1.Intro
对BISMO: A Scalable Bit Serial Matrix Multiplication Overlay for Reconfigurable Computing 的改进,引入了P2S模块+FGPA上的优化+阶段调度的优化+LUT的优化
2.Background: Bit-Serial
改进的思想:内存提供的位顺序与加速器期望接收到他们的顺序要尽量一致,保证内存带宽尽量被高效利用。 传统方法计算的时候一个元素的所有bit都是连续的,因为所有bit是在一次处理过程中被同时用到的,data layout 类似;基于Bit-Serial的方法每次处理的是很多元素的同一个位,输入的时候就要尽量保证data layou变成的形式。 为了实现这种bit-serial的data layout,引入了parallel-to-serial的新模块。
3.The Bit-Serial Matrix Multiplication Overlay
3.1. Overall
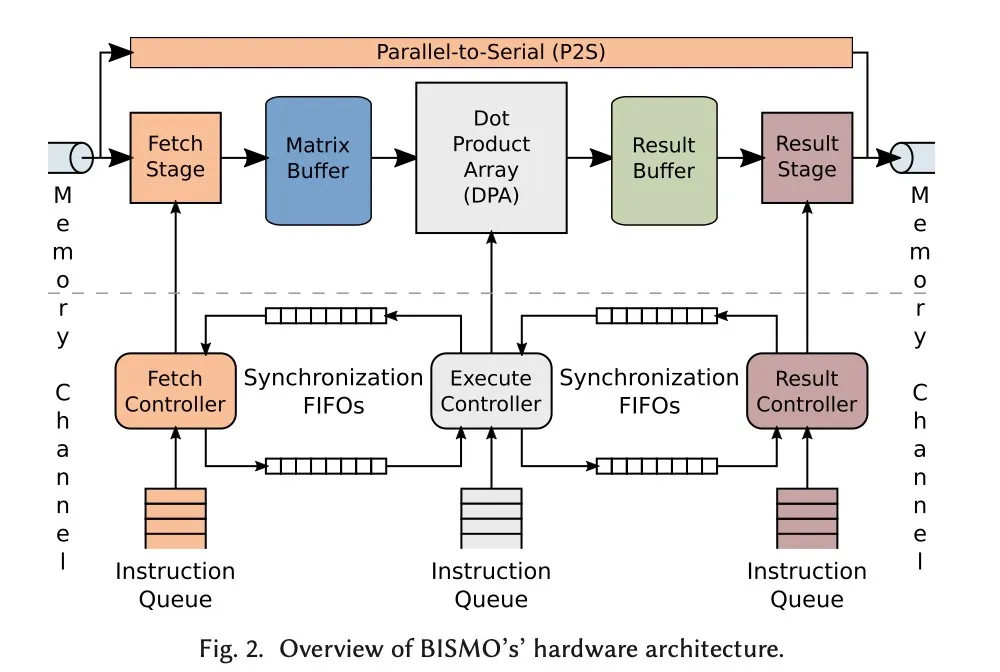
新结构里面多了一个P2S模块,“as an optional, standalone accelerator”。
3.2. the Dot Product Unit DPU
电路上的优化,没看懂
3.3. Bit-Parallel to Bit-Serial Matrix Transformation
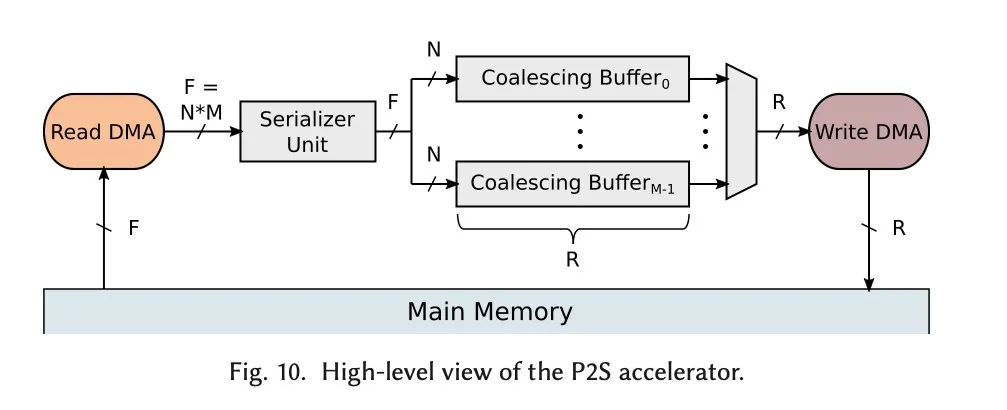
“The total number of coalescing buffers defines the maximum supported precision M of the bit-parallel input matrix and is specified at synthesis time.” DMA读出来的数据按bit放入Buffer中,就是第i位,M的大小决定了P2S模块支持的最大精度。
3.4. Cost Model
和BISMO原文一样从LUT和BRAM两个方面分析
3.5. Programming BISMO
加了一个Running P2S指令,P2S是从DRAM读出再写回DRAM,和BISMO本身完全没有交互。