摘要: 随着参数规模的快速增长,大型生成式模型的部署愈发具有挑战,因为它们通常需要巨大的 GPU 显存占用和海量计算。非结构化模型剪枝是一种常见方法,可在保持良好精度的同时同时降低 GPU 内存占用与整体计算量。然而,现有方案在现代 GPU 上(尤其是在高度结构化的张量核心硬件上)对非结构化稀疏性的支持并不高效。为此,我们提出 Flash-LLM:在高性能但限制严格的张量核心上,对非结构化稀疏性提供精细支持,从而实现低成本且高效的大型生成式模型推理。基于我们的关键观察:生成式模型推理的主要瓶颈在于若干“瘦长(skinny)的矩阵乘”,此类运算计算强度较低,导致张量核心难以被充分利用。对此,我们提出一种通用的“以稀疏方式加载、以稠密方式计算(Load-as-Sparse, Compute-as-Dense) ”的非结构化稀疏矩阵乘(SpMM)方法。其基本思想是在张量核心上容忍对端到端性能并不关键的冗余计算,同时化解显著的内存带宽瓶颈。在此基础上,我们设计了一个面向张量核心的非结构化 SpMM 高效软件框架,充分利用片上资源以实现稀疏数据的高效提取,并重叠计算与访存。大量评测表明:(1)在 SpMM 内核层面,Flash-LLM 分别较当前最先进的库 Sputnik 与 SparTA 平均提速 2.9× 与 1.5×;(2)在端到端框架层面(OPT-30B/66B/175B 模型),以“每 GPU·秒产生的 token 数”为指标,Flash-LLM 相比 DeepSpeed 与 FasterTransformer 分别可达到最高 3.8× 与 3.6× 的提升,且推理成本显著更低。Flash-LLM 的源代码已公开:https://github.com/AlibabaResearch/flash-llm。
1. Intro
模型的三个基本特征:准确性,效率(Latency/Throughput),成本。常见的加速方法:
- 模型切分到多个机器上推理,高成本、可能的低效率;
- GPU offloading,成本低但是显著降低效率;
- 剪枝理论上具有更好的效率、成本优势,但是非结构化稀疏在GPU上利用很困难,长期被关注较少。
cuSPARSE,Sputnik需要模型在>90%的稀疏度的前提下,才能够与dense性能(cuBLAS)持平,而Tensor Core的性能又能够比SIMT性能再提高一个数量级。
根据以上现象,Flash-LLM尝试在Tensor Core上支持非结构化稀疏。借助非结构化稀疏,Flash-LLM缓解了显存占用问题。
Flash-LLM 的高层设计洞见是“以稀疏方式加载、以稠密方式计算 ”。我们作出一个重要观察:生成式模型推理中的关键矩阵乘通常都很“瘦长”。此外,这些瘦长矩阵乘的性能受限于全局内存访问(或内存带宽),而非张量核心的计算能力。
为了实现上面的这种设计思想,需要:
- 设计一种数据结构,以最小代价完成稀疏数据的加载与提取;
- 必须面向GPU的分层存储体系;
- 减少对Tensor Core MM Pipeline的影响。
为了解决上面的问题,Flash-LLM提出:
- 新的稀疏格式Tiled-CSL,在Tensor Core上支持按Tile的SpMM;
- 进一步利用寄存器和Shared Memory进行稀疏数据提取,细致设计了Sparse2Dense的转换流程;
- 引入一种高效的“二级重叠”流程,在完整的软件流水线内协调权重的S2D转换、稠密特征图数据加载与Tensor Core运算;
- 提出一种提前稀疏数据重排的方法,进一步降低Shared Memory中的Bank Conflict现象。
2. Background
2.1. Generative Model Inference
Inference Procedure of Modern Generative Models
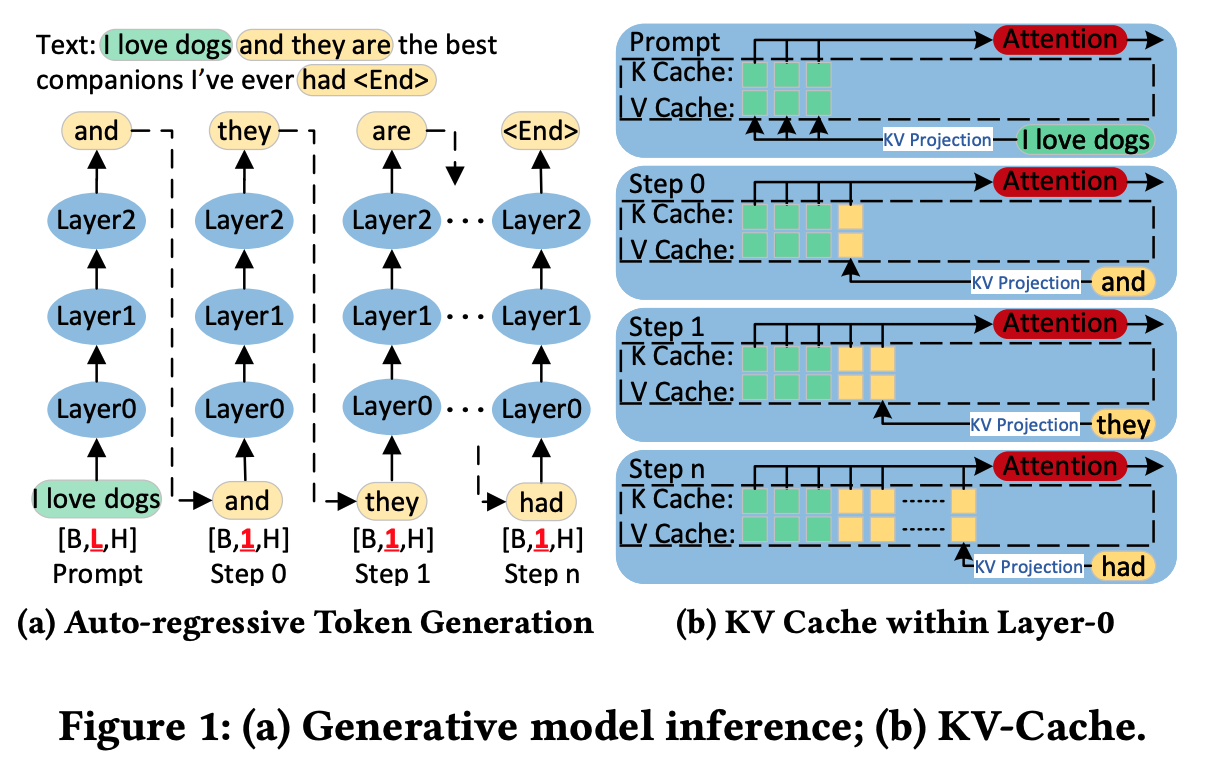
主要是讲Prefill & Decode两个阶段的区别。
Inference Performance Hotspot of LLMs
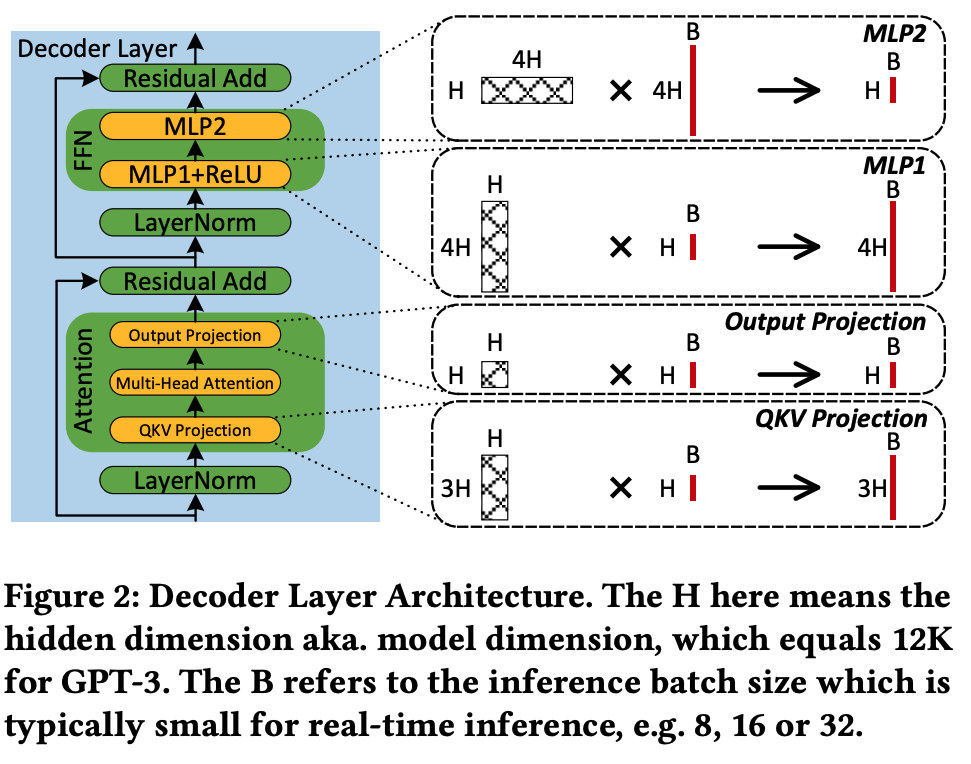
之前Encoder Only的模型主要的性能问题出现在MultiHead Attn中,但是现在的LLM实际上核心的性能问题都是由上图的四个矩阵乘法带来的。上面的四个Matmul是E2E Latency的主要来源,同时也是内存消耗的主要来源。
2.2. Matrix Multiply in LLM Inference
Skinny Matrix Multiply
维度远远小于维度。
Difference between Tensor/SIMT cores
在进行FP32累加的时候,Tensor Core可以提供约于SIMT Core的吞吐。
传统基于SIMT Core的稀疏技术无法直接用在Tensor Core上,因为两者提供的计算粒度完全不同:SIMT基于Scalar工作,可以对单个Element做FMA,但是Tensor Core的单条指令往往完成这种巨大规模的MM,因此不允许任意的element-wise跳过。
3. Opportunities and Insights
3.1. Untructued Sparsity on Tensor Cores
简而言之,结构化剪枝对硬件友好但是精度下降明显,非结构化剪枝可以做到几乎不掉点但是GPU很难利用。
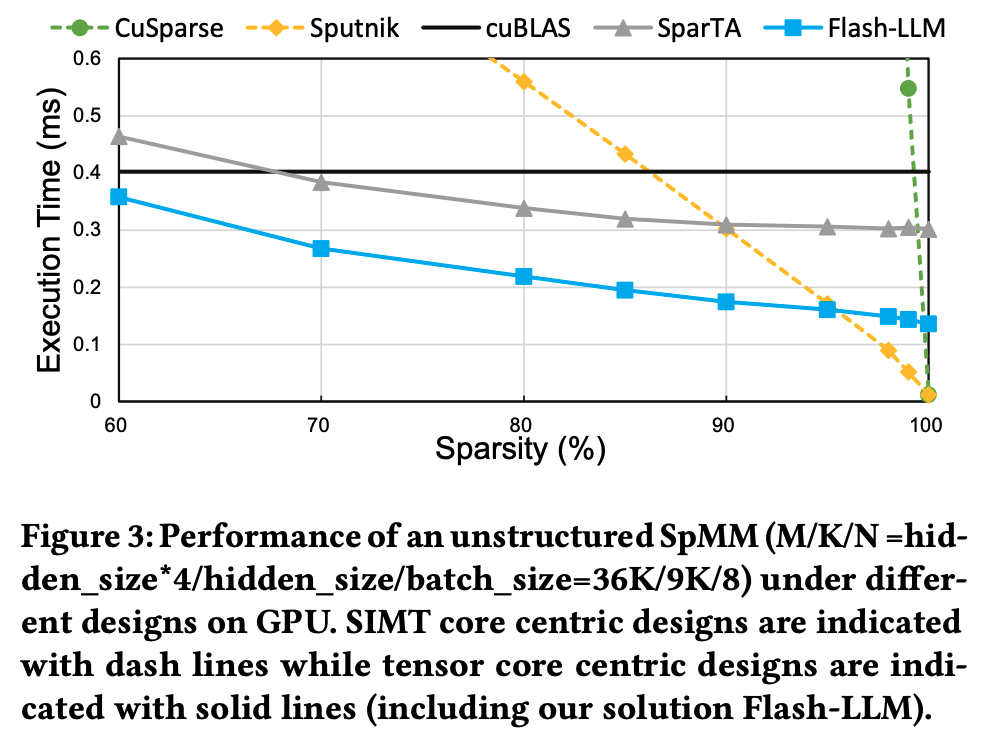
我们观察到,现有稀疏库中的稀疏 MatMul 内核通常慢于 其稠密对照(cuBLAS)。原因在于:cuBLAS 已经使用了张量核心,而这些最先进的稀疏 MatMul 内核仍主要依靠 SIMT 核。由于 SIMT 与张量核心峰值之间存在明显差距 ,LLM 推理迫切需要高性能的非结构化 SpMM 支持。
3.2. Design Opportunities
现代 LLM 推理中的 MatMul 多为瘦长 形态,其计算瓶颈在于片外内存访问/带宽 ,而非张量核心的算术处理。基于此,我们提出“以稀疏加载、以稠密计算 (Load-as-Sparse, Compute-as-Dense)”的基本思路:GPU 内核从全局内存以稀疏格式 加载权重矩阵(减小传输体量),在片上高速缓冲 中重建相应的稠密表示,并在张量核心上计算。关键洞见在于:LLM 推理的瓶颈不在计算侧 ,因此可以容忍 在张量核心上的部分冗余计算。
3.2.1. Performance Bottleneck of Skinny MatMuls in LLM Inference
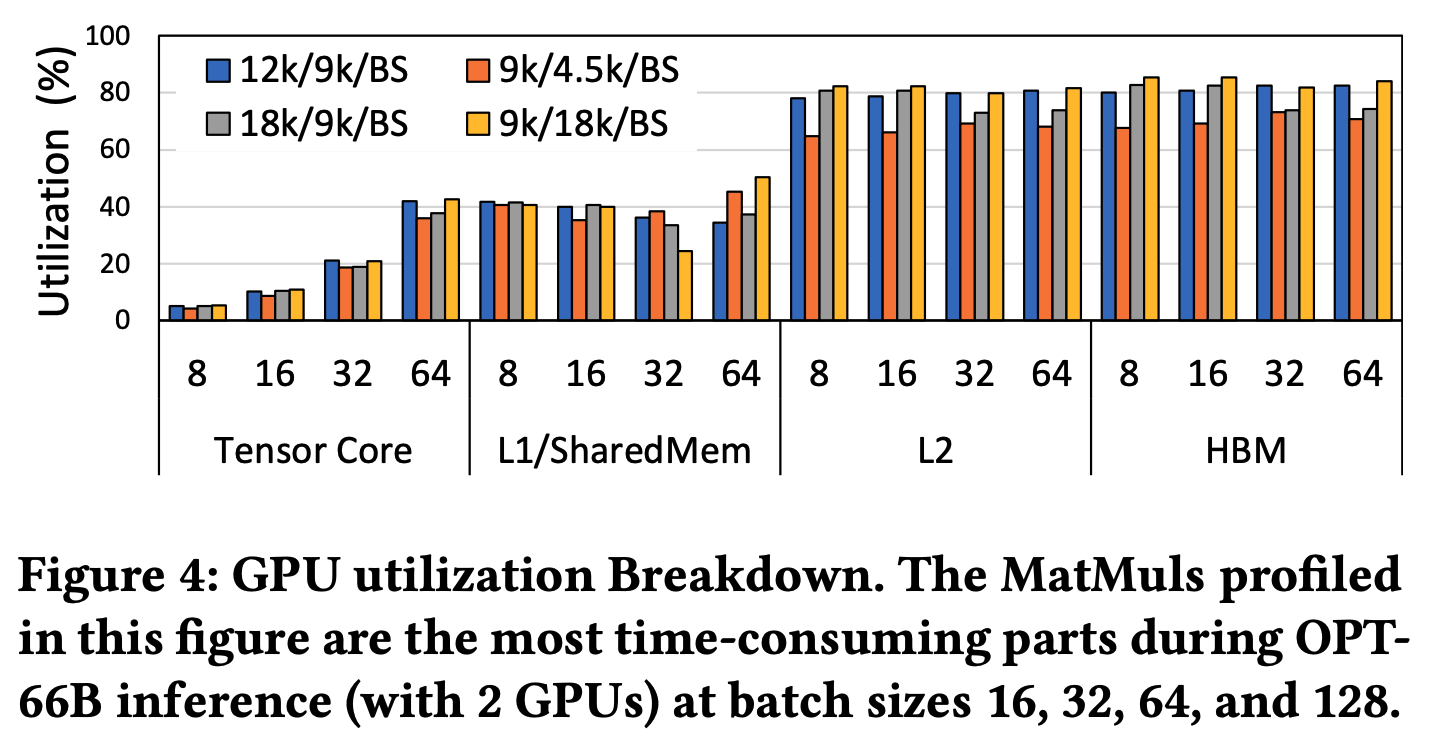
在Batch Size = 8-64的设置下,能看到Tensor Core的利用率大部分时候不超过40%,而L2和HBM已经被完全打满。计算两位 FLOP,按照FP16则读取的数据为字节,因此计算强度:
而计算的相对Skinny意味着就不会很大,如的情况下,。尤其是在生产环境中,就等于BatchSize,而这个数值肯定不会很大。
3.2.2. Load as Sparse, Compute as Dense
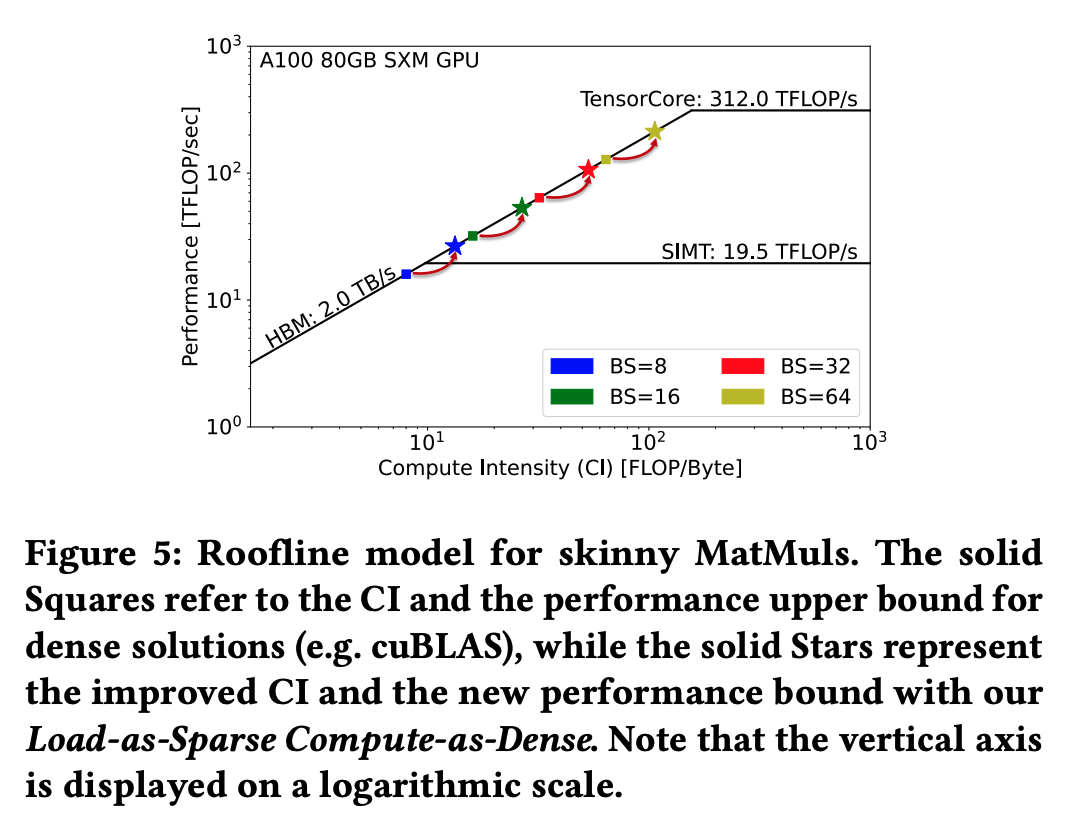
上图方点是原版稠密Kernel,星点是Flash-LLM。Flash-LLM通过Load Sparse, Calc Dense的方法,有:
可以显著提高运算强度。
4. Design Methodology
4.1. Design Overview
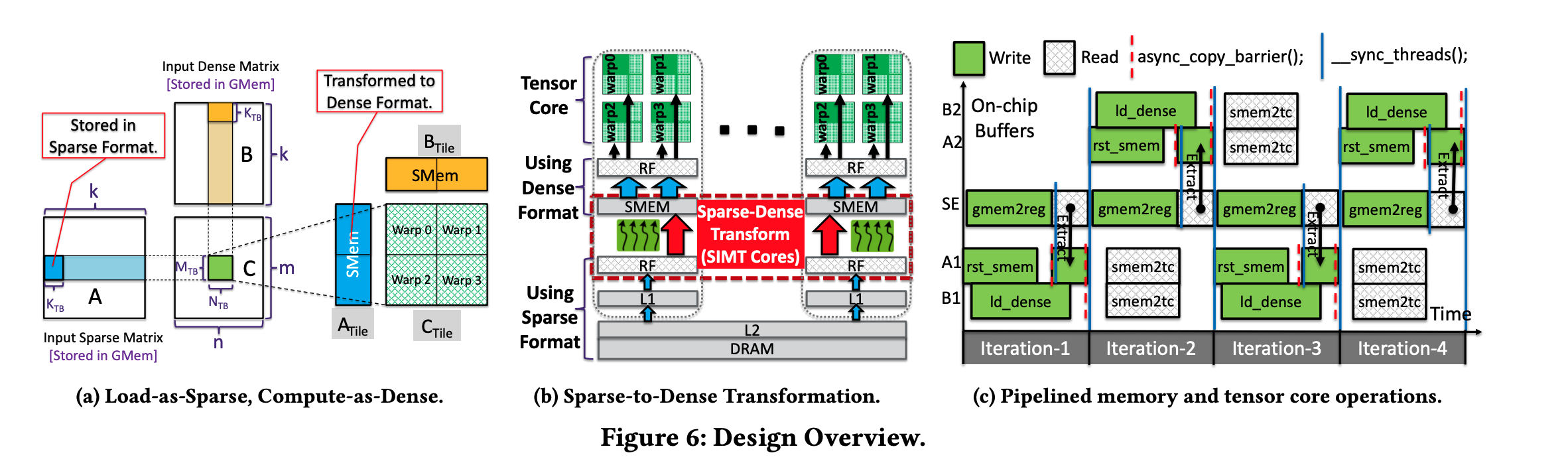
每一个Thread Block负责输出矩阵中的一个Tile()。每次迭代中,每个Thread Block从HBM中加载Sparse存储的()和Dense的(。
随后,通过一个精心设计的转换过程,从稠密转换到稀疏,然后写入Shared Memory中。最后,每个Thread Block消费这些数据,发送到Tensor Core中完成计算并输出。
具体而言,稀疏到稠密转换 的基本思想是:从全局内存上的稀疏编码中提取非零元素,并将其放置到共享内存中稠密布局的对应位置 ,其他位置填零。我们使用分布式寄存器 作为中间缓冲,先暂存非零元素,再将其“抽取”进共享内存;之所以不把共享内存充当此中间缓冲,是为避免对稀疏编码进行“往返式”的共享内存访问。
4.2. Computation Pipeline Design of Flash-LLM
由于每个Thread Block/Warp在计算的时候,都需要预留比较多的寄存器和Shared Memory作为缓冲,GPU的Thread并行度天然的比较低1,因此必须重点优化指令级并行度。
4.2.1. Two-level Overlapping of Memory and Computation
把从HBM中稀疏编码的状态转换到Shared Memory中的稠密状态,需要经过多个阶段:
- 将稀疏编码从HBM加载到分布式寄存器
gmem2reg - 将对应的shared memory位置清零
rst_sms - 将寄存器中的稀疏编码写入到对应的位置
extract - 将dense部分去除直接加载到shared memory中
ld_dense - 最后,从共享内存消费对应的数据发送到tensor core进行计算
smem2tc
在Fig6(c)中可以看到上面的Pipeline中实现了两级的Overlapping:
- inter-iteration overlapping,主要是将片外的加载和和内部的稀疏转换、TC计算等重叠;
- intra-iteration overlapping,主要是将片外加载的各个阶段彼此重叠,高效利用内存系统;
Fig.6c 的横轴为时间、纵轴为双缓冲中的活动状态。系统为配置两块共享内存缓冲(A1/A2),为配置两块共享内存缓冲2(B1/B2),并配备一个在不同迭代中复用的寄存器缓冲 (SE)。具体而言,Iteration-1/3(Iteration-2/4)中的 SE 与 A1(A2)对应于第一(第二)组缓冲上的稀疏到稠密转换流程;B1(B2)对应于第一(第二)组缓冲上的数据搬运。在跨迭代重叠 上,如 Fig.6c 的 Iteration-2 所示:当第一组缓冲上的数据被加载到张量核心并进行计算的同时,Flash-LLM 为第二组缓冲从全局内存加载并抽取 数据到共享内存。在迭代内重叠 上,A1 与 B1 的活动并行进行;并且的
gmem2reg与rst_smem阶段也并行执行。如此就能高效地重叠稀疏数据加载 、稠密数据加载 与张量核心计算 。
稀疏到稠密转换的一项关键设计,是显式使用寄存器 作为全局内存与共享内存之间的数据缓冲。Flash-LLM 明确把稀疏编码从全局内存到共享内存的搬运分成两步:gmem2reg阶段用 LDG 指令(从全局内存加载到寄存器),extract阶段用 ** STS** 指令(从寄存器写入共享内存)。这样做的优点有:
- 更细粒度的拆分,提高了指令并行度,可以更细粒度地控制并行,隐藏高延迟的HBM访问;注意,LDG-STS指令对之间存在读写以来,如果直接在相邻的周期内直接发射,线程执行的数据变为
LDG0, STS0, LDG1, STS1, ...这样,则HBM读写的延迟没有任何隐藏; - 另一方面,数据拌匀被拆分成
gmem2reg和extract两部分,使得gmem2reg和rst_smem之间能够并行。如果在rst_smem完成之前就发射了extract中的STS指令,则写入的数据可能会错误地被rst_smem覆盖。而如果gmem2reg阶段不包含对shared memory的写入,它和rst_smem之间就可以重复执行,进一步提高了指令的并行度。
4.2.2. Minimum Range of Synchronizations and Memory Barriers
由于上面提出的这种Pipeline比较复杂,需要有线程同步和Barrier来保证正确性,但为了性能又需要减少。
为了避免extract写入的数据被rst_smem覆盖,两者之间需要插入Thread Block级别的同步,确保所有thread都完成了对shared memory的清零。同时,还需要另一个同步,确保当前iteration中所有的数据搬运和Tensor Core的计算都已经完成,才启动下一个iteration,因为这些shared memory中的数据会被下一个iteration加载到Tensor Core中作为输入。还需要额外确保所有thread在前一个iteration中读完了register中保存的所有的数据,才能开始下一个rst_smem。
除了Thread Block Sync之外,还需要在HBM2Shared Meory之间的异步复制之间设置Barrier。rst_smem和ld_dense两个阶段都使用安培架构开始引进的cp.async进行复制。具体来说,exrtact只需要等待rst_smem完成,而每个iteration末尾的barrier则需要等待之前的所有的cp.async完成,使得extract和ld_dense之间能够相互重合。
4.2.3. Overall Implementation

在每个iteration中,一方面为了下一次iteration发射异步数据加载指令,另一方面使用double buffer进行当前iteration的tensor core计算。
第一个Barrier在第25行,保证17行中发射的rst_smem都已经完成,然后开始extract,此时第20行的ld_dense也在同步运行。最后调用28行的barrier,保证本iteration的加载和计算都已经结束,再停止当前iteration。
对于Dense的矩阵,tile尺寸就是需要加载的数据量,而稀疏的数据结构中,数据量取决于中的非零元素数量nnz。为此,在加载每个Tile的稀疏编码之前,Flash-LLM在全局元素中定位它的起始位置和长度。为了避免长延迟的HBM读取导致整个指令流stall,还需要每次做prefetch。
4.3. Sparse Encoding and Runtime Parsing
4.3.1. Tiled-CSL Format
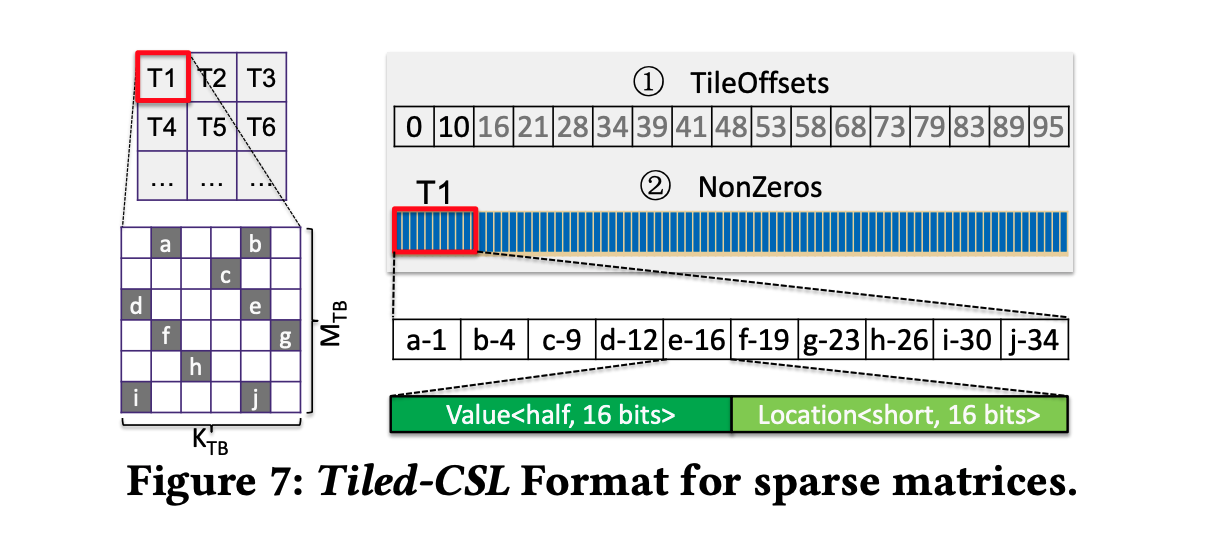
有点像CSR/COO的结合,存Tile内部的局部索引,把CSR里的行指针换成Tile指针,non zeros是所有tile拼在一起拼出来的。这样读数据的时候每个tile内部的数据是连续的,有Tile Offset可以直接O(1)取Tile不需要遍历。但这个数据结构的效率对Tile大小比较敏感,要结合硬件做DSE。
4.3.2. Register to Shared Memory Data Extraction based on Tiled-CSL

使用GPU上的寄存器保存内容的时候必须注意,GPU寄存器是不可寻址的,因此也无法用下标访问“寄存器数组”。如果需要强制把CUDA定义中的数组存入寄存器,访问这个数组的所有下标在编译期必须是静态可确定的 ,否则数组会被放回HBM中。
代码中需要完全展开整个循环,并且将循环上界设为#REG代替。
4.3.3. Ahead of Time Sparse Data Reordering
稀疏权重计算中涉及到两类shared memory的访存:
smem2tc阶段为了tensor core计算执行的shared memory读;extract阶段的shared memory写。
良好的性能要求上面尽量避免bank conflict,但是随机的稀疏模式会让两类访存都难以规避bank conflict问题。
在smem2tc阶段,可以使用ldmatrix内建指令高效地加载到tensor core上。
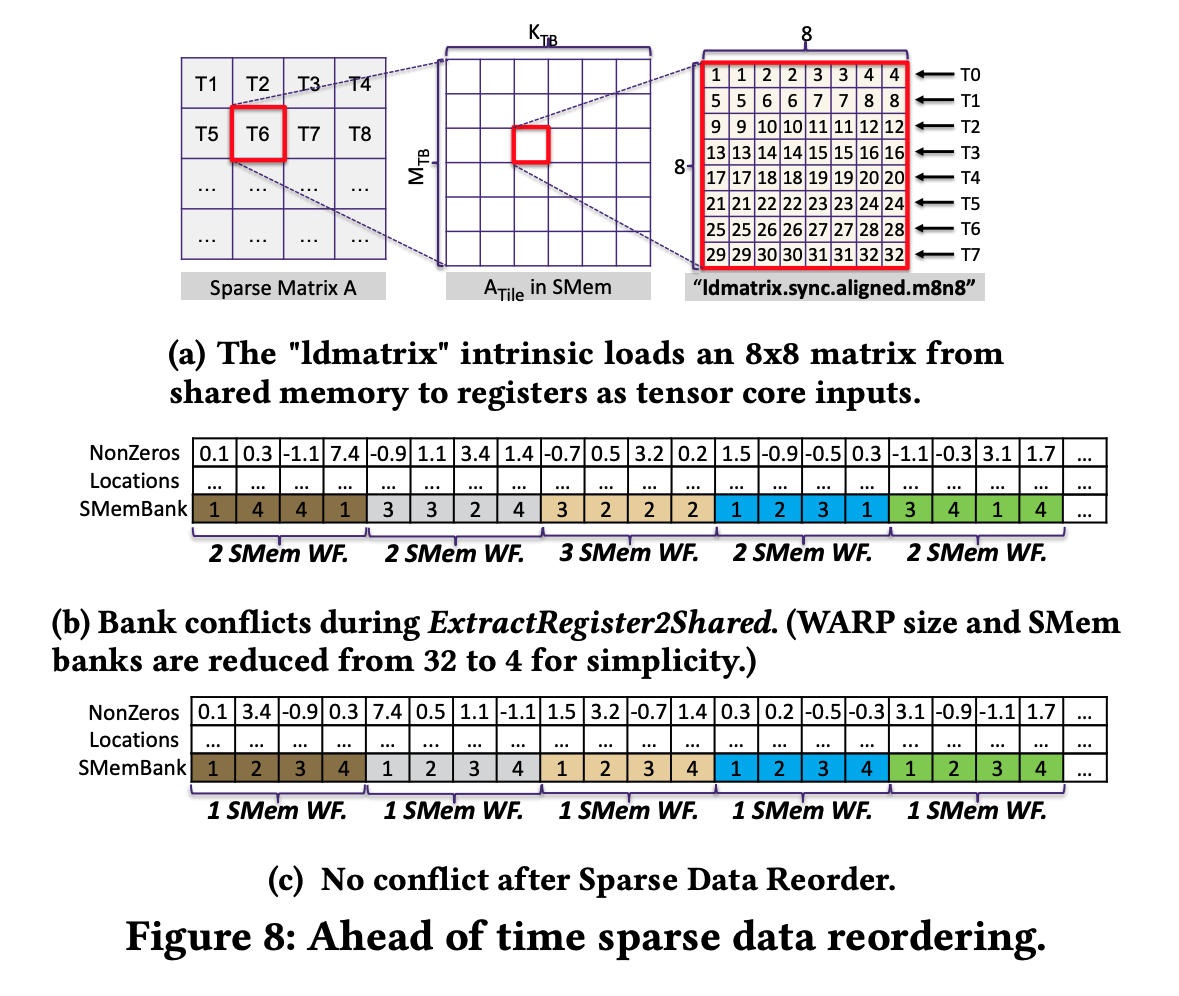
上图可以看到ldmatrix指令的行为:8个thread从shared memory中加载一个的FP16子矩阵;若没有任何bank conflict,一个shared memory wavefront就能完成加载。一个很直观的想法是,可以通过Tile内的位置来分配bankID,这样可以很轻松地保证ldmatrix阶段没有bank conflict。但是,这样的布局很容易让extract阶段的shared memory写发生bank conflict,因为的非零位置是随机的。
为了解决上面提出的这种问题,本文提出一种ahead of time sparse data reodering方法。基本的insight是:ldmatrix的无冲突约束已经决定了每个目标元素的bank,因此我们可以在每个Tiled-CSL内部对nnz元素进行重排,使得不同bank内部的元素能够落在同一个warp的extract阶段成组地处理(因为extract阶段对元素在tile内部的分布顺序并不感兴趣,只是读取index和value然后写到对应的寄存器上)。
5. Implementation
我们提供了一组用于高性能 Flash-LLM 内核的 C++ API,并将其集成到 FasterTransformer中,以便在稀疏化权重 条件下实现高效的分布式推理 。具体实现包括:
- 扩展相关类定义(如
DenseWeight类)以支持 Tiled-CSL 格式; - 扩展库封装(如
cuBlasMMWrapper类),使其能根据输入数据格式自动在稠密 MatMul 库 与 Flash-LLM SpMM 内核 之间切换。
此外,Flash-LLM 可通过其 API 轻松集成到其它深度学习框架中。我们还提供了权重重格式化工具 ,能够将预训练的稠密 PyTorch 模型转换为 Tiled-CSL 格式的稀疏矩阵。
在实现中,我们将 Fig.6a 的分块尺寸设为: 或 ,;当 MatMul 的维度(推理批大小)为 时,相应取值;当 更大时,。线程块大小固定为。这些配置在第 6 节评测的工作负载上表现良好,且可针对其它负载轻松调整 。需要注意的是,配置调优不属于 本文研究范围。
6. Evaluation
所有实验在 NVIDIA A100-SMX8-80GB 平台上进行(CPU:128-核 Intel Xeon Platinum 8369B @ 2.90 GHz;GPU:8×NVIDIA A100 80 GB),操作系统 Ubuntu 18.04、CUDA 11.8。全部评测均启用自动混合精度(AMP)。
6.1. Kernel Performance
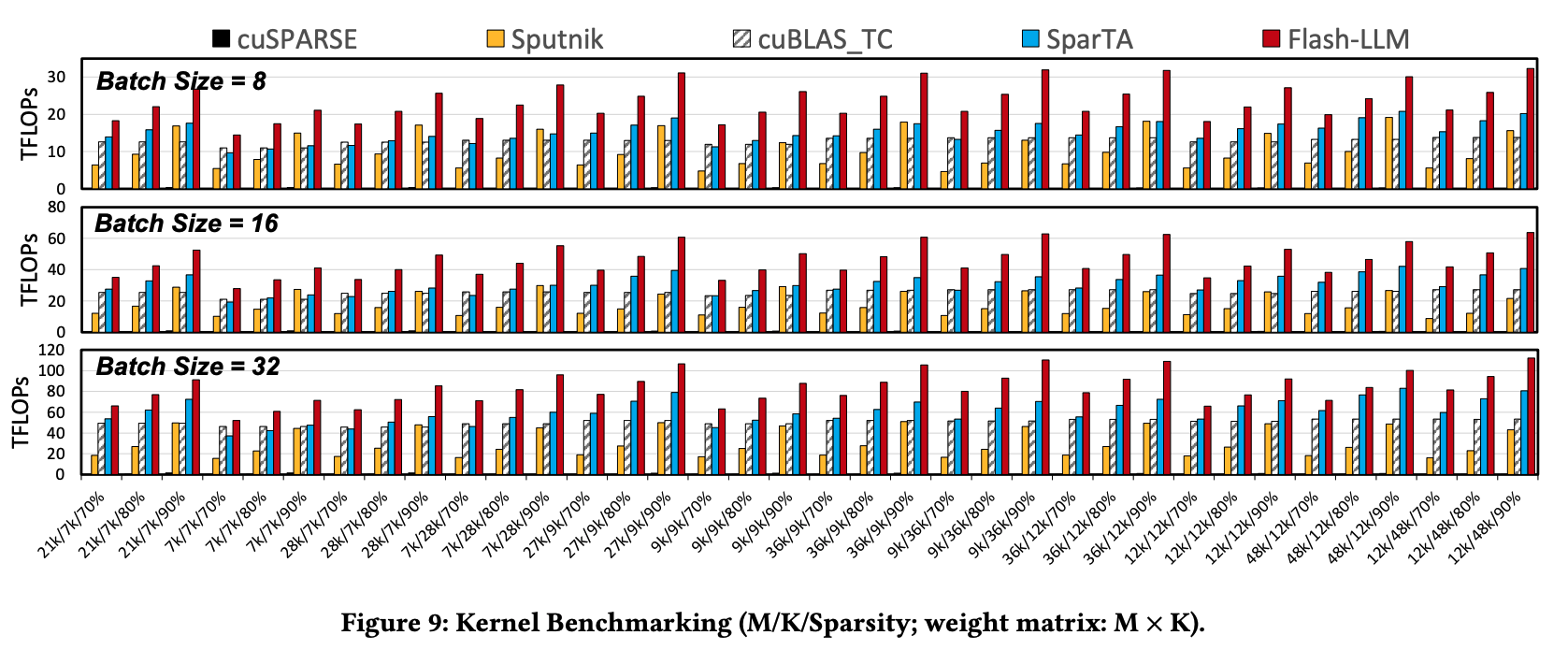
SparTA可以利用Sparse Tensor Core进行计算,但是当稀疏度高于50%的时候,它反而需要额外填充0补全到50%从而适应Sparse Tensor Core的数据流,增加了额外的HBM访问。
6.2. Kernel Analyze
Optimized GPU Utilization
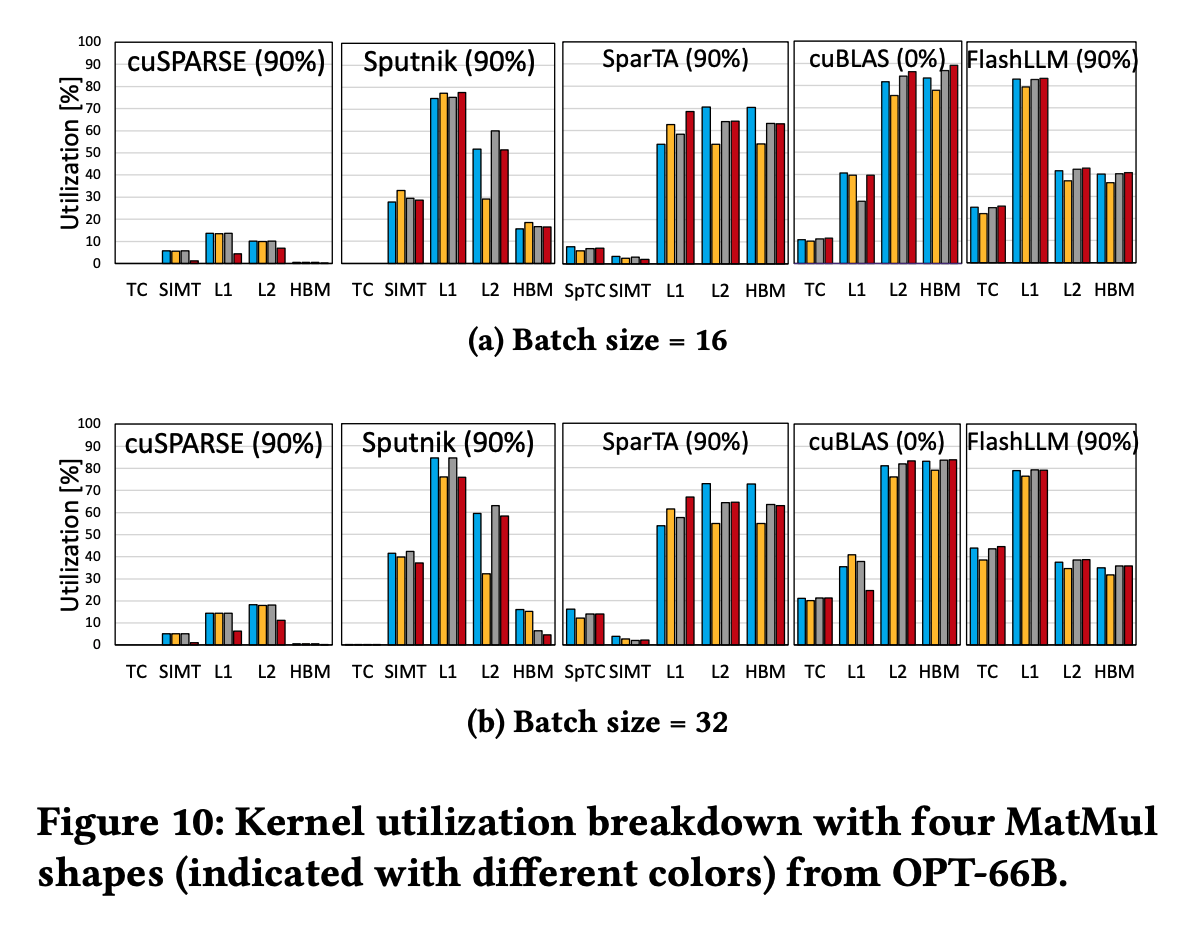
可以明显看到,Sputnik虽然取得了比较高的SIMT利用率,但是Tensor Core的算力实在太高了;而对于cuBLAS,在的时候L2 Cache的带宽就已经用完了,Tensor Core算力无法进一步提升。
Balanced pipeline for memory/tensor core operations
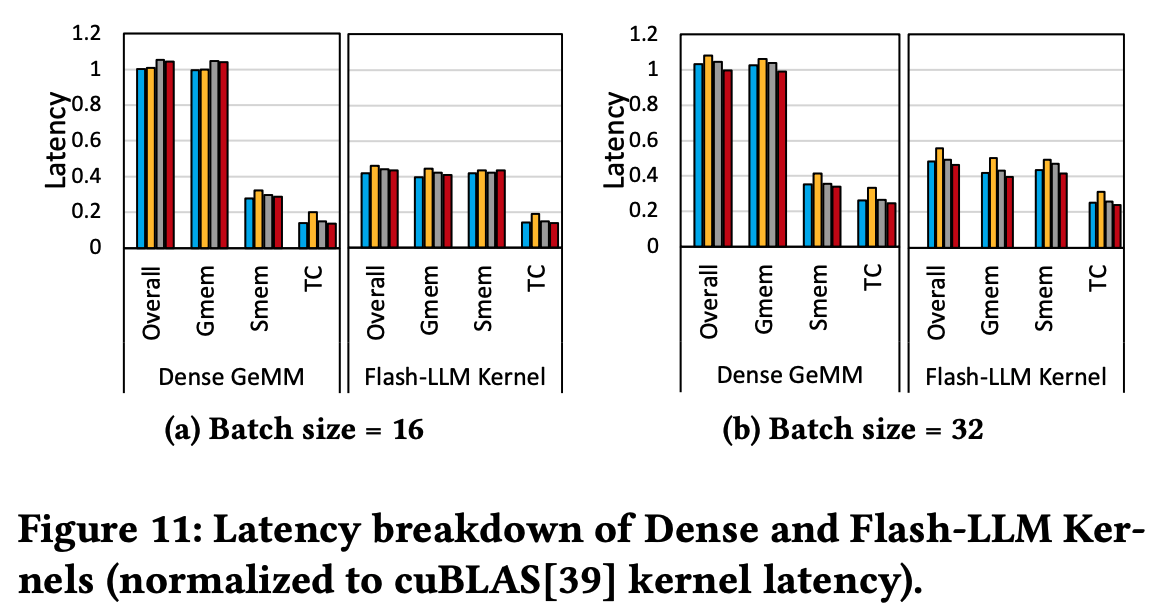
Tensor Core latency其实和Dense的没什么区别,只是降低了存储的瓶颈。
Performance on more Matmul shapes
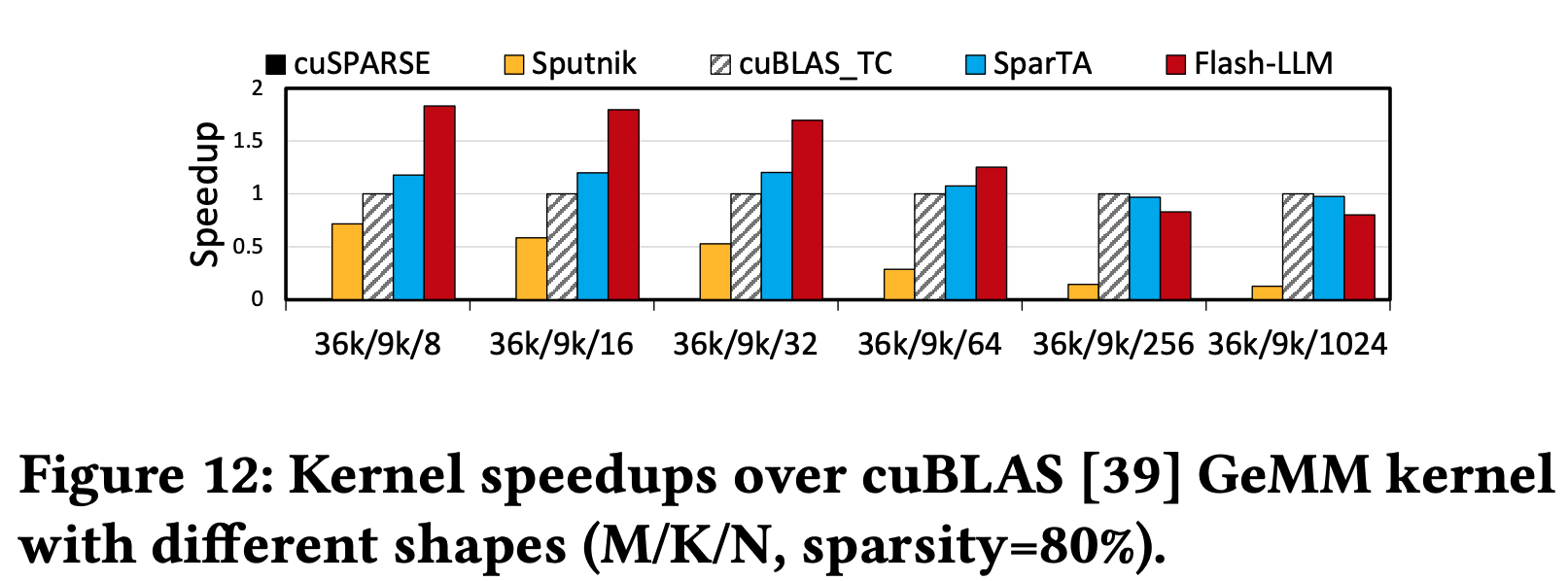
当足够大的时候,由于cuBLAS的效率越来越高,而Flash-LLM的方法中Kernel更复杂、shared memory访问更多,小幅开销更多,最终导致性能被cuBLAS反超3。
6.3. End-to-End Model Evaluation
6.3.1. Case Study: OPT-30B Model Pruning
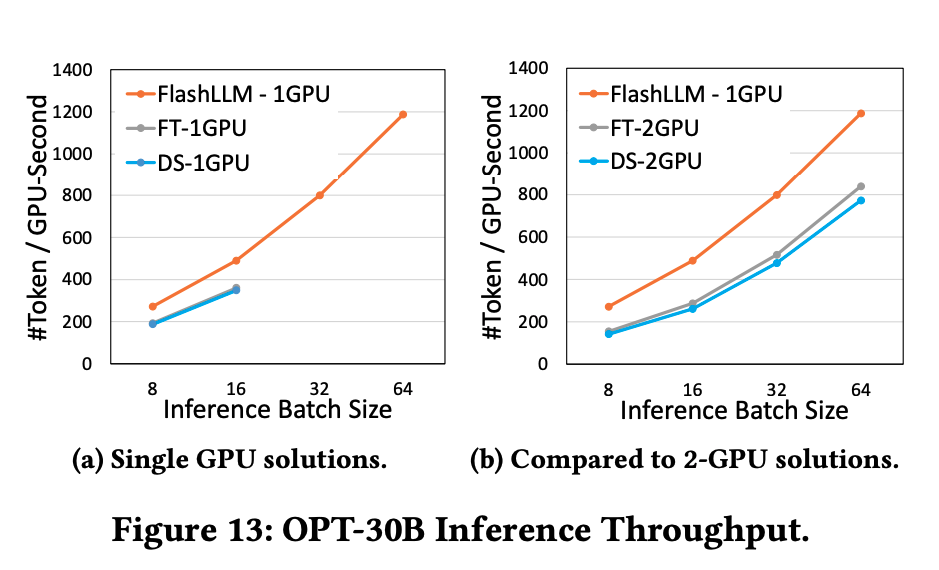
单卡上相比DeepSpeed & FasterTransformer有提升,主要是因为Tiled-CSL降低了权重存储所需要的显存,能够容纳更多KV-Cache和Activation。
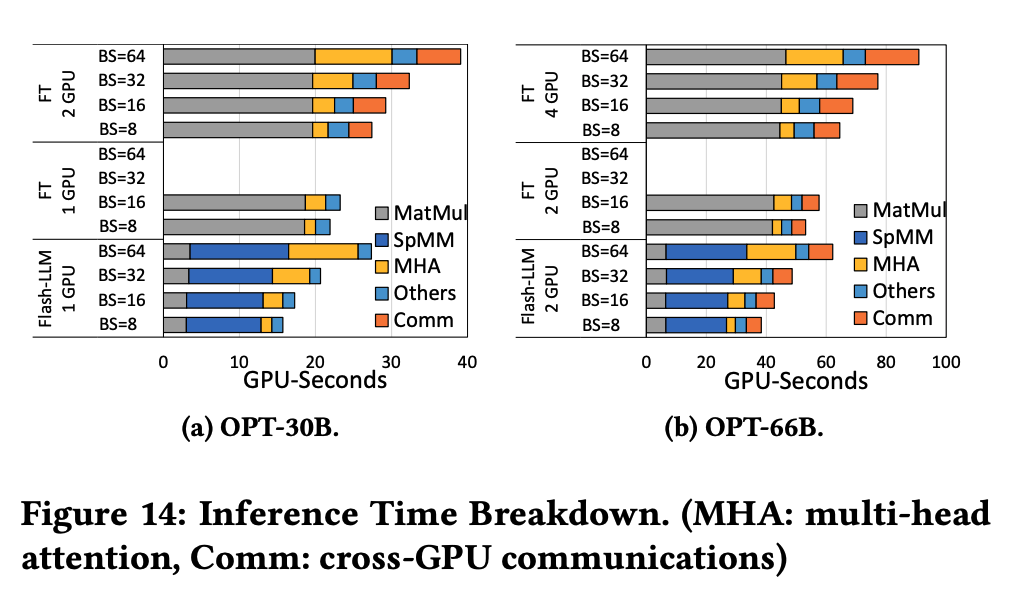
6.3.2. Case Study: OPT-66B
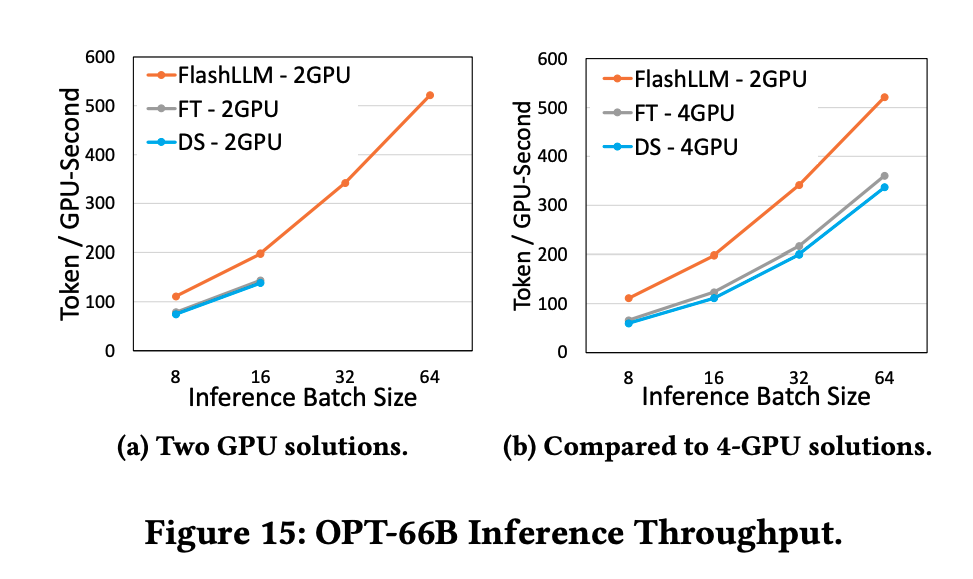
情况是类似的,主要是因为减少了Matmul和跨GPU通信的时间。
6.3.3. Case Study: OPT-175B
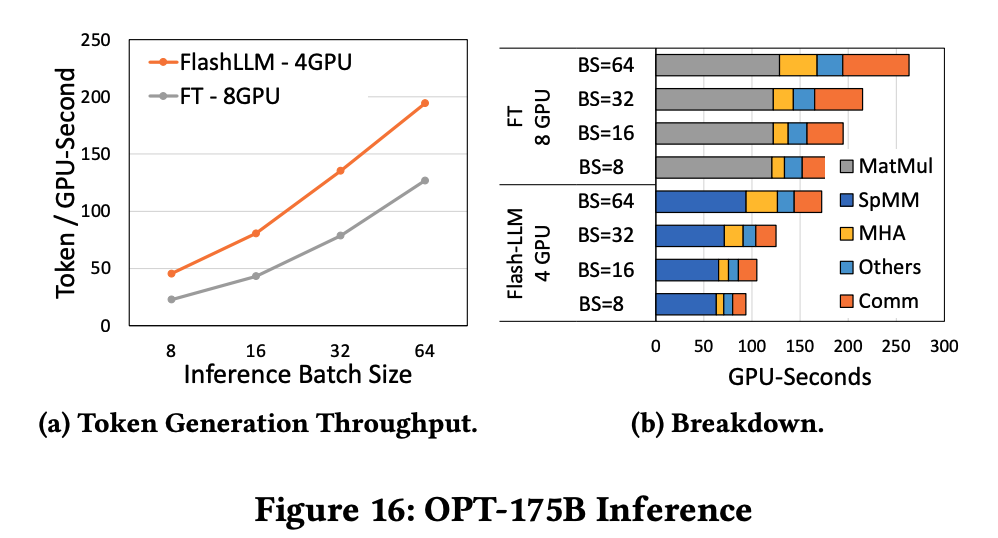
使用本方法可以运行而其他方法不行。
7. Related Work and Discussion
非结构化稀疏 不对分布施加结构约束,因而在现代硬件上难以加速。CPU 侧如 STOREL 、TACO能支持非结构化 SpMM;而 Flash-LLM 聚焦 GPU 侧的非结构化 SpMM(GPU 通常具备更高的带宽、算力与能效)。在 GPU 上执行非结构化 SpMM 的典型做法是SIMT-based:如 cuSPARSE、ASpT、Sputnik。在中等稀疏(<90%)下,Sputnik 明显优于 cuSPARSE 与 ASpT,但由于无法利用张量核心,难以超越其稠密对照 cuBLAS 。TC-GNN 在张量核心上支持非结构化稀疏,但其为 GNN(通常 >99% 稀疏)定制,不适合需要中等稀疏的生成式模型。SparTA 通过将原始稀疏矩阵拆分为(1)供张量核心执行的 2:4 结构化稀疏(借助 cuSPARSELt),与(2)供 SIMT 内核执行的非结构化稀疏(借助 Sputnik)来支持非结构化稀疏。但当稀疏率较高时,2:4 路径需要大量零填充;且若不满足 2:4 的非零过多,SIMT 内核会导致高时延,拖慢整体。Flash-LLM 能在张量核心上高效支持中等稀疏,且无需 2:4 类分布。SparseTIR通过把稀疏矩阵拆成 8×1 列向量并跳过全零向量来在张量核心上支持非结构化稀疏;但在 80% 这类中等稀疏下,能被跳过的向量很少,其性能在稀疏度 >95% 前无法超越稠密基线 cuBLAS,而 Flash-LLM 在60% 稀疏时即可超越 cuBLAS。
8. Conclusion
我们提出了 Flash-LLM——一个利用张量核心在非结构化稀疏性下实现高效大型生成式模型推理的库。我们观察到,生成式模型推理中的矩阵乘(MatMul)通常呈“瘦长(skinny)”形态,其性能受片外内存访问所限。为此,我们提出“以稀疏加载、以稠密计算”(Load-as-Sparse, Compute-as-Dense)的张量核心 SpMM 方法,既减少全局内存占用、缓解内存访问瓶颈,又能容忍瘦长 MatMul 的冗余计算。我们进一步设计了面向张量核心的非结构化 SpMM 高效软件流水线,高效利用片上资源进行稀疏数据提取,并将稀疏数据提取、稠密数据加载与张量核心计算以重叠方式协同推进。在 70%/80%/90% 稀疏度下,Flash-LLM 分别较 cuBLAS / Sputnik / SparTA 提升 1.4× / 3.6× / 1.4×、1.7× / 3.0× / 1.4×、2.1× / 2.0× / 1.6×。我们将 Flash-LLM 内核集成至 FasterTransformer,用于端到端的生成式模型推理。以“每 GPU·秒生成的 token 数”为指标,Flash-LLM 在 OPT-30B/66B/175B 模型上相较 DeepSpeed 与 FasterTransformer 分别可获得最高 3.8× 与 3.6× 的提升,且推理成本显著更低。