摘要: 专用硬件加速器被广泛用于稀疏张量计算。对于无法完整装入片上缓冲的超大张量,分块(tiling)是一种能够提升这些稀疏加速器数据复用率的有前景方案。然而,现有稀疏加速器上的分块策略要么完全依赖动态调度,导致设计复杂度高;要么完全静态,并使用简单启发式方法,适应性不足。此外,这些方法既未充分探索分块的完整设计空间来寻找最优方案,也未能有效管理分块所需、且不可忽视的元数据。为此,我们提出 HYTE ——一种混合静态-动态框架,可在稀疏加速器上实现灵活且高效的分块。HYTE 首先依赖静态离线调度器,通过高效且轻量的采样,确定近似最优的初始分块方案。块的大小与形状、跨块的维度迭代顺序以及缓冲区分配策略都可灵活配置,以适应特定的数据稀疏模式。随后在运行时,HYTE 提供对片外存储器和片上缓冲中分块元数据的高效管理,并通过动态调整块形状,确保在局部数据模式高度变化的情况下仍能保持较高的缓冲利用率。评估结果表明,HYTE 在多种稀疏矩阵上平均性能优于最新稀疏分块策略 3.3× – 6.2×。
1. Intro
如果稀疏矩阵巨大,依旧要进行分块,但是稀疏数据的分布不均匀让分块做起来比较复杂,如果某个块内的元素太多会导致SRAM溢出,太少则data reuse很差。
目前的稀疏加速器尝试通过:
- 运行时动态分块,调整块大小
- 静态启发式,轻度超配缓冲空间
来提高分块的利用率,但两者都存在问题:
不幸的是,纯动态分块因实现复杂度高,不得不将决策范围限制在少数选择;纯静态分块在数据稀疏度变化显著时又往往效率不足。此外,我们发现先前设计并未充分探索分块的完整设计空间:许多设计参数——包括块形状、跨块迭代顺序以及不同操作数在 SRAM 中的相对分配空间——都被固定,因而在张量稀疏模式多样时难以取得最优。与此同时,为支持分块而引入的元数据(例如各块中压缩非零数据的起止位置)也可能带来显著开销,需要硬件精心管理。
本文提出HYTE:一种混合的静态-动态框架,实现高效灵活的稀疏分块。
Contribution:
- 揭示 现有稀疏加速器在分块设计空间(块大小、块形状、跨块迭代顺序、缓冲区分配策略)探索上的不足。
- 提出 一种面向稀疏加速器的静态离线调度器,利用轻量采样自适应地为各类稀疏模式寻找近似最优分块方案。
- 设计 一套硬件架构,支持对块形状的动态调优以保证高缓冲利用率,并在片外/片内高效管理分块元数据。
- 整合 上述技术,构建了一种混合静态-动态框架,实现灵活而高效的稀疏分块,在多种稀疏矩阵上显著优于现有方法。
2. Background and Related Work
2.1. Sparse Tensor Algebra
为避免对零值的无效计算,稀疏张量通常以压缩格式存储,如 坐标格式 (COO)、压缩稀疏行/列 (CSR/CSC),以及它们的块变体(如块 CSR)。这些格式通常把张量维度组织成层级结构,每层由 fibers 组成,即一串有序坐标及对应的非零值。位置 (position)表示一个点在存储中的实际地址;由于压缩掉了零和空指针,其位置常与坐标不同。
2.2. Sparse Tensor Accelerators
Sparse dataflow
主流数据流:Inner Product, Outer Product, Gustavson,由外到内循环顺序分别为:
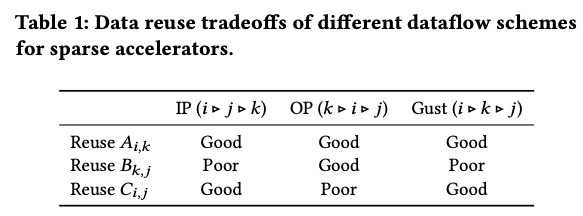
可以看到三者的数据复用倾向有区别。
关键在于:若某张量的“无关”维度(如的)位于内层循环,则该张量可在相邻迭代间重用,复用性优异;若该维度在最外层,则需要反复整幅扫描,易冲刷掉有限的片上缓冲。基于此权衡,有的设计支持多种可运行时切换的数据流,以适应输入张量的多样稀疏模式。
Buffer management
传统硬件管理的高速缓存对专用加速器并不高效。“显式解耦数据编排 ”(EDDO)因而成为缓冲管理范式:计算单元与各级缓冲解耦,通过专用地址生成器尽早预取数据;每级缓冲采用私有地址空间,无需缓存标记开销。
根据数据流,部分张量的访问模式十分不规则,应缓存在片上反复使用,以减少昂贵的片外访问;而呈流式访问、时间局部性较弱的张量仅需极小缓冲。
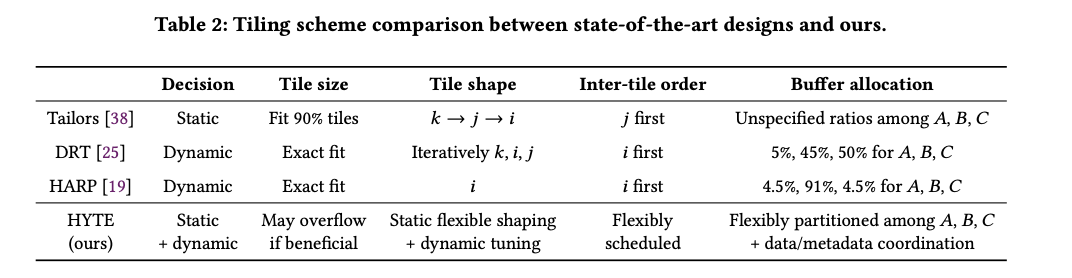
2.3. Tiling in Sparse Accelerators
稀疏Tiling主要可以分为:
- Coordinate Tiling坐标分块,按固定坐标跨度切分,各块在同一维度要么完全重合,要么不相交,简化了坐标匹配;但由于局部稀疏度不同,各块大小差异大,易造成缓冲溢出或利用率低。
- Position Tiling位置分块,按实际数据量(在存储格式中的位置)将张量均匀切分,使各块大小一致;然而块间坐标范围无对齐,管理复杂。
3. Motivation
3.1. Tile Parameters
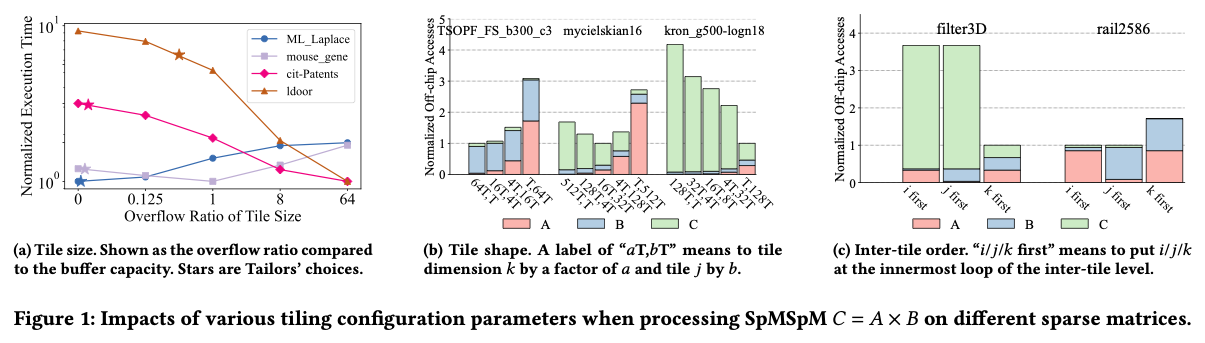
图 1a 以 SuiteSparse 中不同稀疏矩阵的自乘为例(采用 Gust 数据流、16 MB 片上缓冲),展示了块大小对性能的影响。横轴为块大小相对缓冲容量的 溢出比例——例如 “1” 表示块大小是无溢出情况下的 2 倍。可见:
- ML_Laplace 在无溢出时性能最佳;
- mouse_gene 在 2× 溢出时表现最好;
- ldoor 与 cit-Patents 则倾向几乎不分块的更大块。
其原因在于数据模式差异:例如 cit-Patents 极为稀疏,平均每列仅 4 个非零,数据复用机会有限;若分块因子超过 4,重复访问开销将大于复用收益。图中各线的星号为 Tailors 采用“10 % 超配”时的选择,对多数矩阵都非最优。
Takeaway1: 简单地让块大小恰好填满缓冲或按固定溢出比例超配,并非总是最佳;当重复访问开销超过复用收益时尤为如此。
即便块大小相同,块形状 也会显著影响性能。图 1b 在保持坐标体积不变的前提下,比较了不同块形状的片外访问量:
- 对近对角矩阵 TSOPF_FS_b300_c3 ,C 较小,优先沿收缩维 k 分块、重复抓取 C 最佳;
- 对幂律图 kron_g500-logn18 ,C 的访问占主导,仅沿 j 分块、重复抓取 A 更优;
- 结构化矩阵 mycielskian16 介于两者之间,需要在两维上平衡形状才能最优。
Takeaway2: 在块大小固定时,各维坐标跨度的最优组合取决于具体张量的数据模式。
3.2. Control Schemes
- 纯静态 只能用启发式参数优化平均情况。Tailors 的 “10 % 超配” 在图 1a 中经常非最优。
- 纯动态 要么需显著元数据开销(如 DRT 的 32×32 微块 ),要么受限于简单但低效的分块方式 。
Takeaway3: 纯静态分块难以最优,纯动态分块代价过高,二者结合可望兼取其长。
它影响已抓取块的复用,而这与 块内执行顺序 (由硬件实现的数据流固定,见表 1)不同。由于矩阵大小与稀疏度各异,某些场景需优先复用特定张量,因此应支持多样的块间顺序。在图 1c 中,两个矩阵均使用 Gust 数据流且三维平均分块:
- 对 filter3D ,令无关维 k 置于最内层(先 k)以复用 CC 更为关键;
- 对 rail2586 ,此举收益较小。
Takeaway4: 硬件应支持可配置的块间执行顺序,以适应不同张量数据模式。
3.3. Buffer Management
要实现上述灵活分块及控制,缓冲区 亦需相应增强。首先,不同的块间顺序通常只将三个操作数中的一个完整缓存在片上,其他张量流式访问,因此缓冲容量在各张量之间的划分必须灵活。此前方案的固定分配(表 2)难以满足多样需求。其次,动态分块会显著增加 元数据 量及管理成本——不仅包含原压缩格式的索引结构,还有分块新增的元数据(如块内纤维段的起止位置)。
在我们评测的矩阵中,元数据与实际数据量之比的均值和方差分别为 0.27 和 0.51;在极稀疏且分块细粒度的 kron_g500-logn18 中,这一比值高达 3.2×;而在较稠密、分块较粗的 nd24k 与 TSOPF_FS_b300_c3 中,则仅 < 0.02×。因此,让数据与元数据灵活共享同一缓冲空间更为高效。
Takeaway5: 应在不同张量之间、以及数据与元数据之间,实现缓冲容量的灵活分配与高效管理。
4. HYTE Overview
继续基于坐标分块,基于takeaway3需要采用动静态相结合的方法:
- 静态离线阶段
- HYTE 采用轻量级 调度器 ,深入而高效地探索设计空间,决定初始执行方案:
- 块大小、块形状 与 块间顺序 (对应 Takeaway 1、2、4 );
- 必要时选择更大的块,甚至在数据复用不足以抵消重复访问开销时 禁用分块 ;
- 利用张量大小与稀疏度信息,挑选总体数据复用最佳的块形状和块间顺序;
- 对未知信息(如输出张量 C 的稀疏度)采用高效且轻量的采样估计;
- 根据块间复用分析,灵活分配 缓冲空间:为需复用的张量保留最大容量,仅给流式张量预留最小空间(对应 Takeaway 5 )。
- 由此得到的初始方案已接近最优,可直接供硬件执行。
- HYTE 采用轻量级 调度器 ,深入而高效地探索设计空间,决定初始执行方案:
- 动态在线阶段
- 硬件按给定的块间顺序逐块处理,每块数据进入其静态划分 的缓冲区。
- 为支持灵活分块,HYTE 需维护更复杂的元数据来记录块化纤维段的存储位置。框架在 片上缓冲 与 片外存储 两级联合管理数据与元数据(再次呼应 Takeaway 5 ),分别服务块内和块间执行。
- 同时,HYTE 基于实时局部稀疏模式进行 动态调优 ,以保证缓冲利用率最大化:
- 当局部区域比预期更稀疏或更稠密时,静态确定的块大小可能造成缓冲浪费或溢出;
- 硬件会动态调整块形状 ,使其更契合缓冲容量(对应 Takeaway 1、2 )。
- 调优逻辑仅依赖廉价计数器和简单启发式,相较先前复杂设计成本极低;由于初始方案已近最优,动态调优只在偶发误差时介入修正。
5. Scheduling Algorithms

离线采样估计有效的MAC数,在线对这个估计进行微调,同时根据经验对在线估计空间进行剪枝并且设计cost model.
5.1. Sampling and Estimation

主要需要统计:
- effMAC, 期望的有效MAC数
- nnzC_Tk,在沿着K按照T_k的分块factor访问的过程中,输出的C的非零访问量
5.2. Search Space Pruning
设计空间包含 块形状 、块间执行顺序 、缓冲区分配 三类参数。
- 块形状
- 仅考虑各维长度为 2 的幂次,组合数为 。
- 若块形状沿块内最外层循环对应的维度(如 Gust/IP 的 i,OP 的 k)分块,则无收益,可剔除,剩 。
- 若某形状在所有维度均小于另一可行形状,则必然浪费缓冲,也可剔除。
- 块间顺序
- 只有最内层循环 决定跨块复用。3 个张量 3 种选择(i、j、k 何者最内层),只需考虑 3 种而非 6 种全排列。
- 缓冲区分配
- 首先满足块内数据流对不规则张量 的缓存需求;
- 再根据块间顺序,决定是否为被复用张量保留额外空间。
- 两种选择(仅块内复用 / 块内+块间复用),组合为 3+1=4 个候选。
综合起来,搜索空间上限约为 —— 数百个方案,可在极短时间枚举完毕
5.3. Cost Model
- Tiles =
- PE 时间 =effMAC/吞吐率effMAC/吞吐率
- SRAM/DRAM 时间 由访问量 ÷ 带宽得到;访问量需考虑:
- 块内数据流 (表 1)对各张量天然的复用/放大;
- 分块 导致的重复访问;
- 缓冲模式 :若块尺寸 ≤ 缓冲分配,则按复用次数折算;否则按命中率折算;
- 元数据 开销:按块内纤维段数量估算读写次数,再与数据访问同样放大或缩小。
5.4. Case Studies
6. Hardware Architecture
6.1. Overview
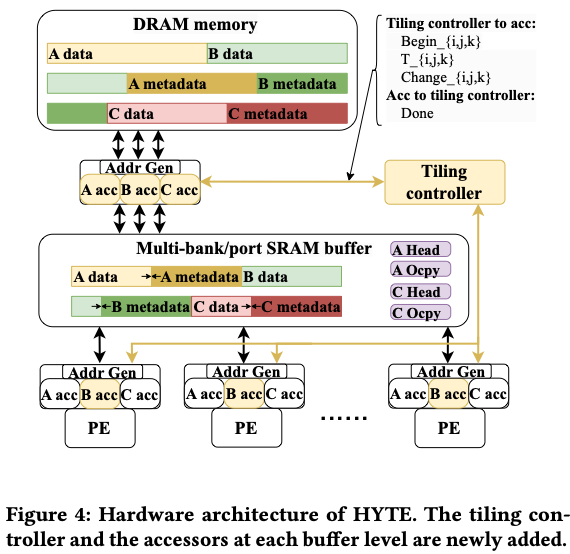
HYTE 主要新增两类硬件组件(阴影部分):
- 分块控制器 :负责整体分块方案的执行;
- 张量访问器 (A/B/C acc):负责将“分块纤维段”取入缓冲,并管理相应元数据。
这些改动仅涉及缓冲控制与数据访问逻辑 (control plane),并 不改变 PE 的计算数据通路 (data plane)。
工作流程
- 分块控制器 装载离线调度器生成的初始方案。
- 控制器依据 块间顺序 与 块形状,在每次块间迭代后决定下一块;相关坐标信息发送给各访问器。
- 访问器 依方案把各张量相应块取入缓冲,并按预先分配的容量管理。
- 我们在 Buffets 的设计上扩展:访问粒度由单元素提升为 “具有起/止坐标的纤维段”。
- HYTE 需有效管理元数据,以便在任意块间顺序下,能由坐标快速得到纤维段的 物理位置 。以往方案要么仅支持固定维度、元数据简单,要么依赖代价高昂的预处理。
- § 6.2 说明跨块元数据的 DRAM 管理;
- § 6.3 说明块内元数据与数据在 SRAM 中的协同排布。
- 最后,HYTE 在硬件中支持 块形状动态调优 ,利用少量计数器搜集运行时统计,并用简单模型实时修正静态方案,进一步提升缓冲利用率。
6.2. Inter-Tile Management
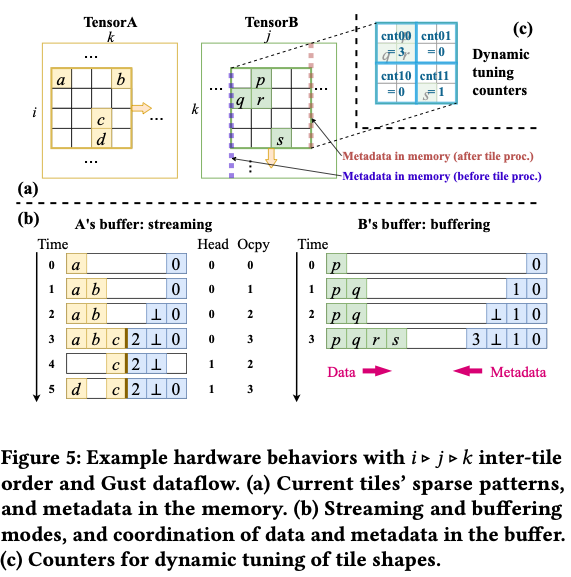
调度好的块间顺序下,分块控制器通过图 4 右上角信号通知访问器下一块的信息:
| 信号 | 含义 |
|---|---|
| Begin_i / Begin_j / Begin_k | 当前块起始坐标 |
| T_i / T_j / T_k | 当前块形状(若经动态调优,可能与静态方案不同) |
| Change_i / Change_j / Change_k | 三态控制:0 = 坐标不变;1 = 沿该维前移一个 T;2 = 复位到 0 |
例如,块间顺序为 时,控制器会连续发送 (0, 0, 1)…,直到最内层迭代结束时发送 (0, 1, 2)。
除了取数,访问器还需维护 纤维段位置元数据 。在取纤维段的过程中,访问器一边顺序递增 position 指针 ,一边检测是否越过块边界;遇界即认定下一个 segment 开始。
- 所需元数据量取决于 块间顺序 与 张量压缩格式 。
- 例:块间顺序 ,且 A,BA,B 均为 CSR 。如图 5(a):
- AA 的迭代方向与其纤维 (row) 保持一致,仅需维护本块内 个 position;
- BB 则需追踪一整列块,可能达到 级别。
- 例:块间顺序 ,且 A,BA,B 均为 CSR 。如图 5(a):
- 因需求多变、规模潜在很大,HYTE 将这类元数据放在 DRAM ,其访存开销已纳入 § 5.3 的成本模型;若过高,调度器可自动选择更保守的分块方案。
6.3. Intra-Tile Management
得到坐标范围与起始位置后,访问器按静态分配 的缓冲空间将纤维段读入。每个张量支持两种模式:
| 模式 | 说明 |
|---|---|
| Buffering | 整块装入缓冲,多次复用 |
| Streaming | 按需小批流入流出 |
图 5(b) 示意:假设对张量 B 采用 buffering,对 A 采用 streaming。
- 数据与元数据 对称生长 :
- 一方自缓冲一端向中心增长,另一方自另一端增长;二者相遇前均可扩张。
- 当写入纤维段数据时,同时在元数据区记录其 起始位置 。
- Streaming 采用 Buffets 的循环缓冲:
- 维持 head 与 occupancy;
- 如图 5(b) 的时间点 3,A 缓冲已满;时间点 4 逐出最早段 (a,b),head+1,occupancy-1,为新段 d 腾出空间 (时间点 5)。
- Buffering 模式下,若本块数据意外超过预分配(局部密集导致),则 不驱逐 先前数据(它们仍将复用);超出部分直接 旁路 缓冲。这源于静态估计未捕获局部稀疏变化,§ 6.4 的 动态调优 将对其进行校正。
6.4. Dynamic Tuning
访问一个block的时候,用
统计四个象限的非0元素,获取更加精细的稀疏信息。
假设当前块是的,控制器额外评估:
九种布局,评估
- 是总的非0
- 通过上面的外推得到,如:的形状,估计为
调整触发与时机.
-
当 最佳候选形状 的估计命中率比当前形状 高出 5 %以上 时,控制器才会决定调整。
-
若当前块间迭代方向与待调整维度不同,立即更改形状会导致新旧块 边界不对齐 。因此,调整会 延迟 ,直到下次迭代即将沿该维度推进时再生效。
例如图 5(a) 中 B 的块间顺序为先 k 后 j。此时修改 不影响迭代;但若要修改 ,则需等下一轮 j 维迭代开始时再应用,以免坐标错位、增加控制复杂度。
7. Methodology
https://github.com/tsinghua-ideal/HYTE-sim模拟器,主要任务是SpMSpM且方阵,额外测试了一些不规则稀疏计算的kernel。
8. Evaluation
8.1. Overall Performance
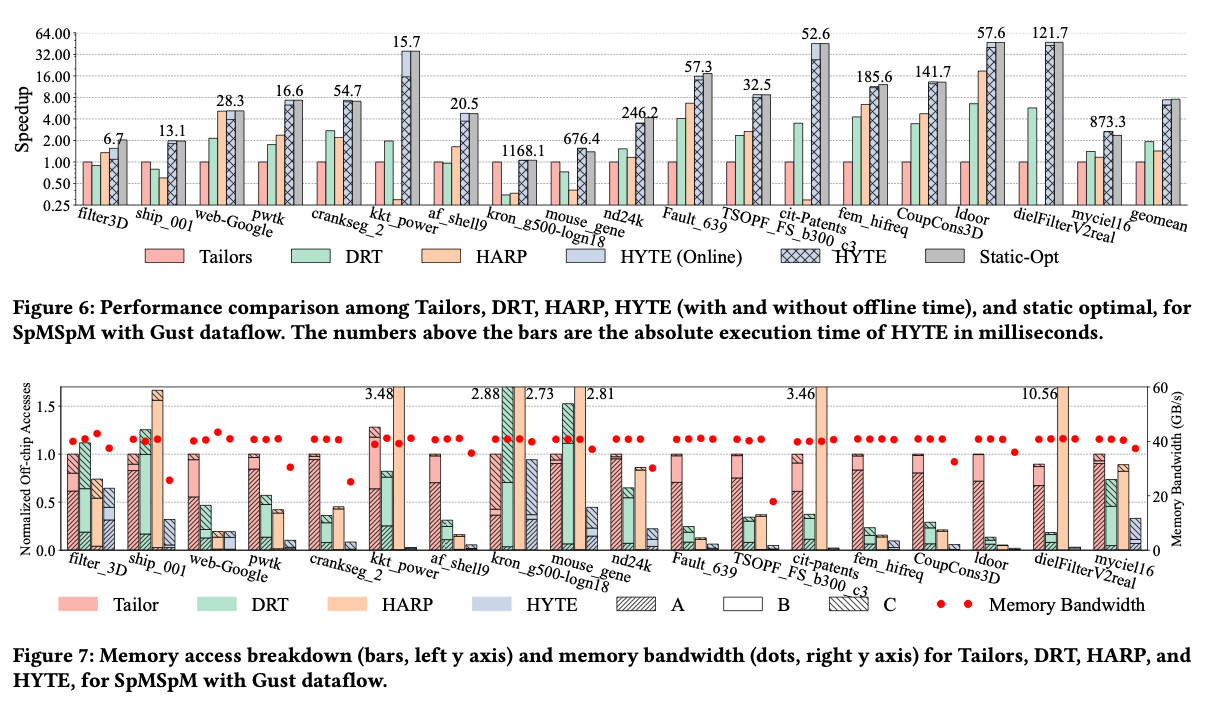

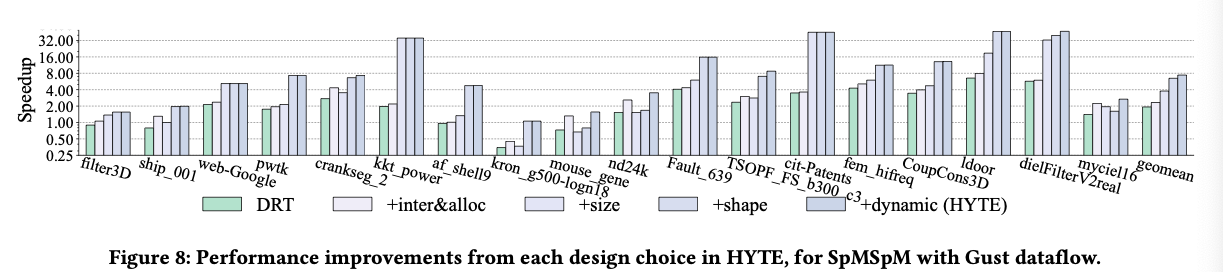
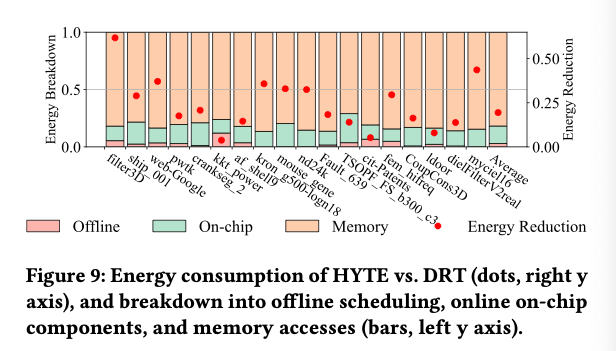
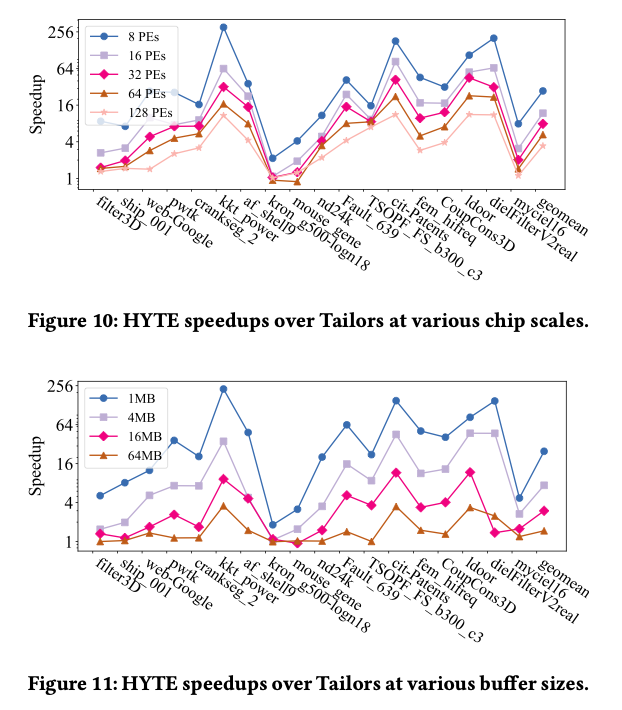
方法听起来没有很specific的东西,所以在不同的task/scale/chip上都有效
8.2. Results of Different Kernels
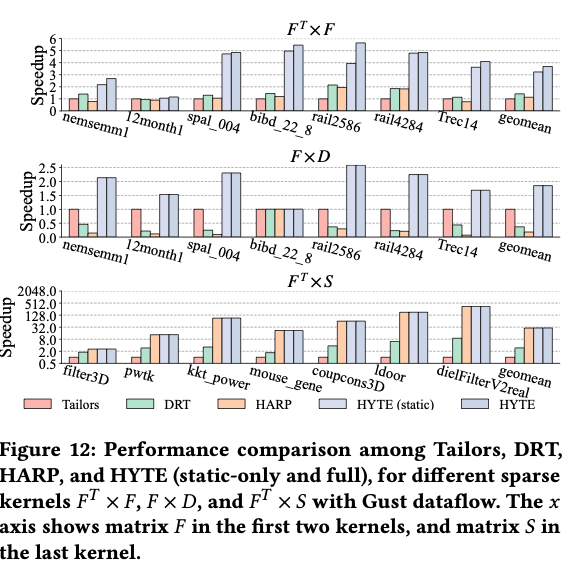
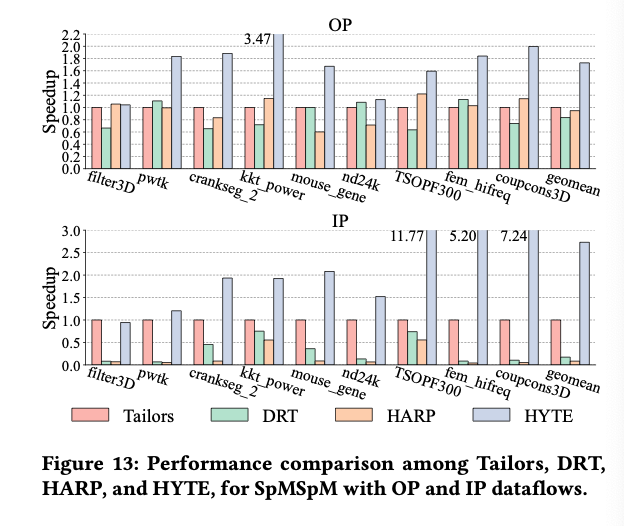
8.3. Results of Different Intra-Tile Dataflows
9. Discussion
分块控制器实现. 分块控制器承担三项核心职责:(1) 组织块间迭代;(2) 在多个 PE 之间同步进度;(3) 支持动态调优。前两项在任何支持分块的稀疏加速器中都必不可少,通常由专用硬件控制器实现 。第三项是 HYTE 新增的,但其复杂度很低,仅需汇总各访问器的计数器值并据此更新块形状,进而影响任务 (1)。因此,将三者整合到同一控制器更为合理。
除了专用硬件,也可以用软件来执行分块控制。由于控制器需持续与其他组件交互,若使用主机 CPU,则 PCIe 往返延迟以及 CPU 端轮询/中断和上下文切换的开销都会带来不利影响;采用片上嵌入式核虽更灵活,却比专用控制器占用更大面积和功耗。
扩展到多级缓冲. 虽然本文评估聚焦单级全局 SRAM,HYTE 可以自然地扩展到多级缓冲层次。硬件可按层级方式组合:每层配本地访问器,共享全局分块控制器。调度器则需搜索更多参数(各层块形状等),可沿用当前算法自外而内逐层迭代完成。
面向结构化稀疏的调度. 若输入张量呈现结构化稀疏(如 N:M、块对角),调度流程还能进一步简化:已知的非零分布使得 effMAC 和 等指标可直接解析获得,无需采样。若工作负载包含多组结构相近的张量,也可对代表性张量离线一次性采样后复用。
局限性. HYTE 的离线调度主要受采样与成本模型精度限制,但图 6 说明静态方案已十分接近最优,因此 HYTE 的动态调优设计得较为简洁,在大多数情况下已足够。然而,更细粒度的在线调整仍可能带来进一步收益。另一方面,HYTE 可能把部分本来受限于内存的负载转变为计算受限(图 7),此时增加 PE 资源或可继续提升性能。稀疏张量处理中的某些固有瓶颈(如坐标匹配)与 HYTE 的分块优化相互独立,有待后续研究。
10. Conclusion
本文提出 HYTE ——一种面向稀疏张量加速器的 混合静态-动态分块框架 。与既有分块策略相比,HYTE 全面探索了分块设计空间:块大小/形状、块间顺序以及缓冲分配与管理策略。离线静态调度器首先为特定稀疏张量生成近最优方案;运行时硬件再对其进行轻量动态调优。实验表明,HYTE 在不同稀疏内核与多种数据流下均取得显著且稳定的性能提升,并显著降低能耗。
后半截有点没精力看了,跟现在在做的东西差别还是比较大。