摘要 : 我们提出了一个易于理解的、可视化的性能模型,为程序员和架构师提供关于改进浮点计算并行软件和硬件的见解。
1.Intro
现在的并行计算硬件(multicore)没有一个很好的衡量性能的模型,文章提出一个insightfu的模型来衡量。
2.Performance Models
现行的方法已经可以预测程序的表现了,但是没有给程序提供改进的方向。
3.The Roofline Model
纵坐标是Attainable FLops/s,横坐标是”Operational Intensity”操作强度,定义为每个bit DRAM流量的操作次数。
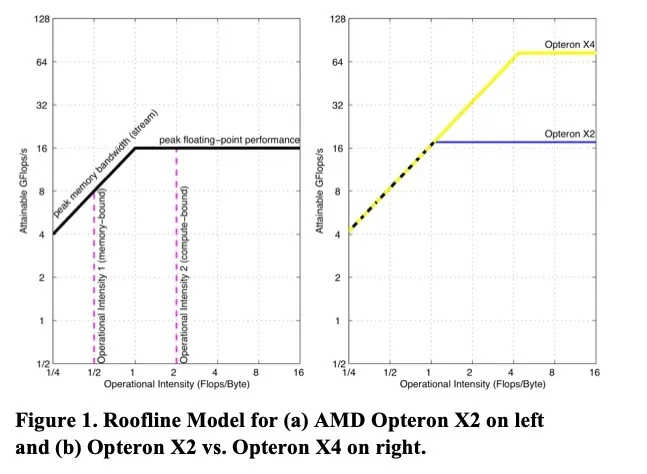
处理器能够计算的速度有上限所以后半部分是水平线;在达到上限之前,操作强度越高,读取同样多的数据处理器可以进行的操作越多,Attainable FLOP/s就越多。
如果一个系统的屋脊点靠左,证明系统的内存带宽很足够,不需要很高的操作强度就可以达到最高的算力,反之则证明带宽不足。
4.Adding Ceiling to the Model
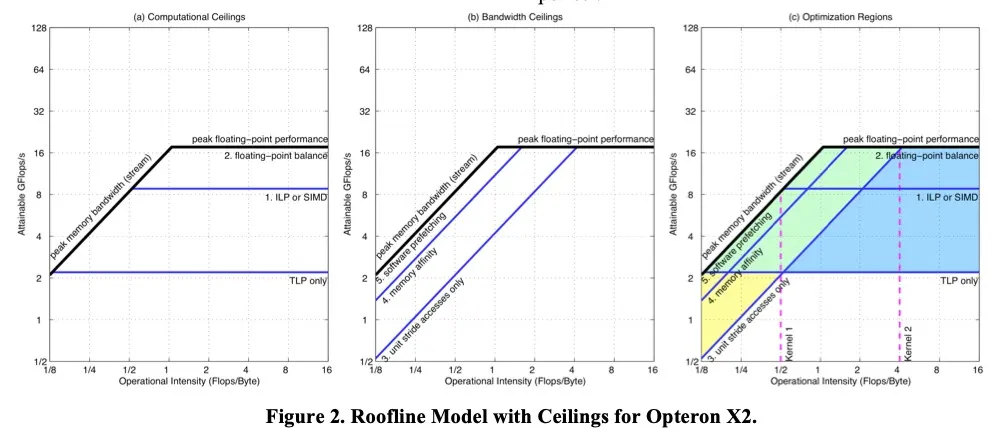
通过一个标准程序测试不同的优化会带来什么样的影响,左边两张图合成了第三张图。后续的程序测试就可以看是落在了第三张图的哪个区域,来决定是需要优化内存读写相关的内容还是提高计算相关的内容。
5.Tying the 3Cs to Operational Intensity
操作强度在一个程序中不一定是一个固定值,除了程序本身的波动之外,还有可能是查找缓存失败等其他可以避免的因素导致操作强度降低。对于这些问题需要尽力消除。
6.Demonstration of the Model
在四个多核CPU上跑了实验,证明了Roofline Model的有效性