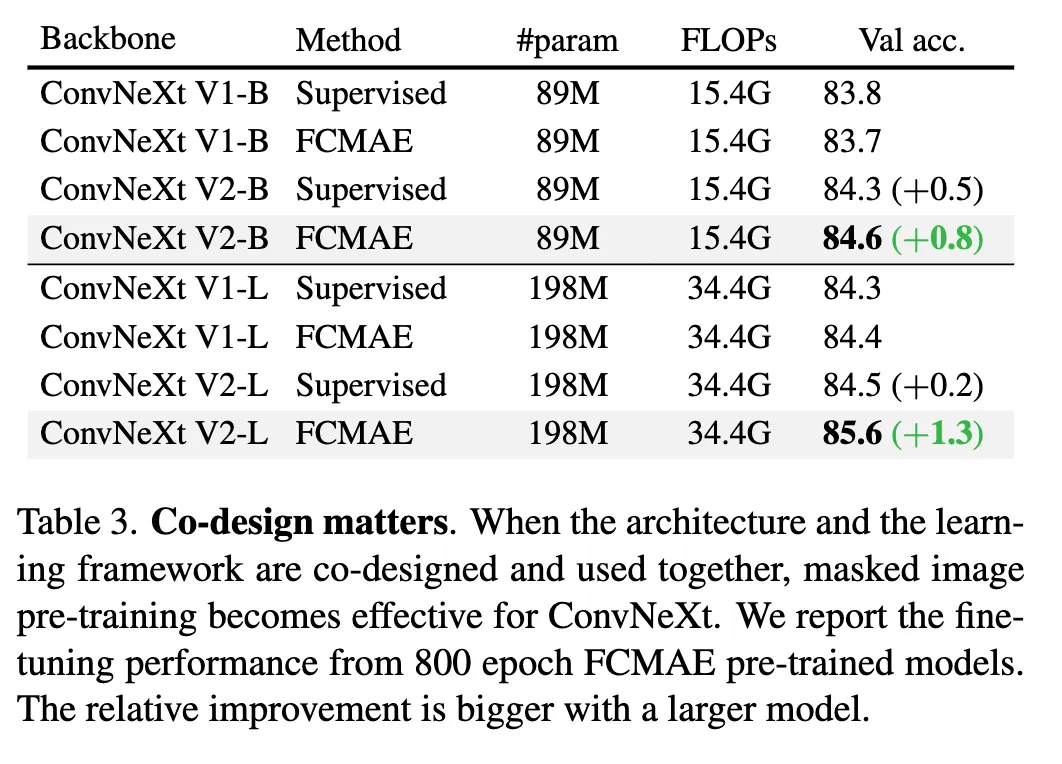
Co-design matters
如果不修改网络的框架,直接做MAE没什么效果;如果只修改网络的框架添加GRN而不做MAE,效果也不怎么样。这证明模型和学习的框架应当一起考虑。
Model scaling
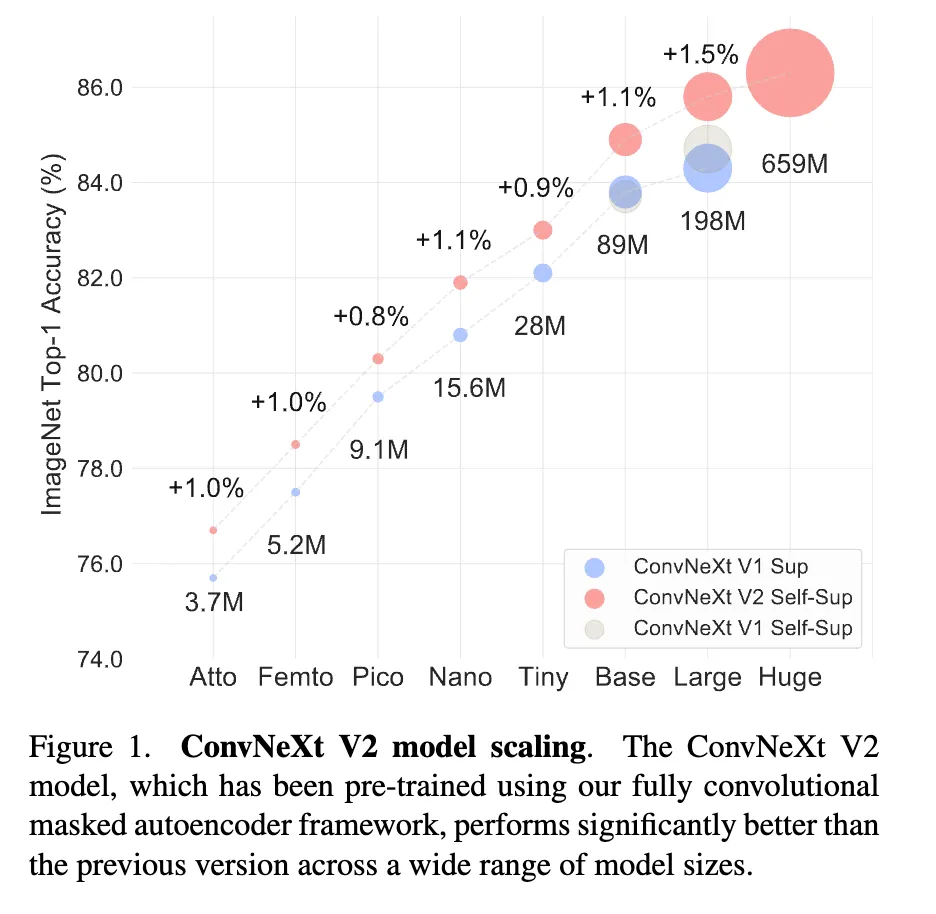
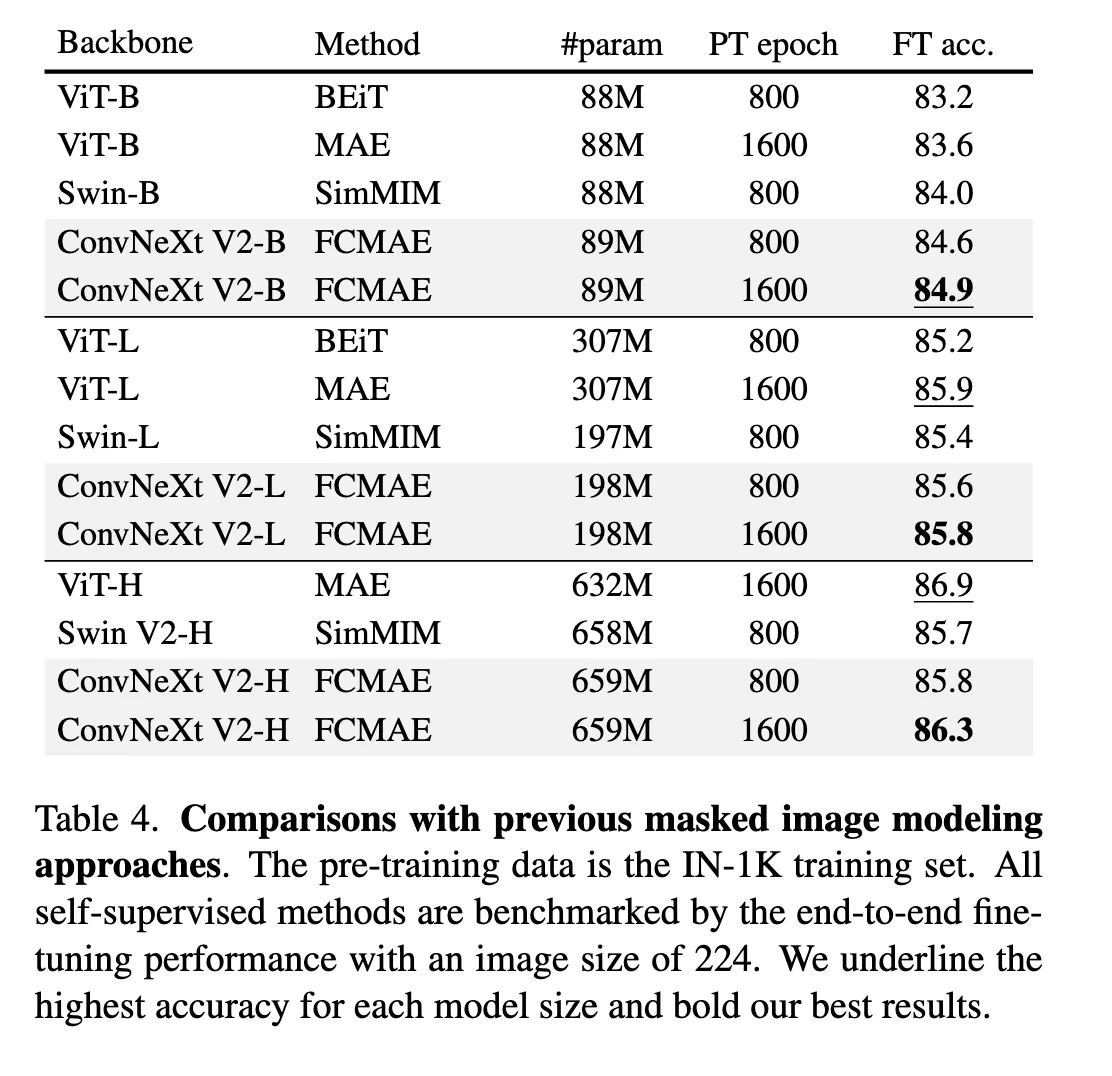
Comparisons with previous methods
绝对数值上和ViT-H这种超大模型还有差距,但是在后面可以看到如果做finetune这个差距就会缩小。
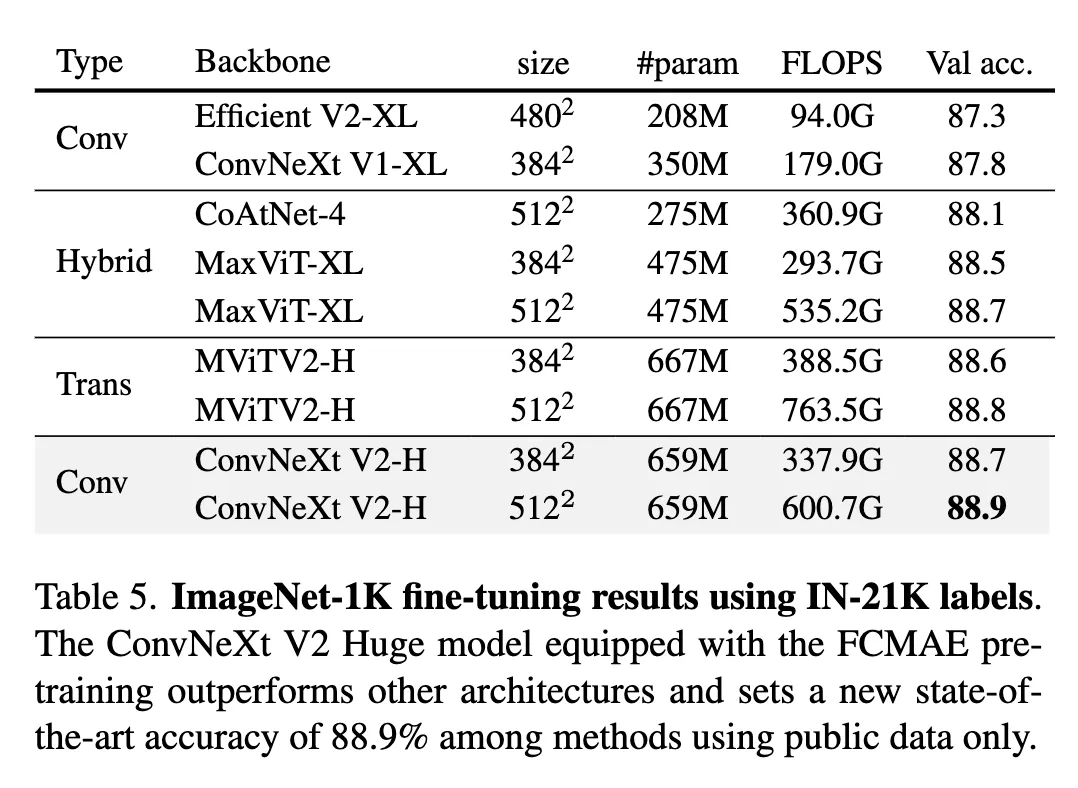
ImageNet-22K intermediate fine-tuning
我们的方法,使用基于卷积的架构,仅使用公开可用的数据(即ImageNet-1K和ImageNet-22K)就创造了新的state-of-the-art准确率。
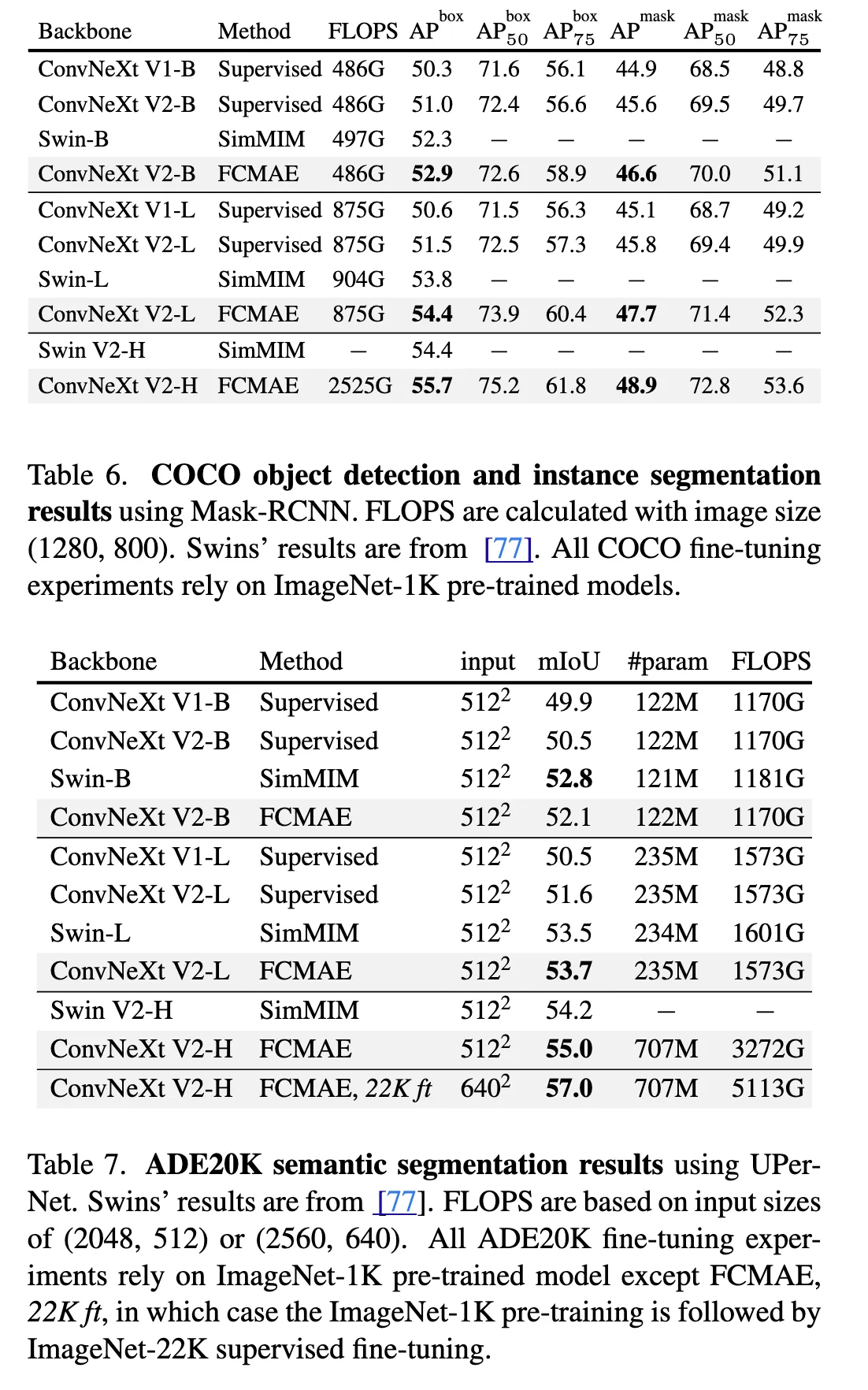
6. Transfer Leaning Experiments
Object Detection and segmentation on COCO
Semantic Segmentation on ADE20K
和ConvNeXt V1的实验对齐。
7. Conclusion
在本文中,我们介绍了一个新的ConvNet模型家族,称为ConvNeXt V2,涵盖了更广泛的复杂度范围。虽然架构变化很小,但它专门设计为更适合自监督学习。使用我们的全卷积掩码自编码器预训练,我们可以显著提高纯ConvNets在各种下游任务中的性能,包括ImageNet分类、COCO目标检测和ADE20K分割。
没有ConvNeXt V1那么惊喜,小修小补的工作。关于Training和Arch需要一起设计的想法和师兄那边印证起来了。中间的操作适不适合SNN化,包括我在Video Stream上能不能做MAE都还需要思考。