3.8 update: 面试之后反问环节学习了一下面试官工作中的workflow,现在大规模AI Infra调优要关注的内容真的很多,从最底层的文件系统和存储到分布式的通信,再到CPU上的workload与GPU上的workflow,整个过程中非常多的环节只要有差错就会导致整个系统的吞吐下降严重。这里写的内容基本只关注了GPU最多到CPU level的内容。有点坐井观天了。
0. GPU编程模型
0.0 GPU与CPU
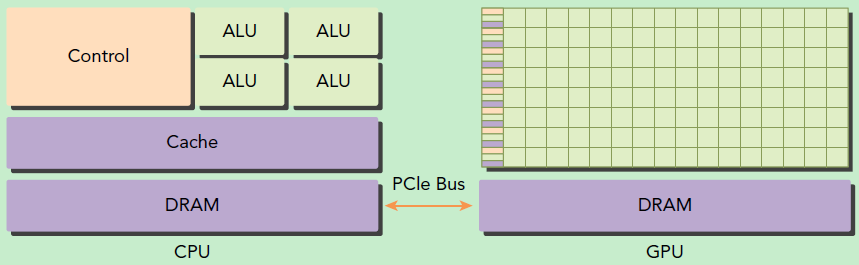
CPU:少量高性能核心,大缓存,复杂的控制逻辑结构,因此可以执行比较复杂的串行任务;
GPU:大量简单核心(ALU/Tensor Core),小缓存,流水线长但是控制逻辑简单。
这种差异使得GPU更加擅长做大规模并行计算(如向量/矩阵乘法),也就更适合做AI方向的算力(MM等各种大规模并行计算的内容多,而设计细节逻辑控制如if的内容少)。
0.1. GPU编程模型
GPU上线程的组织结构分为三级,Grid→Block→Thread:
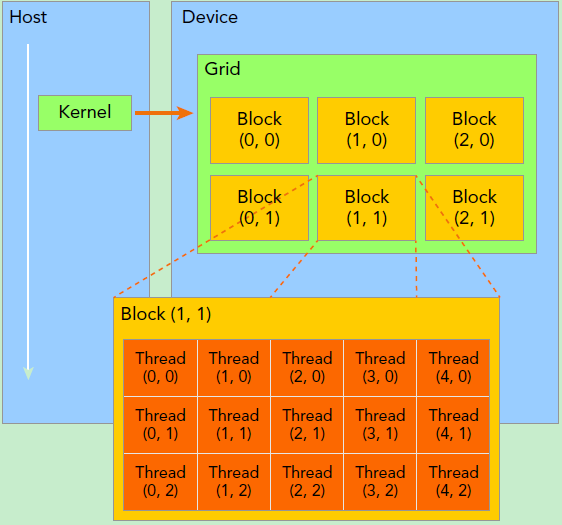
写CUDA的时候调用__global__或__device__声明的Kernel的时候会有参数<<<gridSize, blockSize>>>声明的就是这个kernel占用的资源数量。
这种线程组织结构非常适合做高并行度的计算,如下面给出的简单例子:
// 定义Kernel
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N) // 防止越界
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel 线程配置
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
// kernel调用
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
就可以想象成由numBlocks * threadsPerBlock个thread并行地计算C = A + B。
同一个threadBlock内的所有thread物理上都是由同一个SM处理的,现代GPU的单个SM支持的最大thread数量可以达到1024个。这些thread需要共用寄存器等各种资源。同时,虽然逻辑上代码中很多内容可能是并行地执行的,但是在物理上则未必,因此还需要了解GPU的缓存结构与一些其他的具体物理结构。
0.2. GPU存储结构
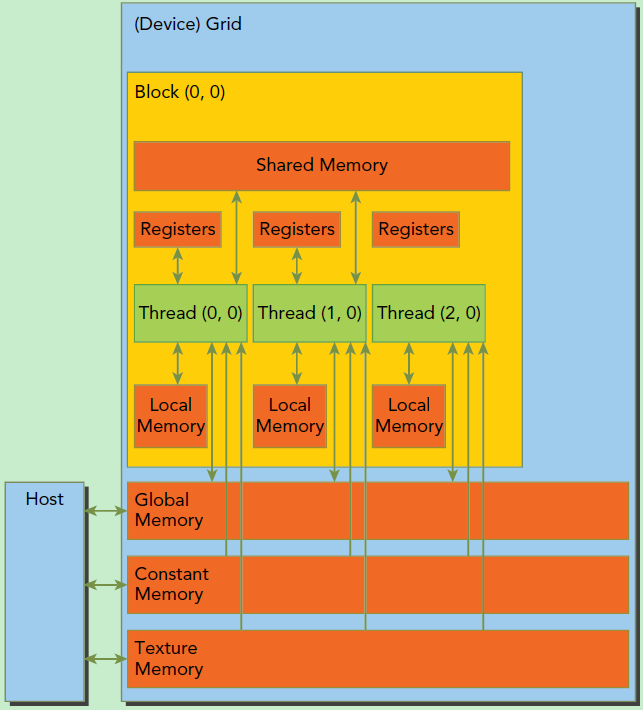
Global Memory就是HBM显存。每个threead有自己的Local Memory和Register;每个Block私有一份Shared Memory,它的生命周期和Block一致;所有的线程都可以访问Global Memory,以及Constant Memory和Texture Memory。
- Global Memory, 就是HBM显存,所有的thread都可以访问它,在GPU上初始化一个值而不指定位置的时候,就在Global Memory里面;一般写Host2Device的过程,就是把数据从CPU内存搬运到Global Memory中;
- Shared Memory,每个threadBlock独有一块Shared Memory,一般是几十KB,由于Global Memory比较慢,一般是把Global Memory中,本block需要用到的内容搬运到自己的Shared Memory中,计算完之后再传回去;
- Constant Memory & Texture Memory,针对特定内容(常量或者2D纹理)做了优化,访问速度接近Shared Memory但是只能存储特定内容;一般用这两块地方优化数据访问,减少Shared Memory中需要的空间,比如将很多计算中不会修改的常量放在Constant Memory中,这样就可以又快又节省空间地完成计算;
- Local Memory,最小,每个thread独有,存一些临时变量;
0.3. SM, Warp and Warp Divergence
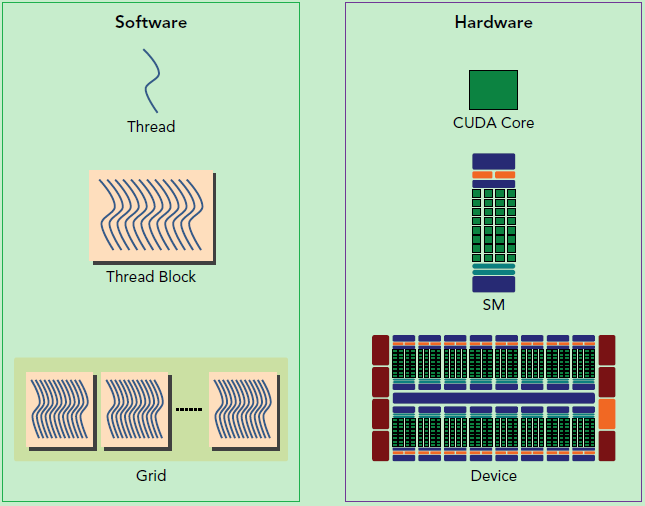
SM的全称是Streaming Multiprocessor,流式多处理器。当一个Kernel被执行的时候,它的grid中的block被分配到SM上。每个block都只能被一个SM调度,一个SM通常能调度多个block。这意味着,一个grid内部的block可能实际上被多个不同的SM调度,也就是说grid只是一个逻辑上的结构,而SM才是物理上真正的结构。
SM采用的SIMT(Single-Instruction Multiple-Thread)结构,基本单元是warp而不是thread。一个warp中包含32个thread。这些thread同时执行相同的指令,但是各自有各自的寄存器和PC。它们在遇到if这样的分支指令的时候实际上会有不同的路径,但是根据GPU结构的规定,在同一个cycle内一个warp内的thread只能执行相同的指令,也就是说,假设有
if (...) { /* Situation A */ }
else { /* Situation B */ }
在一个warp内产生分歧,则整个warp都会执行A和B两种情况,这意味着很多thread实际上空置了(等待另一部分thread完成对应分支的计算),这种情况称为Warp Divergence,会导致非常严重的性能下降。因此在设计CUDA程序的时候,需要非常注意Warp Divergence的情况,尽量减少在GPU上做包含复杂逻辑的计算。
一个SM能够同时并发的warp数量是有限的,因为SM需要给每个warp内的thread分配寄存器、给每个block分配shared memory,这意味着假设grid非常大,内部的block就会争用资源,因此SM分配到的block/warp并不一定总是并行执行的。这也导致了,分配不同大小的grid和block,可能会导致程序的性能差异。另外,考虑到warp内总是由32个thread,threadBlock的大小一般是32的倍数。
0.4. Tensor Core
之前讲的SM内部的计算结构是CUDA Core,比较新的显卡里面还有Tensor Core用于专门加速AI任务(主要是GEMM)。
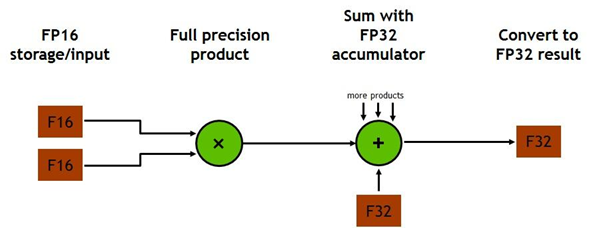
Tensor Core支持在一个cycle内,完成对两个的FP16矩阵(张量)的GEMM计算,并且最终reduce到另一个的矩阵上,即先做乘法,然后做加法reduce,实现,一个cycle完成了64次FP16FMA(Fused Multiply Add),并且计算的过程中采用FP32,这种“混合精度”的模式降低了精度损失。
FP16 & BF16?

BF16的阶码和FP32一样长,数值上下限接近,不太容易上下溢出,但是精度比FP16更低,比较容易出现舍入、转换精度丢失的问题。
0.5. CUDA Streaming
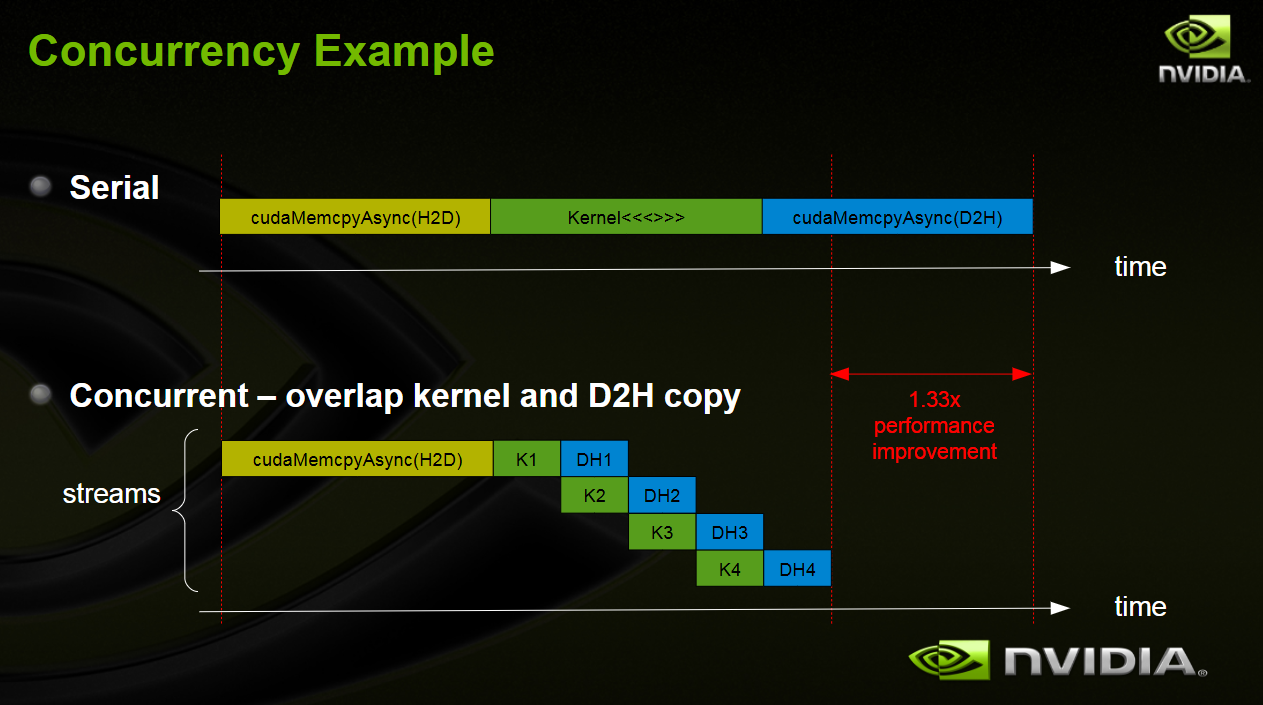
调用myKernel<<<…>>>(…)的时候,Host实际上很快就会返回,相当于是把这个Kernel append到了GPU的一个“任务队列上”。访存的过程也有如cudaMemcpyAsync()这样的异步API来实现。Stream允许多个CUDA操作在不同的Stream中并行执行,提高GPU的利用率和性能。
每个Kernel都可以关联到一个Stream上,Stream内部会严格保证执行顺序,上一个执行完了才会执行下一个;但是Stream之间不能保证执行顺序,如果没有显式地同步两个Stream,它们就能异步执行。可以利用Stream实现Kernel之间的并行、数据搬运与计算的并行。

0.6. Unified Memory
后期的CUDA为了减少程序员的心智负担,提供了Unified Memory,旨在自动管理Host和Device之间的Memory,提供了一片看起来相同的“Unified Memory”。使用__managed__关键字声明的全局变量会变成Unified Memory中的内容。
Unified Memory中的内容:
- 可以被CPU和GPU共同访问,
- 并且是同一个指针,
- 在部分架构中还可以让CPU和GPU并发地同时访问(要注意同步)。
同时,使用cuMallocManaged()也可以分配Unified Memory。CUDA会自动管理Unified Memory中内容的迁移和同步,让开发者不需要再GPU和CPU之间复制数据。
0.7. Profiling
根据GPU的硬件构造,写了CUDA Kernel/一个pytho推理脚本之后可以用Nsight System(多个kernel,System level的信息)和Nsight Compute(单个Kernel,Kernel Level的信息)做Profile,可以关注:
0.7.1. Occupancy
Occupancy是一个SM上正在并行的warp数量与最大支持的并行warp数量之比,衡量一个SM是否“满载”。如果一个warp因为访存产生stal的时候,SM的调度器会尝试转换到其他的warp运行来隐藏stall,但如果所有的warp都在stall,这个SM就会闲置。
如果:
- thread block太大
- 一个block使用的shared memory太多
- 一个thread使用的寄存器太多
都会导致一个SM上能够并行的block/warp减少,occupancy就会降低。
需要注意的是,occupancy只是用来隐藏stall,但不一定意味着越高执行效率就越高。如果一个warp可以通过很多寄存器存储中间计算结果,会出现SM的Occupancy很低(因为能分配的寄存器少)但是计算效率很高(因为中间结果不需要去抢shared memory甚至global memory了)。
0.7.2 异步API
调用Kernel和大部分CUDA API都是异步的,可以不阻塞CPU,让CPU继续去做其他的工作,在需要处理GPU返回的数据的使用通过cudaStreamSynchronize或者cudaEventSynchronize显式地同步。
还可以通过Stream规划,下面的例子相当于让stream1需要搬运数据(大部分CPU参与)的时候,GPU可以处理stream2上的Kernel。
// 假设有h_A, h_B, h_C三个在Host上的数组
// d_A, d_B, d_C三个在Device端的数组
// size为数组大小
cudaStream_t stream1, stream2;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
// 异步拷贝数据到GPU
cudaMemcpyAsync(d_A, h_A, size, cudaMemcpyHostToDevice, stream1);
// 同时在另一个stream上执行另一个kernel
kernel1<<<grid, block, 0, stream2>>>(...);
// 等stream1传输完后,再调用下一个kernel
kernel2<<<grid, block, 0, stream1>>>(...);
// 如果需要在CPU端等待其中一个或全部完成
cudaStreamSynchronize(stream1);
cudaStreamSynchronize(stream2);
0.7.3. Host - Device之间的数据传输
Pinned Memory:采用cudaMallocHost的时候可以让一块Host的内存锁定,操作系统无法将它写回磁盘,GPU用DMA可以快速访问这个内存,提升带宽;
可以用前面的stream的方法,把数据传输和kernel运算拆开,隐藏访存开销;还可以合并小的数据传输,一次传一块大的;
0.7.4. Kernel中的访存
对于Global Memory,SM会把一个warp内所有thread的访存凑起来访问,所以尽量保证一个warp内thread的访存stride是合适的,不要乱序,保持32字节对齐,可以提高带宽利用率;
比如
__global__ void simpleKernel(const float* input, float* output, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
output[idx] = input[idx];
}
}
// 这种场景下:连续访问,线程0->idx=0,线程1->idx=1..
// Warp访存能合并成连续大块。
如果写成:
__global__ void badKernel(const float* input, float* output, int stride) {
// 假设stride非常大
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int realIndex = idx * stride; // 不再是连续地址
output[realIndex] = input[realIndex];
}
吞吐就会降低。
对于Shared Memory,Shared Memory的访问很像cache,包含32个bank,数据是按照4字节顺序排布在bank0 - bank31的,一个bank一个cycle只能被访问一次。如果一个warp内同一个cycle要访问不同的地址,就需要等待变成多个指令,降低吞吐。一般通过加padding解决这个问题。
__global__ void sharedMemKernel(const float* A, float* B) {
__shared__ float tile[32][32+1]; // 添加1列padding,避免bank冲突
// ... 拷贝时也需要注意访问方式 ...
}
0.7.5 指令级优化
计算 - 访存比,主要是要提高“计算密度”,profile的时候需要关注roofline model。
prefetch,可以提前把下一轮要用来计算的取数据指令先发了,然后发这一轮计算的指令,这样这一轮算好了下一轮的数也快取好了。
指令重排,可以先把没有数据依赖的指令插到有数据依赖的指令之间,减少后面的计算等前面的计算的情况。
循环展开,用更多的寄存器并行算。
1. CUDA基础
1.0. global, device, host
__global__: 在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。__device__:在device上执行,单仅可以从device中调用,不可以和__global__同时用。__host__:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。
1.1. threadBlock指定
调用Kernel:myKernel<<<gridSize, blockSize>>>(...)中指定了这个Kernel占用的资源数量。由前面的图可以知道,threadGrid, threadBlock内部其实可以看做是二维排布的,另一种kernel调用的写法可以是:
dim3 blockDim(16, 16); // 2D threadBlock, 大小为16 * 16
// dim3 blockDim(16, 16, 2); // 3D thread Block, 大小为16 * 16 * 2
myKernel<<gridDim, blockDim>>(...);
如果按照之前直接给进去一个数值的写法,其实就等价于写dim3(blockSize, 1, 1)。在一维的场景下这么些更加方便。
同一个Block内部的线程会被分配到同一个SM上,因此调整thread数量一般考虑:
- 单个SM的寄存器资源、共享内存使用等;
- 保持32的倍数,因为一个warp是32个thread;
1.2. 常见API
- 并发和事件相关
cudaStreamCreate/cudaStreamDestroy: 创建/销毁多个 stream,实现多重并发队列。cudaEventRecord/cudaEventSynchronize: 利用 event 做某些测量或同步点。cudaStreamWaitEvent: 让一个流在另一个流上的事件完成后再执行,替代显式的 stream 同步,粒度更细。
- 异步操作 & Pinned Memory
cudaMallocHost/cudaFreeHost: 分配固定页的 Host 内存 (Pinned Memory)。异步 memcpy(cudaMemcpyAsync)+ DMA 可以提升 CPU-GPU 传输性能。cudaMemcpyAsync: 常见于让数据传输和 Kernel 执行重叠。cudaLaunchHostFunc: 允许某些回调函数在 GPU 上的工作完成后在 Host 端被调用。
- Unified Memory (Managed Memory)
cudaMallocManaged: 分配统一内存,CUDA 负责在 CPU/GPU 间迁移和一致性维护。- 一些高级特性,如预取(
cudaMemPrefetchAsync)可以在多 GPU 的平台上显式地预取到本地 GPU,以减少缺页开销。
- 原子操作
atomicAdd/atomicCAS等 Device 函数,在需要并发更新时必不可少。- 如果在 Warp 内做归约/同步,也可以用 Shuffle (
__shfl_sync) + 原子操作进行优化。
- Warp Shuffle Intrinsics
- 如
__shfl_sync,__shfl_down_sync,__shfl_xor_sync等,可以在 Warp 内交换数据做归约,而不必借助 Shared Memory。对小规模并行归约或 prefix-sum 有用。
- 如
- 流图 (CUDA Graph)
cudaGraphCreate、cudaGraphAddKernelNode、cudaGraphInstantiate、cudaGraphLaunch等。- 可以把一段反复执行的、带有依赖关系的流/Kernel/Memcpy 记录成图,实例化后重复执行。通常可以减少 driver overhead,提高性能,对推理场景也常见。
- 多 GPU 相关
cudaSetDevice、cudaDeviceCanAccessPeer、cudaDeviceEnablePeerAccess: 在多 GPU 间直接 peer2peer 传输数据,提升多 GPU 并行计算的效率。- 或者使用更高层库 (NCCL) 做多 GPU/allreduce 通信。
一个GPT生成的GEMM Kernel:
#include <cstdio>
#include <cstdlib>
#include <cuda_runtime.h>
// Block大小,用于Tile的尺寸
#ifndef BLOCK_SIZE
#define BLOCK_SIZE 16
#endif
// 简单的检查CUDA错误的宏
#define CUDA_CHECK(call) \
do { \
cudaError_t err = call; \
if (err != cudaSuccess) { \
fprintf(stderr, "CUDA error at %s:%d: %s\n", __FILE__, __LINE__, \
cudaGetErrorString(err)); \
exit(EXIT_FAILURE); \
} \
} while (0)
// Kernel:对 (M x K) * (K x N) -> (M x N) 做分块乘法
__global__ void gemmKernelTiled(const float* __restrict__ A,
const float* __restrict__ B,
float* __restrict__ C,
int M, int N, int K)
{
// block 内 线程对应的行列索引
int row = blockIdx.y * BLOCK_SIZE + threadIdx.y;
int col = blockIdx.x * BLOCK_SIZE + threadIdx.x;
// 在 shared memory 中缓存 A、B 的分块
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
float sum = 0.f;
// 以 BLOCK_SIZE 为步长,逐步把 A、B 的不同子块载入 shared memory,并做局部乘法累加
for (int tileIdx = 0; tileIdx < (K + BLOCK_SIZE - 1) / BLOCK_SIZE; tileIdx++) {
int A_col = tileIdx * BLOCK_SIZE + threadIdx.x; // A的列
int B_row = tileIdx * BLOCK_SIZE + threadIdx.y; // B的行
if (row < M && A_col < K) {
As[threadIdx.y][threadIdx.x] = A[row * K + A_col];
} else {
As[threadIdx.y][threadIdx.x] = 0.f;
}
if (col < N && B_row < K) {
Bs[threadIdx.y][threadIdx.x] = B[B_row * N + col];
} else {
Bs[threadIdx.y][threadIdx.x] = 0.f;
}
__syncthreads(); // 同步后再进行本 tile 的累加
// 累加当前 tile
for (int i = 0; i < BLOCK_SIZE; i++) {
sum += As[threadIdx.y][i] * Bs[i][threadIdx.x];
}
__syncthreads();
}
// 最终结果写回 C
if (row < M && col < N) {
C[row * N + col] = sum;
}
}
int main() {
// 1. 设置矩阵维度,比如 512 x 512
int M = 512, K = 512, N = 512;
size_t sizeA = M * K * sizeof(float);
size_t sizeB = K * N * sizeof(float);
size_t sizeC = M * N * sizeof(float);
// 2. 分配主机内存(Pinned Memory)
float *h_A, *h_B, *h_C;
CUDA_CHECK(cudaMallocHost((void**)&h_A, sizeA)); // pinned
CUDA_CHECK(cudaMallocHost((void**)&h_B, sizeB));
CUDA_CHECK(cudaMallocHost((void**)&h_C, sizeC));
// 初始化数据
for (int i = 0; i < M*K; i++) {
h_A[i] = static_cast<float>(rand()) / RAND_MAX;
}
for (int i = 0; i < K*N; i++) {
h_B[i] = static_cast<float>(rand()) / RAND_MAX;
}
// 3. 分配设备内存
float *d_A, *d_B, *d_C;
CUDA_CHECK(cudaMalloc((void**)&d_A, sizeA));
CUDA_CHECK(cudaMalloc((void**)&d_B, sizeB));
CUDA_CHECK(cudaMalloc((void**)&d_C, sizeC));
// 4. 创建 stream,准备做并发拷贝和 Kernel
cudaStream_t stream1, stream2;
CUDA_CHECK(cudaStreamCreate(&stream1));
CUDA_CHECK(cudaStreamCreate(&stream2));
// 5. 异步传输 A, B 到设备 (stream1, stream2都可以)
CUDA_CHECK(cudaMemcpyAsync(d_A, h_A, sizeA, cudaMemcpyHostToDevice, stream1));
CUDA_CHECK(cudaMemcpyAsync(d_B, h_B, sizeB, cudaMemcpyHostToDevice, stream2));
// 6. Kernel 配置
dim3 block(BLOCK_SIZE, BLOCK_SIZE);
dim3 grid((N + BLOCK_SIZE - 1) / BLOCK_SIZE,
(M + BLOCK_SIZE - 1) / BLOCK_SIZE);
// 7. 发起 Kernel 到 stream1, 同时可以让 stream2 做别的事
gemmKernelTiled<<<grid, block, 0, stream1>>>(d_A, d_B, d_C, M, N, K);
// 8. 异步拷回 C 到 host (依然是 stream1, 可以等 Kernel 完成后再执行)
CUDA_CHECK(cudaMemcpyAsync(h_C, d_C, sizeC, cudaMemcpyDeviceToHost, stream1));
// 9. 同步,确保计算和拷贝都完成
CUDA_CHECK(cudaStreamSynchronize(stream1));
CUDA_CHECK(cudaStreamSynchronize(stream2));
// 这里可以验证一下结果正确性(和 CPU 端简单矩阵乘法对比),省略...
// 10. 清理
cudaStreamDestroy(stream1);
cudaStreamDestroy(stream2);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
cudaFreeHost(h_A);
cudaFreeHost(h_B);
cudaFreeHost(h_C);
printf("Done.\n");
return 0;
}
要点说明:
- Pinned Memory :通过
cudaMallocHost分配,Host 内存页锁定,可被 GPU DMA 高速读取。 - 异步操作 :
cudaMemcpyAsync+ 指定 stream,使数据传输和 Kernel 调用都可以异步排队,不必让 CPU 阻塞等拷贝完成。- 在示例里,我们把拷贝 A、B 到不同流
stream1、stream2,然后在stream1上发起 Kernel 并拷回 C,演示多流并行思路(可根据场景再进一步拆分)。
- Tiled GEMM :
- 通过 shared memory
As、Bs做分块缓存,减少 Global Memory 的访问次数。 - 每个 Block 处理
BLOCK_SIZE x BLOCK_SIZE的输出子块。 - 通过
__syncthreads()先把 A、B 的子块读入 shared memory,再进行乘加累积。
- 通过 shared memory
这个Kernel关于AB load的时候应该有点问题,现在这个写法不能保证B被load完kernel才开始执行。
2. 推理优化
2.1. 模型量化
模型量化是为了在不太损失精度的情况下,将参数从全精度降低到8B甚至更低的精度的整数或别的数据,降低内存通信带宽和显存占用的同时,还能利用INT8或其他的推理引擎实现低功耗高吞吐的模型推理。
模型量化的基本公式可以写作:
scale控制缩放,zero_point将数值对齐到某个位置,round的策略比较多种,可能四舍五入也可能是别的,用于把数值转换到整数域来。量化一个模型就是针对每个Layer/Channel/…,找到一个合适的scale和zero_point(对于混合精度量化,还有比特位宽),让模型的精度不要大幅度下降。
一般来讲,推理的时候会把模型按照上面的公式逆推回FP32的原精度,虽然增加了计算量,对模型的量化主要是降低了存储和读取模型的带宽需求,这样提升了运算速度(大部分时候模型还是以访存为瓶颈)。
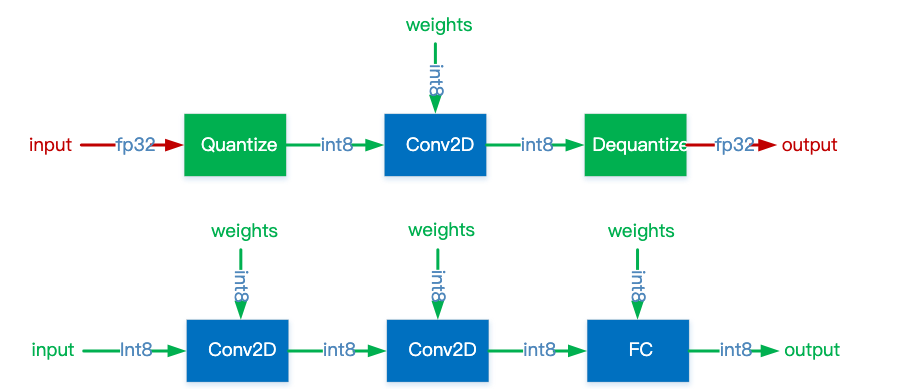
量化模型推理的时候,有的采用混合精度推流,在遇到需要量化的层的时候就把全精度的内容量化到低精度,推理完之后再进行解量化还原成全精度;有的则直接采用纯整数推理,全程都是用量化后的精度进行推理。
2.2.0 量化算数
量化乘法:
在量化后的模型里面,输出的乘法都会被这样计算,会融合到一个kernel中。如果各个channel之间的scale不同,并且需要做加法,那么也需要做相似的操作。
量化scale的选取:
- MinMax
很容易被outlier影响,比如大部分点都在之间但是有一个100,量化考虑的数据范围也会落在上,精度容易受影响,尤其是量化Activation的时候更严重。
- Moving Average MinMax
带动量地平滑掉一部分outlier
- KL散度量化
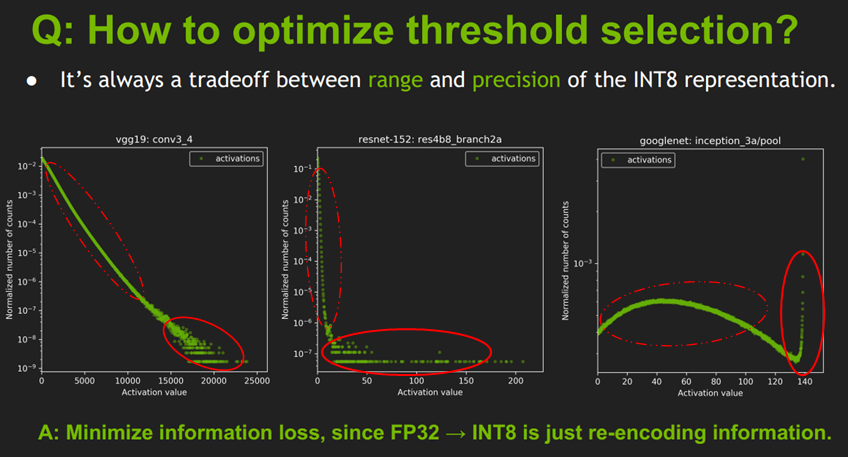
考虑上面这种,不同layer之间有不同的数据分布,如果直接考虑最大最小值进行线性地映射,就可能会
先对数据做直方图统计,遍历备选,超出阈值的会被合并到边界中,然后计算KL散度:
用KL散度估计量化后的数据分布和量化前的数据分布的相似程度,如果越相似证明量化损失的信息越少。
2.1.1. PTQ
Post Training Quantization在训练阶段就正常训练,一般的流程为:
- 训练一个
FP32模型; - 准备少量的calibration数据,一般是几千个或几百个,让原模型进行推理,推理过程中统计每一层的权重和激活值的分布,这样可以得到最大最小值,进而可以得到合适的量化区间(也就得到了scale和zero_point);
- 直接将权重量化成对应的低精度形式,推理的时候也要对激活做对应的量化。
2.1.2. QAT
在训练的时候插入一些Fake Quantization算子,在forward的过程中模拟量化后的状态,反向传播的时候还是用FP32,从而在训练的时候更好地调整权重分布,同时利用训练中的统计信息调整scale和zero_point。
QAT的精度一般会比PTQ的更高,但是需要在训练的过程中就引入Quantization的过程,开销比较大(训练比推几个calibration data难多了)。
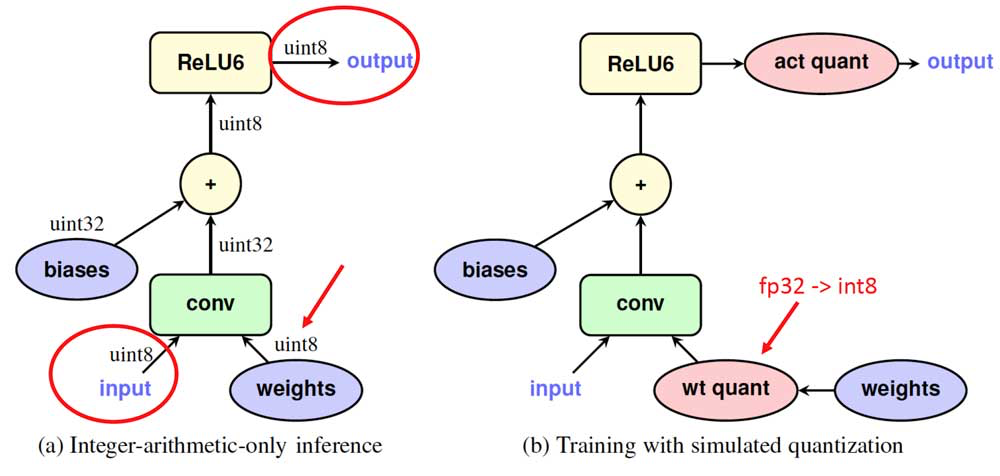
2.1.3. Integer Only
一般来说,LayerNorm、Softmax、GELU这样的层其实很难被量化,很多工作在这些层上都会用FP32代替。
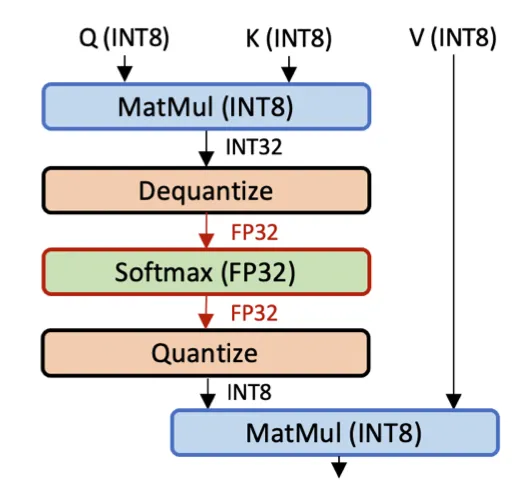
这样做推理效率很差,会在全精度推理的layer形成瓶颈。纯整数的方法基本是考虑用二次或者三次近似的方法,将这些函数转换成多项式,然后把量化方程带入这些多项式函数,再按照之前的方法进行化简。有的还会把其中包含的FP系数进一步优化为迭代 + 位移操作,完全消除所有的整数操作。里面包含的scale一般会分解为两个int一个代表乘数一个代表移位。
2.2. 剪枝与蒸馏
2.2.1. 模型剪枝
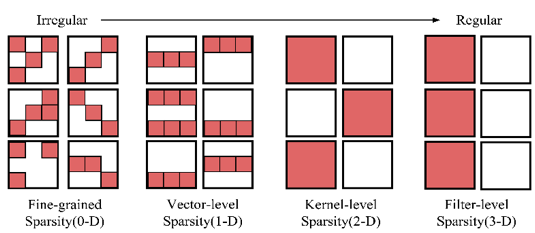
一般是根据weight的绝对值大小或者梯度等指标,直接把小的数值设置为0,然后如果存储模式和硬件都支持稀疏化的优化,就能减少运算和存储。
有各种不同的剪枝粒度,但是太小的GPU不好利用,太大的掉点太厉害,要么是在很细粒度然后剪枝做到90%+的稀疏度然后利用稀疏编码处理。
2.2.2. 模型蒸馏
通过一个已经训练好的Teacher指导一个更小的Student模型进行训练,从而使得Student模型在精度上接近Teacher,但参数和计算量更小。有的会用Teacher输出的Logits或者Softmax分布指导Student的学习,也有的会在不同的layer上插入,让Student的特定layer模仿Teacher的特定layer。
2.3. 推理框架
2.3.1. TensorRT
NVIDIA家的高性能推理引擎,针对CUDA GPU做优化,主要优化机制包括:
- Kernel Fusion,在网络的计算图层面将多个operation融合成单个Kernel,最典型的是Convolution + Bias + BatchNorm + ReLU,这样一次操作之后可以在一个Kernel内部完成所有的计算,避免了数据多次写回显存再读入的开销,降低了Kernel Launch的次数和内存的带宽占用,这种称为“横向融合”;另一种“纵向融合”是,TensorRT可以将网络中多支路中相同的Kernel融合成一个更宽(channel数更多)的Kernel,目标也是产生更大的Kernel,让GPU的计算粒度更粗,减少调度开销的同时提供更多优化的可能性(更高的计算强度);
- 自动FP16/INT8量化,可选PTQ还是QAT;
- Layer Tactic,主要是针对各种Kernel的各种情况实现了不同的高效算子(如来自cuDNN、cuBLAS或者自己实现的),针对模型和目标硬件,选取最高效的进行计算,有点类似TVM等编译器做的事情。
- 其他的更复杂的包括:常量折叠,编译时确定某些数值在推理之前就能够确定结果,直接在编译期间算好,按照一个常量存到程序中;多流执行,根据模型的计算图自动分配到不同的stream以期并行执行;
2.3.2. TVM

一个深度学习编译器,通过引入中间表示,希望适配不同的模型到不同的后端上,都能够完成高效的优化和计算。
TVM的整体结构可以分为以下几个关键组成部分:
- 前端 :TVM支持多种深度学习框架的模型作为输入,比如TensorFlow、PyTorch、MXNet、Keras等。通过这些前端接口,TVM可以读取不同框架定义的模型,并将其转换成中间表示(IR)。
- 中间表示(IR) :TVM使用两级IR,即Relay和TIR(Tensor IR)。Relay是一种高级IR,用于表示高级神经网络算法;而TIR是一种低级IR,用于表示更接近于硬件的操作和优化。
- 自动调度(AutoTVM/AutoScheduler) :为了在特定硬件上获得最佳性能,TVM提供了自动调度工具,如AutoTVM和更现代的AutoScheduler,它们可以自动优化模型的计算图和内核实现。
- Runtime :TVM提供了一个轻量级的运行时,支持模型在目标硬件上的部署和执行。这包括对多种设备的支持,如CPU、GPU、FPGA等。
- 编译流程 :TVM的编译流程包括模型的加载、优化(例如算子融合、内存优化)、自动调度、代码生成等步骤,最终生成可以在目标硬件上运行的机器码。
2.4. 杂项优化
2.4.1. 重排
访问内存的时候一般还是希望是连续访存,这样效率最高,但是有的kernel存在stride过大或者访问顺序和传统的NCHW内存排布模式不匹配,在做GEMM中常见的优化就包括调换循环顺序以期获得最高的吞吐。在现代GPU上一般比较适合用NHWC的格式更加友好,而CPU上一般喜欢用NCHW。
Transformer中的QKV向量一般按照[seq_len, num_heads, head_dim]存储,也是为了适应访存模式+对齐数据。
3. 训练优化
不完全地说,部分训练优化措施解决的问题都是因为显存不足引发的。因为显存不足导致需要使用多卡乃至多机器进行训练,而扩大了device量也导致了更多的通信,这种通信引入的延迟又进一步引入了更多的问题。当然训练实际上也有很多其他的问题需要解决,比如数值稳定性等,训练过程需要解决FP的精度上下溢引入的问题,训练本身的梯度消失/梯度爆炸的问题,在特定场景下收敛困难的问题等。但感觉Infra领域,主要需要解决的各种问题还是显存不足引发的各种问题。
3.1. 显存相关
3.1.1. Automatic Mix Precision
在forward和backward的过程中,大部分时候用FP16/BF16做计算,只在做梯度累加或其他可能导致数值不稳定的操作的时候,再用FP32做计算。并且,在backward的过程中,还会乘以一个缩放因子避免FP16精度太低产生的下溢,反向结束算完梯度之后再除以相同的数值。
3.1.2. Activation Checkpointing
显存特别小的情况下,可以不保存所有的中间层的activation,只保存一部分关键layer的激活,当反传的需要对应的数值的时候,再重新算一遍,用时间换空间;
3.1.3. Gradient Accumulation
希望用大batch但是显存不够的时候,可以把做多次前向把梯度累加几次,然后再做一次反传,可以在相同的精度下模拟更大的batch,但是计算频率降低了,可能对精度有影响。
3.2. 并行训练与通信
3.2.1. Data Parallel
每张卡上都是完整的模型,会给不同的input/batch,这样每张卡自己做自己的forward + backward,然后全局的梯度All Reduce同步更新。这种做法最简单,通信量小,torch的DP, DDP都属于这种方法。
DP的问题是,如果model足够大,大到一张卡装不下了,这种时候DP就直接没办法训练了,就需要把model切分到多张卡上。
3.2.3. Model Parallel
将一个模型在多张卡上分片分块存储,可以进一步分为:
- Pipeline Parallel,将模型不同的layer放在不同的GPU中,多个GPU串行执行,在多种输入下形成pipeline,通信最少,但是在LLM时代一个layer要占用的内存可能就比一张卡的显存大了,这种时候就不能用;
- 假设一个大batch推进去的话会有很多气泡,pipeline不起来,所以一般是打很多小的batch连续计算,方便提高吞吐
- 适合深度较大的网络
- Tensor Parallel,如果一层都大到放不下,就要考虑将layer内部进行的矩阵计算按照行或者列拆分到不同的GPU上,每个GPU算一个小部分,然后通过AllReduce或者AllGather合并结果;
- Megatron-LM的实现是每张卡拥有一些tensor列,计算的时候只计算自己负责的这部分,反向传播的时候才汇集到一起;
- DeepSpeed是计算的时候每张卡都会从其他的卡同步,恢复成完整的参数张量再进行计算;
- 其他的组合方式,比如Tensor + Pipeline + Data Parallel三级都有,或者类似ZeRO这种更加灵活的可以把Optimizer State等各种都分片。
4. LLM相关
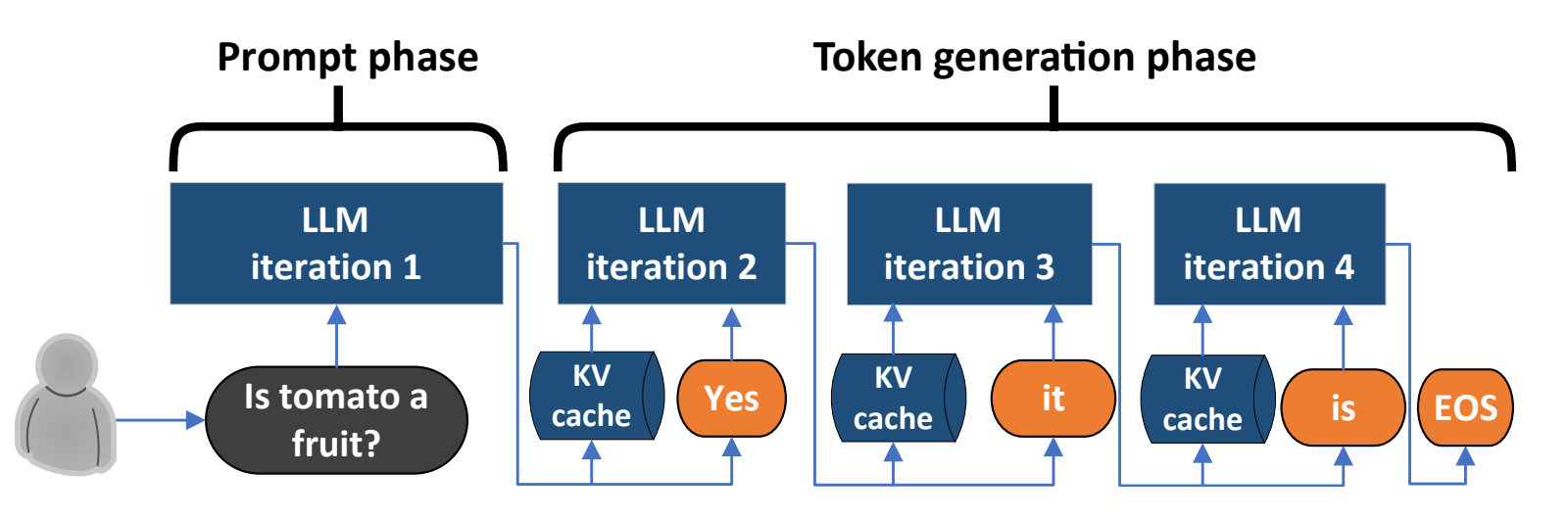
LLM的推理可以分成Prefill和Decode两个阶段,Prefill阶段是处理用户输入,而Decode阶段是自回归地生成输出。
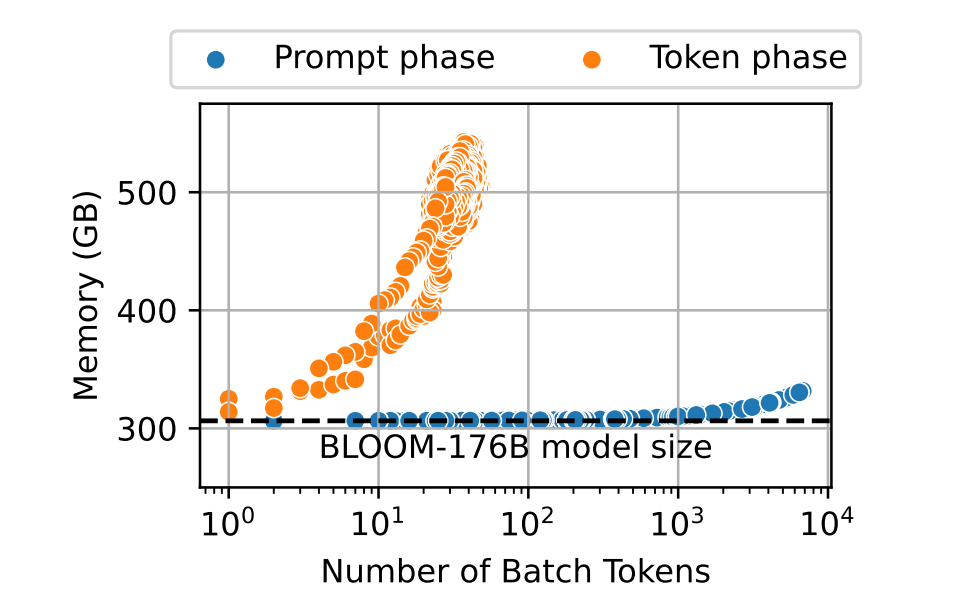
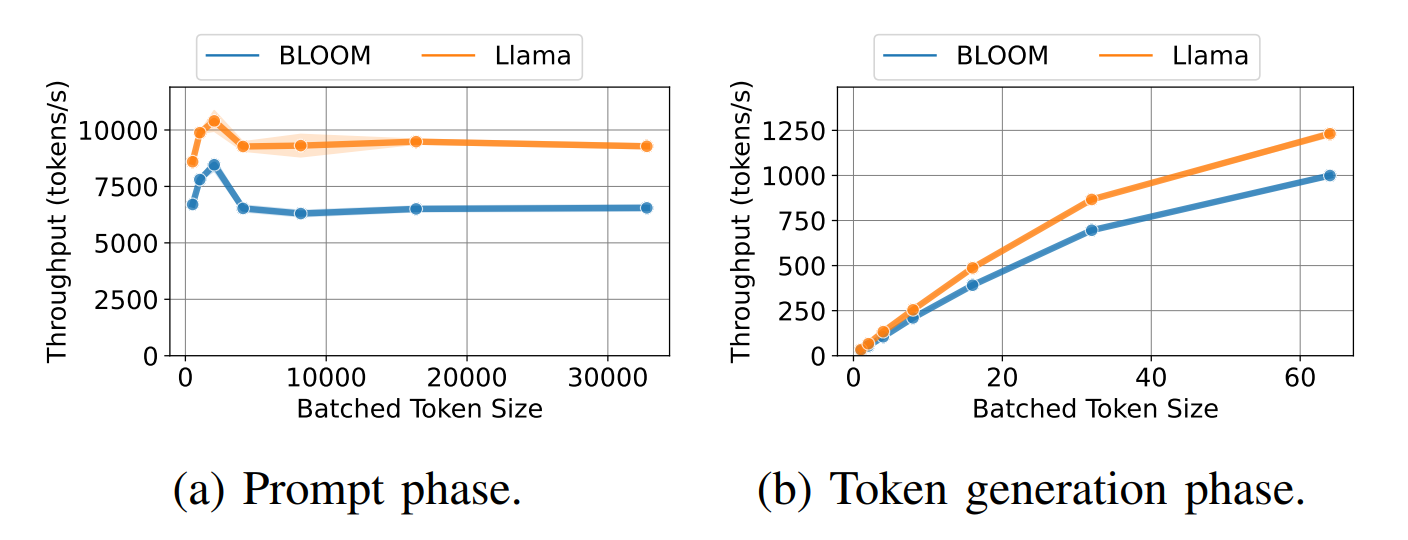
可以看到Prefill阶段的访存次数远少于Decode阶段,而计算量则刚好相反。所以针对两个阶段有不同的优化策略,对于Prefill阶段是典型的Computer bound,而对于Decode阶段则是Memory Bound阶段。
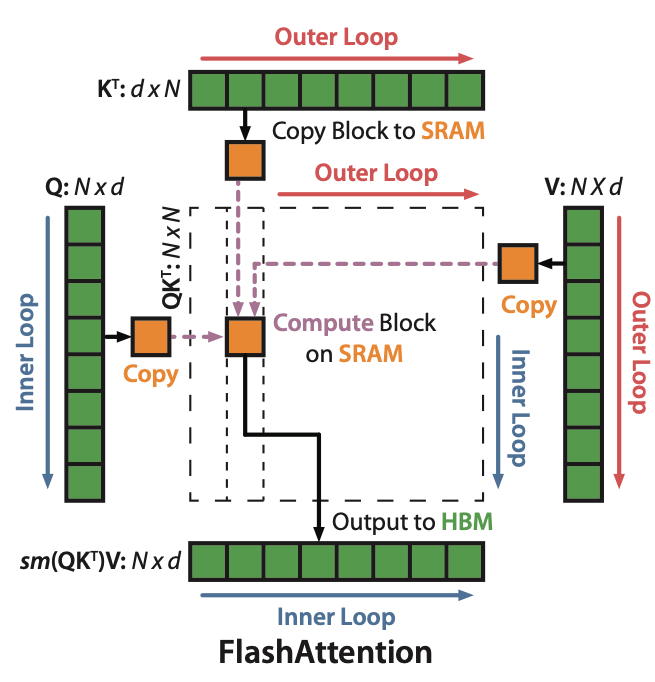
4.1. Flash Attention
传统Self-Attention计算的时候会形成一个seq_len * seq_len的中间矩阵,要做现代LLM 64K甚至128K上下文长的话,这个中间结果已经大到不可接受了。
Flash Attention(v1) 将Attention的计算过程做了reorder和tiling,让几乎所有的中间结果都只在Block Level存在,这意味着只需要保存到寄存器或者Shared Memory中,而不需要大量向HBM中读写内容。
Softmax可以写作:
算Attention的时候做分块,分块后的向量softmax的流程变为:
- 输入 , 计算
- 保存
- ,这个数值是有问题的,因为和目前都不是全局的数值
- 输入,计算
- 更新
- 计算
- 更新
- ,这个值就是正确的了
- 利用新保存的信息更新之前的有问题的值,即
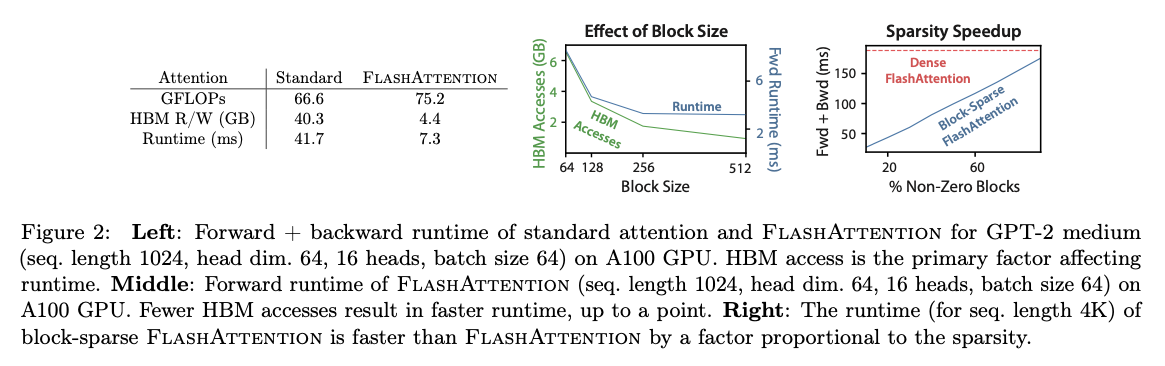
这样分块计算能更好利用Memory Locality,减少HBM访问,增大吞吐。虽然引入了的额外计算,但是吞吐更高了。
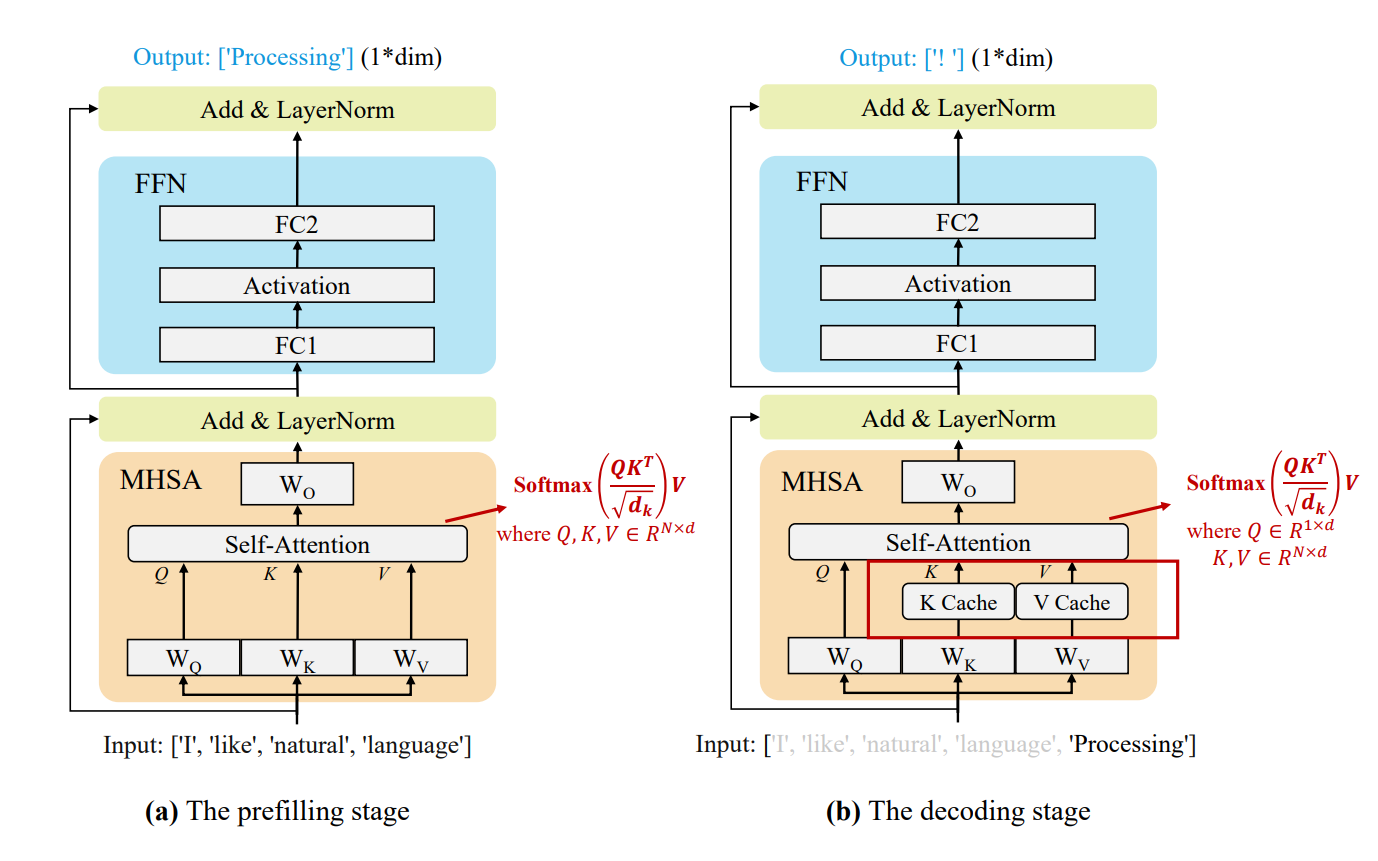
4.2. KV Cache
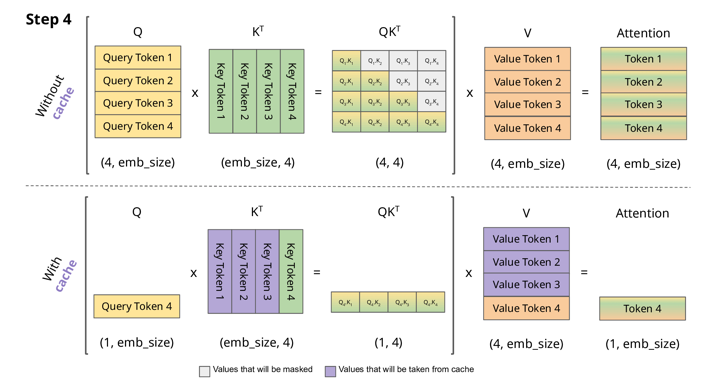
紫色部分就是KV Cache,因为自回归模式生成的前面这些内容都是被重复利用的,这样可以大幅度减少计算。
4.3. MQA, GQA, and MLA
一般而言,KV Cache能够占到系统总体显存占用的30%左右,也非常大。因此,降低KV Cache的大小同样也是一个很重要的优化手段。
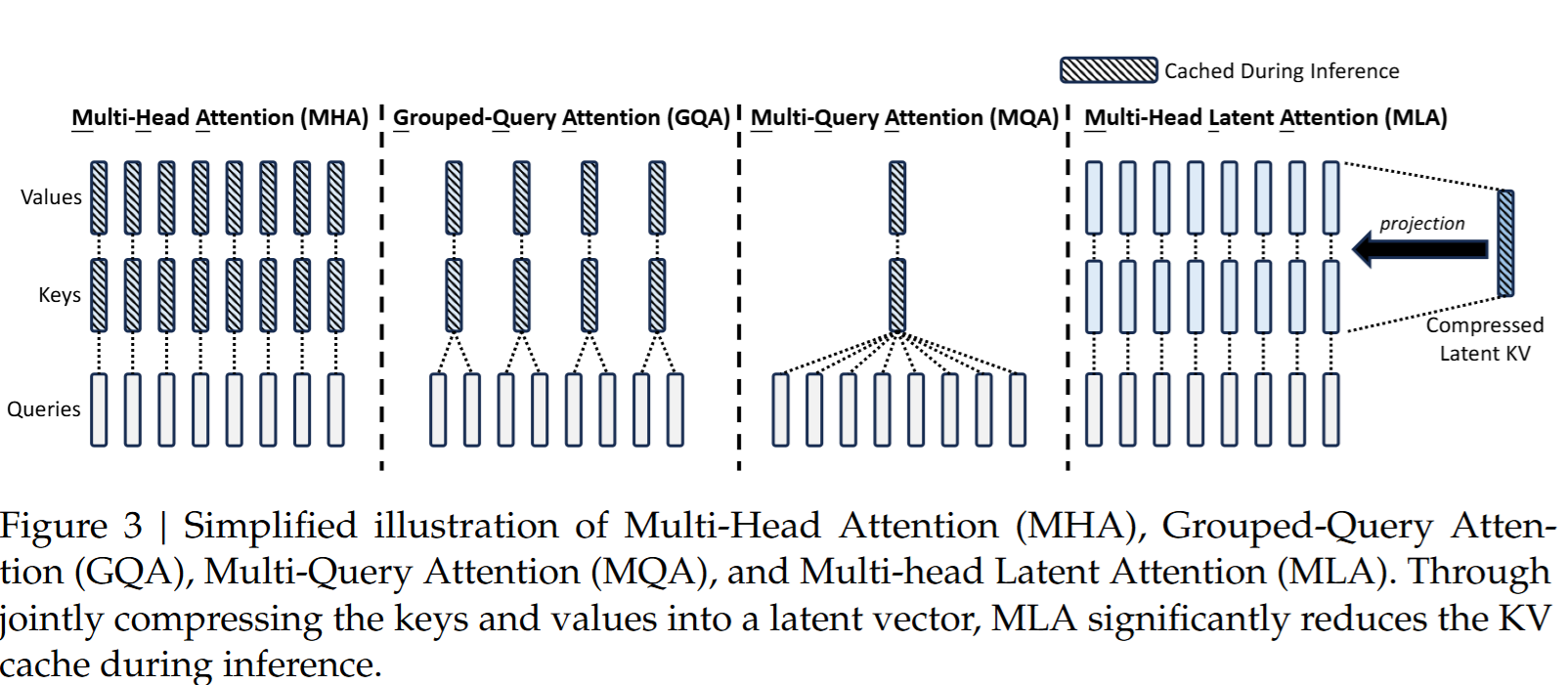
Multi-Query Attention, MQA认为可以让所有的Query共享同一个KV,原文的作者认为这样做精度损失并不大,并且共享相同的KV还意味着整个模型的参数量也减少了,这部分可以在后面的FFN补回来,把精度补回来一部分。
然而,也有人会担心MQA对KV Cache压缩太多了,会影响到整个模型的学习效率和结果,因此提出了Grouped-Query Attention,将head分为若干组,每组共享一对KV。也就是当只分一组的时候,GQA就退化成MQA,而分组数量等于head数量的时候就会变回MHA。
MLA则是通过一个压缩的Latent KV Cache,在计算的时候通过线性变换还原到更大的大小。具体细节这里暂时不写,离简单的推理/训练优化的主题太远了,中间还涉及到LoRA相关的内容,就之后再单独写一篇MHA的文章学习一下论文吧。
参考内容:
国内大厂GPU CUDA高频面试问题汇总(含部分答案) - 知乎
developer.download.nvidia.com/CUDA/training/StreamsAndConcurrencyWebinar.pdf
https://www.cnblogs.com/sasasatori/p/18337693
https://zhuanlan.zhihu.com/p/570795544
https://zhuanlan.zhihu.com/p/505570612
https://zhenhuaw.me/blog/2019/neural-network-quantization-introduction-chn.html
https://medium.com/@joaolages/kv-caching-explained-276520203249