摘要: 尽管现代decoder‑only的 LLM 在多个领域取得了优越的性能,但其生成文本中的幻觉已成为普遍问题,进而阻碍其在知识密集型任务中的应用。检索增强生成(retriever‑augmented generation,RAG)提供了一条解决路径,但检索器的非参数化特性妨碍了它与 LLM 之间的深度交互。本文提出使用一个预训练、可微的外部记忆,将记忆从 LLM 解码器中解耦。该外部记忆为一个 MLP,通过在整个预训练数据集上模仿检索器行为进行预训练。由此得到的体系结构包含一个在语言建模上预训练的 Transformer 解码器,以及一个在检索器模仿任务上预训练的外部 MLP 记忆;该架构在困惑度与下游任务表现上均表现出色。实验表明,我们的架构随模型规模呈现更陡峭的幂律缩放趋势;与仅解码器模型相比,在 WikiText‑103 和 Web 数据集上分别实现了 17.5% 与 24.1% 的提升,并且在增加训练时仍能受益而不过拟合。我们在三个幻觉评测基准上取得了更优表现,并在九个记忆密集型任务上表现出色。此外,相比于 kNN‑LM(5 亿token),我们的方法带来 80× 的加速;相较仅解码器模型,推理速度快 1.3×。不同于会削弱推理能力的 kNN‑LM,我们的 MLP 记忆提升了 StrategyQA 的表现。我们将于未来开源代码与模型。
1. Intro
Decoder-Only的LLM幻觉问题一直很受人关注。为了缓解幻觉,一般会:
- 添加SFT,但往往会削弱模型的performance;
- 添加RAG,但是RAG本身依赖于Query-Key之间的相关性,并且此过程无法引入到训练中;
一些新兴的方法是,采用一些额外的记忆访问机制,如Memory Network, Sparse Access Memory, …但是这些方法一般应用在特定的下游任务上,有些缺乏通用性。
本文提出一种面向LLM的外部记忆,在整个pretrain dataset上,这个外部记忆用一个“模拟检索”进行训练。具体来说,遵循kNN-LLM的设定,该记忆学习将 LLM 在某一步的隐藏状态映射到一个与 kNN 检索器输出匹配的词表分布。在推理阶段,我们将 LLM 的原生输出与来自外部记忆(经检索器模仿预训练得到)的输出进行插值融合。我们最终的架构由一个 Decoder与一个外部 MLP记忆组成,二者分别通过不同的预训练任务(语言建模与检索器模仿)进行预训练。对于该预训练外部记忆,我们同时追求以下特性:
- 端到端可微,意味着可训练;
- 高度可压缩的记忆,便于高效部署;
- 低延迟推理;
- 可扩展的一般知识记忆,覆盖整个训练数据集;
- 长期记忆;
2. Related Works
- RAG,主要的问题还是latency和不能和LLM一起训练;
- Memory-Augmented Language Models, 一般是关注上下文范围内的记忆优化,这篇文章和这些工作有区别,更倾向于做可训练RAG这种东西
- MLP Architectures
3. Methods
3.1. Preliminary: -nearest neighbors language model
NN-LLM
kNN-LLM通过将LLM的参数化输出分布,与外部存储的非参数化的分布进行插值。具体来说,给定一个上下文,则下一个token的概率计算为:
其中是外部数据检索的分布,是LLM的分布。
Datastore
假设是LLM将上下文编码为定长向量的一个函数,对于训练集中的每一个样本,定义,其中,是下一个token。则完整的数据:
Inference
推理时,LLM得到将上下文编码为,给出自己对下一个token的推理,利用某个距离度量检索个最近的,然后对负距离施加softmax,得到一个非参数化分布,有:
3.2. MLP Memory
3.2.1. Architecture
近期有一些工作观察到,FFN层可以充当Key-Value Memory,提示MLP可能存在一些记忆性质。本文提出一个全MLP的记忆模块,可以作为kNN-LLM中kNN/RAG的等价物。
3.2.2. Training Pipeline
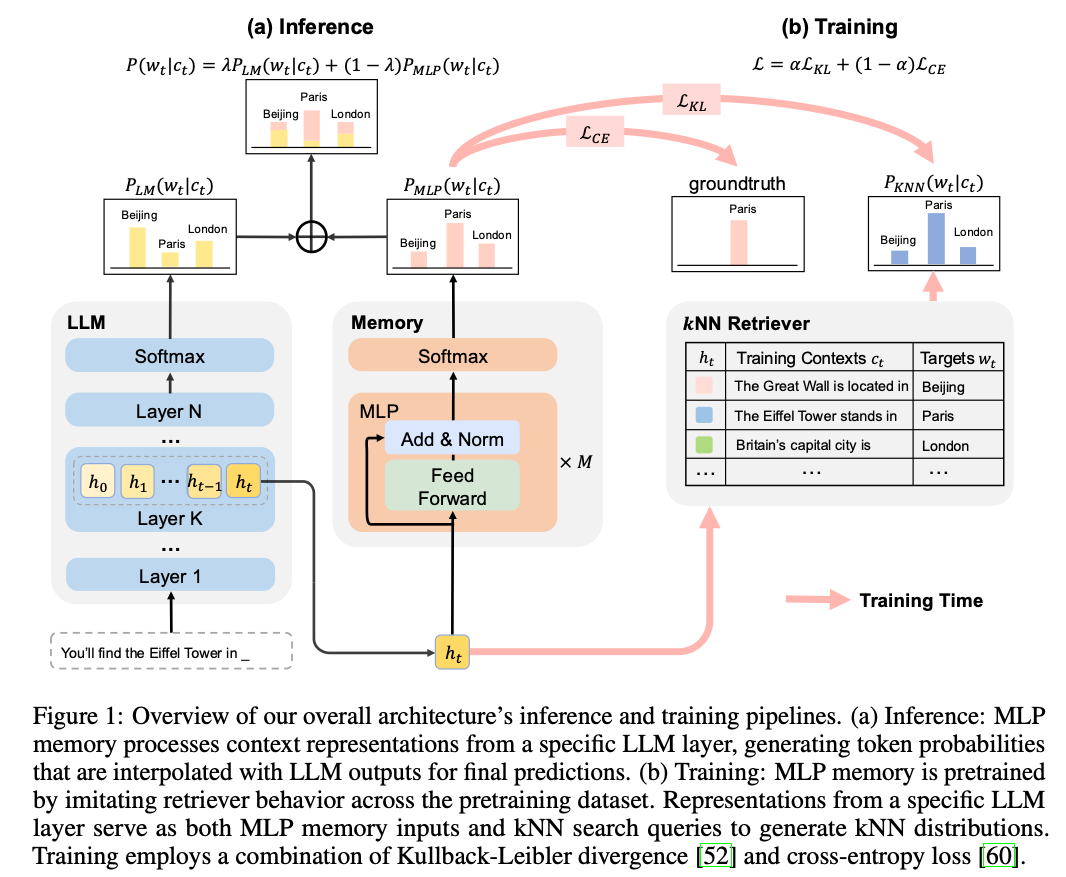
训练流程应该包括:(i)对LLM进行标准的训练;(ii)对MLP Memory进行检索模仿的训练。
- Step1:Datastore Construction,按照前面说的方法构建;
- Step2: Pre-computed NN Search,对于训练集中的每一个,根据在上做kNN检索,为了避免这个信号塌缩成One-Hot的,去掉真实结果(因为在训练集上,我们确实能够检索到真实结果),取前个结果构建kNN分布
- Step3: Memory Module Training,step2得到了,训练一个MLP预测这个分布。
实验中显示,仅依赖于交叉熵:
q训练这个模块容易导致严重的过拟合,因此额外引入KL散度:
3.3. Inference Efficiency Analysis

主要的优点是这个纯MLP的记忆模块里面没有attention机制,结构简单推理起来比较快。
4. Experiments
4.1. Scaling law
Setup:
我们以标准Decoder Only模型与本文的总体架构开展缩放律实验。基线采用四个不同参数规模的 GPT‑2 变体:GPT2‑small(124M)、GPT2‑medium(345M)、GPT2‑large(774M)与 GPT2‑xl(1.5B)。对于 MLP 记忆,我们设定 small(124M)、medium(335M)、large(774M)三种配置,与标准架构的缩放趋势保持一致。将匹配规模的 GPT‑2 变体与 MLP 记忆外联集成后,总参数量分别约为 248M、710M 与 1.5B。所有模型在两个数据集上训练:WikiText‑103 (约 1 亿词元)与混合 Web 数据集(约 6 亿词元)。我们的 Web 数据集融合了与常见 NLP 任务相关的多源知识,包括 WikiText‑103、Amazon Reviews、CC‑NEWS与IMDB 。
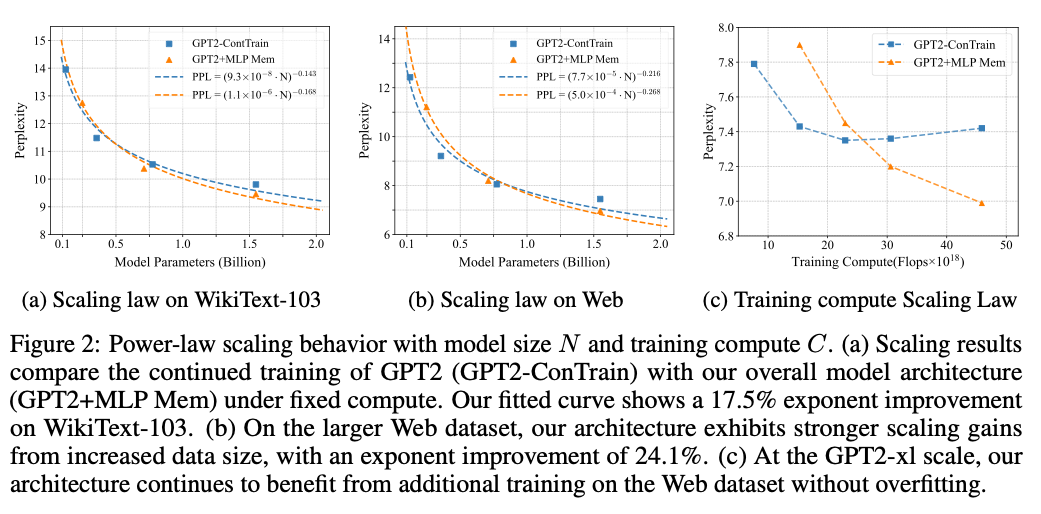
(a)在固定计算预算下,将持续训练的 GPT‑2(GPT2‑ConTrain)与我们的总体架构(GPT2+MLP Mem)在 WikiText‑103 上的缩放结果进行对比;拟合曲线显示我们在 WikiText‑103 上的指数提升 17.5%。(b)在更大的 Web 数据集上,随着数据规模增加,我们的架构展现出更强的缩放收益,指数提升 24.1%。(c)在 GPT2‑xl 规模下,我们的架构在 Web 数据集上持续受益于额外训练且无过拟合迹象。
4.2. Hallucination Reduction with MLP Memory
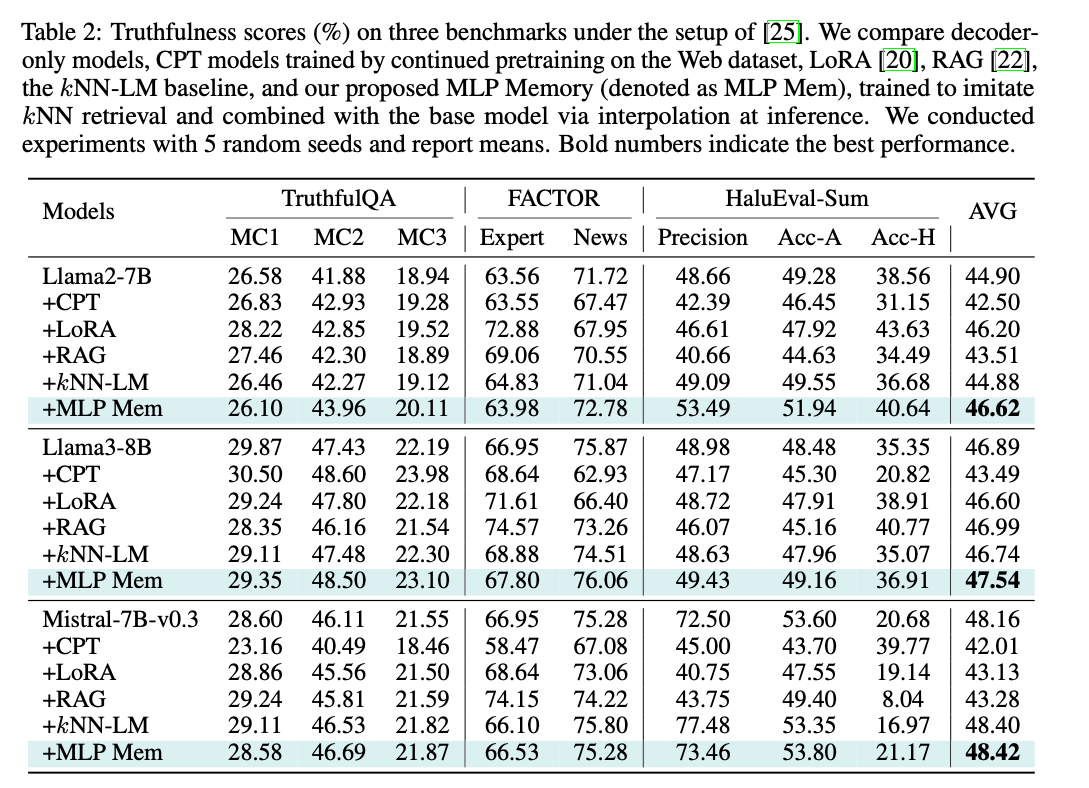
通过分离训练记忆模块并在推理时插值融合,我们在保持原模型能力的同时增强事实准确性,为在不牺牲生成能力的前提下缓解幻觉提供了新视角。
4.3. Improving Memory-Intensive Tasks Performance with MLP Memory
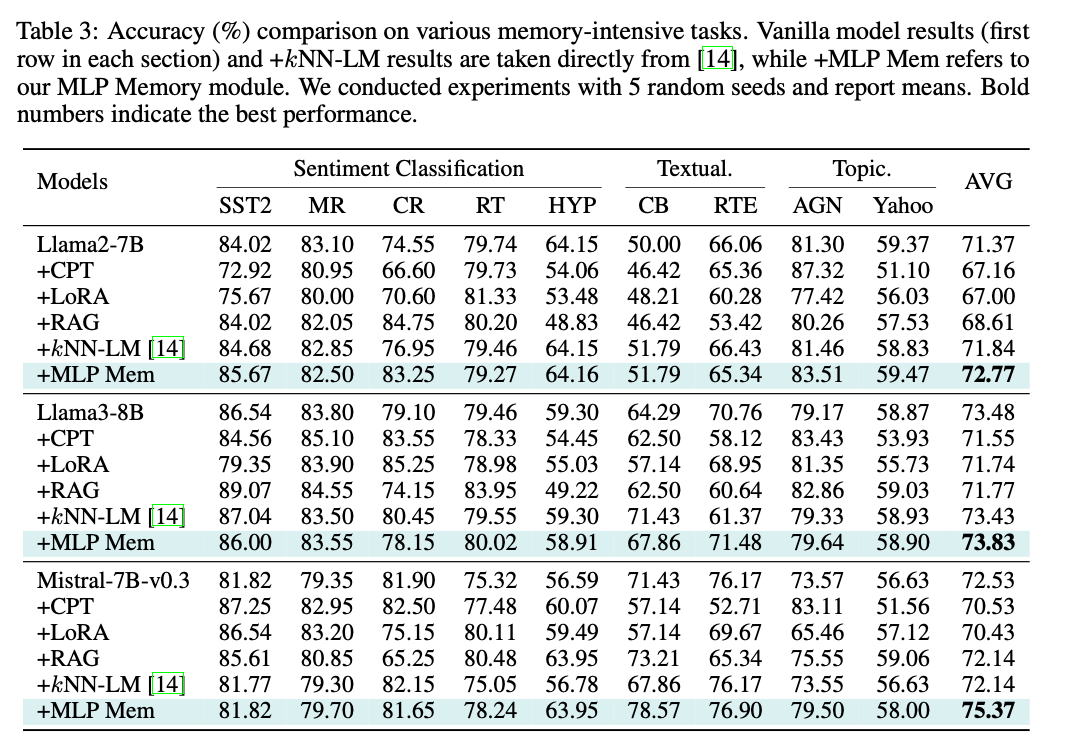
MLP 记忆在完全参数化的架构内有效模拟检索能力,在不牺牲任务表现的情况下,为 kNN‑LM 提供了一个高效替代方案。
4.4. Ablation Study and Analysis
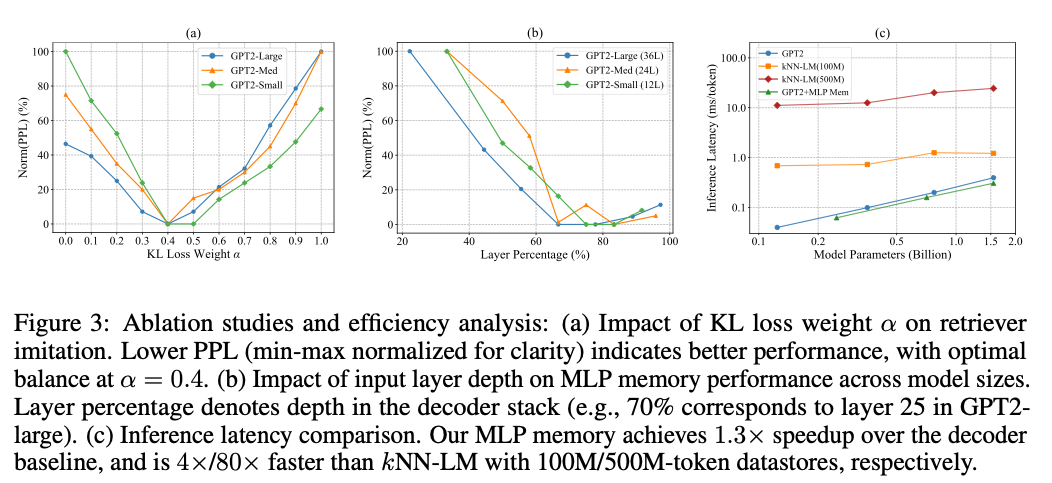
- 哪一层最适合作为 MLP 记忆的输入? 虽然 kNN‑LM 常使用最终 FFN 的输入作为检索键,但我们的 MLP 记忆在约 70% 的网络深度处稳定达到最优,且与模型规模无关。这与 Memorizing Transformers 的发现一致(其最优也在约 75% 深度)。我们在 GPT2‑small(12 层)、GPT2‑medium(24 层)、GPT2‑large(36 层)上评估,将 MLP 记忆接入不同的 Transformer 块。图 3(b)中,横轴为相对深度(20%–100%),纵轴为min‑max 归一化的困惑度(0% 最好,100% 最差)。这一跨规模一致的模式有别于 kNN‑LM 习惯使用最终层表示的做法。
- 推理时延对比。 我们比较三种方法的推理效率:标准自回归解码器(GPT‑2)、检索式的 kNN‑LM、以及我们的总体架构。解码器因注意力与KV 缓存导致随序列长度二次增长的时延;kNN‑LM 在生成过程中需对大外部数据存储进行动态近邻搜索,其开销随库规模急剧上升。图 3(c)显示,我们的架构(GPT2+MLP Mem)相较仅解码器加速 1.3×,相较 kNN‑LM 在 1 亿词元与 5 亿词元存储上分别快 4×/80×。这些评估在上下文长度 512下进行;如分析,随着上下文增长,MLP 记忆因避免注意力的二次缩放而带来更显著的效率优势。
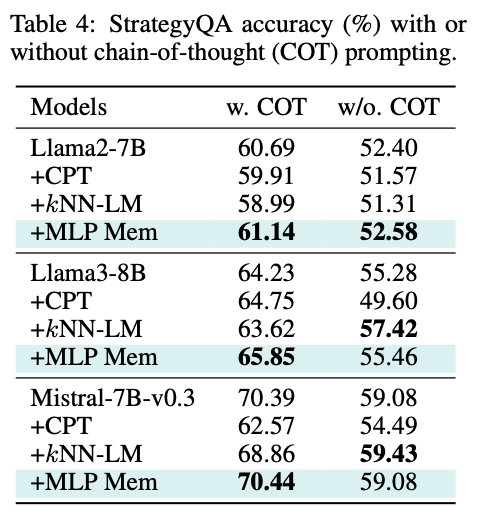
- 对推理能力的影响。 我们在 StrategyQA 上进一步评估 MLP 记忆(该基准要求多步推理与事实知识)。表 4 展示了是否采用 COT(chain‑of‑thought) 提示下的准确率对比:CPT 的结果不稳定,尤其在 Mistral‑7B‑v0.3 上,使用 COT 会下降 7% 以上;kNN‑LM 亦常损害表现(如 Llama‑2‑7B 在 COT 下 ‑1.7%)。相反,MLP 记忆在所有模型、无论是否使用 COT,均带来稳定增益,其中在 Llama‑3‑8B 上的提升尤为明显(使用 COT +1.62%)。值得注意的是,既有工作指出 kNN‑LM 会削弱推理能力,而我们的方法增强了推理。这表明参数化检索所捕获的信息比非参数化检索更为丰富,有利于同时提升事实准确性与推理。
5. Conclusion
本文提出一种新型架构:通过一个预训练、可微的外部 MLP 记忆来将记忆从 Transformer 解码器中解耦,且该记忆模仿检索器行为。总体架构端到端可微;MLP 记忆作为真正的长期记忆,在整个训练语料上完成预训练。此外,外部记忆高度可压缩(在 1 亿词元的数据存储规模下,将存储从 220GB 降至 2.8GB),并消除昂贵的检索操作:相较 kNN‑LM(5 亿词元)推理加速 80×,相较仅解码器加速 1.3×。我们的架构展现出较仅解码器更强的缩放行为,显著降低幻觉,并在记忆密集型任务上带来提升。出人意料的是,与先前关于 kNN‑LM 削弱推理的结论相反,我们的 MLP 记忆增强了推理,在所有基座模型上提升了 StrategyQA 表现。这一结果印证了我们受神经科学启发的假设:分离记忆与生成是推进语言模型的一条有前景的道路。
6. Limitation
受计算资源限制,我们当前实现中对 MLP 记忆的训练最多使用了 6 亿词元;其中 Web 数据集是我们最大的语料。未来工作将把规模扩展至数十亿甚至数千亿词元,以充分挖掘潜在性能收益。另一个方面,尽管我们在推理阶段消除了检索开销,但本方法需一次性的预处理开销,以执行生成 MLP 记忆训练目标所必需的三步 kNN‑LM 操作(数据存储构建、索引建立、与 kNN 分布生成)。