摘要 :专门的深度学习(DL)加速堆栈是为特定的框架、模型架构、运算符和数据类型设计的,它们提供了高性能的吸引力,但牺牲了灵活性。算法、模型、运算符或数值系统的变化威胁着专用硬件加速器的可行性。 我们提出VTA,这是一个可扩展面对不断演进工作负载的可编程深度学习体系结构模板。通过参数化体系结构、两级ISA和JIT编译器,VTA实现了这种灵活性。两级ISA基于(1)任务ISA,明确协调并发计算和内存任务;(2)微码ISA,在单周期张量操作中实现多种运算符。接下来,我们提出了一个配备JIT编译器的运行时系统,用于灵活代码生成和异构执行,以有效利用VTA体系结构。 VTA已经集成并开源到Apache TVM中,后者是一款先进的深度学习编译堆栈,在不同模型和不同硬件后端上提供了灵活性。我们提出了一个流程来进行设计空间探索,并生成定制化硬件架构和软件运算符库,可以被主流学习框架所利用。我们通过在边缘级FPGA上部署优化的用于对象分类和风格转换的深度学习模型来演示我们的方法。
1.Intro
VTA是为了将快速更新的加速器和快速变化的机器学习两个领域相联系的工作。 Contribution :
- 一种可编程加速器设计,提供两级编程接口:高级任务ISA允许编译器栈进行显式任务调度,低级微码ISA提供软件定义操作灵活性。VTA架构完全可参数化:硬件内部函数、存储器和数据类型可以定制以适应硬件后端要求。
- 可扩展的异构执行运行时系统,通过对微码内核进行即时编译来提供操作灵活性。例如,VTA运行时使我们能够将原始面向计算机视觉设计的VTA功能扩展到支持风格转换应用中找到的运算符,并且无需对硬件进行任何修改。
- 调度自动调优平台,可以优化数据访问和数据重用以快速适应底层硬件变化和工作负载多样性。
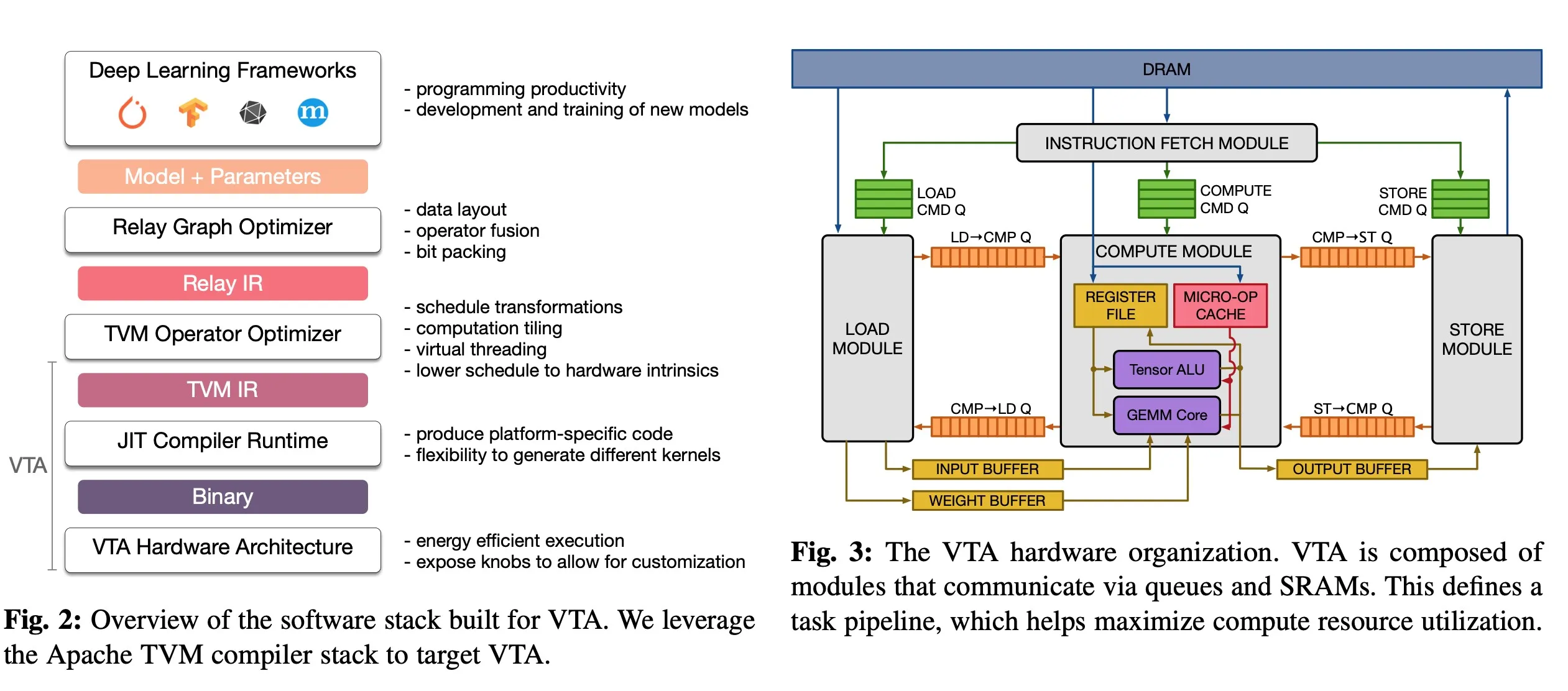
2.VTA Hardware-Software Stack Overview
VTA类似接在TVM的一个后端,上层部分和TVM是一样的,额外增加了JIT Compiler&Runtime和硬件部分的设计
3.VTA Architecture and JIT Runtime
3.1. Hardware Architecture
如图3.支持fetch、load、compute和store四个命令,支持流水线。特点:
- 可参数化,支持修改GEMM的形状、整形精度、SRAM位宽
- 通过流水线实现了latency hiding,实现形式和TVM里面的虚拟线程相对应
- task level ISA
- 有tensor ALU和GEMM两个计算模块;tensor ALU负责element wise的操作,比如加法、激活函数、normalization、pooling等,GEMM做矩阵乘
3.2. JIT Runtime System
中间层,协调CPU和加速器的异构计算,同时把下层抽象成单个TVM后端便于开发;添加中间层还可以做内存管理之类的操作,使得模型不用被一次全部载入到加速器中,“overcome physical limitations”;
4.VTA Hierarchical Optimization
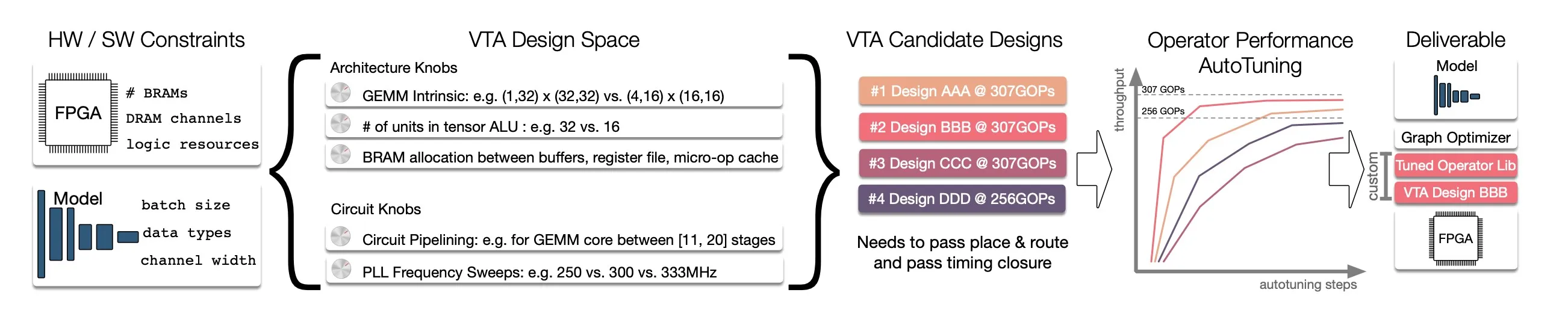
4.1. Hardware Exploration for Varying FGPA Sizes
VTA的GEMM形状、数据类型、ALU分配和电路相关的东西都是可调节的,设计空间很大,优化的软件要能搜索便于布线、性能较高的配置。 具体的配置要根据实际部署的模型运算性质进行调整,比如conv2D如果kernel面积大,按照roofline model描述的算术强度就高,就依赖于计算强度,而kernel很小甚至为1(退化成element wise操作)就更依赖于内存带宽。
4.2. Schedule Exploration for Operator Autotuning
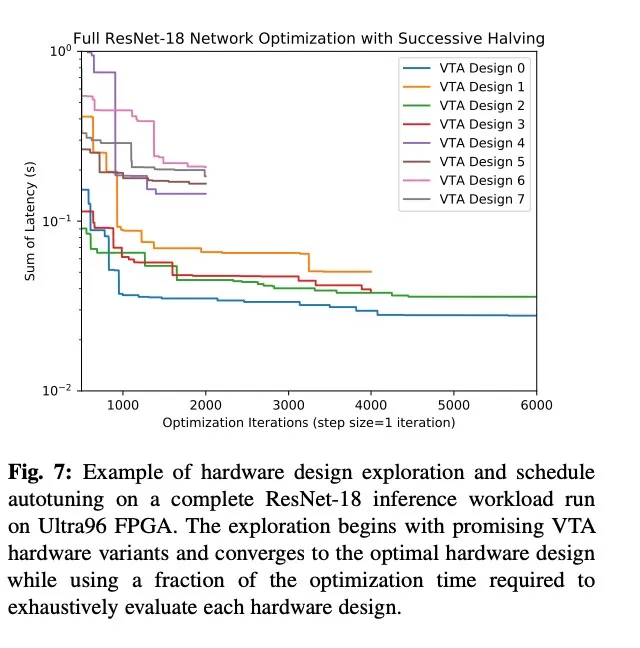
用的TVM之前做的方法,不同的VTA硬件参数本身也属于一个超参数,对这个参数的选择用了基于SuccessiveHalving的方法作为备选项。
- 看一下SuccessiveHalving SuccessiveHalving : 首次迭代验证所有超参数组,平均分配资源,然后选择前x%(一般是前一半,所以叫halving)的超参数组重新迭代;
4.3. Full Network Optimization Case Study