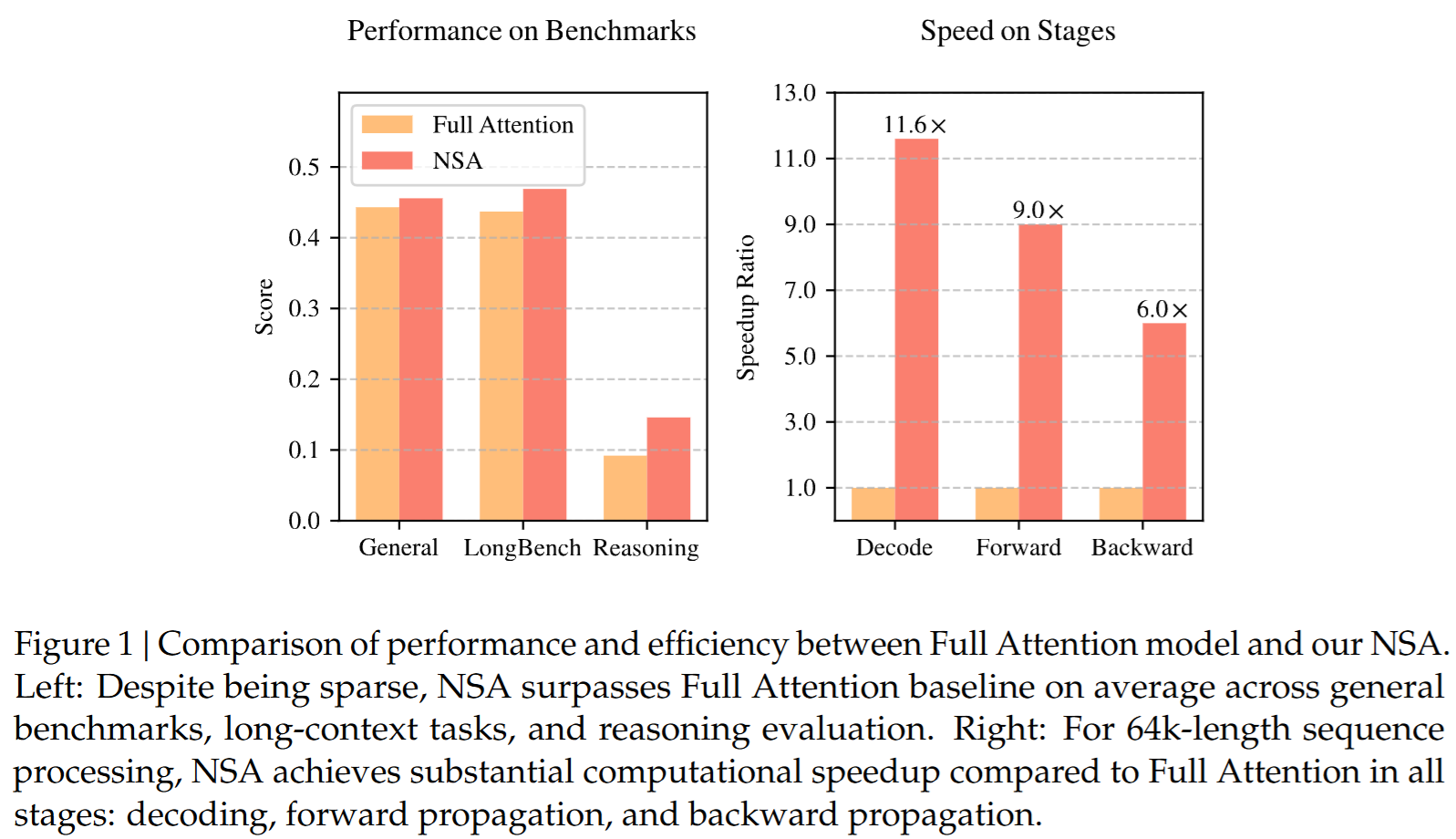
摘要: 长上下文建模对下一代语言模型至关重要,但标准注意力机制的高计算开销带来了显著的计算挑战。稀疏注意力为在保持模型能力的同时提升效率提供了一个很有前景的方向。我们提出NSA,一种原生可训练的稀疏注意力(Natively trainable Sparse Attention)机制,将算法创新与贴合硬件的优化相结合,以实现高效的长上下文建模。NSA采用动态分层稀疏策略,将粗粒度的 token 压缩与细粒度的 token 选择相结合,同时兼顾全局上下文感知与局部精度。我们的方法在稀疏注意力设计上包含两项关键创新:(1)通过计算强度(arithmetic intensity)均衡的算法设计,并结合面向现代硬件的实现优化,获得了显著加速;(2)支持端到端训练,在不牺牲模型性能的前提下降低预训练计算量。如图 1 所示,实验表明,使用NSA进行预训练的模型在通用基准、长上下文任务以及基于指令的推理上与全注意力(Full Attention)模型持平或更优。同时,在长度为64k的序列上,NSA在解码、前向传播与反向传播各阶段相较全注意力均取得了可观的加速,验证了其在整个模型生命周期中的效率。
1. Intro
Vanilla Attention机制的计算复杂度制约了现在大模型长上下文的发展能力。
一种自然的优化方式是,借助softmax注意力天然存在的稀疏性,选择性计算关键的Q-K对,在保持性能的同时显著降低开销:如KV-Cache eviction methods, blockwise KV-Cache选择,基于聚类/抽样/哈希的KV Cache选择等方法。但是这些方法在实际部署中往往达不到它们声称的理论加速,更重要的是这些方法只实现了推理优化,而在训练阶段支持不足。
要使得稀疏注意力在部署中真正有效,需要解决两个关键挑战:
- 贴合硬件的推理加速:无论是在prefill阶段还是decoding阶段,都需要硬件友好的算法设计,从而缓解内存瓶颈和硬件调度瓶颈,得到实际的speedup;
- 训练感知的算法设计:需要设计支持端到端、可训练的算子,降低预训练成本的同时不损失性能。
考虑到以上两个Challenge,现在提出的方法大部分还是存在明显不足。
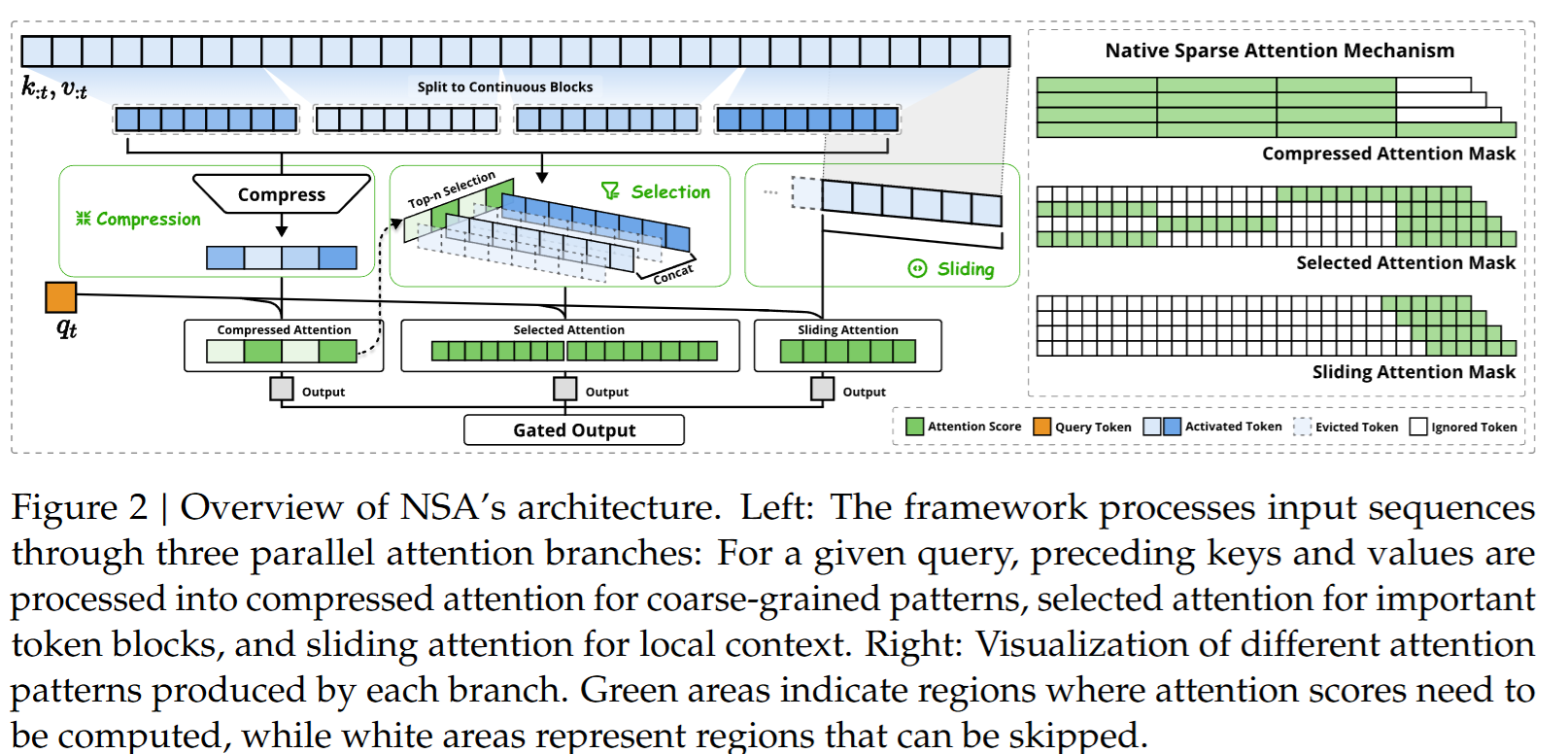
为了解决以上问题,本文提出NSA,融合分层Token建模。如下图所示,NSA将K-V组织为时间上的块,围绕每个Q通过三条并行的注意力路径降低每个Q的计算量:
- 压缩的粗粒度Token(从而捕捉全局模式);
- 选择性保留的细粒度Token(聚焦比较重要的细粒度Token);
- 局部上下文的滑动窗口。
随后实现了Kerne最大化效率。NSA围绕前文提出的两个Challenge提出了两个核心Contribution:
- 面向硬件的专门优化,针对Block-wise稀疏注意力实现Tensor Core利用和内存访问的优化,确保Arithmetic Intensity是均衡的;
- 训练感知优化,通过高效的算法设计和Backward算子实现了稳定的端到端训练,使得NSA同时支持高效的部署和端到端的训练。
2. Rethinking Sparse Attention Methods
现代稀疏注意力方法在降低 Transformer 模型的理论计算复杂度方面已取得显著进展。然而,多数方法主要在推理阶段施加稀疏,而仍保留一个以全注意力(即没有稀疏)预训练得到的主干,这可能引入架构偏置,从而限制其充分发挥稀疏注意力优势。在介绍我们的原生稀疏架构之前,本文从两个关键视角对这些局限进行系统分析。
2.1. The Illusion of Efficient Inference
很多方法在注意力计算上实现了理论上的稀疏,却在实际的计算latency上没有得到对应的speedup,原因为:
- 阶段受限的稀疏性,如H2O,在decoding阶段施加稀疏,而在prefilling阶段需要进行稠密计算;相反地,MInference只在prefill阶段进行稀疏,而decoding阶段是稠密的。由于至少有一个阶段完全进行稠密的计算,这类方法在不同的任务下speedup变化非常大,单阶段的方法削弱了它的优势;
- 与先进注意力架构的不兼容,很多稀疏优化的方法不支持现代decoding的新优化,如Multi-Query-Attention,GQA等。这些架构通过跨多个查询头共享 KV显著缓解了解码时的内存访问瓶颈。以 Quest为例:在MHA模型中,它让每个注意力头独立选择其 KV-cache 子集,从而在计算与内存访问上都呈现稳定的稀疏性;但在 GQA 等架构下,同一组内多个查询头的选择会取并集,导致KV-cache 的实际访问量对应于所有头选择的联合。这意味着虽然计算量下降了,但内存访问量仍然偏高——从而与先进架构所追求的高效内存访问设计发生冲突。
上述局限的根本在于:许多现有稀疏方法关注于KV-cache 缩减或理论计算缩减,却难以在先进框架/后端中实现显著的时延下降。这促使我们开发同时结合先进架构友好性与硬件高效实现的算法,才能真正把稀疏性转化为模型效率的提升。
2.2. The Myth of Trainable Sparsity
本文之所以要讨论原生的、可训练的稀疏注意力,是因为对于Inference Only技术的两点观察:
- 性能退化,在完成pretraining之后再施加稀疏,会使模型脱离预训练中的最优化轨迹;
- 训练效率需求,高效处理长序列训练对LLM的发展至关重要,既包括在更长文档上的预训练、增强模型的上下文容量,也包括后续的长上下文微调和强化学习阶段。然而,现有稀疏注意力的方法集中在推理阶段,对训练期的计算挑战关注不足。并且,在对现在的各种稀疏方法做”训练”阶段的适配的时候,还会遇到新的问题:
- 不可训练的组件,如ClusterKV中的K-Means聚类,MagicPIG中的SimHash选择等离散的操作会阻断梯度,限制模型学习最优稀疏模式的能力;
- 低效的反向传播,一些理论上可训练的稀疏注意力机制在实践中训练效率低下,如HashAttention采用Token级的选择,在注意力计算的时候需要从KV-Cache加载大量离散的单个Token,引入了严重的非连续访存,无法利用诸如FlashAttention这些依赖于连续内存访问和Tiling设计的技术进行优化。
2.3. Native Sparse as an Imperative
鉴于上述在推理效率与训练可行性上的限制,我们对稀疏注意力机制进行了根本性再设计。我们提出 NSA,一种原生稀疏注意力框架,同时面向计算效率与训练需求。后续章节将详细介绍 NSA 的算法设计与算子实现。
3. Methodology
3.1. Background
- Attention Mechanism:每个query token 针对之前的全部key 计算相关性分数,然后和对应的value 做加权求和,即:
其中,
- Arithmetic Intensity:计算强度指计算操作次数与内存访问次数之比,决定了算法在硬件上的优化侧重。每块 GPU 都存在一个关键的计算强度阈值,由其峰值算力与内存带宽之比确定:超过该阈值的任务为算力受限(受 FLOPs 限制),低于阈值的任务为带宽受限(受内存带宽限制)。就因果自注意力而言:在训练与预填充阶段,批量矩阵乘与注意力计算具备较高计算强度,在现代加速器上呈算力受限;相反,在自回归解码阶段,每步仅生成一个 token,却要加载整段 KV-cache,整体呈带宽受限且计算强度低。
3.2. Overall Framework
为了发挥注意力机制中天然系数的潜力,本文用一组更紧凑、信息密度更高的KV代替原始的KV(会针对每个动态构造:
设计多种映射策略从而得到多种不同的“高密度KV”:
其中分别表示压缩、选择、滑动窗口三种映射,为输入特征经过一个MLP+Sigmoid之后得到的Gating分数,映射后的KV总数
通过保证维持高稀疏性。
3.3. Algorithm Design
下面介绍。
3.3.1. Token Compression
相邻的K/V连续块压缩为整个Block来捕获整个块内的信息,压缩可以写作:
其中是块长,是相邻块滑窗的步长,是一个包含块内位置编码、可学习的MLP,将一个块内部的多个Key压缩为一个Key,于是又:
通常取降低信息碎片化。同理。
3.3.2. Token Selection
仅用压缩 token 可能丢失细粒度信息,因此需选择性保留个别关键的 key/value。我们提出一种高效的 token 选择机制,在低开销下识别并保留最相关的 token。
-
Blockwise Selection,在空间连续的Block上处理Key/Value,原因包括:
- 硬件效率,现代GPU对连续块访问的吞吐远高于随机索引
- 注意力Score的分布规律,相邻的Key的Softmax分数往往相似。
同时,分块计算也便于利用Tensor Core进行计算。
-
Importance Score Computation
具体实现中,首先将KV序列划分为Selection blocks,然后对每个块计算重要性分数。注意到,在前文对块进行压缩的时候,我们已经得到了一个中间分数,可以直接令:
为压缩Key和的注意力分数。记一个选择块的长度为,当Selection和Compression的配置相同()的时候,可以直接取,否则有:
即按照空间关系分割、求和。
在GQA,MQA这样的跨Head共享KV Cache的架构中,为了最小化Decoding阶段的KV Loading,需要让一个组内部每个head都选择相同的块。为了满足这个条件,对组内的个Head的注意力分数求和:
这样保证了同一个GQA组内选择了相同的块,避免了离散的内容载入。
- Top-n Block Selection
取前K个Token,然后拼接起来。
3.3.3. Sliding Window
注意力中的局部模式通常学习更快、占主导,可能“捷径化”学习过程,使模型无法从压缩/选择分支中有效学习。为此我们引入独立的滑动窗口分支,显式处理局部上下文,使其他分支(压缩、选择)能专注于其各自特征而不被局部模式“抢答”。
在窗口大小的最近token上保持不变:
3.4. Kernel Design
为在训练与预填充阶段达到接近 FlashAttention 的加速效果,我们基于 Triton 实现贴合硬件的稀疏注意力内核。鉴于 MHA 在解码期内存开销大、效率低,我们聚焦于共享 KV-cache 的 GQA/MQA 架构(与当前主流 LLM 一致)。压缩与滑窗分支可直接复用 FlashAttention-2 的内核;而选择分支需要专门的稀疏选择内核。
若沿用 FlashAttention“按时间连续的查询块装入 SRAM”的策略,块内不同查询可能对应不相邻的 KV 块,会造成低效的内存访问。为此我们提出不同的查询分组策略:对序列上的每一个位置,将同一个GQA组内全部的Query Head全部装入SRAM(它们共享一组稀疏KV Block)。Forward如下图:
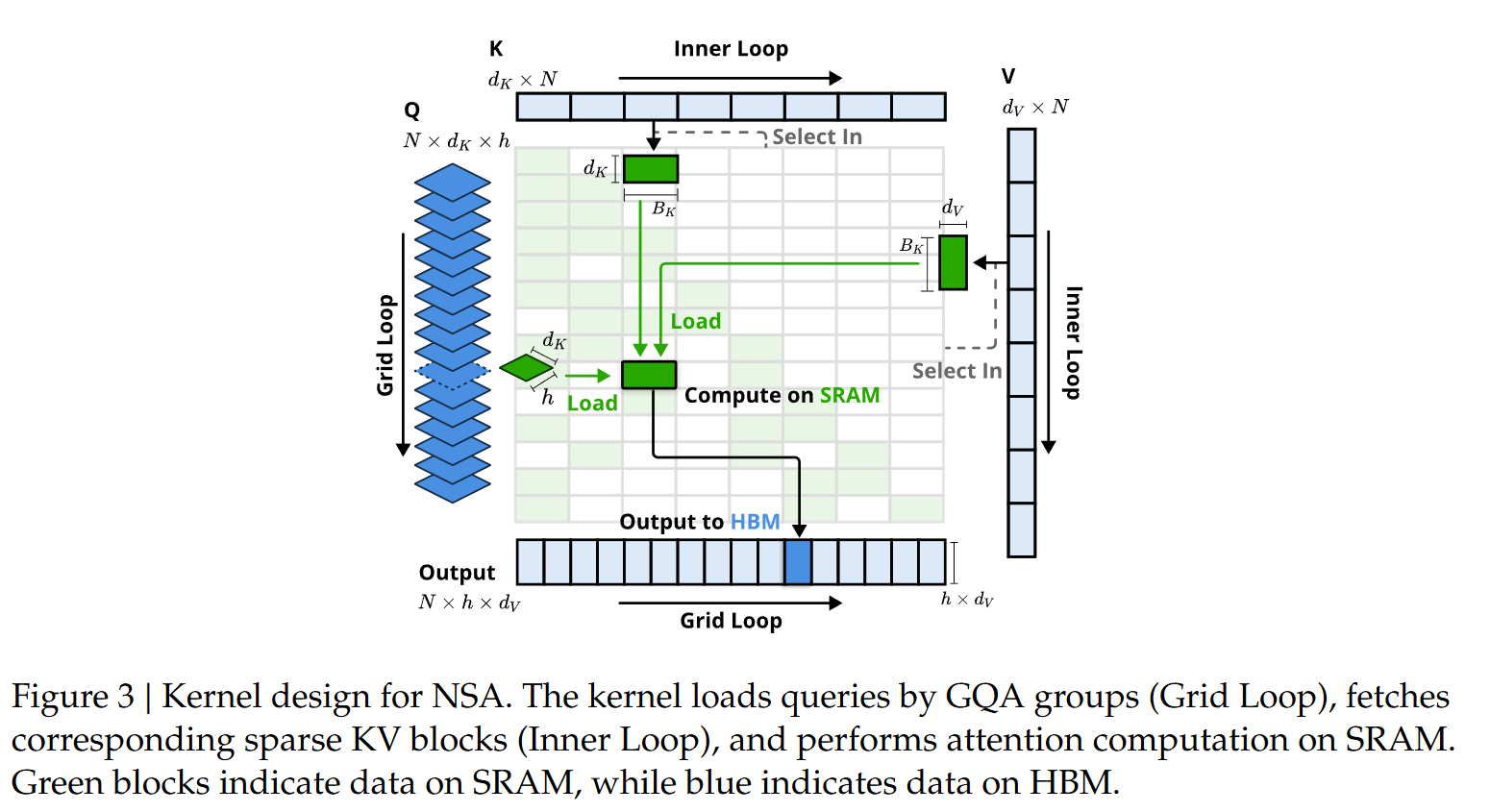
- Group-Centric Data Loading,在每个Inner Loop中装入该组在的所有Head和共享的KV Block索引;
- Shared KV Fetching,在Inner loop中,按照顺序加载KV Block到Cache中,,其中是Kernel内部的Tiling的一个Block的大小,满足从而最小化载入次数;
- Outer Loop on Grid,因为Inner loop的长度只与所选的块数近似成正比,而不同的query Block之间几乎一直,因此将外层的Input/Output循环放入Triton的Grid调度器,简化、优化Kernel。
通过:(1)组内共享消除冗余 KV 传输;(2)在 GPU 多流处理器间均衡计算负载,从而实现近似最优的计算强度。
4. Experiments
4.1. Pretraining Setup
遵循当前主流 LLM 的做法,我们采用结合 GQ与 MoE 的主干:总参数 27B,3B active。模型为 30 层,隐藏维度 2560。
- GQA:分组数设为 4,注意力头总数 64。每个头的查询、键、值维度分别设为 。
- MoE:采用 DeepSeekMoE 结构(72 个路由专家 + 2 个共享专家),top-k=6。为保证训练稳定性,第 1 层的 MoE 以 SwiGLU 形式的 MLP 替换。
4.2. Baselines Methods
除 Full Attention 外,我们还评测了多种推理期稀疏注意力方法:H2O(Zhang et al., 2023b)、infLLM(Xiao et al., 2024a)、Quest(Tang et al., 2024)与 Exact-Top(先计算全注意力分数,再对每个 query 选 Top-n key 再做注意力)。这些方法覆盖多样范式:KV-cache 淘汰、面向查询的选择与精确 Top-n 稀疏选择等。
- 在通用评测场景中,样本长度多处于各稀疏方法的局部窗口内,因此它们与 Full Attention 几乎等价;在该设置下,我们仅报告 NSA vs Full Attention 的对比。
- 在长上下文评测场景中,我们与全部稀疏基线进行对比,并统一稀疏度以保证公平。
- 在链式思维推理评测中,由于稀疏基线不支持训练,我们只与 Full Attention 对比。
4.3. Performance Comparison
- General Evaluation
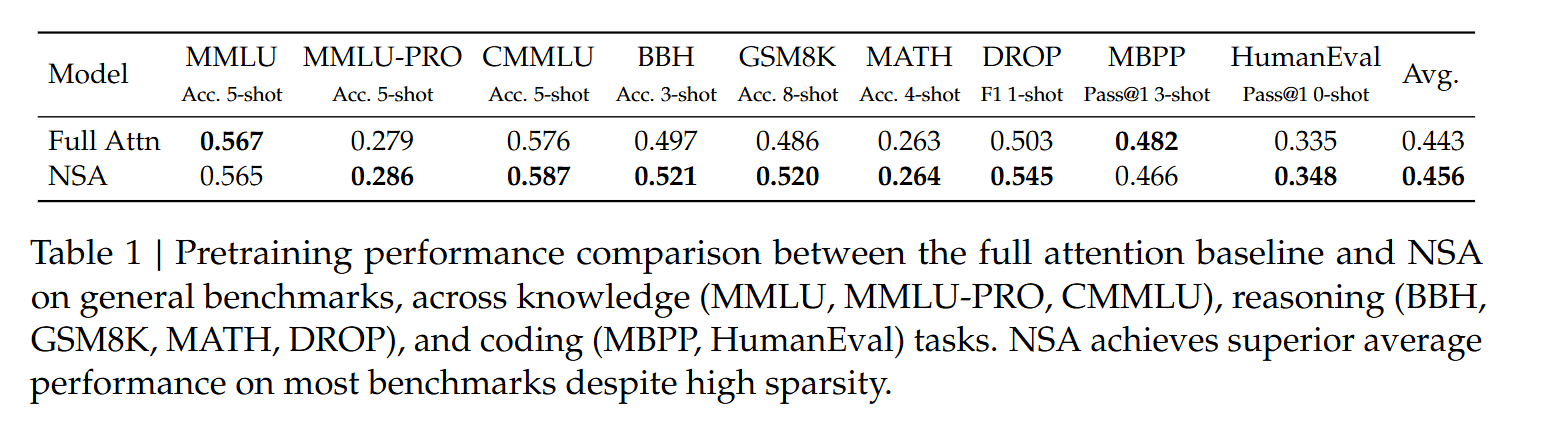
基本没有掉点,甚至略有提升。
- Long-Context Evaluation
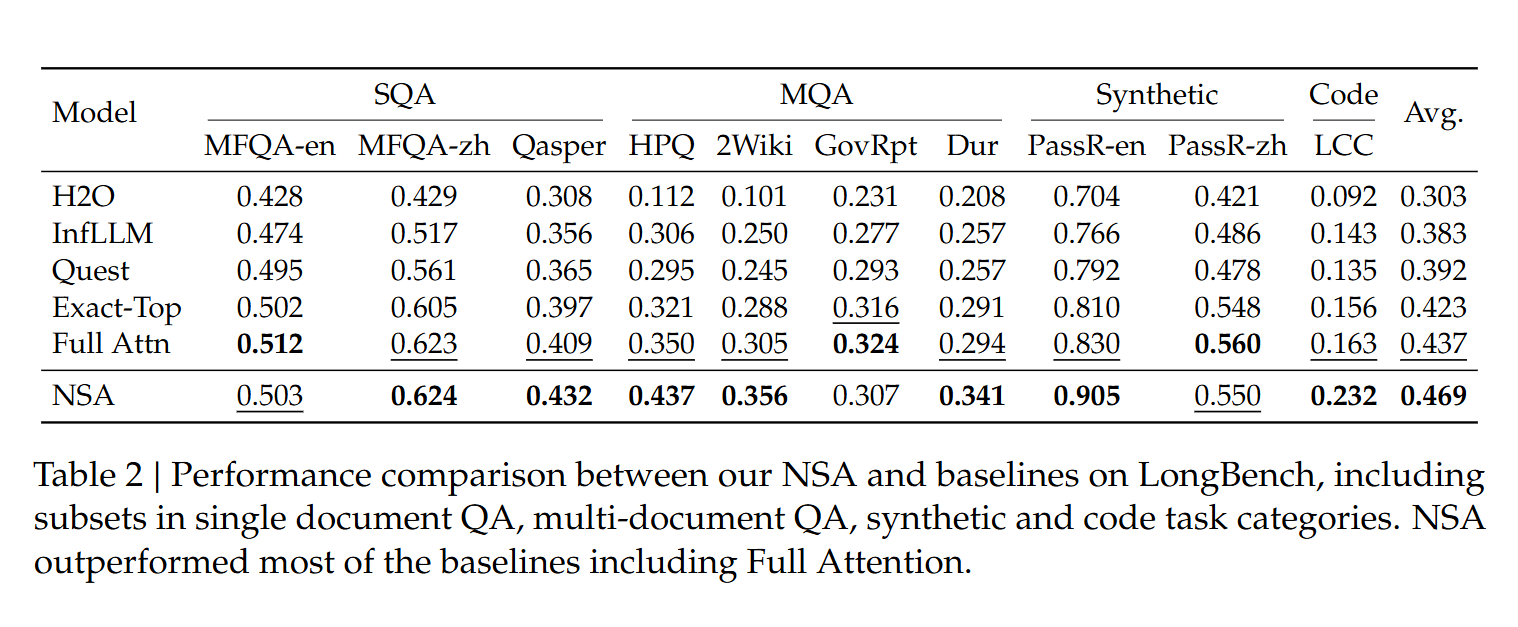

长上下文表现很好,不掉点。
- Chain-of-Thought Reasoning Evaluation
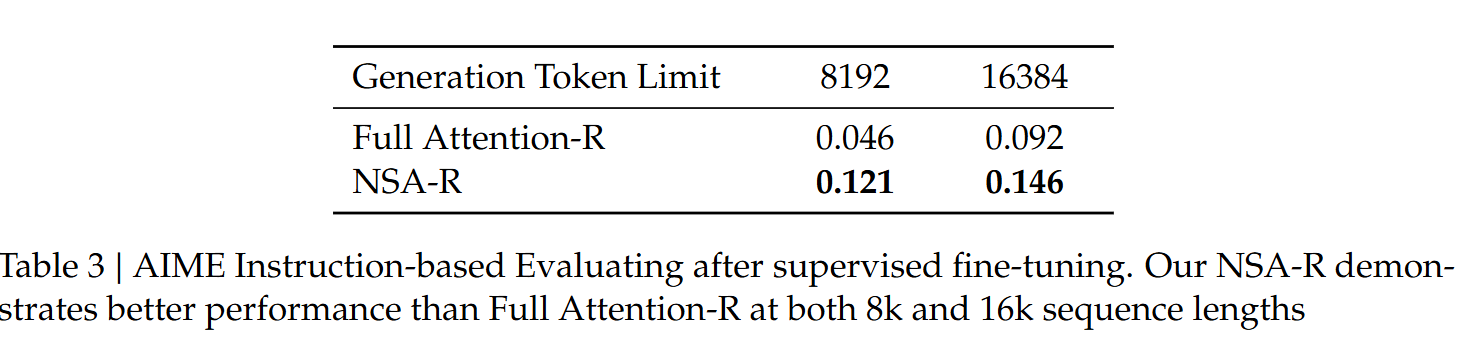
在CoT上表现也更好。
5. Efficiency Analysis
8*A100按Chpt4中的模型参数进行设置。
5.1. Training Speed
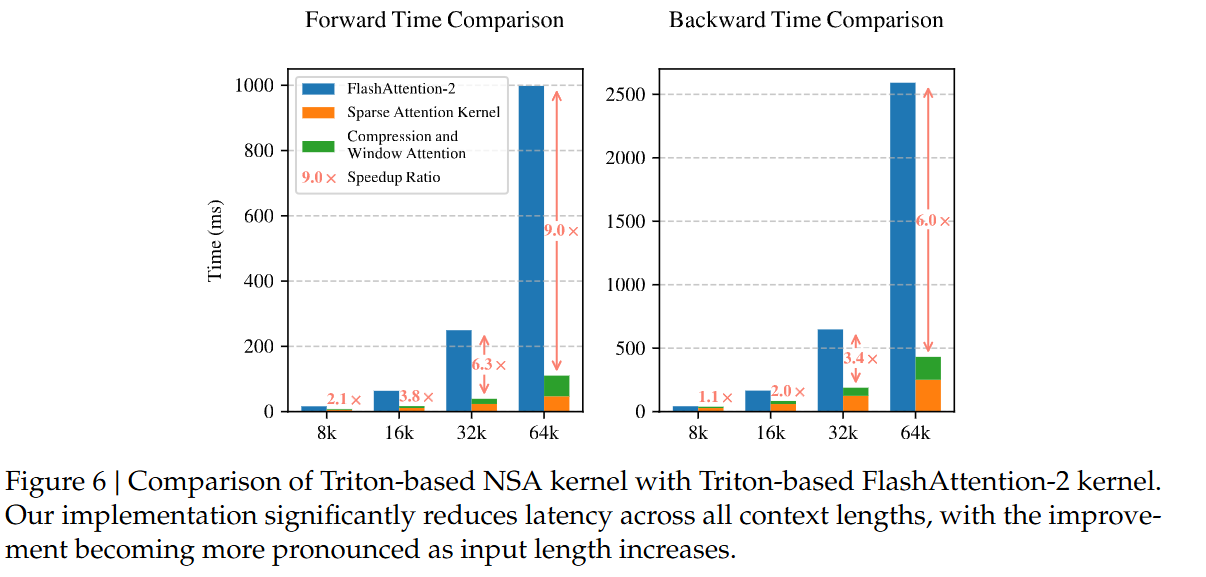
可以注意到上下文长Speedup越明显。
5.2. Decoding Speed
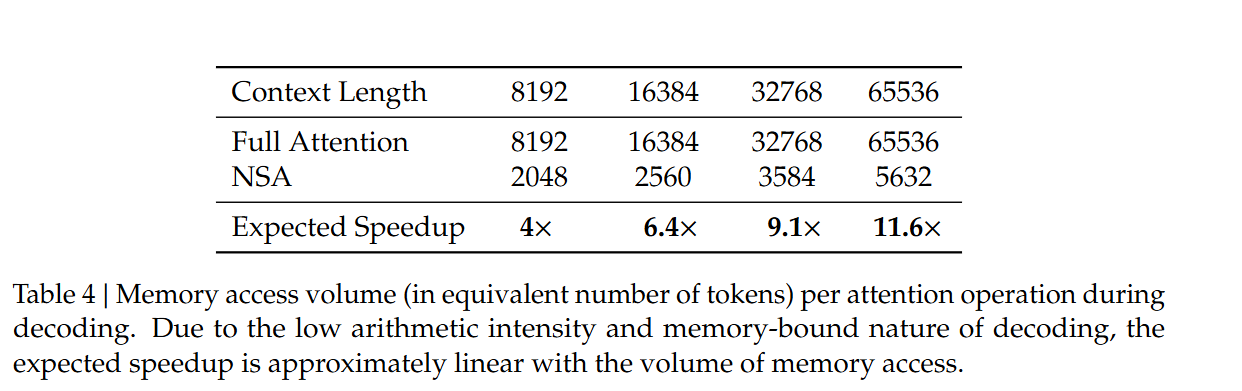
表上是”等效加载token数“。采用NSA的方法。
6. Discussion
本节回顾 NSA 的设计过程,并总结我们在探索不同稀疏注意力策略时得到的关键洞见。尽管本文方法取得了积极结果,但理解替代方案的挑战与注意力分布的可视化分析,同样能为后续研究提供有价值的上下文。首先,我们讨论促使我们做出当前设计抉择的替代 token 选择策略的挑战;随后给出注意力模式可视化,帮助理解注意力的分布规律。
6.1. Challenges with Alternative Token Selection Stategies
在设计 NSA 之前,我们尝试将既有稀疏注意力方法扩展到训练阶段。然而这些尝试遇到了多方面困难,最终促使我们设计出一种不同的稀疏注意力架构。
基于 Key 聚类的策略。 我们考察了类似 ClusterKV这类方法:把来自同一聚类的 Keys 与 Values 存放在连续内存区域。这在理论上可用于训练与推理,但面临三大挑战:
(1)动态聚类本身带来不可忽视的计算开销;
(2)算子优化因跨簇不平衡而变得困难,尤其在 MoE 系统中,专家并行(EP)的组间执行时间偏斜会导致持续性负载不均;
(3)实现层面的约束:需要周期性重聚类与按分块顺序训练的协议。这些因素叠加形成显著瓶颈,严重限制了其在真实场景中的有效性。
其他分块式选择策略。 我们也考虑了与 NSA 不同的分块式 key/value 选择方案,如 Quest与 infLLM。这些方法通常先计算每个 KV 块对当前查询 的重要性分数,再按分数选取 Top-n 块。现有方法面临两个关键问题:
(1)选择操作不可微。基于神经网络的分数估计需要辅助损失,这增加了算子开销,并且常导致性能下降;
(2)启发式、零参数的分数估计召回率较低,带来次优表现。
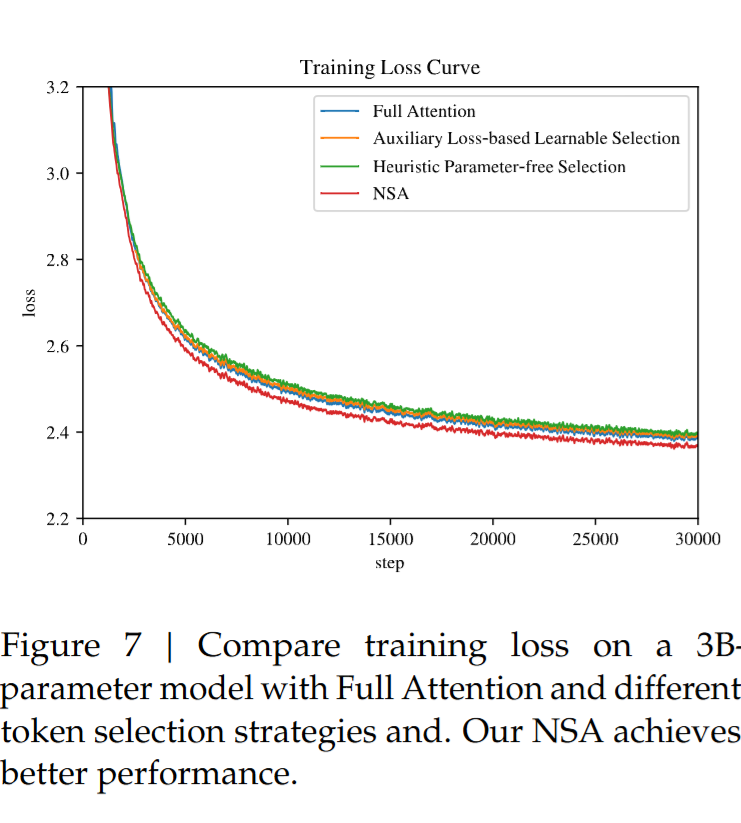
在一个3B、结构相似的架构上,对比了两种额外的实现和NSA/Full Attention的训练曲线
- 一种是为每个Token引入了一个额外的”Query“,并且每个Block还有一个代表性Key,块内注意力的均值生成块级别的监督信号,通过KL散度预测块的重要性
- 遵循Quest的策略,用Query和Key-Chunk按坐标min-max向量逐元素乘法评估重要性,在不引入额外参数的情况下做计算。
6.2. Visualization
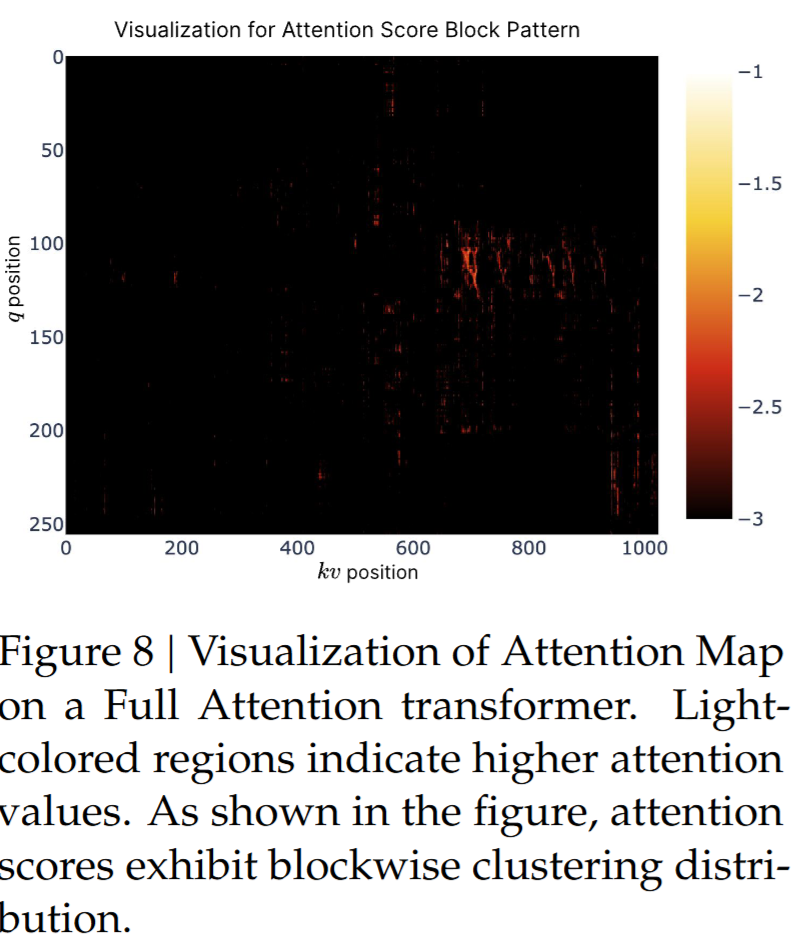
可视化揭示了一个有趣现象:注意力分数在空间上往往呈“分块式聚集”,相邻的 key 通常具有相似的重要性。这启发了我们的 NSA 设计:按空间连续性选择关键块可能是有效的途径。该现象表明,序列中相邻 token可能与查询 token 共享某种语义关系(具体性质仍需进一步研究)。基于此观察,我们选择在连续 token 块层面而非单 token 层面进行稀疏化,以提升计算效率并尽量保留高注意力模式。
7. Related Works
我们回顾通过稀疏注意力提升注意力计算效率的既有方法。按照核心策略,这些方法大致分为三类:(1)固定稀疏模式;(2)动态 token 裁剪;(3)面向查询的选择。下面分别介绍代表性工作。
7.1 固定稀疏模式
SlidingWindow 是常见做法,仅在固定窗口内计算注意力。StreamingLLM把“注意力sink”与局部窗口结合以处理连续文本流。MoA与 DuoAttention也采用类似的局部 + 汇思路来建模长序列。Longformer在局部窗口注意力与全局 token 之间交替,处理超长序列。与这些方法不同,NSA 不依赖预定义的稀疏模式,而是在训练中自动学习稀疏结构,从而保留利用完整上下文的潜力。
7.2 动态 token 裁剪
部分方法旨在推理时降低内存与计算开销,通过动态 KV-cache 剪枝实现。H2O、BUZZ与 SeP-LLM等方法会自适应地驱逐被判定为不重要的 token。FastGen与 HeadKV通过为不同注意力头分配不同策略来优化计算;SnapKV提出仅保留最关键的特征,从而高效利用内存。与这些推理导向的方法不同,NSA 在训练阶段即原生地引入稀疏性。
7.3 面向查询的选择
另一类工作关注与查询相关的 token 选择,以在保持注意力质量的同时减少计算。Quest采用分块式选择,按“查询 × 块坐标 min-max”的相似度估计块重要性。infLLM把注意力汇、局部上下文与可检索块结合;它通过为每个块选代表性 key 来估计重要性。HashAttention把“关键 token 识别”表述为推荐问题,把查询与 key 映射到海明空间并用学习到的函数度量相似度。ClusterKV先聚类再在聚类中选 token;MInference与 TokenSelect按 token 级重要性做选择;SeerAttention把查询与 key 分成空间块并执行分块选择以便高效计算。与这些方法相比,NSA 在训练、预填充与解码的整个模型生命周期中,实现了硬件对齐的稀疏注意力计算。
8. Conclusion
本文提出 NSA,一种面向硬件对齐的稀疏注意力架构,用于高效的长上下文建模。通过在可训练架构中融合分层的 token 压缩与分块式 token 选择,我们的体系在保持全注意力性能的同时,实现了训练与推理的加速。在通用基准上,NSA 的性能匹配甚至超过全注意力;在长上下文任务上,NSA 的建模能力更强;在推理能力上也获得了提升。上述优势伴随着可测量的时延降低与显著的加速收益。