1. Background
Modern EDA work flow:
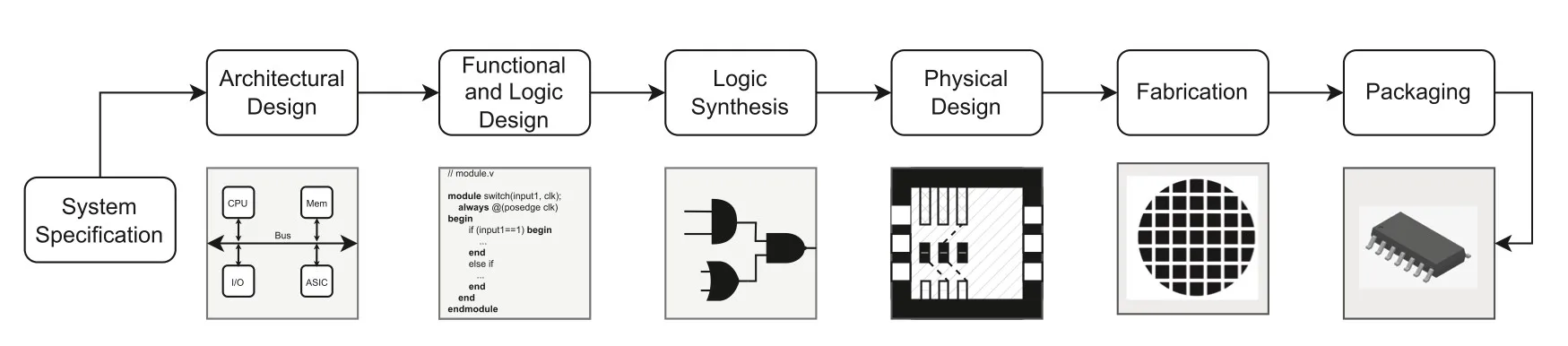
传统的基于启发式搜索或者其他求解器的方法求解的都是NP完全问题,实际表现差,用ML方法更好。在逻辑综合、器件放置、布线、测试、验证等环节都已经引入了机器学习方法,这些环节用传统方法都非常耗时。 电路本质也是一种图,传统机器学习方法处理图都先要对图做Graph embedding,实现输入的降维和规模限制。典型基于random walk的embedding方法在一般任务上表现良好,但是当输入规模很大的时候同样非常耗性能,并且这种embedding忽略了原始图的结构,也不能学习到新的结点类型。 提出图神经网络,将图的邻接矩阵直接作为系统的输入,旨在最大程度地保留图的整体结构信息,对处理图结构的数据应当会有更优秀的效果。
2. Classification
任务上:
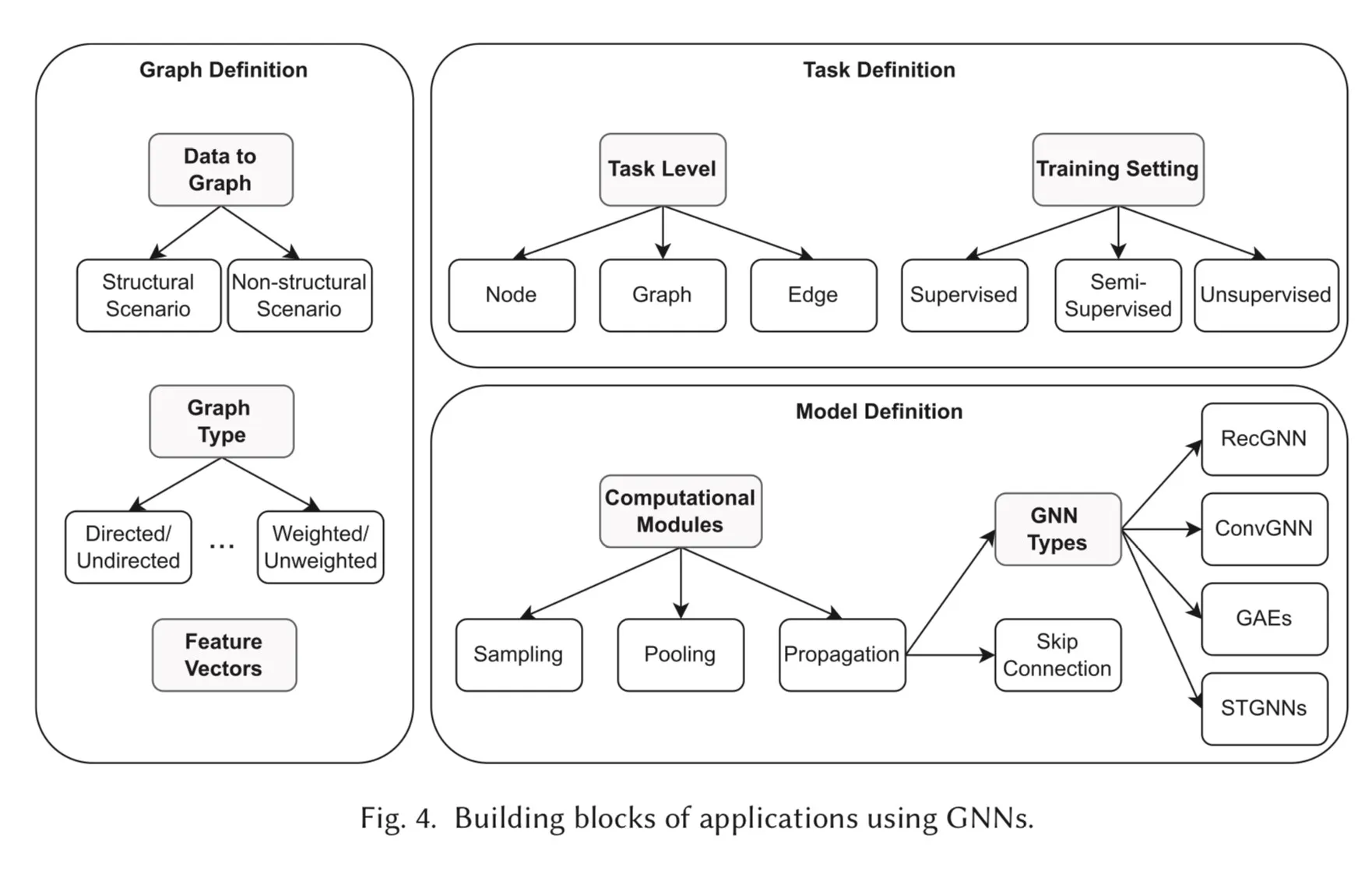
技术上:
2.1. Recurrent Graph Neural Networks
图上的循环神经网络。按照图的连接交换信息更新节点状态, 时刻节点的隐藏向量可以表示为_:_
即节点时刻隐藏向量的状态分别和节点的特征向量、相邻节点的特征向量、相邻边的特征向量以及上一时刻的隐藏向量有关。 按上述方法迭代到收敛状态,但是有的时候达不到收敛的状态,所以会设置一个迭代总次数上限。
2.2. Convolutional Graph Neural Networks
卷积图神经网络,可以从频域角度理解或者从空域角度理解。 频域上来说,图不具有平移不变性,所以可以把卷积认为是做傅里叶变换的过程,在时域上的卷积可以看做在频域上的相乘。频域方法都是基于拉普拉斯特征的。空域的方法和在图像上做卷积类似,只是要注意图中的卷积核的“大小”和图像中不一样,并不是固定的。
2.2.1. GCN
聚合相邻节点特征,做线性变换。若堆叠多层就变成:
缺点:
- 一次要读入整个图,耗显存,处理不了大图
- transductive,只能处理训练中见过的节点类型
2.2.2. GraphSAGE
训练时只保留样本之间的边,包含Sample和Aggregate两个步骤。Sample指如何对相邻节点的个数进行采样,Aggregate指获得相邻节点的embedding之后如何更新自己的embedding。 Sample: 对于一个节点,从它相邻的节点中选择 个,假设采样深度为,还要对选择的节点再进行次相同的采样。这种选择时有放回的,要保证每个节点采样后的邻居数量一致,拼接成了定长的Tensor。 Aggregate: 分为Mean Aggregator、LSTM Aggregator和Pooling Aggregator。其中Mean Aggregator可以写作:
和GCN的做法基本一致,所以也可以分类到卷积图神经网络中。LSTM Aggregator就是对邻居按照一个随机排列组成的tensor做LSTM。Pooling Aggregator可以写作:
通过学习节点的embedding,模型变成了inductive的,并且通过假设相邻节点的embedding应当相似还可以转化成无监督的学习。
2.2.3. GAT
为了给相邻节点之间的权重不同,借鉴类似Transformer的方法加入self-attention机制,写作:
同样可以引入多头的self-attention。
2.3. Graph Autoencoders
无监督,主要在图表示学习和图生成工作应用的比较多。Encoder-Decoder结构,Encoder一般是之前的ConvGNN或者RecGNN,将图转换低维的包含结点结构信息的向量,输入到Decoder中。Decoder通过向量重建图的邻接矩阵表示,学习中要损失函数计算的重建图和原图之间的距离。
2.4. Spatial-Temporal Graph Neural Networks
输入的图是随时间变化的序列,一般方法是建模描述动态节点输入,并且要假设相邻节点之间的相互依赖性。
3. GNN for EDA
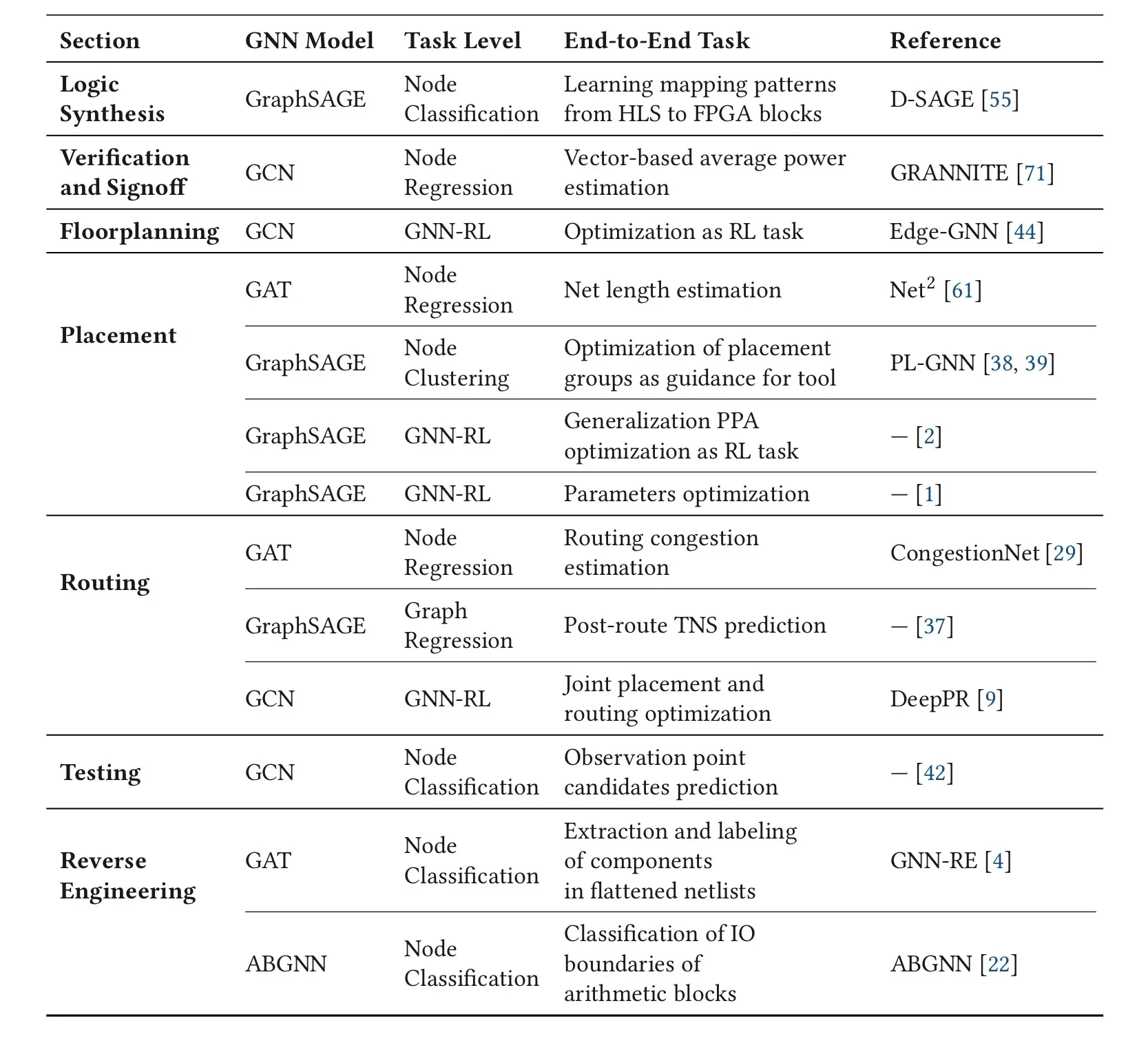
3.1. Logic Synthesis
D-SAGE预测的是HLS部署到FGPA上之后的delay,然后预测node是部署到DSP上还是Lookup Table里面,edge连接的两个点是否部署在相同的设备上。 逻辑综合主要包括哪些步骤?需要后续的学习
3.2. Verification and Signoff
GRANNITE预测的是toggle rate,电平变化的速率,关注的还是结果质量方向的问题。
3.3. Floorplanning
在设计规则的约束下把网表转换为元器件2D grid,马尔可夫过程,适合用RL。
3.4. Placement
RL为主,引入GraphSAGE和GCN帮助提取图特征的也有。
3.5. Routing
从非欧的图连接转换为符合要求、分数最高的2D布线方案。方法比较丰富,有直接产生布线的,也有在布线优化中产生转角关节的。
3.6. Testing
测试的时候不仅要观察最终结果,还需要观察中间过程,但是没有办法直接观察整个电路的工作情况,所以测试的时候需要添加测试点。测试点的选取完全是经验性的,并且添加过多的测试点也会很耗时费力。一种基于GCN的方法将结点分类为是否容易观察到错误两种,保证生成测试点的数量尽可能少的情况下能覆盖大部分错误。
3.7. Reverse Engineering
主要以组件识别和IO boundaries分类为主。
4. Challenges
鲁棒性,可解释性,更复杂的图类型,安全性,训练耗时和数据集问题。在EDA领域,输入规模过大,需要额外的图种类的处理和新结构的设计。 目前的数据基本是由EDA工具在设计过程中生成的,有时候由于生成的数据都具有相同的生成参数,可能会产生bias的数据。
5. Future Works
Transfer learning, Feature information, bigger datasets,…