摘要 :有越来越多的需求将机器学习引入各种硬件设备。当前的框架依赖于特定供应商的操作库,并针对一小部分服务器级别的GPU进行优化。将工作负载部署到新平台——如手机、嵌入式设备和加速器(例如FPGA、ASIC)——需要大量手动工作。我们提出了TVM,这是一个编译器,通过暴露图层次和运算符层次的优化来实现深度学习工作负载在不同硬件后端上具有可移植性的性能。TVM解决了与深度学习相关的优化挑战,例如高级运算符融合、映射到任意硬件原语以及内存延迟隐藏等问题。它还通过采用一种基于学习的成本建模方法自动优化低级程序以适应硬件特性,从而快速探索代码优化。实验结果表明,TVM在各种硬件后端上提供了与最先进、手动调整库相竞争的性能,包括低功耗CPU、移动GPU和服务器级别GPU。我们还展示了TVM针对新型加速器后端(如基于FPGA 的通用深度学习加速器)进行目标设置的能力。该系统已经开源,并在几家大型公司内部使用中。
1.Intro
模型被部署在内存组织、计算单元各不相同的设备上,需要进行优化。传统的TF、Torch之类的方法依赖计算图进行优化,层次太高 ,无法处理特定硬件后端算子级别的优化和转换,并且不好移植。
需要实现一个,从现有框架中获取深度学习程序的高级规范,并且为各种硬件后端生成底层优化代码的编译器,有如下挑战:
- 利用特定的硬件功能与抽象,包括对data layout、内存层次或者对简单加速器中的调度从而隐藏访存延迟等;
- 优化空间大,比如循环展开、顺序调整、tiling等,搜索空间很大,直接作为黑盒(不考虑关系)进行搜索成本太高,但为现代硬件设计一个通用的cost model又很难;
TVM为解决这些挑战提出的三个方法:
- Tensor Expression Language
- Automated program optimization framework & ML-based cost model
- Graph Rewriter
Contributions :
- 确定了在不同硬件后端上为DL workload提供性能可移植性时所面临的主要优化挑战。
- 引入了利用跨线程内存重用、新颖的硬件指令和隐藏延迟的新型调度原语。
- 提出并实现了一个基于机器学习的优化系统,可以自动探索和搜索优化张量运算符。
- 构建了一个端到端的编译和优化堆栈,允许将高级框架(包括TensorFlow、MXNet、PyTorch、Keras、CNTK)中指定的深度学习工作负载部署到不同的硬件后端(包括CPU、服务器GPU、移动GPU和基于FPGA加速器)。开源TVN已经在几家大公司内投入使用。
- 使用真实workload对TVM进行评估,在服务器级别GPU、嵌入式GPU、嵌入式CPU和自定义通用FPGA加速器上进行。实验结果显示,TVM在各种后端上具有可移植性,并且相较于由手动优化库支持的现有框架,其速度提升范围从1.2倍到3.8倍不等。
2.Overview
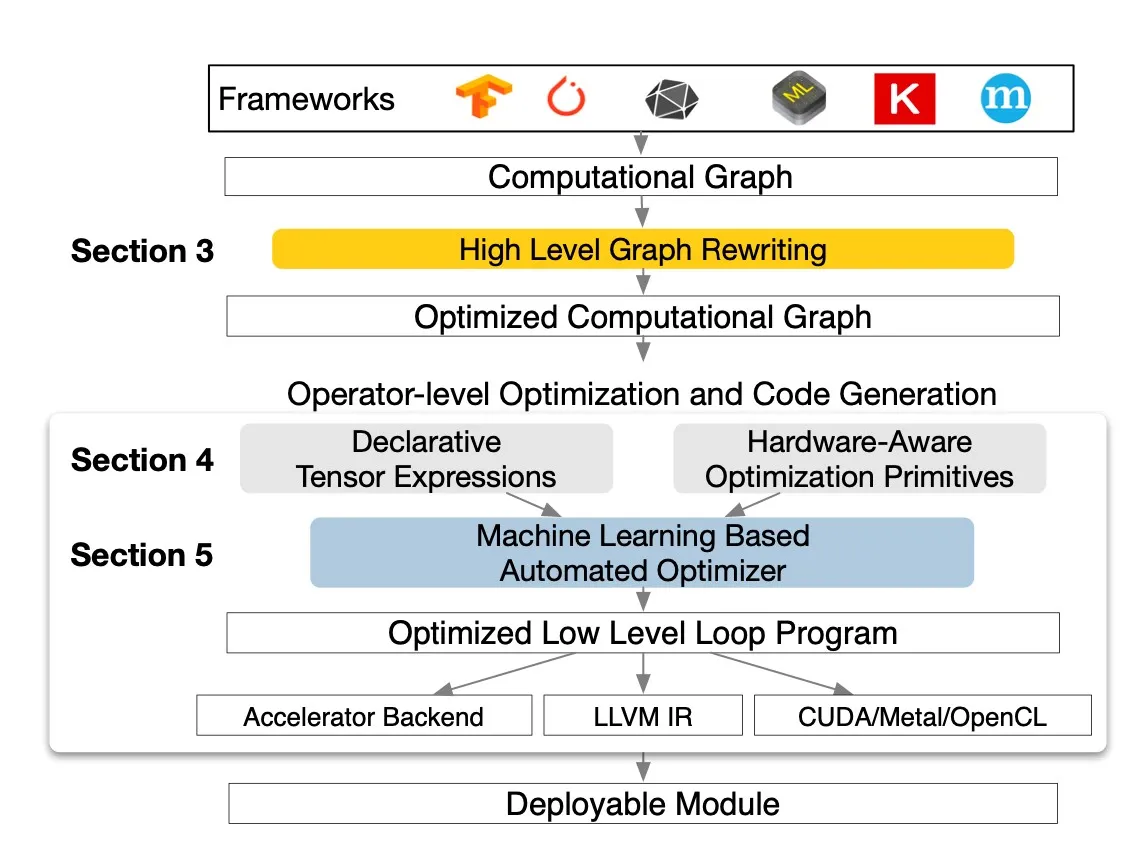
从ML frameworks获得模型,转换为计算图,然后进行graph-level的优化、operator-level的优化,然后codeGen输出到对应的后端
3.Optimizing Computational Graphs
TVM优化的方法:operator fusion、constant-folding、static memory planning pass、data layout transformations…
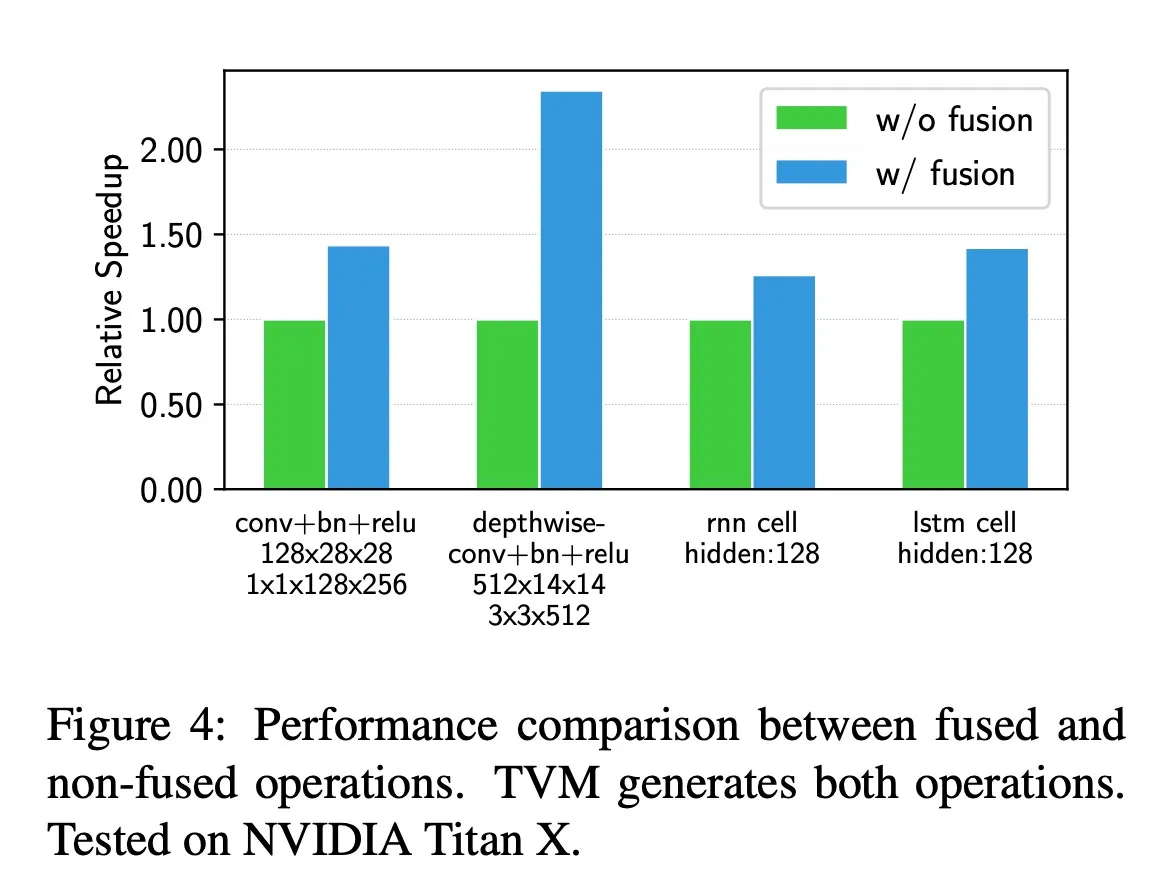
3.1. Operator Fusion
将多个运算结合成一个,从而避免保存中间结果的访存,减少运行时间。算子可以分为
- injective,element-wise的算子,比如add
- reduction,比如sum
- complex-out-fusable,在输出上可以融合element-wise算子的算子,比如conv2d
- opaque,无法融合的,比如sorts
3.2. Data Layout Transformation
目标是将计算图转换为可以更好利用内部数据结构在目标硬件上执行的计算图。首先需要指定每个算子的“首选data layout”,然后根据一系列约束条件调整data layout。
上面这些high-level的图优化都可以提高效率,但是实际上效果取决于运算库的支持。只有少量框架支持算子融合,而随着算子数量增加,data layout、数据类型 、加速器指令数量都会快速增加,如果要求框架对于所有增加的算子、后端都编写相应的kernel是不现实的。
4.Generating Tensor Operations
4.1. Tensor Expression and Schedule Space
Tensor expression:

指定了输出tensor的形状和如何计算的表达式。 tensor expression里面避免出现循环之类的结构,是为了将计算和调度解耦。
Scheduling: scheduling的过程是增量地applying basic transformation,中间要保证逻辑等价性。

4.2. Nested Parallelism with Cooperation
一般的方法是递归地切分任务成子任务从而提高并行性,线程之间不共享内存,称为“shared-nothing nested parallelism”。 另一种办法是让多个thread一同取他们需要的所有数据,并且共享这组数据,提高了数据的利用率与并行性。要实现这种办法TVM引入了内存作用域的概念,便于在调度空间中标记计算阶段。

- barrier有点没看懂,待查
4.3. Tensorization
DL负载基本可以分解成GEMM或者conv,所以现代处理器正在逐步添加对于这些操作的支持。利用这些支持为编译调度带来了新的挑战。同时,TVM不能只支持一种固定的(特定硬件的)操作原语,因为硬件正在不断更新、而TVM支持多种硬件。TVM的设计需要一种可拓展的解决方案。 TVM将算子的实际操作与算子声明进行的操作相分离。下面是一个GEMM8*8的tensor定义和实际操作。 ![[Pasted image 20230831154233.png]]
4.4. Explicit Memory Latency Hiding
通过将内存操作和计算相重叠,隐藏内存读写的延迟。在不同硬件上实现内存延迟隐藏的方法是不同的,需要根据硬件后端采取不同的策略。通过”decoupled”的方式实现延迟隐藏:
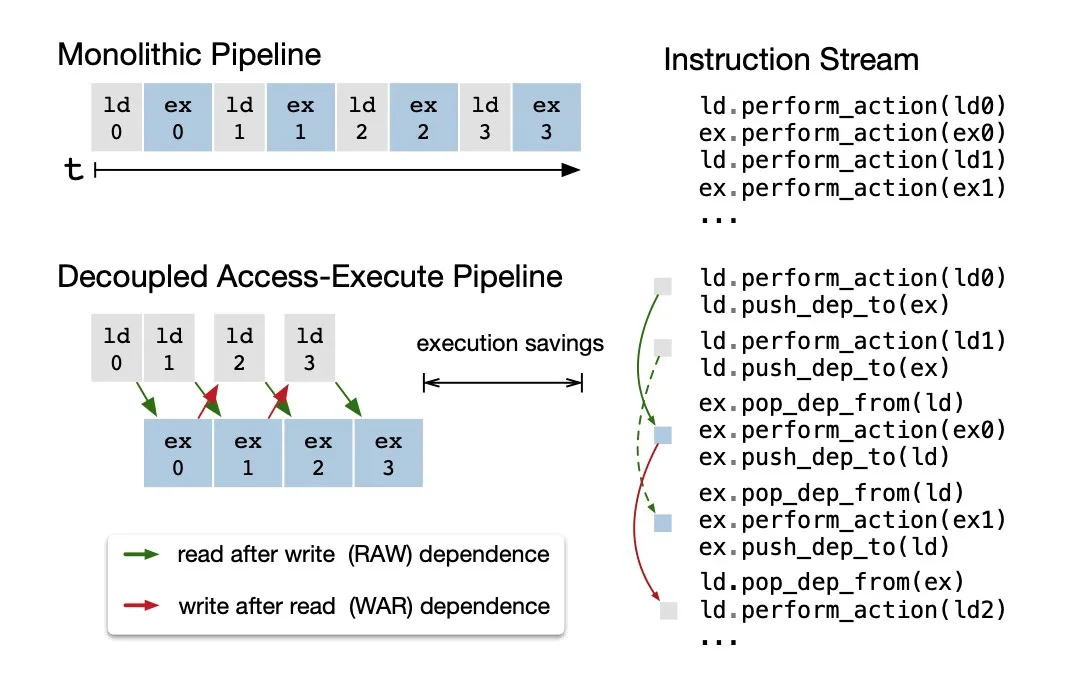
- 具体看一下decouple的东西
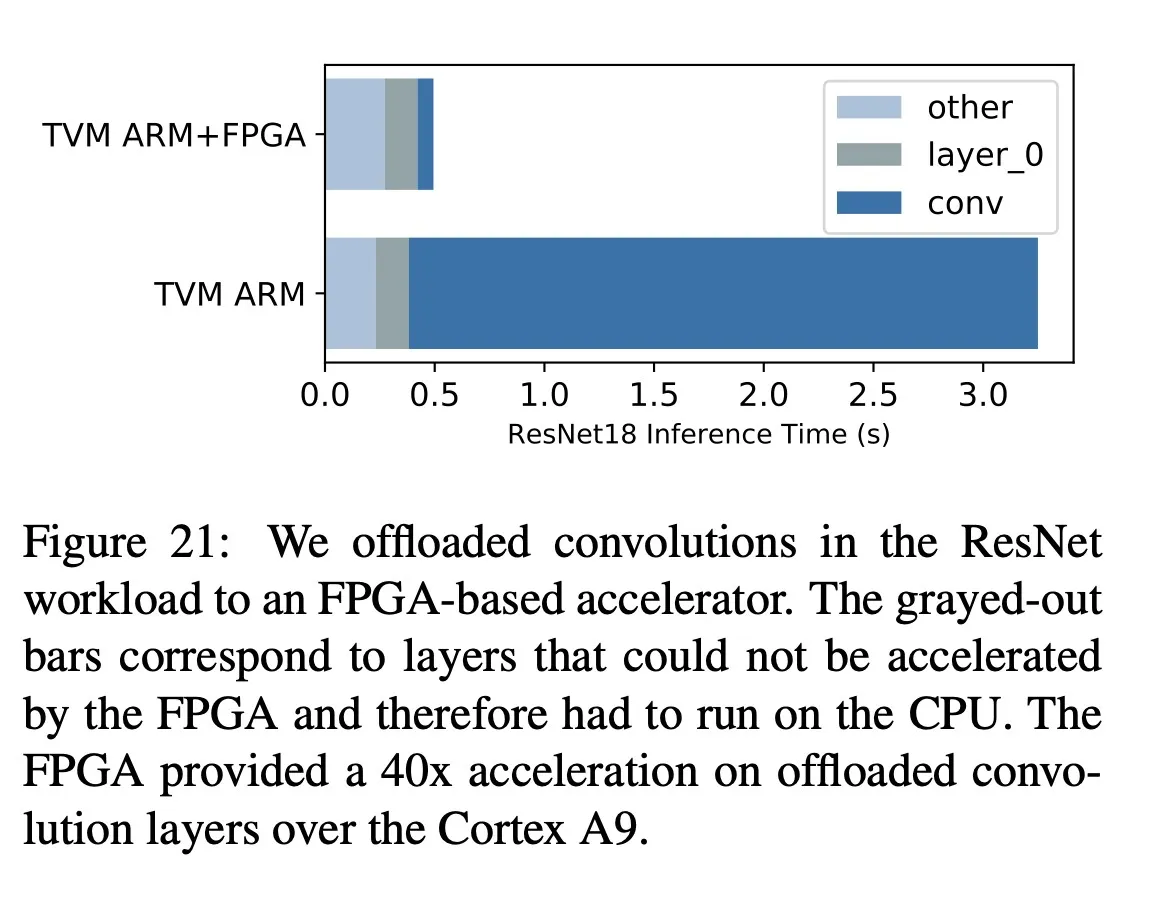
Hardware Evaluation of Latency Hiding : 在FPGA上跑ResNet检查每一层的加速情况
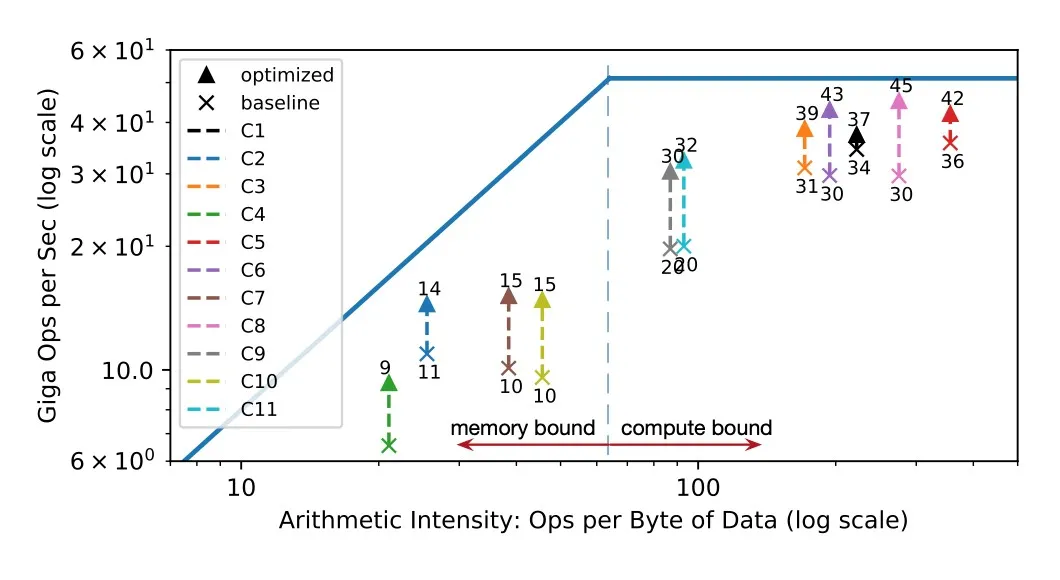
在添加了latency hiding机制之后每层都更靠近roofline了,证明了有效性。
5.Automating Optimization
TVM为每层针对特定输入形状和布局创建专用算子,系统需要选择调度优化以及特定于优化的参数。TVM构建了一个自动调度优化器,主要包括一个提出有前景的新配置方案的explorer和一个预测给定配置性能的模型。
5.1. Schedule Space Specification
给出API,让开发者可以规定哪些量是优化过程中可以变化的。同时还为硬件后端创建了通用的主模版,主模版可以从tensor expression中提取可能的优化量。
5.2. ML-Based Cost Model
讲的内容跟intro里面差不多,额外讲了关于优化过程中要考虑speed和quality的tradeoff。 参数预测用过TreeRNN和XGBoost,两者预测质量相似,但是XGBoost速度将近为两倍并且训练时间少的多。
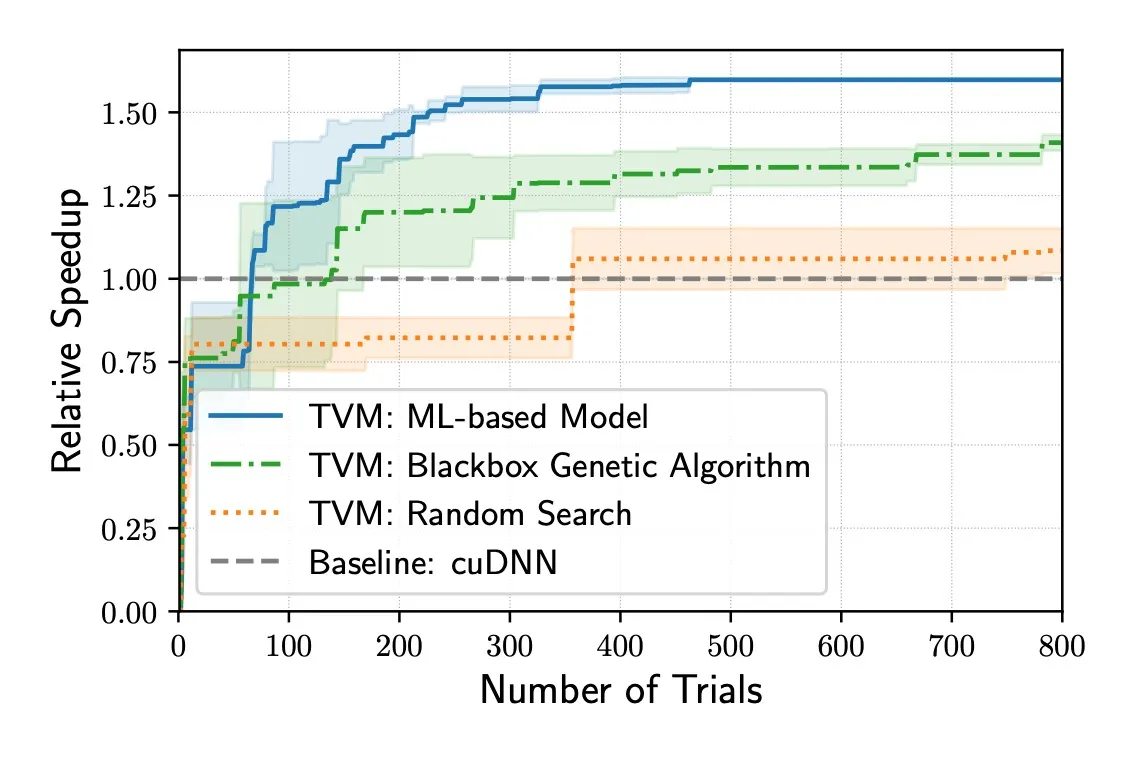
5.3. Schedule Exploration
用前面获得的Cost Model,模拟退火去搜一个比较好的config。
5.4. Distributed Device Pool and RPC
分布式计算相关,没怎么仔细讲
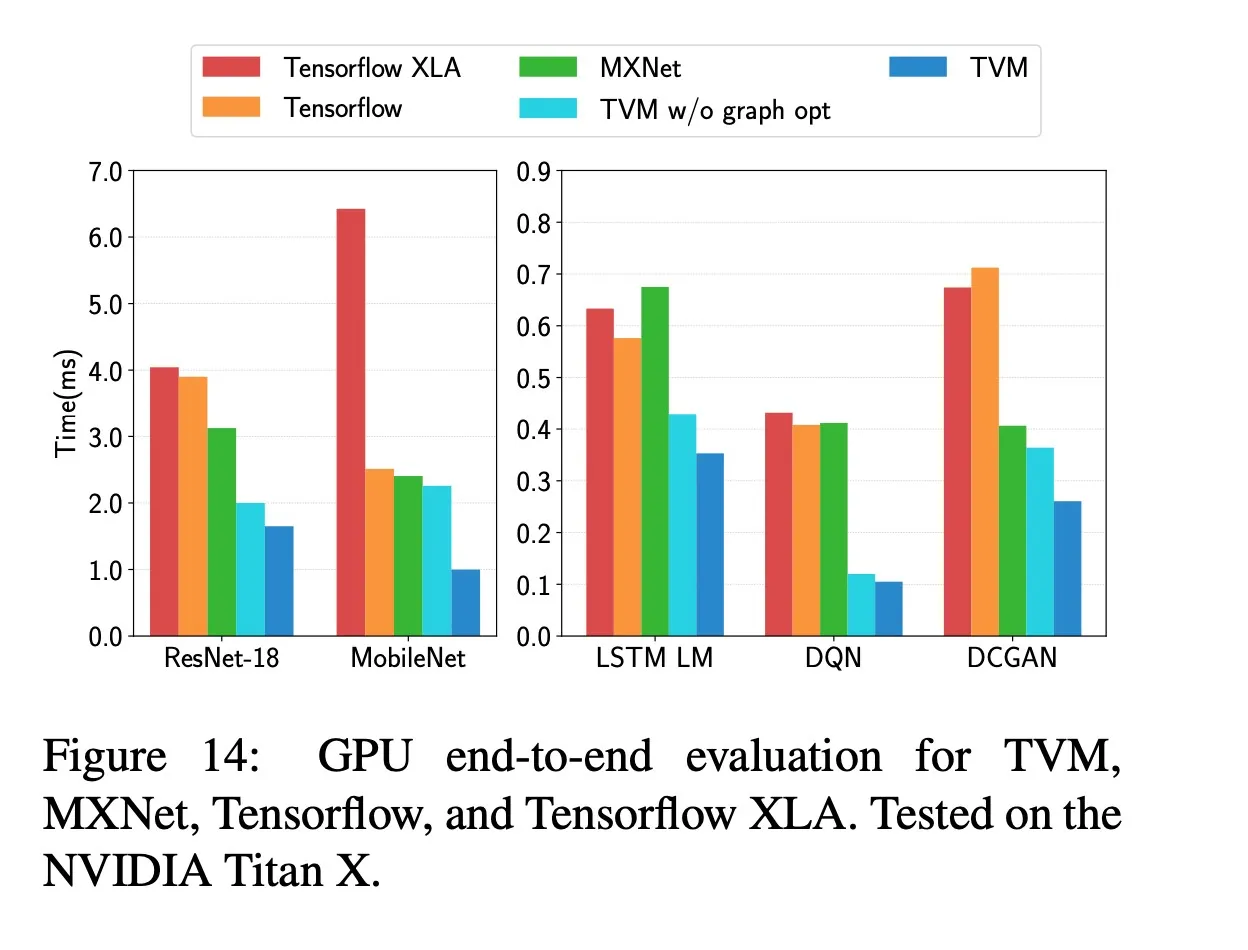
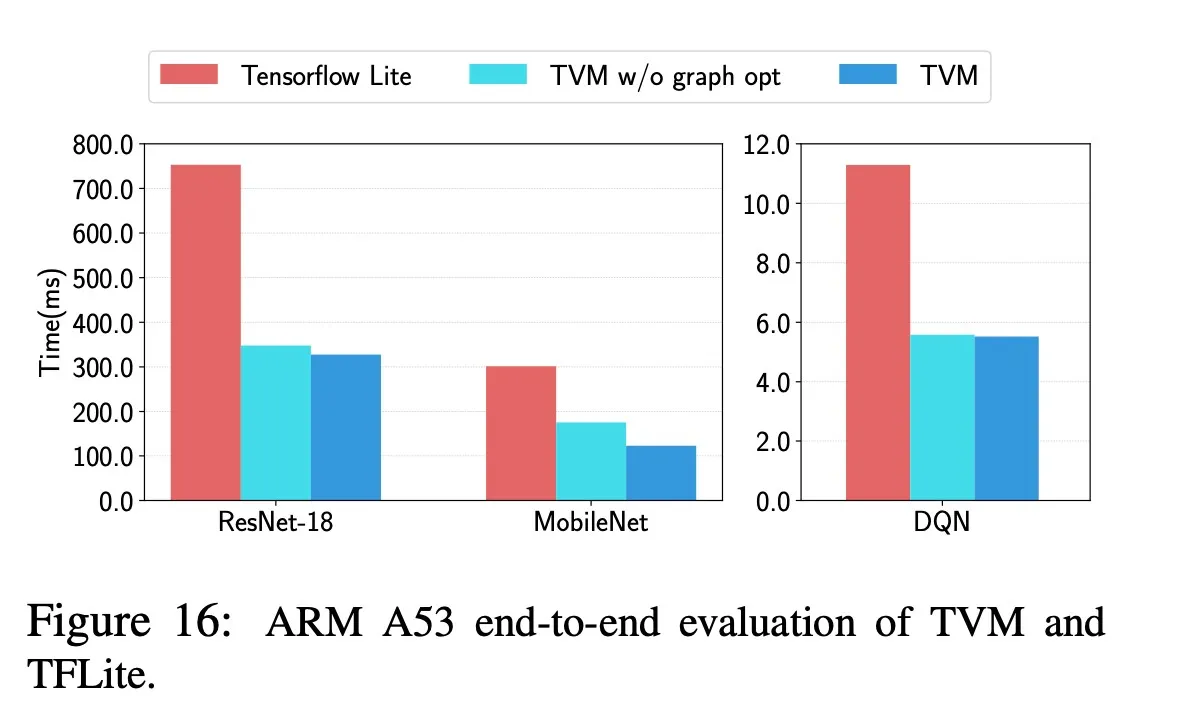
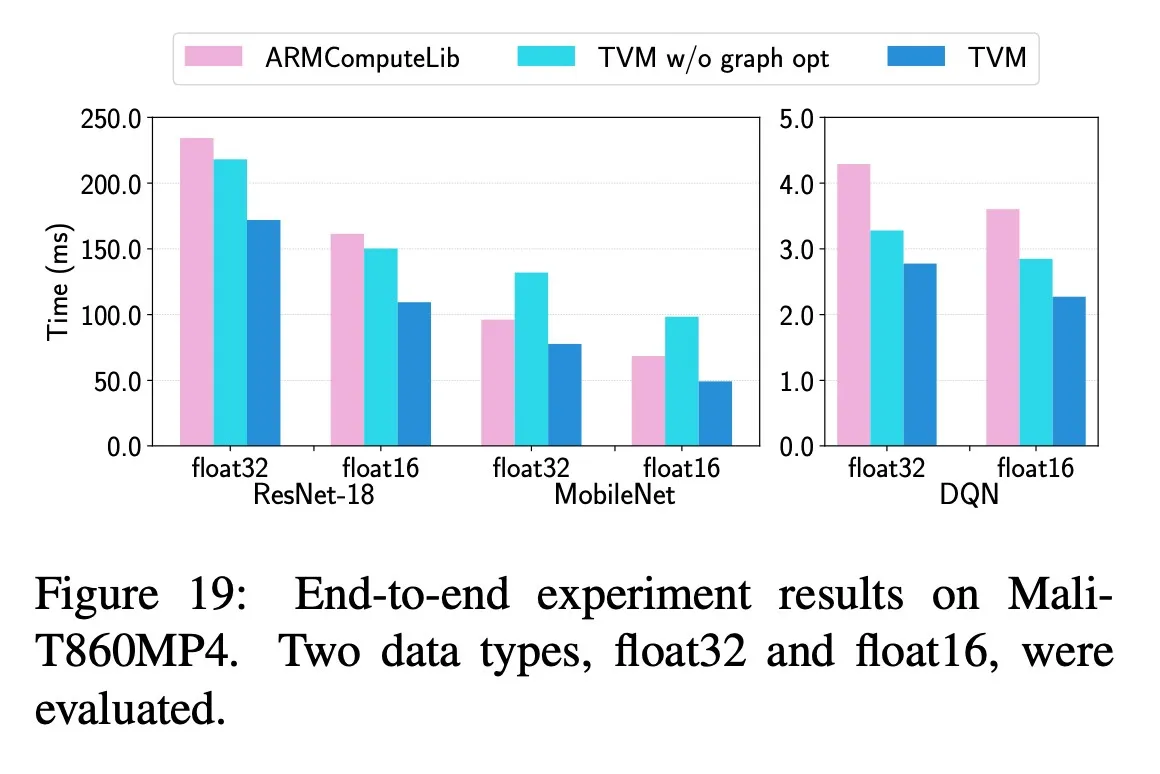
6.Evaluation
questions:
- Can TVM optimize DL workloads over multiple platforms?
- How does TVM compare to existing DL frameworks(which rely on heavily optimized libraries) on each back-end?
- Can TVM support new, emerging DL workloads(e.g., depthwise convolution, low precision operations)?
- Can TVM support and optimize for new specialized accelerators? 分别在Sever-class GPU、嵌入式GPU、嵌入式CPU和加速器上做了测试,测试了ResNet、MobileNet、LSTM LM、DQN、Deep Convolutional Generative Adversarial Network