摘要: 本文并不试图设计一种在视觉识别方面表现最先进的方法,而是探讨一种更高效的方式来使用卷积以编码空间特征。通过比较最新卷积神经网络(ConvNets)和视觉Transformers的设计原则,我们提出利用卷积调制操作来简化自注意力机制。我们证明,这样的简单方法可以更好地利用嵌入在卷积层中的大卷积核(≥7×7)。基于所提出的卷积调制,我们构建了一系列分层的ConvNet,称为Conv2Former。我们的网络简单易懂。实验结果表明,Conv2Former在ImageNet分类、COCO目标检测和ADE20k语义分割方面,都优于现有流行的ConvNet和视觉Transformer,比如Swin Transformer和ConvNeXt。
1. Intro
近期,有一项有趣的工作ConvNeXt显示,通过对标准ResNet进行现代化改造,并采用与Transformer类似的设计和训练策略,ConvNets甚至可以比一些流行的ViTs表现更好。
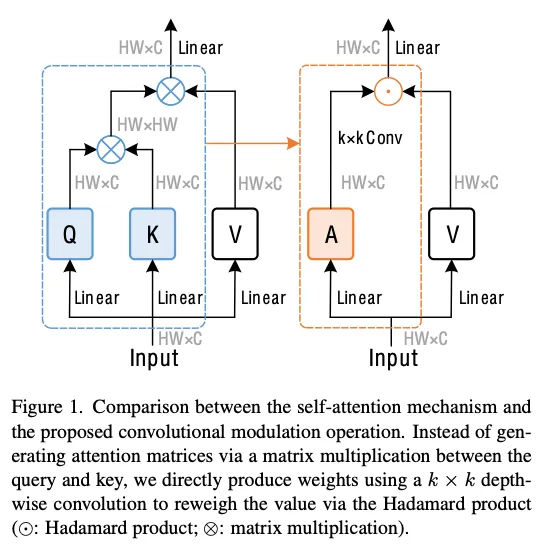
self-Attention是通过加权求和所有位置来计算每个像素的输出,本文尝试通过大卷积核的输出和”value representations”做Hadamard逐元素乘积来模拟。本文将这种操作称为”Convolutional Modulation”。
主要还是想利用Full Conv Net来避免图片增大的时候,计算复杂度用ViT类模型会变成二次方。
2. Related Work
2.1. Convolutional Neural Networks
更新的ConvNet工作开始关注大卷核来提升性能,比如VAN用DS Conv + 空洞卷积分解大的Kernel。
2.2. Vision Transformers
2.3. Other Models
基本就是混合ViT + Conv或者在ConvNet中间塞Attention,如MobileViT等。
3. Model Design
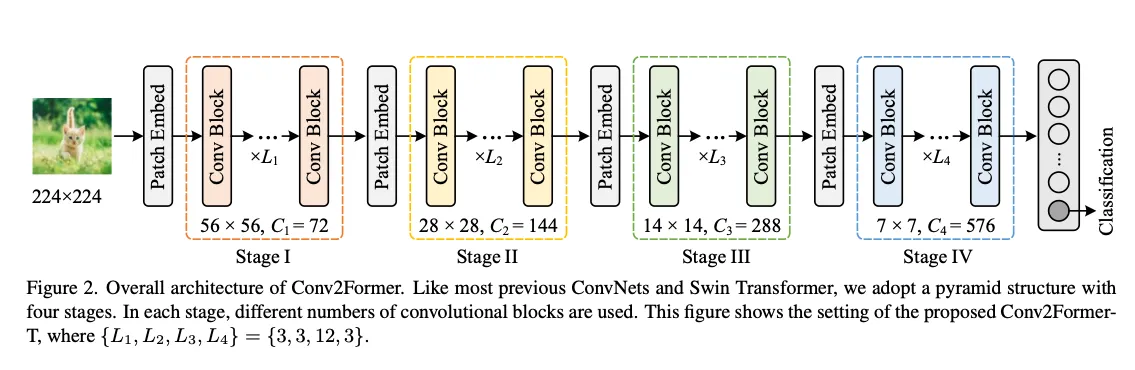
3.1. Architecture
Overall architecture
类似ConvNext/SwinFormer的结构。

Stage configuration
1 : 1 : 3/9 : 1,但是可能有微调(见表1)。文章观察到,小模型(<30M参数)中深度更大的效果更好,如表2.
3.2. Convolutional Modulation Block
也包括一个Self-Attention + FNN的组合。
Self-attention
输入序列长度为,self attention通过linear得到,其中。输出是基于相似度得分(self attention中就是)对做加权求和得到的:
Convolutional modulation
避免用上面的方式计算得分,而是使用一个的深度可分离卷积、逐元素Hadamard乘积构造注意力:
这个操作使得处的像素能和周围的像素相关联,然后用linear层完成channel之间的信息交互。
Advantage
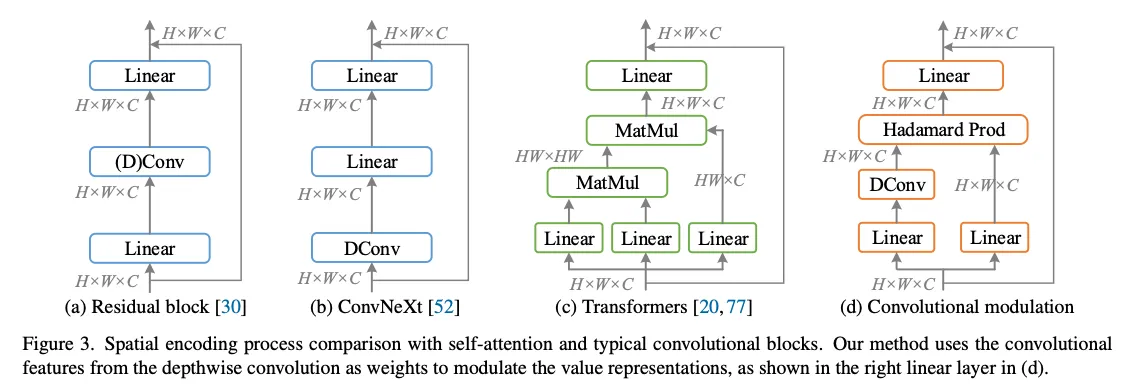
3.3. Micro Design
Larger kernel then
ConvNext中指出,大于的卷积收益不大反而带来额外开销。但是本文认为,收益不大是因为ConvNext采用空间卷积的方法不好。本文使用更大的kernel可以也能获得收益。综合考虑模型效率,本文默认将卷积核大小设置为。
Weighting strategy
我们将深度可分离卷积输出的特征作为权重,去调制线性投影后的特征。值得注意的是,在Hadamard乘法之前,我们并未使用任何激活或归一化层(例如Sigmoid或Lp归一化)。这是获得良好性能的一个关键因素。例如,如果像SENet那样在乘法前加一个Sigmoid,则会使性能下降超过0.5%。
Normalization and activations
采用LayerNorm + GELU可以提点大概0.1~0.2%。
4. Experiments
4.1. Experiment Setup
Datasets
ImageNet-1k, ImageNet 22k预训练然后Image 1k上finetune。
Training Settings
我们使用PyTorch 实现模型训练,并采用AdamW优化器,线性缩放学习率:。初始学习率,权重衰减为,与已有研究的建议一致。在ImageNet训练中,我们将图像随机裁剪至,并采用MixUp、CutMix等常见数据增强。我们也使用了随机深度(Stochastic Depth)、随机擦除(Random Erasing)、标签平滑(Label Smoothing)、RandAug以及初始值为的Layer Scale。我们总共训练300个epoch。对于ImageNet-22k实验,我们首先在此数据集上预训练90个epoch,然后在ImageNet-1k上微调30个epoch,策略与ConvNeXt相同。
4.2. Comparison with Other Methods
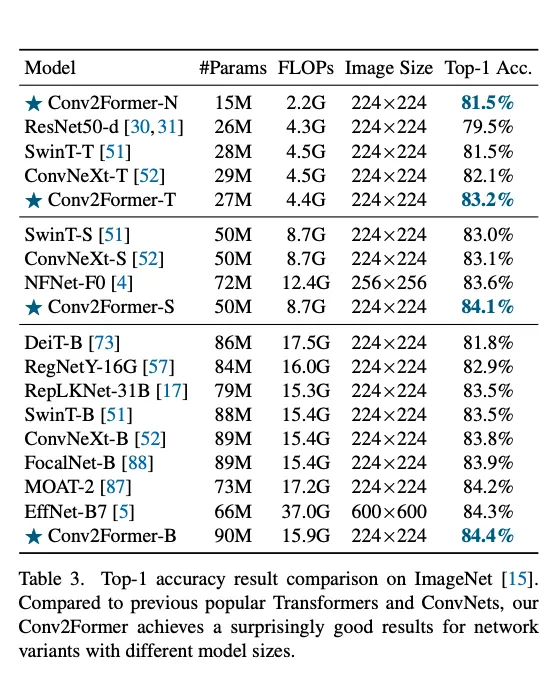
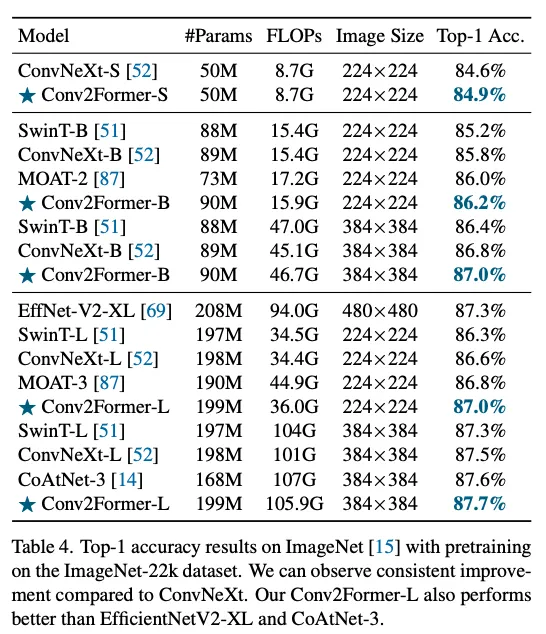
模型更小,精度更高。在ImageNet-22k上也有比较好的效果,证明scale up之后的大模型也有效。
Discussion
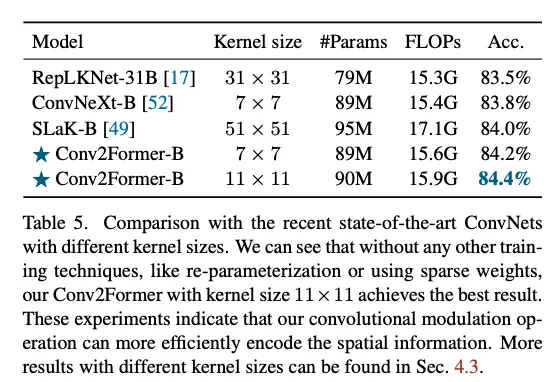
之前的工作用大kernel的时候会出现难以优化的问题,但是本文的框架似乎没有这样的问题,不采用重参数化、稀疏化也有比较好的效果。
4.3. Method Analysis
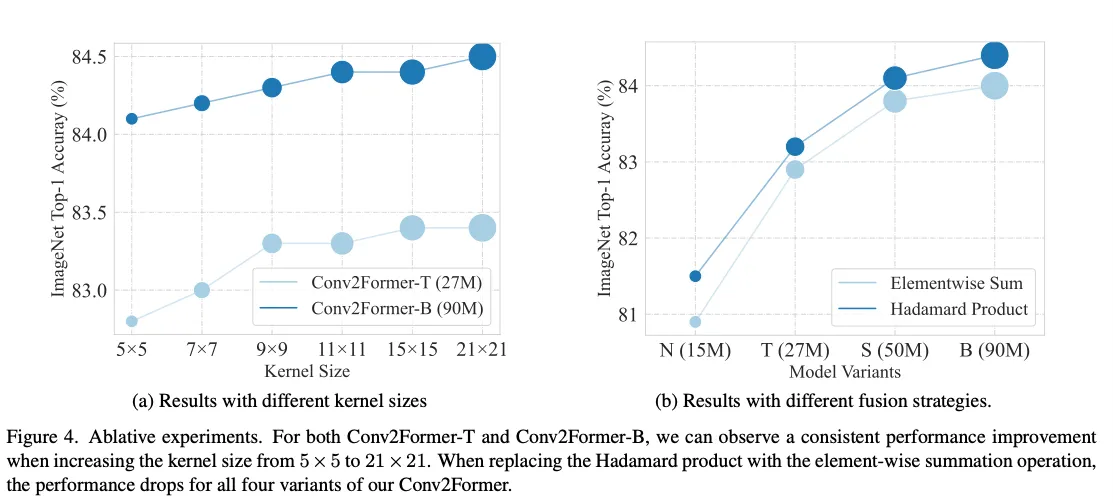
Kernel Size
fig4(a),可以看到性能一直在增没有饱和,证明文章提出的这种结构就是能更好利用卷积的;
Harmard product is better than summation
fig4(b),比elementwise Sum效果更好,不管模型的size如何;
Weighting strategy
比如在A后面加、做L1 Norm等、归一化到之间等,效果都不如现在这种做法。

这个结论和传统Attention中喜欢用sigmoid把权重变成正数的处理方法不一样。
4.4. Results on Isotropic Model to ViTs
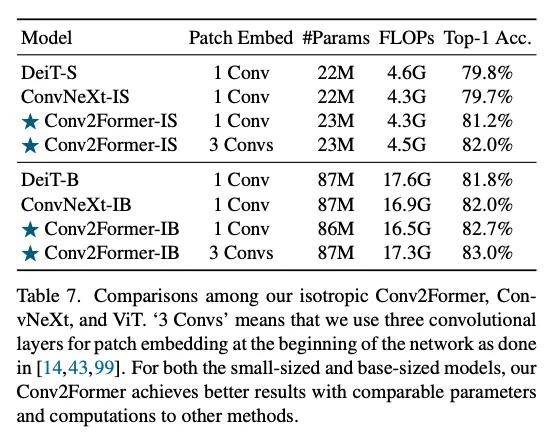
改成ViT风格,只有一个embedding层然后多堆Transformer块。
对于约22M参数的小模型,Conv2Former-IS比DeiT-S和ConvNeXt-IS高出约1.5个百分点;当模型规模增加到80M+时,我们的Conv2Former-IB取得82.7%的Top-1精度,相比ConvNeXt-IB和DeiT-B分别高出0.7%和0.9%。此外,若在patch embedding中使用三层卷积,还能进一步提升效果。
4.5. Results on Downstream Tasks
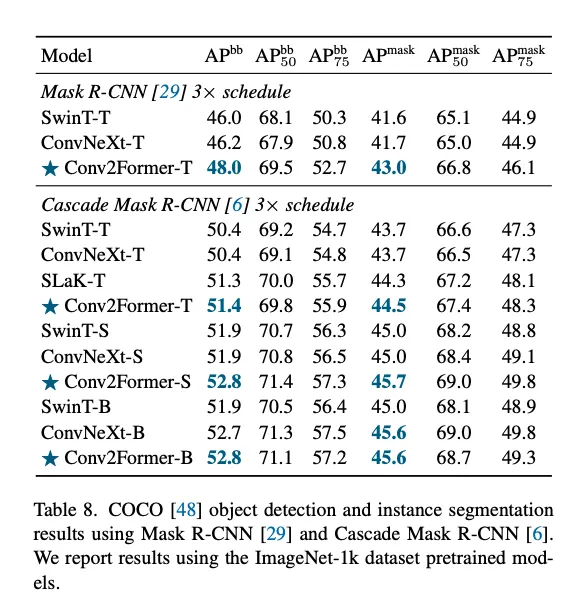
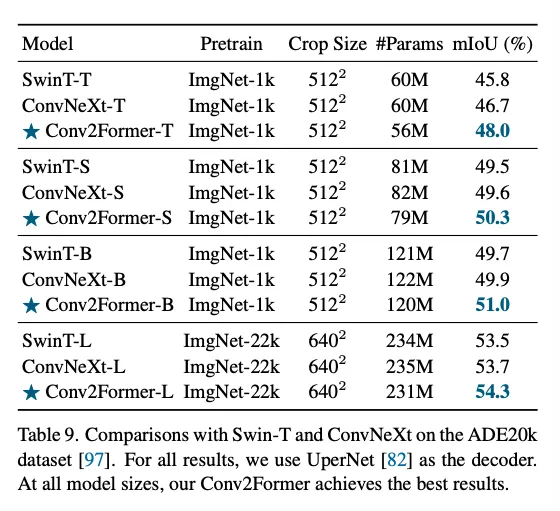
COCO和ADE20k.
5. Conclusions and Discussions
本文提出了Conv2Former,一种新的基于卷积的网络结构。其核心是卷积调制 操作,它通过简单的卷积和Hadamard乘积来简化自注意力机制。我们展示了,这种卷积调制操作在使用大卷积核()时更为高效。我们在ImageNet分类、目标检测和语义分割等任务上的实验也证明,Conv2Former优于现有的CNN模型以及大多数Transformer模型。
Discussion
最新的视觉识别模型通常在低层特征编码时强依赖卷积。我们相信,CNN在视觉识别方面仍有很大的提升空间。例如,如何更高效地利用大卷积核(),如何在固定大小卷积核的前提下更有效地捕获大感受野,以及如何更好地将轻量级注意力机制引入CNN,都值得深入研究。
Limitations
本文主要研究如何更好地利用大卷积核来构建CNN,我们只关注了CNN模型的设计。如何将本文提出的卷积调制块与Transformers相结合,是未来值得探讨的方向。
又一篇用DS Conv + 模块设计的文章,DS Convolution可能是非Softmax的SNN Attention有力candidate?