BISMO : BI t S erial M atrix M ultiplication O verlay 摘要 : 矩阵乘法是科学和工程中众多应用的关键计算核心,具有丰富的并行性和数据局部性,非常适合高性能实现。许多依赖于矩阵乘法的应用可以使用降低精度的整数或定点表示来提高性能和能源效率,同时仍然提供足够的结果质量。然而,不同应用阶段之间或者依赖于输入数据时可能需要不同精度要求,使得恒定精度解决方案无效。本文介绍了BISMO,一种基于可重构计算的向量化位串行矩阵乘法叠加层。BISMO利用FPGA出色的二进制操作性能,在所需精度和并行性上提供可扩展的矩阵乘法性能。我们对BISMO在一系列参数下资源使用情况和性能进行表征以建立硬件成本模型,并在Xilinx PYNQ-Z1开发板上展示了6.5 TOPS峰值性能。
1.Intro
矩阵乘法是一种很重要的操作,目前的大部分加速器基本提供的是固定精度的矩阵乘法计算,但是新的机器学习技术中有很多采用了mix precision的方法,在传统的固定精度阵列上进行混合精度的计算耗时甚至不支持。 本文设计了BISMO,利用bit serial的方法实现了一种可以对任意精度、任意规模的矩阵进行矩阵乘法计算的加速器。代码开源在[https://github.com/EECS-NTNU/bismo]。
2.Bit-Serial Matrix Multiplication
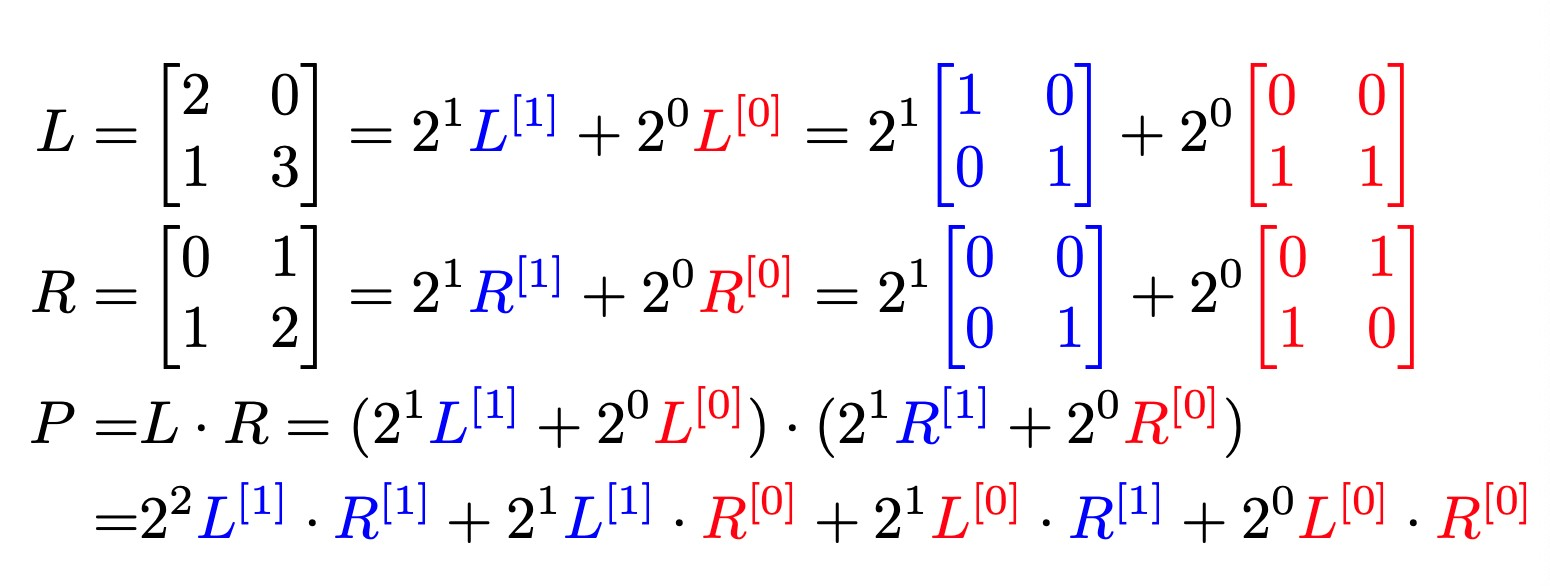
3.The Bit-Serial Matrix Multiplication Overlay
可以对整数和定点数做bit serial的乘法,把数bit slice成多个片以后在不同的阵列上面并行地计算。 BISMO的key features:Precision-scalable,Hardware-scalable,Software-programmable
3.1. working stages
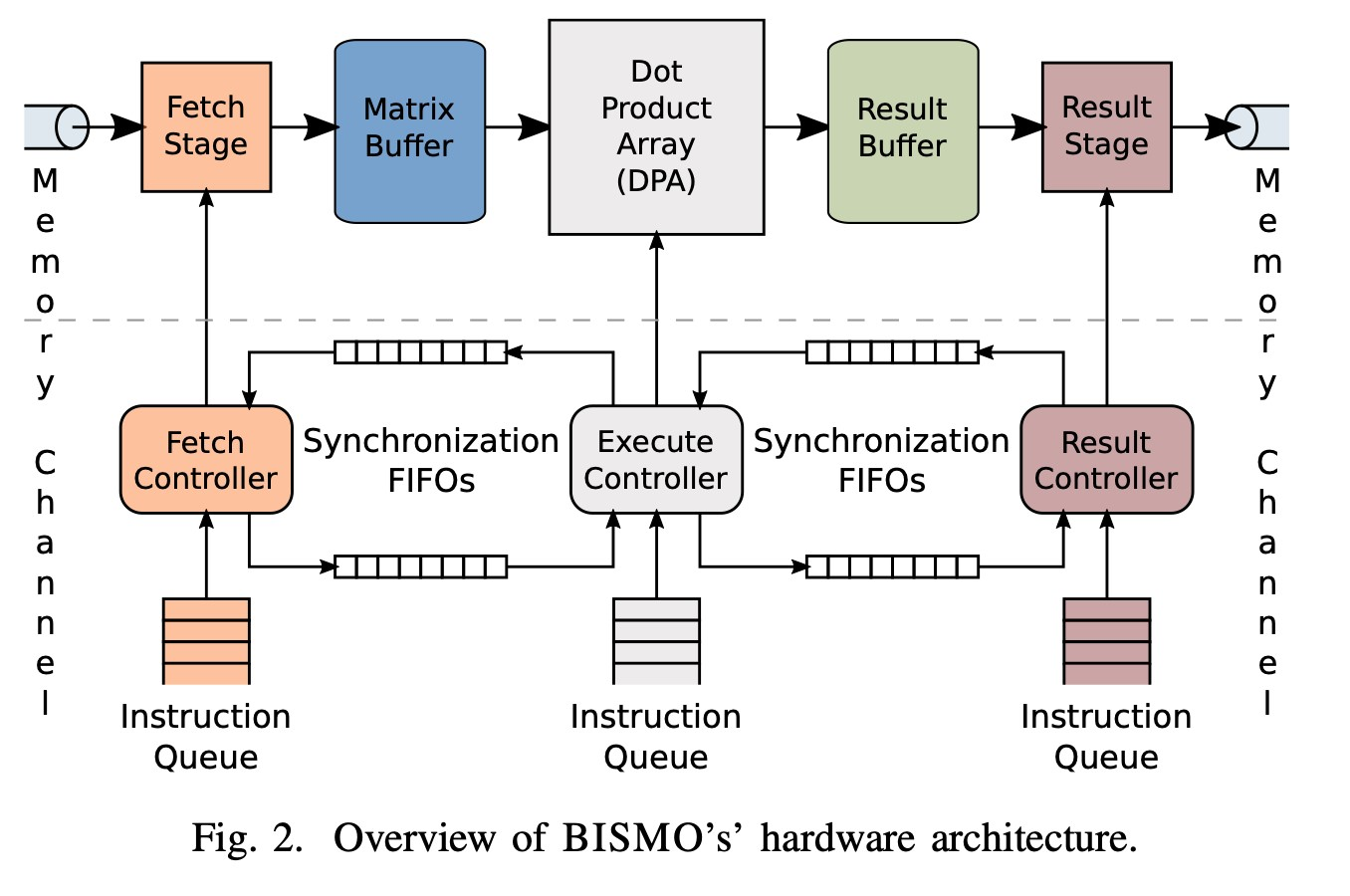
- The Fetch Stage : 靠DMA从Main Memory里面读取需要计算的数据到Stream Buffer里面,然后分块发放到对应的buffer?
- The Execute Stage : 把buffer里的数据输入到DPU进行计算。同一个行/列的DPU会共用对应的Buffer,这种broadcast机制避免了数据的重复复制,提高了并行性。
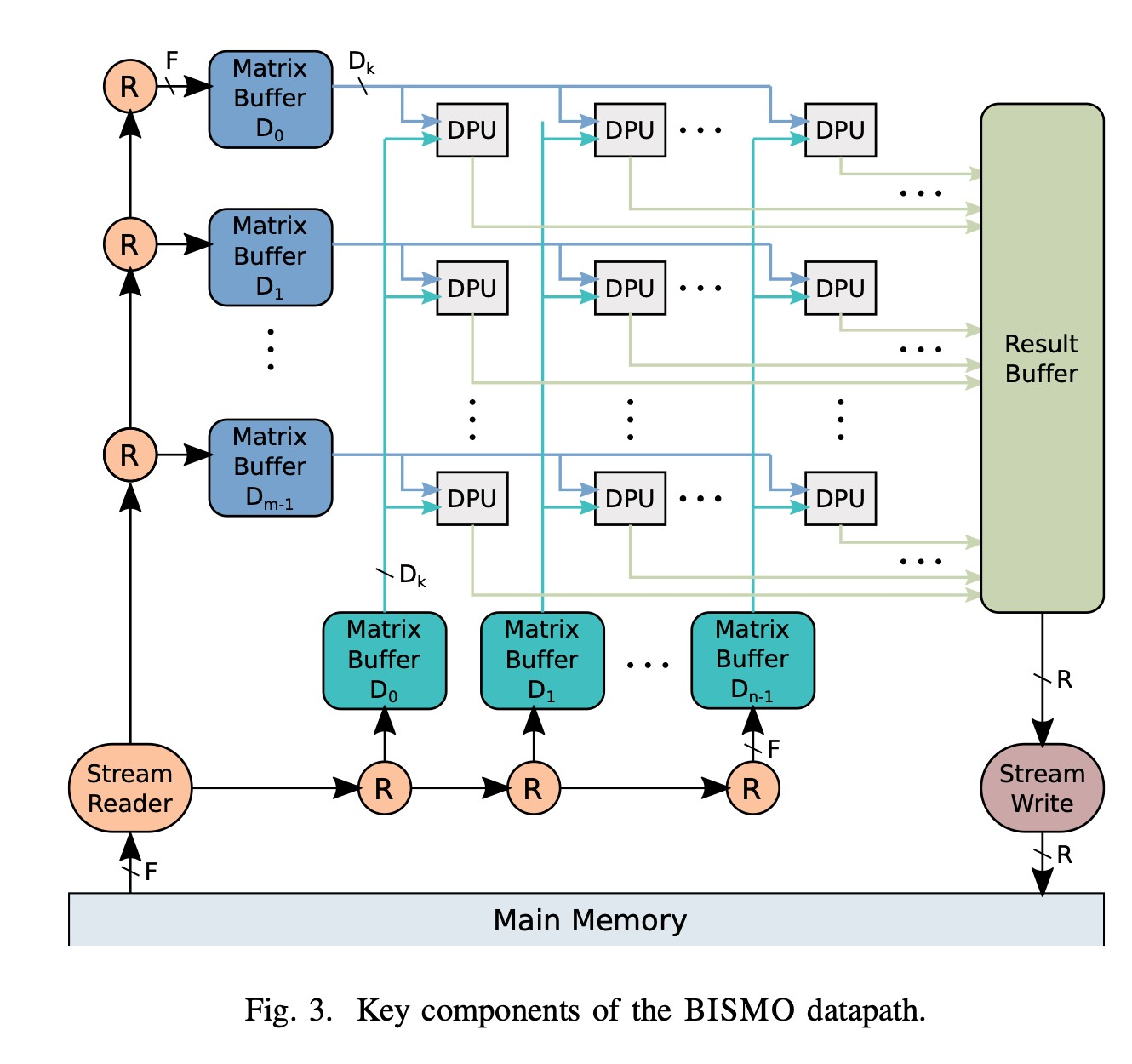
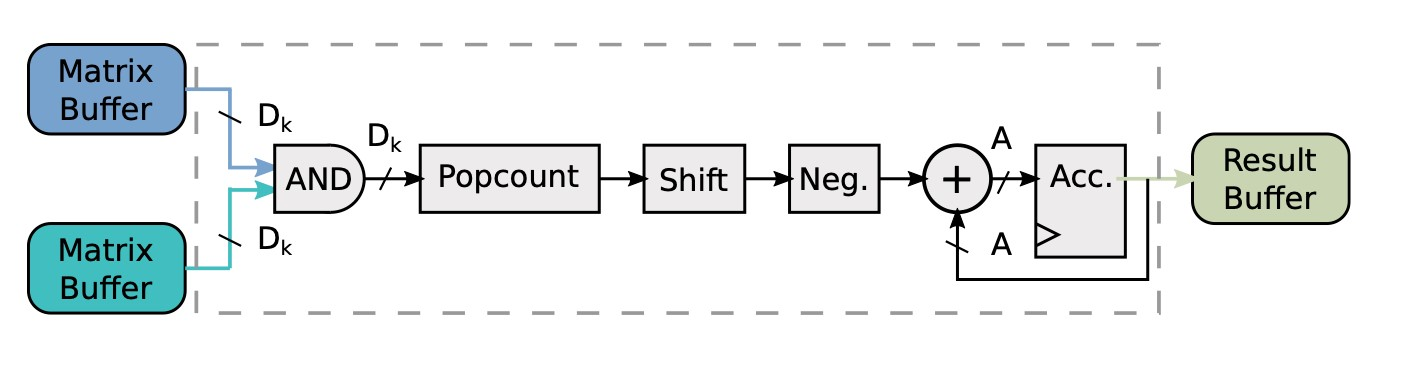
- The Result Stage: 把结果输入到Result Buffer里然后走DMA写回到主存中
3.2. Cost Model
- LUT cost : 详细看一下FPGA原理再补
- BRAM cost
3.3. Programming BISMO
Instructions:

Running Timeline:
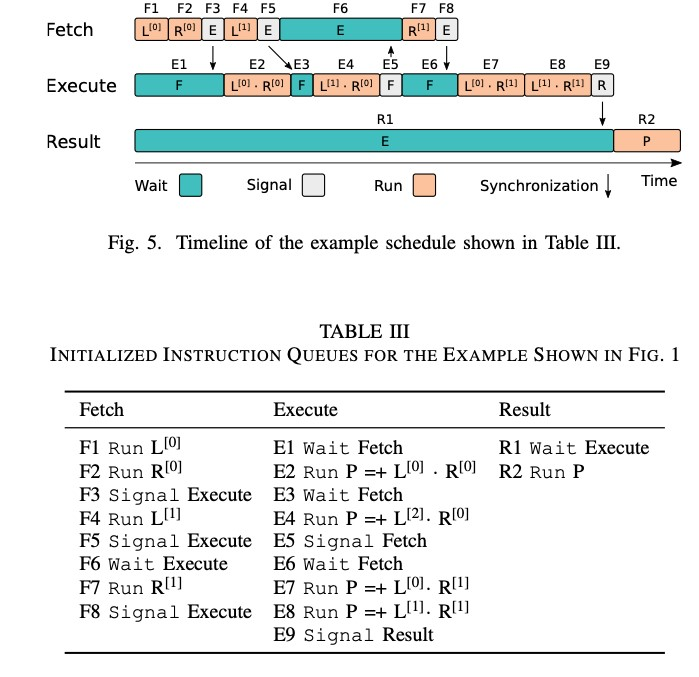
L0, R0都是bit-slice;流水线的形式,在E阶段可以继续F下一次计算要用的数据,通过wait和signal信号实现同步和互斥
4.Evaluation
设备:PYNQ-Z1, Xilinx Z7020 FPGA with 3200 LUTs, 140 BRAMs and 3.2 GB/s of BRAM bandwidth.
4.1. Synthesis Results and Resource Cost
详细看一下FPGA原理再补
4.2. Runtime Performance
bit-packed data layout : 可能多个数值保存在同一个变量中,“bit-packed”
4.2.1. Peak Binary Compute
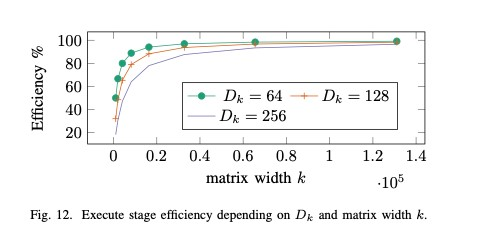
更大位宽/更大同时能算的位数都能提高计算效率,原因比较显然;更大的需要更大的Matrix width ,要保证DPU流水线始终被填满,减少空置等待的时间(F)
4.2.2. Peak Bit-Serial Compute:
这篇论文里面还没有用P2S的专门硬件来做,分析的是bit-serial方式的计算和传统的直接计算之间的差别
4.2.3. Stage Overlap
矩阵规模大的时候整个阵列类似一个流水线的状态,各个stage之间重叠可以提高效率减少cycle数