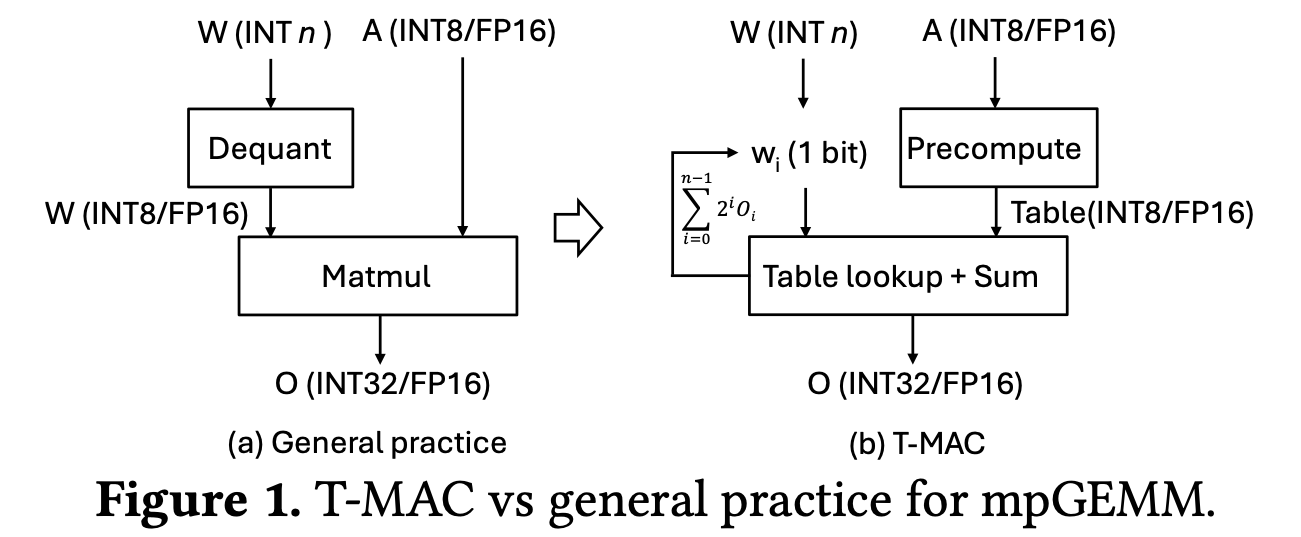
摘要: 在边缘设备上部署大型语言模型(LLMs)对提升端侧智能日益重要。权重量化是降低 LLM 在设备上内存占用的关键步骤。然而,低比特 LLM 在推理时须对低精度权重和高精度激活执行混合精度矩阵乘(mpGEMM)。现有系统由于缺乏对 mpGEMM 的原生支持,只能先将权重反量化,再进行高精度计算,这种间接方式会带来显著的推理开销。本文提出 T‑MAC——一种基于查找表(LUT)的创新方法,用于在 CPU 上高效推理低比特 LLM(即仅权重量化的 LLM)。T‑MAC 直接支持 mpGEMM,无需反量化,同时消除了乘法并减少了所需加法运算。具体而言,T‑MAC 将传统的“数据类型中心”乘法转化为按位查表,并实现了一种统一且可扩展的 mpGEMM 方案。我们的 LUT 内核随权重量化比特数呈线性扩展。在低比特 Llama 和 BitNet 模型上的评测显示,与 llama.cpp 相比,T‑MAC 吞吐量最高提升 4 ×,能耗降低 70%。在 M2‑Ultra 上,T‑MAC 对 BitNet‑b1.58‑3B 可在单核生成 30 token/s、八核生成 71 token/s;在 Raspberry Pi 5 上可达 11 token/s。T‑MAC 以 LUT 计算范式为资源受限的边缘设备部署低比特 LLM 铺平了道路,而不牺牲计算效率。系统已开源:https://github.com/microsoft/T‑MAC。
1. Intro
之前算法BitNet系列的加速算法的续作,BitNet这样的超低weight bitwidth的工作在GPU/CPU/通用硬件上不好运行,出现了很多类似W4/2/1, A16/8的工作,而现在的通用硬件上一般只支持两个操作数的宽度对齐的操作,无法处理这样的混合精度,导致:
- 性能问题,要把weight的低比特转换到activation的高比特上,这种转换的开销缩减了低比特量级的收益;
- 开发难度,针对任意一种混合精度,由于数据在内存中的排布模式不同,都需要重新设计对应的Kernel。
本文基于LUT-GEMM做,LUT的主要Challenge:
- LUT查表的过程涉及到很多随机内存访问;
- LUT建表带来了巨大的额外存储开销。
本文提出T-MAC mpGEMM,
- 系统层面上,提出以LUT为中心的数据布局,通过重排和Tiling的方法让LUT存储在各种方便访问的介质(如,寄存器)中,并且尽量提高复用,加速计算的同时减少了存储开销
- 算法层面上,提出了对Table的量化和合并技术,进一步缩小规模
2. Background and Motivation
2.1. LLM on Edge
主要在讲端侧LLM部署,主要的问题是:
- Memory占用,LLM占用太多Memory了
- Compute和Bandwidth也有bound
2.2. Low-Bit (Weight-Quantized) LLM
weight quantization尝试在不太降低精度的情况下,降低显存占用和可能的计算量。
2.3. Deplotment Challenges of Low-Bit LLM
- Mixed-precision GEMM/GEMV, 端侧LLM做部署的时候很容易出现两个操作数的精度不同,而实际上传统硬件都是只支持两个操作数有相同精度的,导致现在的系统很多需要做反量化,引入了额外的开销;
- Bit-width/precision diversity, 不同的部署场景、不同的量化模型可能有不同的位宽,针对不同的位宽的优化方法差异是很大的。
2.4. LUT-based Computation for Quantized Model
量化LLM的一个新的趋势是,用Look Up Table方法。对于低比特的量化模型,LUT方法预先计算所有可能出现的权重-激活乘积,推理的时候避免所有计算,直接查表。
注意到,在GPU上的LUT方法,性能经常不如之前的反量化的Kernel,因为其性能受限于GPU的架构,要么LUT Table的存储空间太大导致不足,要么访问Table的速度不够快。相比之下,在CPU上进行推理得到加速的可能性更大。
3. Design
考虑:
混合精度GEMM可以按照weight Bit-Serial的模式,切分成多个1B片段的乘积,然后针对这个1B片段进行LUT生成、查表和计算,满足了不同精度可以使用一套相同技术处理的要求。
3.1. T-MAC Algorithm
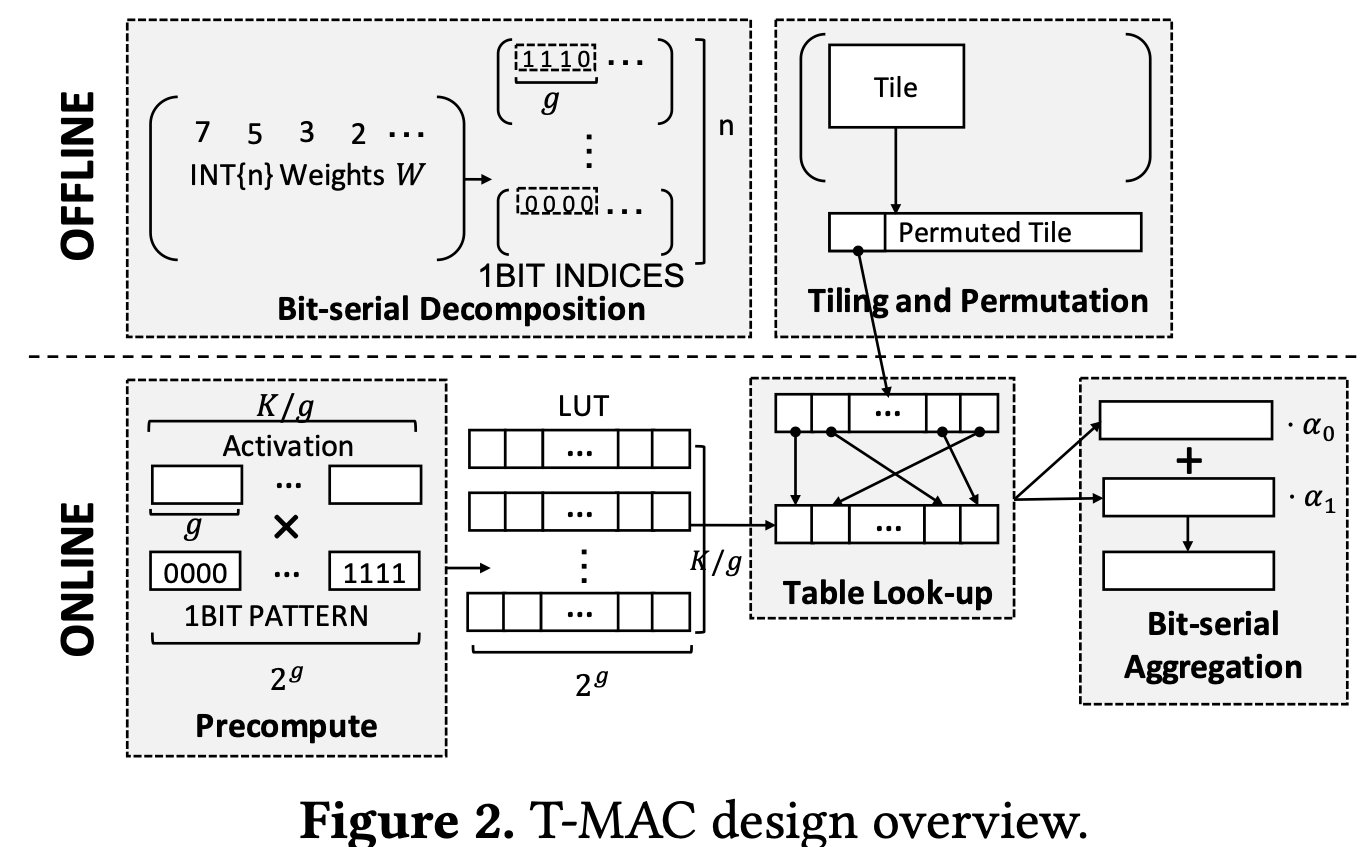
- Offline阶段:将n-bit的weight转换为1bit切片,然后生成种不同的计算结果
- Online阶段:对于形状为的Activation Vector,预先生成种不同的模式,则T-MAC会生成一张的结果查找表,然后按”Bit-Serial”模式查找结果→累加结果Pipeline生成结果;
举例:
假设分组中,总长度为,首先拆分成组,针对某一组,会将这一组乘以个不同的weight bit组合的可能全部计算出来,保存到现在的LUT中,得到了。
在接下来的计算中,只要对于这一组,直接用需要乘的weight模式去LUT中查找,然后把结果累加起来并且添加的移位。
这样假设在Llama这样的模型中,取,考虑每Token的推理成本,
- 对于直接计算乘加,计算有次FMA操作
- 对于T-MAC的算法,首先做次建表操作,之后做次查表和加法操作。
但相同的,实现LUT的过程中存在一些挑战:
- 查表操作中涉及到很多的随机访问;
- 建表过程产生的内存开销大了很多,需要更多寄存器更多空间存放结果。
为了解决上面的问题,T-MAC还提出了一种LUT-Centric Data Layout。
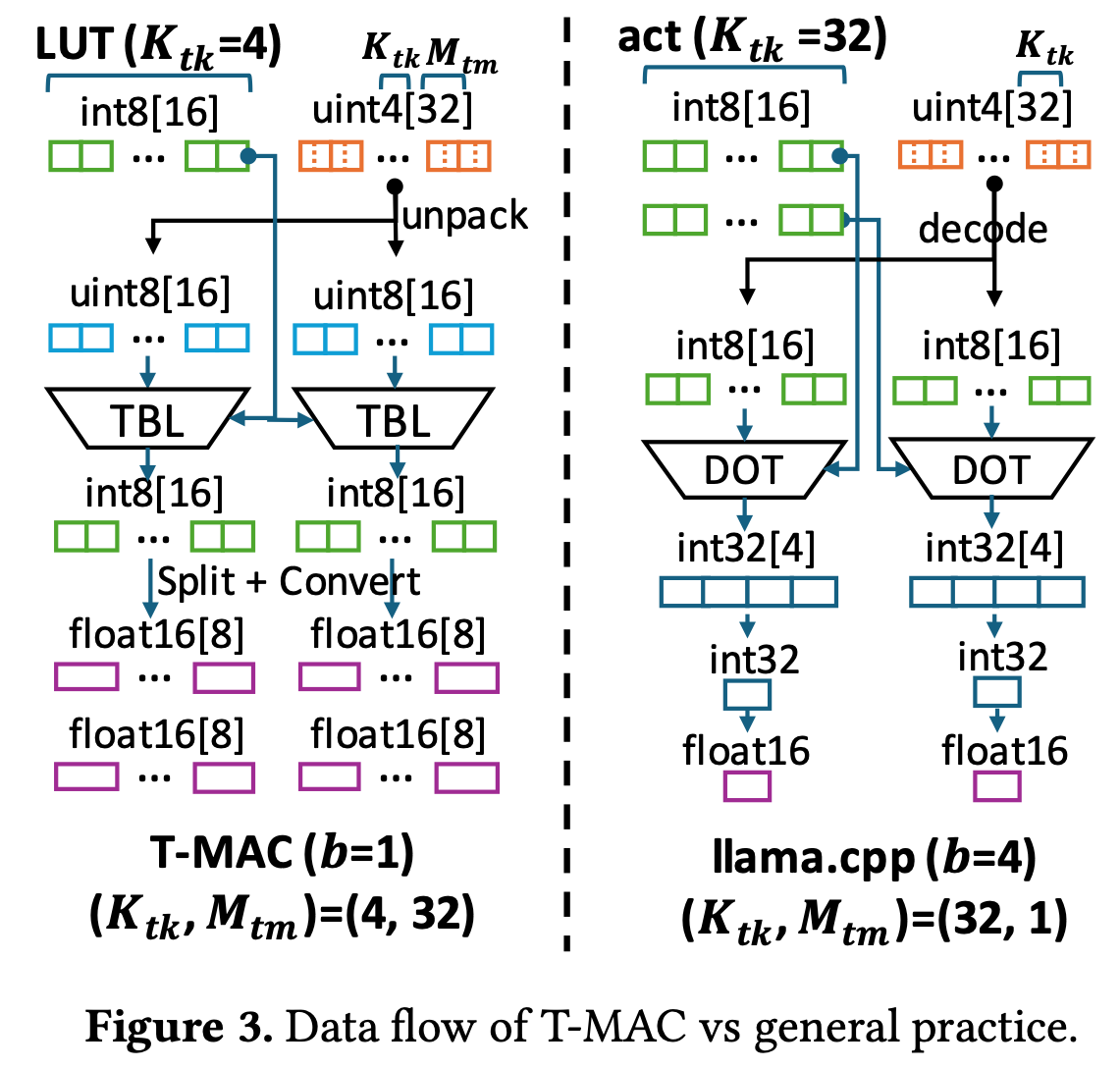
3.2. LUT-Centric Data Layout
LUT‑GEMM 需额外空间存放查找表及中间结果,且查表访问呈随机性。为提升存储与访问效率,我们设计了 LUT‑centric 数据布局 :把查找表放在寄存器等片上存储,通过axis reodering与 tiling 提高数据复用、降低内存占用,并辅以两项布局优化——weight permutation与weight interleaving——进一步提升效率。
- Put lookup table on on-chip memory,为了加速计算需要把更多内容放在片上(对于CPU,寄存器最快),如果溢出了就会显著降速,因此需要额外的technique;
- Axis reodering,对于GEMM (指的是实际的内存中存放的方式,为了保持访存的连续性将转置),默认的循环顺序是,但是LUT-GEMM需要沿着轴建表,规模很大,因此LUT-GEMM中的循环顺序修改为,这样每次维护的表的大小变为
- Tiling,设Tile大小为,在LUT-GEMM中相同的可以公用同一个LUT,更大的可以提高表的复用。
- Layout optimizations,包括
- Weight Permutation,将weight按Tile在内存中存放,消除不同tile之间的随机访问开销
- Weight Interleaving,CPU一般是小端的,unpacking的时候需要做额外的操作,因此直接在离线阶段就把unpacking前面的这种重排先做好。

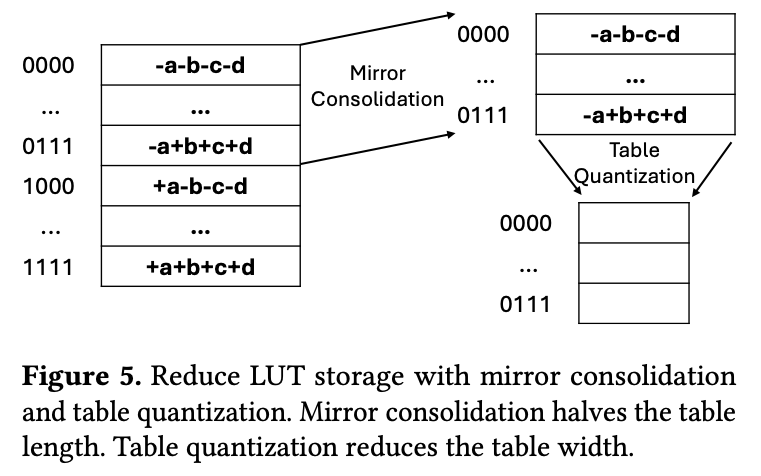
3.3. Reduce LUT Storage
- Mirror Consolidation,LUT中有很多模式是相互对称的(模式取反),因此可以只存一半,另一半取负;
- Table Quantization,降低表的精度,比如将Table的结果从FP16的降低到int8+scale factor
4. Implementation
- Code generation through TVM, 采用TVM + LLVM生成代码从而适配不同的硬件和GEMM Size,并且自动应用常见的优化;
- API and integration,提供了C++和Python的接口;
- Parallelism,在CPU上多线程运行,去除llama.cpp的多线程防止与T-MAC算法内部的多线程算法冲突;
- Efficiant table look-up by TBL/PSHUF,两种指令集都有高效的8Bit查表指令

- Determine the size of on-chip LUT,需针对每种硬件微调 片上 LUT 数量 :既要充分利用片上存储,又不能溢出导致 LUT 在 tile 内被换出。片上存储越大,可驻留的 LUT 越多,中间结果聚合后再写回,有助降低带宽。过多 LUT 造成寄存器溢出则反而带来开销。参数 亦取决于片上存储与指令吞吐:当 时,一张 LUT 恰好装入一条 NEON.TBL / AVX2.PSHUF 所需寄存器;若 ,则需两条寄存器及较慢的 ARM.TBL2 / AVX512.PSHUF。
- Fast 8-bit aggregation,先在低bit累加然后转换成高bit,如果做了table的量化则可以直接在INT8这种低精度上用AVG/RHADD指令求和,然后减去概率偏差,吞吐高很多但是掉点;
- Bit-serial linear transformation,由于weight只取,发现可以将weight值做一个缩放,scale到上,从而减小LUT极值,降低量化误差。由于同时又想避免浮点乘法,最后取。则有:
- Register swizzling for efficient LUT precomputation,LUT的形状为,用加减法代替乘法提高吞吐,并且沿着轴做向量化,如:
索引到 A 的地址非连续。通过 NEON.LD4 或 AVX2.vgatherdps 可高效加载这些非连续数据。但在 AVX2 上,若直接把 LUT 写回内存,需从 SIMD 寄存器抽取零散字节,效率极低。我们采用 寄存器 swizzling :先用 vpblendvb 将不同寄存器中的 8‑bit 值混合,再用 vpermd 调整 32‑bit 元素顺序,最后用 vpshufb 对 8‑bit 值做最终 Shuffle,使 LUT 以连续布局写回。
5. Evaluation
5.1. Evaluation Setup

内核与模型。
- 内核基准 :选取 Llama‑2‑7B 、Llama‑2‑13B 中真实出现的矩阵形状;
- 端到端基准 :使用多种量化模型——4 bit、3 bit、2 bit、1 bit Llama 与 1 bit、1.58 bit BitNet。
- 4 bit Llama 来自 GPTQ ;
- 3 bit / 2 bit Llama 来自 BitDistiller ;
- 1 bit Llama 来自 OneBit ;
- 1.58 bit BitNet 的三值权重视作 2 bit,拆为两张 1 bit 矩阵。
基线实现。
- llama.cpp (版本 b2794,2024 年 5 月发布)——当前边缘设备 LLM 部署的 SOTA,纯 C/C++ 编写、无依赖,对硬件高度优化。
- 内核层面 :各平台使用 llama.cpp 自带优化内核作基线。
- 模型层面 :在 llama.cpp 中替换 mpGEMM/mpGEMV 内核为 T‑MAC LUT 实现,与原版对比。
- 另有 llama.cpp (BLAS) :在 M2‑Ultra 走 Accelerate,其余平台走 OpenBLAS。BLAS 在 mpGEMM 时快于 llama.cpp 原生;mpGEMV 则相反。因此 T‑MAC 仅在 mpGEMM 场景对比 BLAS 。
测量方法。
- 内核延迟 :CPU 上先 warm‑up 10 次 ,再 测 100 次 取平均;M2‑Ultra 需先运行 ≥1 s 以激发峰值性能。
- 模型吞吐 :在集成 T‑MAC 内核后的 llama.cpp 中,连续生成 64 token × 20 轮 ,统计 token/s。
5.2. mpGEMV/ mp GEMM Performance Benchmark
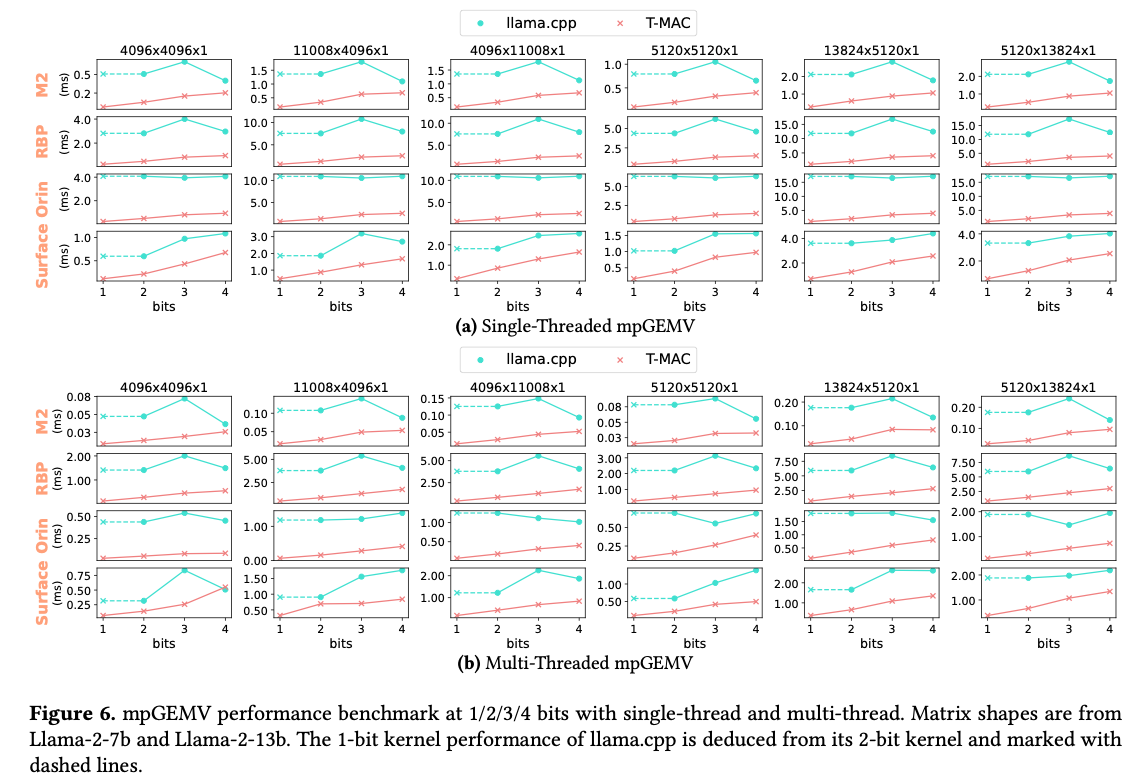
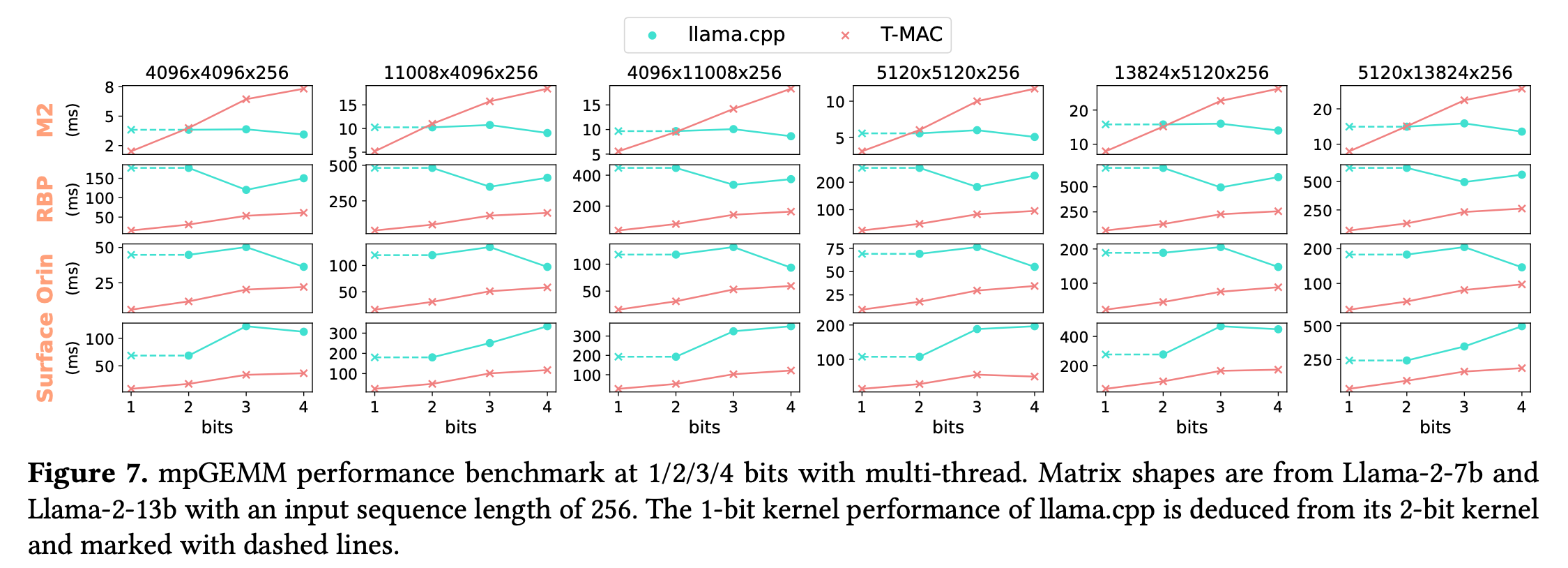
观察到:Llama.cpp的Kernel在weight精度降低到3Bit的时候,计算时间甚至慢了15%,因为decode这些3Bit的数据的开销反而更大了,而T-MAC在1Bit下能够取得的加速。
另一个观察是,T-MAC取得的最好加速比在3-bit,因为目前的做法下8无法整除3,ALU处理3Bit的数据需要配合SHITF&ADD。
5.3. End-to-End Inference Throughput
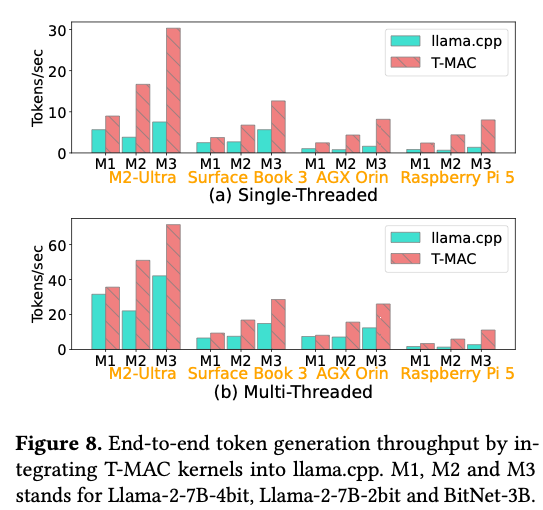
树莓派上11token/s,M2 Ultra上71tokens/s。
5.4. Power and Energy Consumption
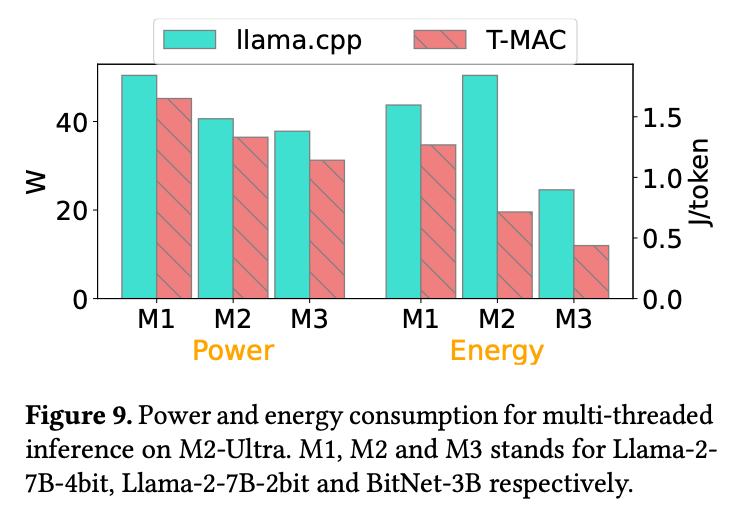
在 M2‑Ultra 上使用 powermetrics (采样 500 ms,运行 ≥120 s)测量多线程版本的功率/能耗
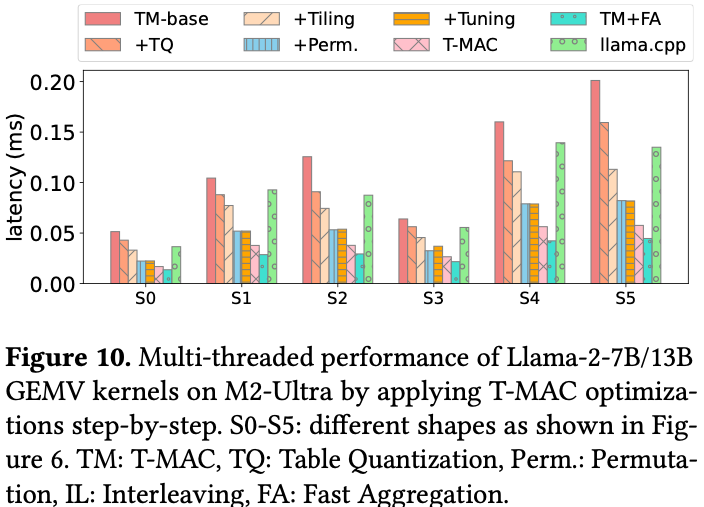
5.5. Optimization Breakdown
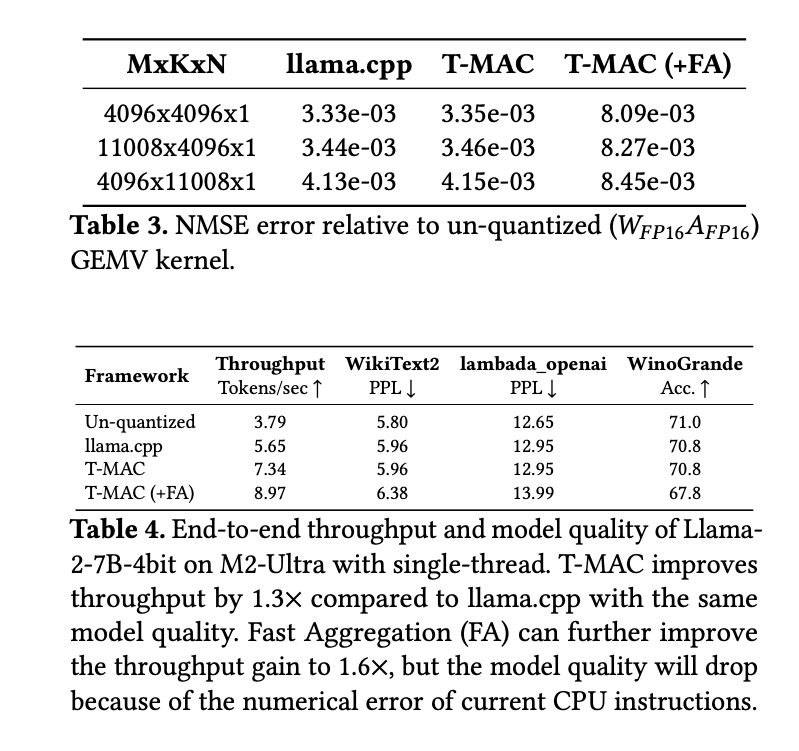
5.6. Error Analysis
主要来源于Table quantization和Fast Aggregation。
5.7. Compared with GPU/NPU
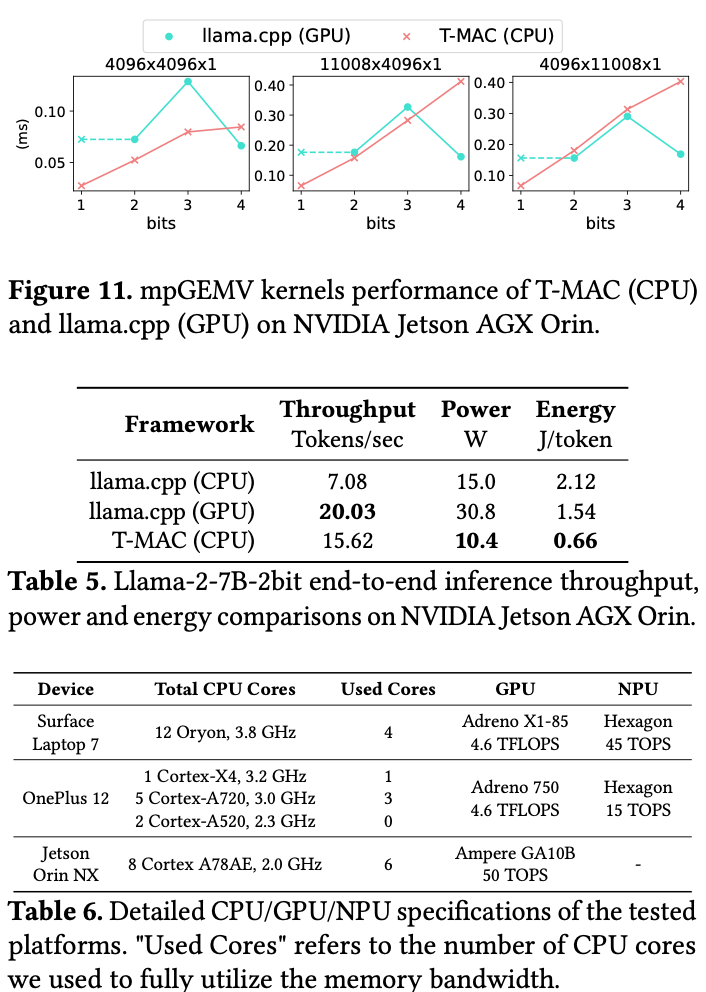
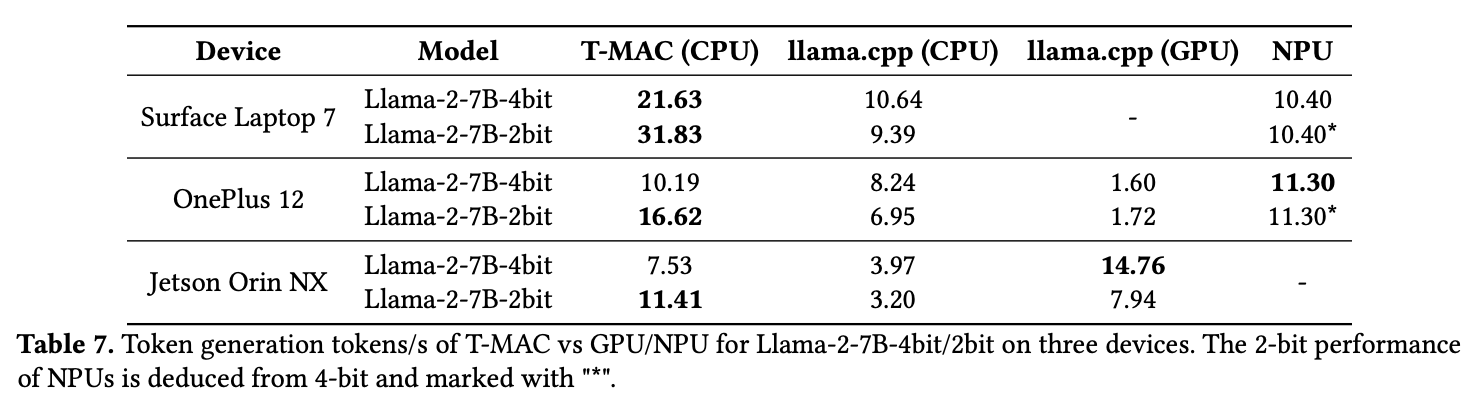
主要是能效上的提升。
6. Related Works
- LLM Quantization Algorithm
- LLM Inference System
7. Conclusion
T-MAC 将传统以数据类型为中心 的乘法运算转化为按位查表 ,为日益流行的 mpGEMM 提供了一种统一且可扩展的解决方案。在边缘设备普遍可得的 CPU 上,T-MAC 内核相较 llama.cpp 最高可实现 6.6× 的加速,使得 CPU 推理速度可与同设备 GPU 相当,甚至更快。因此,T-MAC 为在边缘设备(即使是 Raspberry Pi 这样的轻量平台)部署 LLM 提供了一条无需倚赖 GPU 的切实可行之路。同时,T-MAC 也为基于 LUT 的新型 LLM 硬件加速器设计打开了广阔空间,因为相较于乘法器,LUT 在硬件实现上更加高效。