摘要 :近年来,人们对于机器学习应用中的自定义空间加速器越来越感兴趣。这些加速器使用处理元素(PEs)的空间阵列,并通过定制的缓冲层级和片上网络进行交互。这些加速器之所以高效,是因为它们采用了优化的数据流(即,在PEs之间进行空间/时间分区以及细粒度的调度)策略来优化数据重用。本研究的重点是使用分块的通用矩阵乘法(GEMM)核心来评估这些加速器架构。为此,我们开发了一个框架,用于为给定的空间加速器和工作负载组合找到优化的映射(数据流和瓦片大小),并利用分析成本模型来评估运行时间和能量消耗。我们对五种空间加速器的评估表明,我们的框架系统性地生成的分块GEMM映射,在各种GEMM工作负载和加速器上都能实现高性能。
1. Intro
用脉动阵列(systolic array)的加速器越来越多,关于GEMM dataflow需要更好的研究和建模。在空间加速器上优化GEMM映射面临以下挑战:(i)输入矩阵的大小差异显著;(ii)可能的映射空间涉及多级切分、并行化和循环顺序,可能高达数十亿;(iii)必须将加速器的数据流选择和其内部结构(例如,多播、归约树)作为约束条件考虑;(iv)需要准确的成本模型来模拟不同加速器的数据流,并估计映射在加速器上的性能。
本文主要提出一种对GEMM建模的方式(an analytical cost model MAESTRO-BLAS that can be used to evaluate the accelerators for mappings generated by FLASH),然后基于这种建模的方式设计了FLASH,一种Data Mapping Explorer,最后在五个常见的加速器上面测试了六种常见的workload。
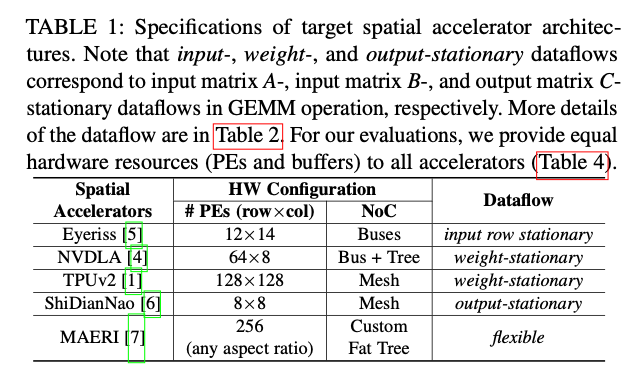
2. Background
2.1 GEMM
The key difference that emerges in this study is that while one loop order is typically the best among GPUs (or CPUs) even from different vendors, the same is not true for spatial accelerators as they are quite diverse.

2.2 Spatial Accelerators
架构: 常见的GEMM Data Mapping如下图,注意到基于脉动阵列的硬件相比普通的硬件增加了Spatial Reuse or Spatio-Temporal Reuse(表现起来就是数据在PE之间流动、脉动阵列的计算形式),这种Reuse是因为片上互联Netrok-on-Chip(NoC)得到的。
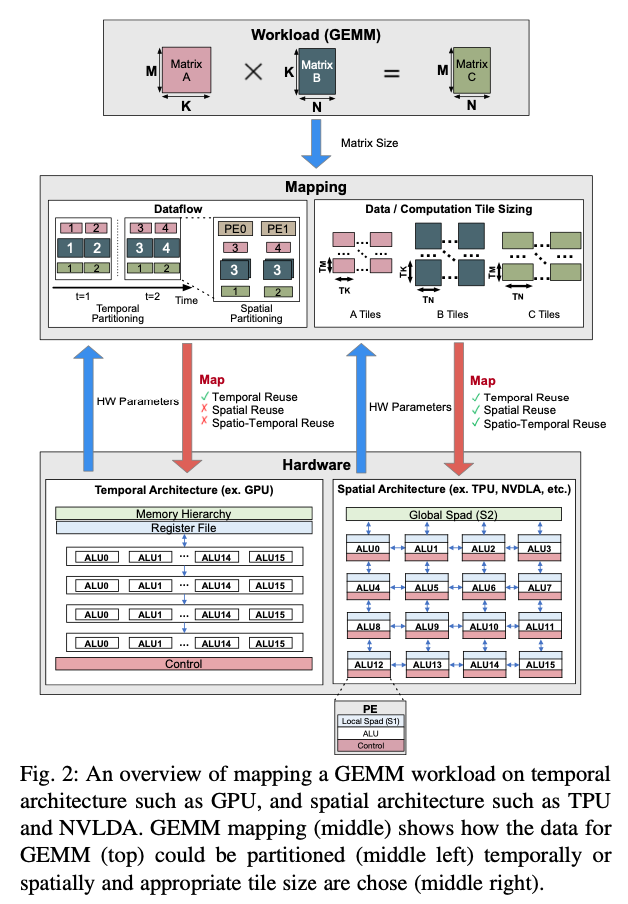
脉动阵列中的Data Reuse: 数据在PE之间流动,形成了时间或者空间上的Data Reuse。
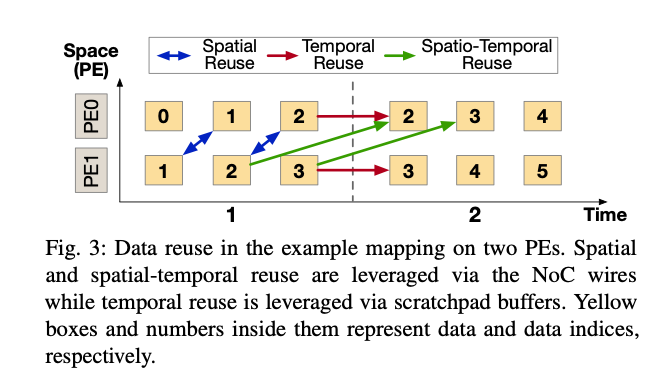
GPU与脉动阵列的区别: 1)脉动阵列中的PE之间可以直接通过NoC通信;2)脉动阵列的硬件能够提供时间和空间两个维度上的Data Reuse,通过硬件上的多播、广播以及NoC实现,而GPU一般只能通过Scratchpad实现时间上的Data Reuse。
2.3 Dataflow Directives and Mapping
Dataflow一般包括两方面,parallelization strategy和computation order。在脉动阵列上,parallelization strategy几乎完全被硬件结构决定。
Dataflow Directives: TemporalMap,SpatialMap, and ** Cluster。**
TemporalMap implies that the data changes over time, and remains same over space (i.e., across PEs). ** SpatialMap** implies that the data changes over space (i.e., parallelism). ** Cluster** helps describe hierarchical dataflows by grouping PEs into clusters of certain Size.
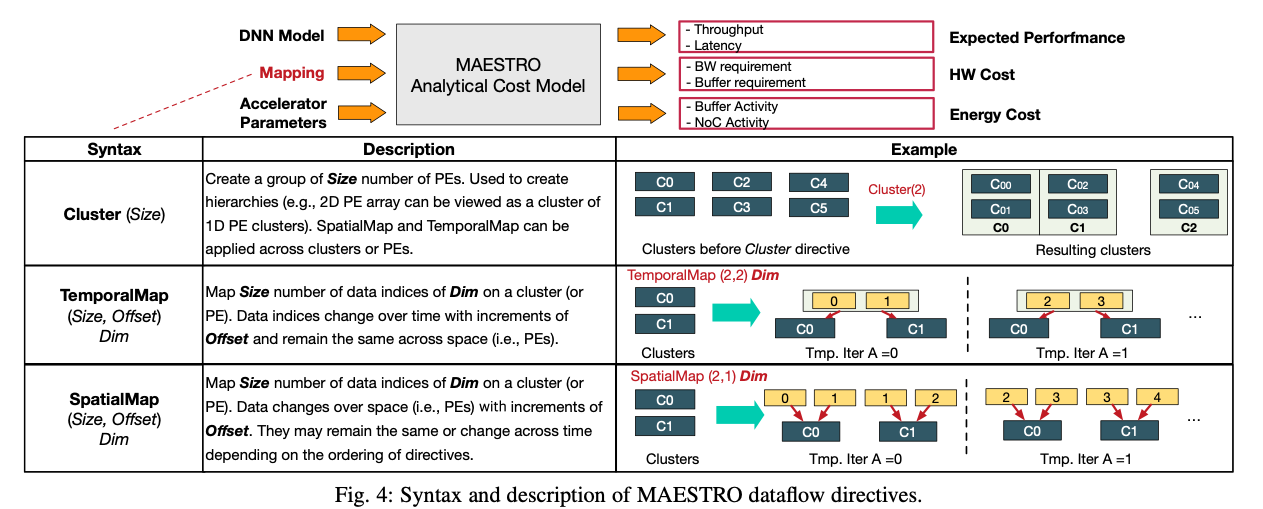
- Cluster (Size) :
- 语法 :
Cluster(Size) - 描述 : 创建一个包含**
Size** 数量的PEs的组。用来创建层级结构(例如,2D PE阵列可以被视为1D PE集群)。SpatialMap和**TemporalMap** 可以跨集群或PEs应用。 - 示例 : 在**
Cluster(2)** 指令应用之前和之后的集群布局变化。
- 语法 :
- TemporalMap (Size, Offset) Dim :
- 语法 :
TemporalMap(Size, Offset) Dim - 描述 : 在一个集群或PE上,映射**
Dim** 维度的数据索引的**Size** 数量。数据索引随时间变化,以**Offset** 的增量变化,但在空间上保持相同(即,PEs)。 - 示例 : 时间迭代**
A=0** 和**A=1** 时,不同的PE如何按时间映射相同的数据索引。
- 语法 :
- SpatialMap (Size, Offset) Dim :
- 语法 :
SpatialMap(Size, Offset) Dim - 描述 : 在一个集群或PE上,映射**
Dim** 维度的数据索引的**Size** 数量。数据随空间变化(即,PEs),以**Offset** 的增量变化。它们可能保持相同或根据指令的排序在时间上变化。 - 示例 : 时间迭代**
A=0** 时,不同PE如何通过空间映射相同的数据索引,并且数据是如何被直接传递的。
- 语法 :
用三个首字母(S or T)代表矩阵的在对应的维度上是时间上并行的还是空间上并行的。比如,指的就是一般的三重循环进行的GEMM。写成,下划线后面指的是一个Cluster内部的Data Mapping、下划线之前的指的是Cluster之间的DataMapping,所以指的是利用Cache、进行矩阵分块加速的GEMM。指的是在维度上存在空间并行,比如将A矩阵按行分割放在不同的cuda tensor core上。这种标记没有指明计算的顺序,所以完整的Dataflow Directives写成,指明内外的循环计算顺序。
3. Accelerator Modeling Methodology
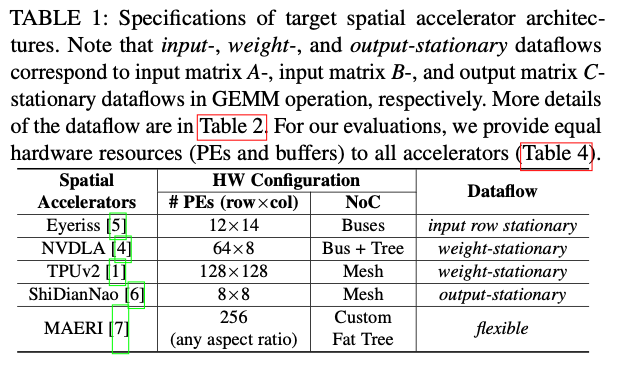
注意到每一种加速器提供的PE数量、形状都不同,这会影响到它们的Dataflow和具体性能。在evaluation部分会让这五个加速器的PE数量相等,以便于公平比较。
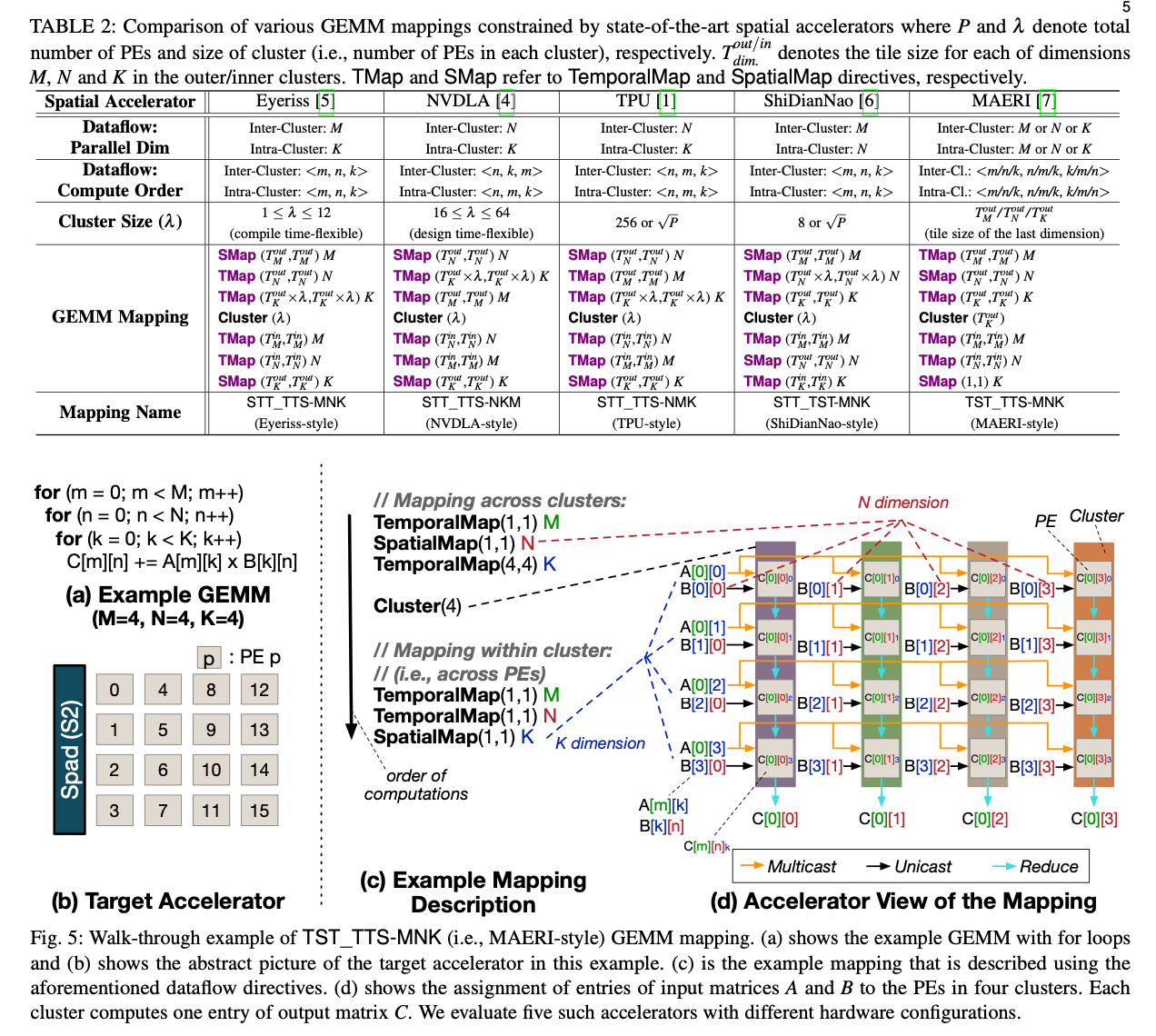
3.2 Walk-through Example of TST_TTS Mapping
详细讲了一下Fig5,重新声明了一个Dataflow最关键的包括Clustering,Intra-Cluster Behavior和Inter-Cluster Behavior。
举了一个关于tiling的例子,主要是体现tiling和mapping的目的都是最小化访“存”的次数,无论是访问内存、访问scratchpad还是访问其他PE中的数据(通过NoC)都会带来延迟。
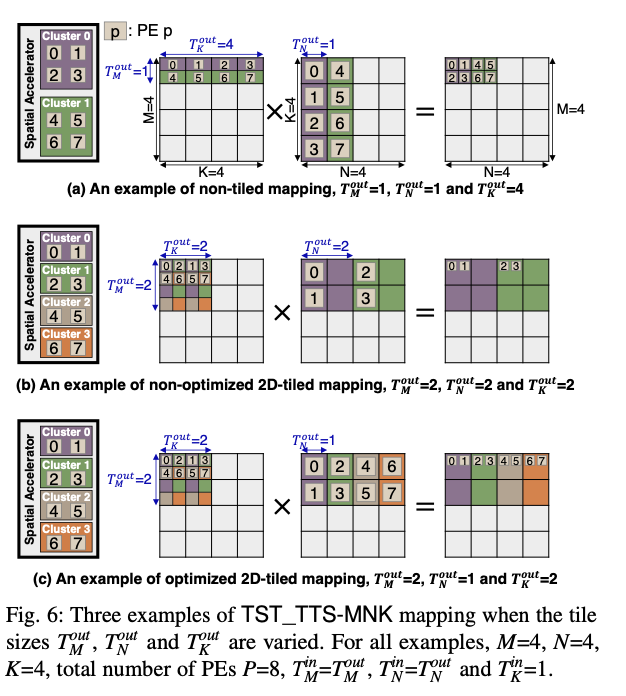
ChatGPT解释为什么效率高:
图6(a)展示了一个非分块(non-tiled)映射的情况,其中所有的瓦片大小都设为1,除了K维度外,其瓦片大小设为4。在这种映射中,每个处理元件(PE)仅计算结果矩阵C的一个元素。由于没有在M和N维度上进行分块,因此没有充分利用空间加速器的数据重用潜力。所有PEs虽然都在工作,但这种策略没有有效地使用集群间(inter-cluster)和集群内(intra-cluster)的数据通信,可能导致较高的数据传输成本和更多的内存访问。
图6(b)展示了一个非优化的2D分块(non-optimized 2D-tiled)映射,其中瓦片大小在M和N维度上设为2,K维度也设为2。尽管进行了分块,但这种方法并没有充分利用所有的集群。在这个特定的例子中,只有两个集群被用于计算,因为只有瓦片大小与N维度匹配的集群可以被映射到N维度上。这导致了最后两个集群(Cluster 2和Cluster 3)处于空闲状态,也就是说PEs 4-7没有被使用,这减少了并行度并导致了PE资源的浪费。
相比之下,图6(c)展示了一个优化的2D分块(optimized 2D-tiled)映射,其中瓦片大小被仔细选择以匹配PE的数量和集群的布局。在这种映射中,ToutM_ToutM_和ToutK_ToutK_都设为2,而ToutN_ToutN_设为1。这意味着每个集群现在都在计算矩阵C的一行,每个PE计算一个子块,这最大限度地提高了PE的使用率,并且由于瓦片大小与集群的布局相匹配,也允许在集群内部有效地重用数据。
因此,与图6(a)和(b)相比,图6(c)的分块映射方法提供了更高的资源利用率和数据重用率,这通常会导致更高的计算效率和性能。在实际应用中,选择合适的瓦片大小是优化空间加速器性能的关键因素之一。
3.3 MAESTRO-BLAS cost model
基于MAESTRO完成,输入一个DNN、一个加速器的configuration和一种mapping方式,输出预估的runtime,访存次数、arithmetic intensity和预期的能耗等。
4. FLASH:A Mapping Explorer for GEMM
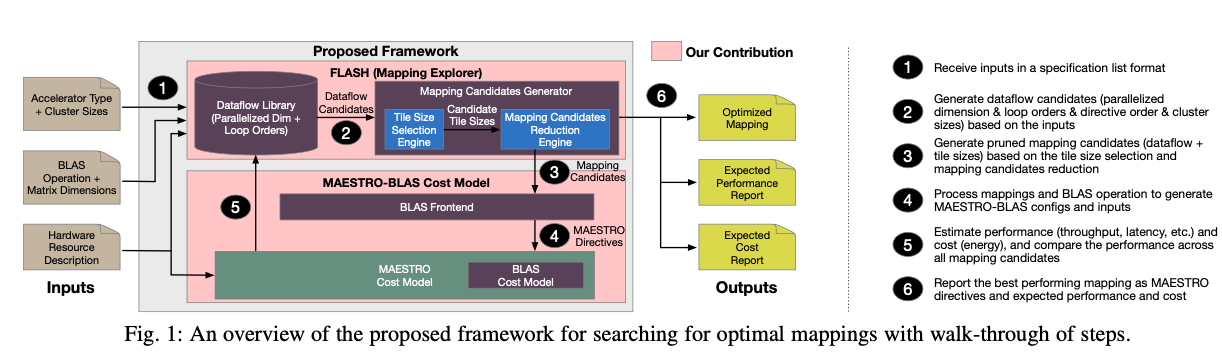
直接搜各种参数的组合太耗时了,需要利用各种限制减少搜索的情况数量。
硬件限制:
1. 硬件可能对GEMM循环的顺序有限制,举例的五种加速器中只有MAERI可以自定义循环计算的顺序;
2. 硬件可能对Cluster Size有限制;
3. 硬件对Tile Size有限制,因为硬件上能存放的数据是有上限的;
对硬件上的多级scratchpad对Tile Size大小的影响做了建模,考虑多大的tile size能够隐藏scratchpad和内存之间通信的latency。总体上来说是考虑内部通信方式等其他configuration,给出了一个方程用来约束搜索的情况。把候选的情况输入MAESTRO-BLAS求对应的表现然后选取一个最好的。
5. Experimental Evaluation
5.1 Evaluation Methodology
workload选了好几种,形状各异,测试FLASH的性能。还测了两种不同的hardware configuration。
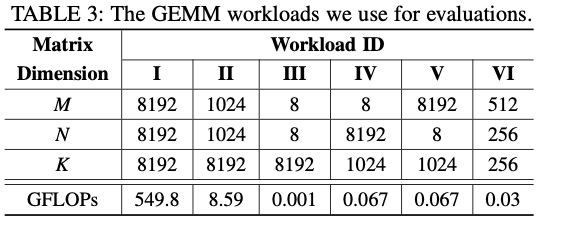
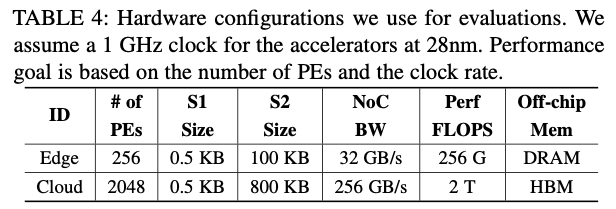
5.2 Search Space Pruning & Mapping Candidates Reduction
实验证明4中提出的FLASH用到的几个限制(主要是两个公式)有效减少了需要生成的情况,减少了99.9%的时间。
5.3 Impact of FLASH Tiling
tiling最重要的是减少了访问两级scratchpad的次数,和传统架构中减少cache miss是一个道理。对于不同的循环顺序相当于不同的stationary,也可以看出loop order实际上应该和workload的形状相关。
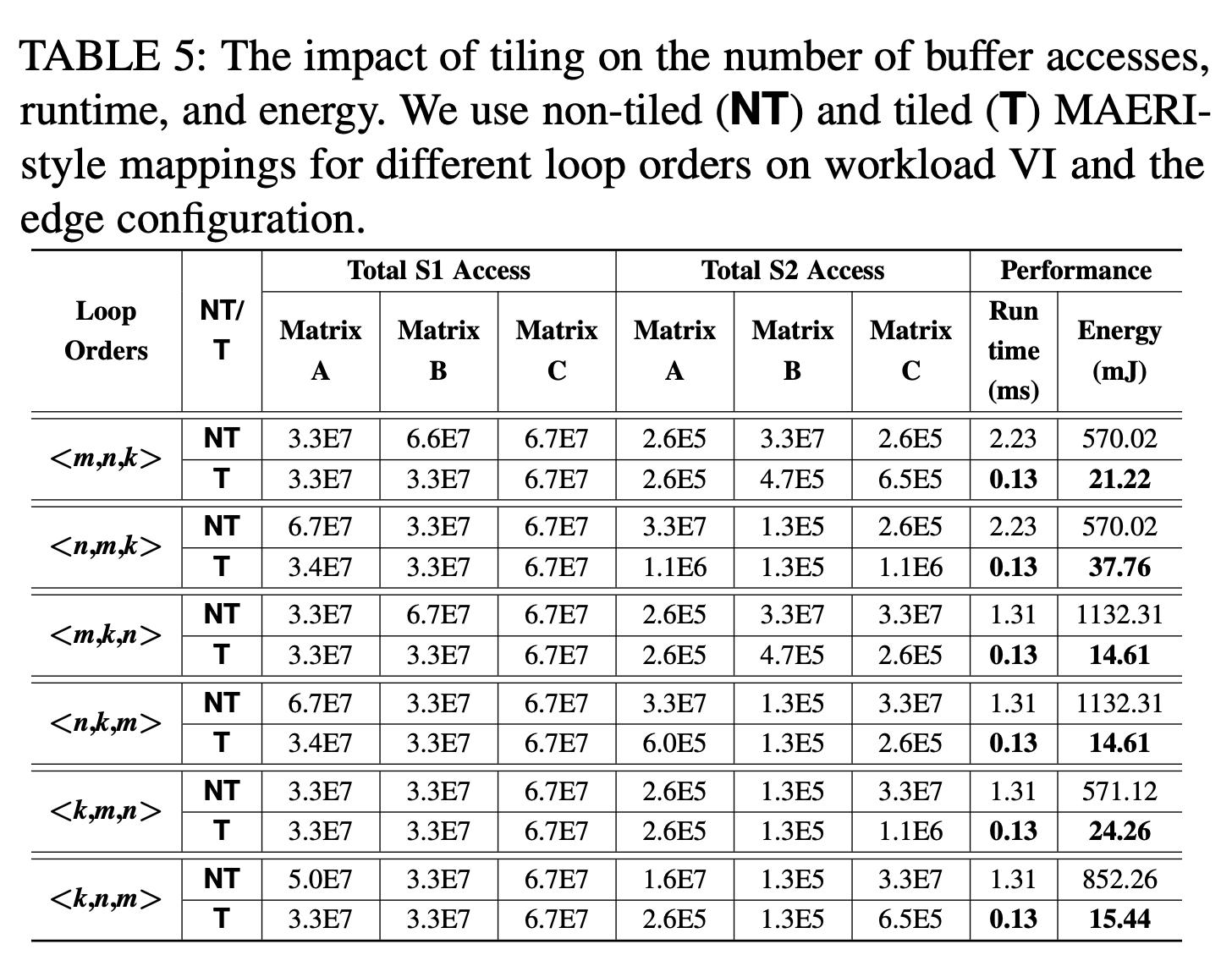
5.4 Evaluation of Accelerator and Workloads
由于除了MAERI之外循环顺序都是固定的,可以看到它们对不同形状的workload有明显的“偏好”。一方面取决于循环顺序,另一方面取决于加速器能够提供的空间并行性在哪个维度。
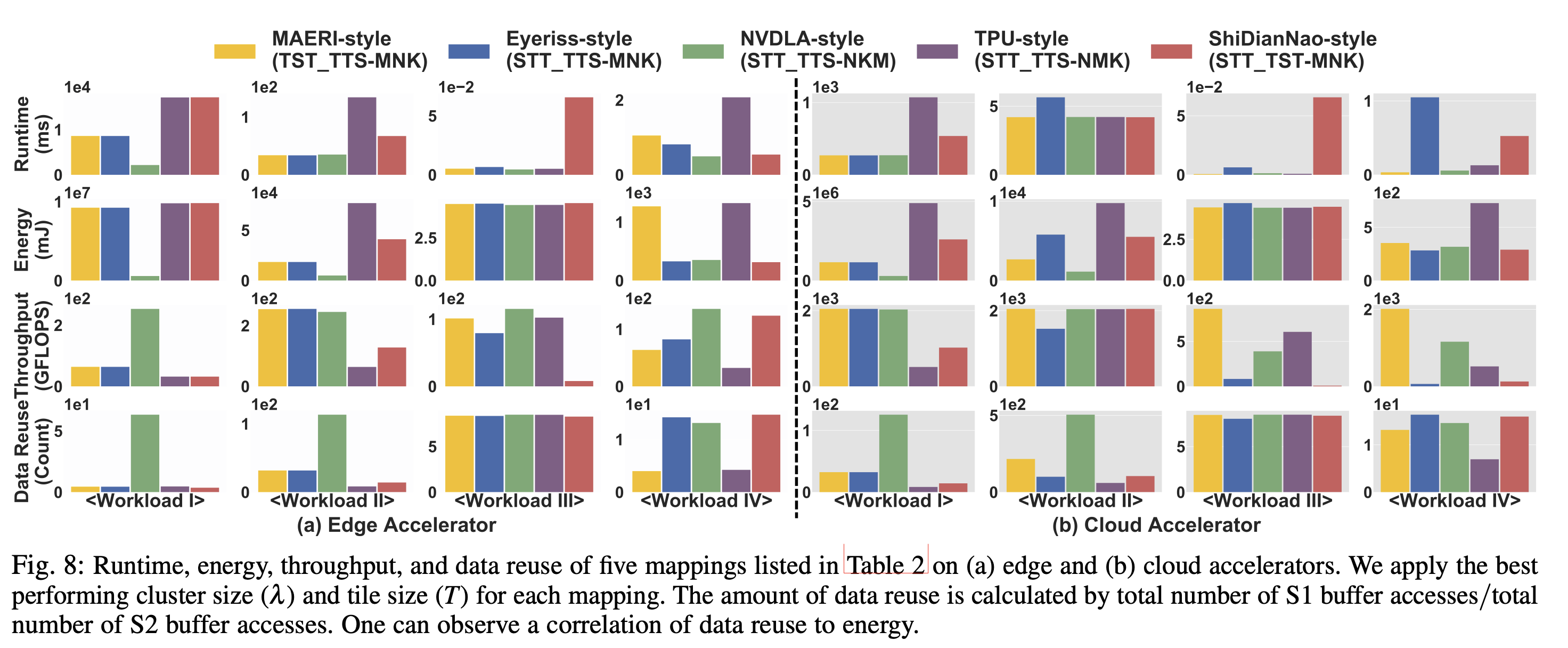
The preference toward loop order based on workload and mapping scheme implies that the flexibility in loop order can provide significant runtime and energy benefits.
还评估了一些DNN workload,不过主要是按算子和layer级别的评估(只评估了FC & MLP)。
6. Related Work
Mapper for Spatial Accelerators :主要是特定加速器的mapping设计。
GEMM Accelerators;
Auto-tuning/Tiling for BLAS: ATALS, SPIRAL. Most of these past work limit themselves one popular loop order for CPU architectures.
7. Conclusion
We develop a framework FLASH for evaluating spatial accelerators via the GEMM kernel. FLASH considers all aspects of the mapping (tile sizes and dataflow for temporal, spatial and spatio-temporal reuse) within the microarchitectural constraints from the accelerator (number of PEs, NoC capability, buffer hierarchy), prunes the search space based on these constraints and additional heuristics, to produce optimized mappings for GEMM. The experimental results show the importance of different co-design considerations computer architects and algorithm designers have to take. This comprehensive study lays the first steps for a heterogeneous HPC node with these accelerators that can address the need of machine learning applications and computational science applications. The ideas in this work could lead to future work studying other dense and sparse ML and CSE kernels over accelerators.
论文的标题没带它们的主要工作FLASH?PolymorPIC内部只有PE存的数据和DRAM数据两个级别,没有cache-like buffer,同时计算顺序有天生的约束,所以主要考虑的还是who-stationary?