帧间信息传递
- RNN like:维护一个隐状态,每次输入的时候更新这个状态,相当于保存了之前所有状态的融合
- Transformer
- cross attention like:Q是当前输入,KV是之前memory保存的东西
- self attention like:把当前输入拼接到之前的memory
- multi frame
1. 视频流任务
- 目标检测
- 在视频流中进行目标检测和分类的任务,用单帧的模型一般就可以做的比较好,因为现在的单帧目标检测模型效果就很好
- 强调视频流一般是考虑检测的鲁棒性(连续帧之间目标检测不容易闪烁)和实时性(FPS要求)
- 目标跟踪
- 跟踪目标,尤其是多目标跟踪
- 一般会要求在目标移动过程中被遮挡或者短暂消失也能预测到位置
视频生成有监督或者无监督地生成视频现在比较火的是给定文字Prompt+初始帧或者只有prompt,生成一段视频
自动驾驶相关的任务:
语意分割数据集如MIT DriveSeg,一般是视频+语意分割标记
- Occupancy Forecasting
- 预测车辆周围的空间在未来一段时间中是否会被占用,类似轨迹预测等
- 目标跟踪
- 多目标跟踪+分割,数据集有camera only的,也有视频+点云的
- BEV生成任务
- 从单个/多个cam或者cam+雷达生成BEV
- 有时生成的BEV还是被语意分割后的
- 车道线检测
- 端到端自动驾驶
- 仿真数据合成
事件相机/DVS 相关的任务
很多种多样,感觉主要是利用事件信息做视觉信息的补充,比如直接补充cam的信息,或者作为cam-Lidar/红外的一种中间状态,补充信息完善之前的任务
- SFOD: Spiking Fusion Object Detector,SNN+Event Camera 的目标检测,CVPR2024
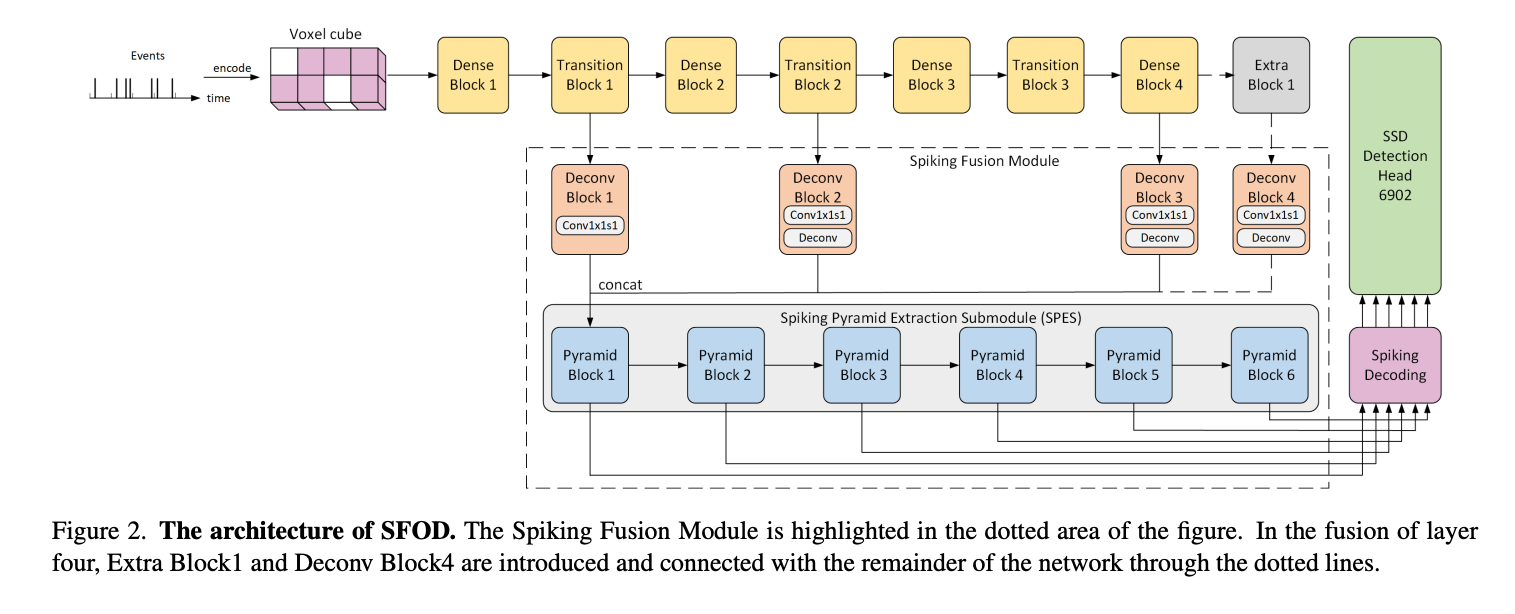
实际上是把事件相机输出的信息首先按照frame组织,利用CNN(DenseNet)提取了特征,再将特征通过Spiking Fusion Module输入到SPES中,感觉有点绕远路的感觉。并且没有多帧之间的处理。
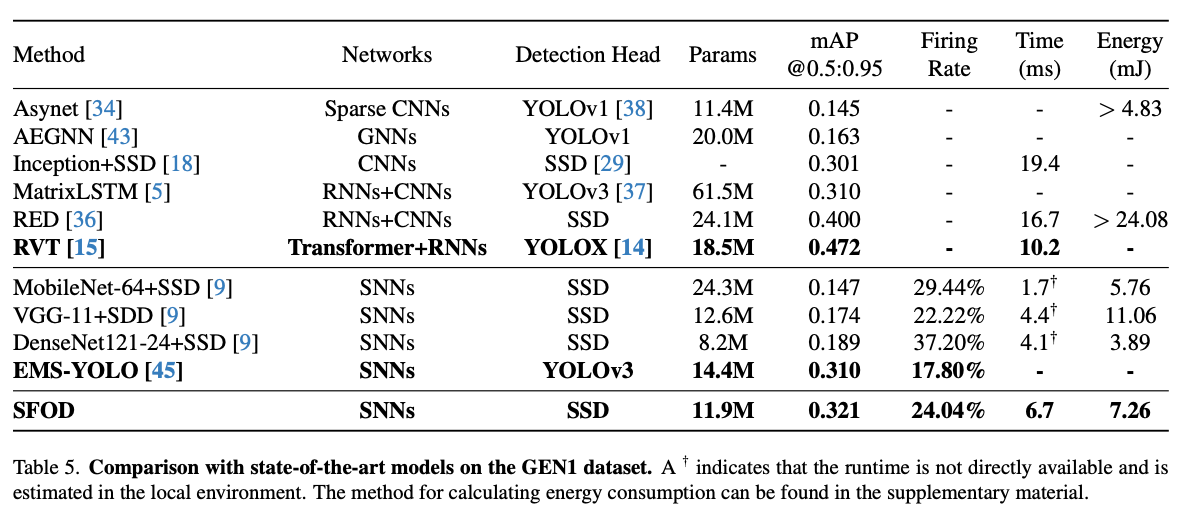
其他工作
- Efficient and Effective Time-Series Forecasting with Spiking Neural Networks ,微软的用SNN做时间序列预测的工作,ICML2024
- Autaptic Synaptic Circuit Enhances Spatio-temporal Predictive Learning of Spiking Neural Networks ,北大的神经元改进工作,ICML2024
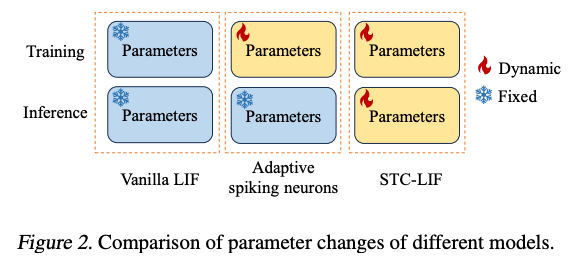
文章表示LIF这样的neuron只适合静态识别这样的场景,在学习时空预测这样的任务的时候表现不好。文章提出的STC-LIF
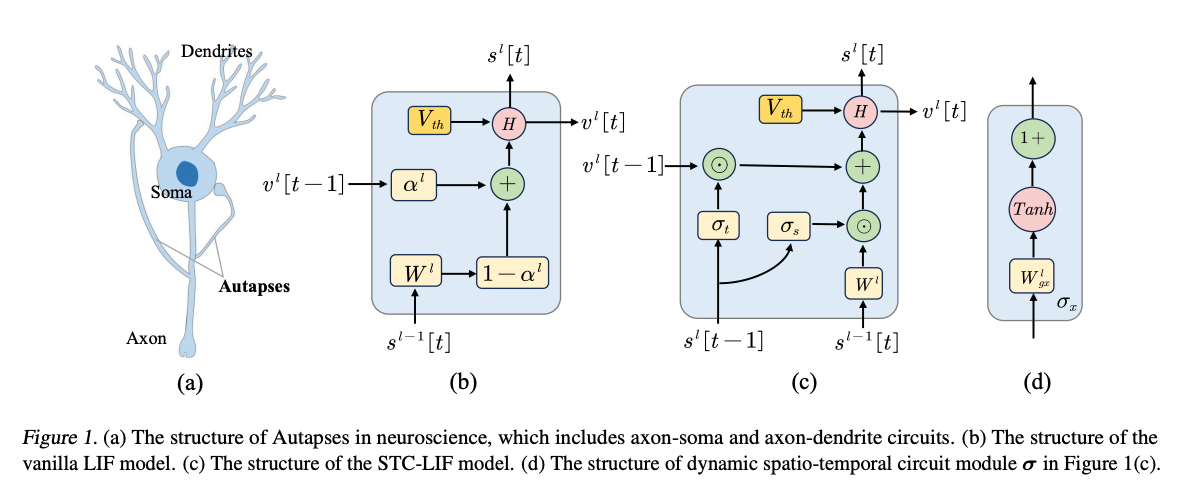
引入了生物学中的自突触,相当于增加了参数,用于调节历史信息(膜电位)和当前信息(输入电流)的权重。Leakage参数不再是一个单独的指数/线性泄露,而是根据neuron自己以及相邻neuron上一个时刻的输出。
STC-LIF的Neuron可以表示为:
其中是Hadamard积,分别是轴突-树突电路调节因子和轴突-胞体调节因子。
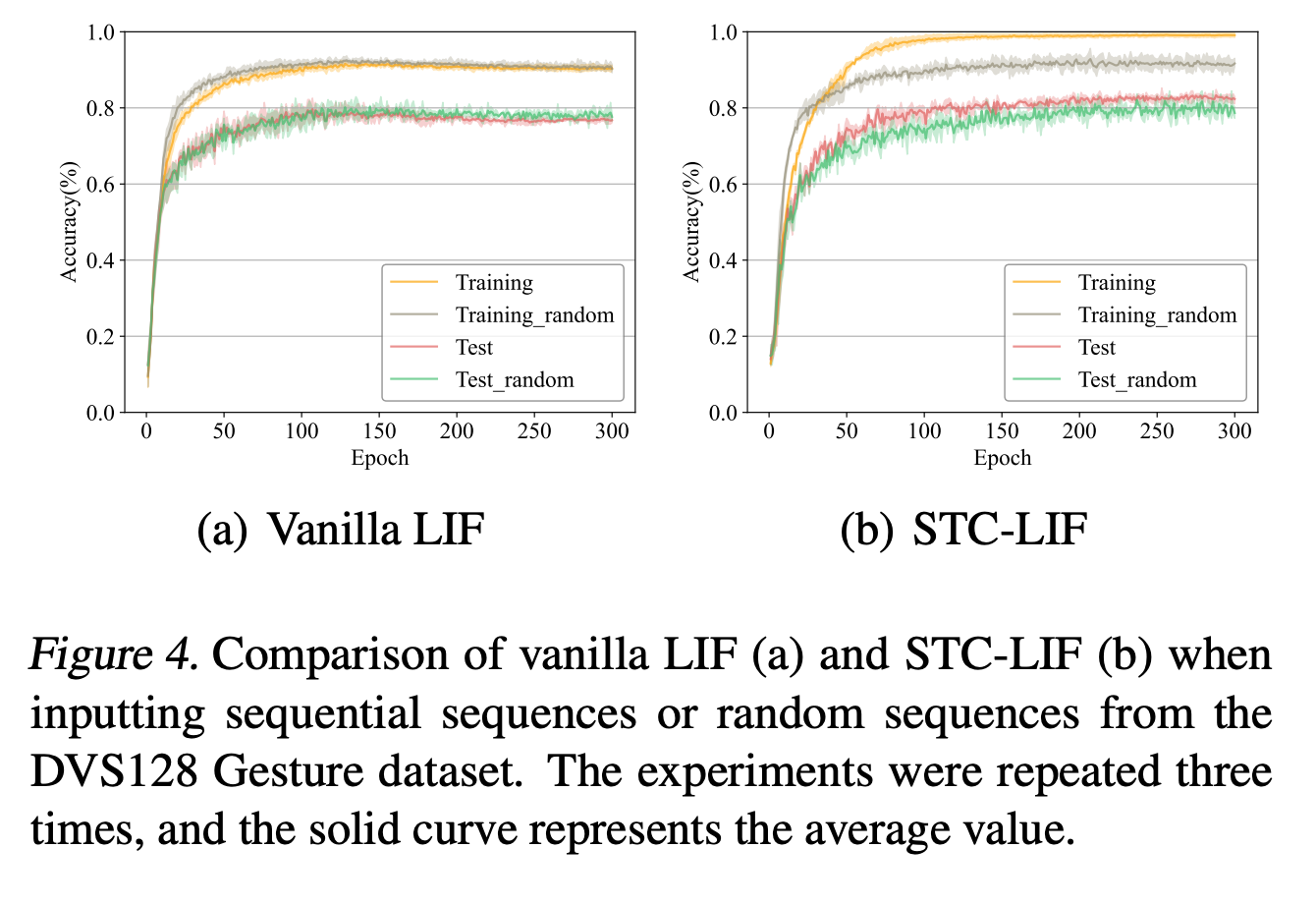
有一个比较有趣的结论:使用LIF,但是训练的时候打乱帧的顺序,不会导致LIF的性能下降,证明LIF很有可能没有学习到时间顺序上的关系,但是本文提出的STC-LIF则出现了性能下降,证明这种Neuron学习到了时间尺度上的信息。
- Point-to-Spike Residual Learning for Energy-Efficient 3D Point Cloud Classification ,安徽大学的工作,在输入电流上和多个neuron组织的残差连接
最终的方向
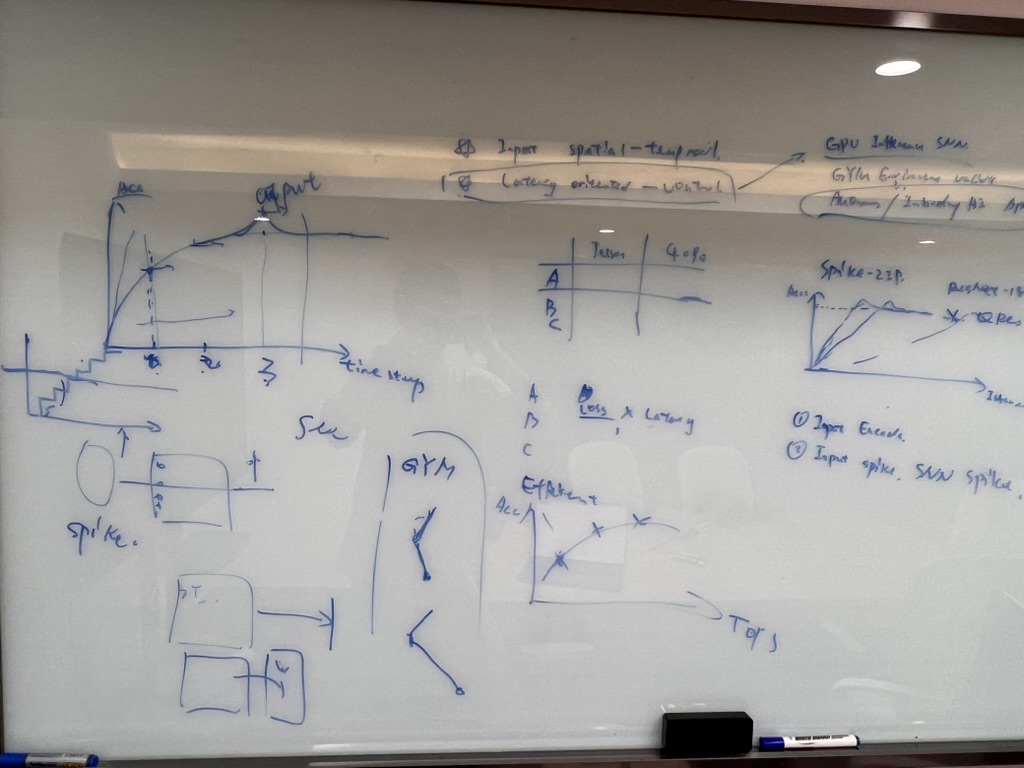
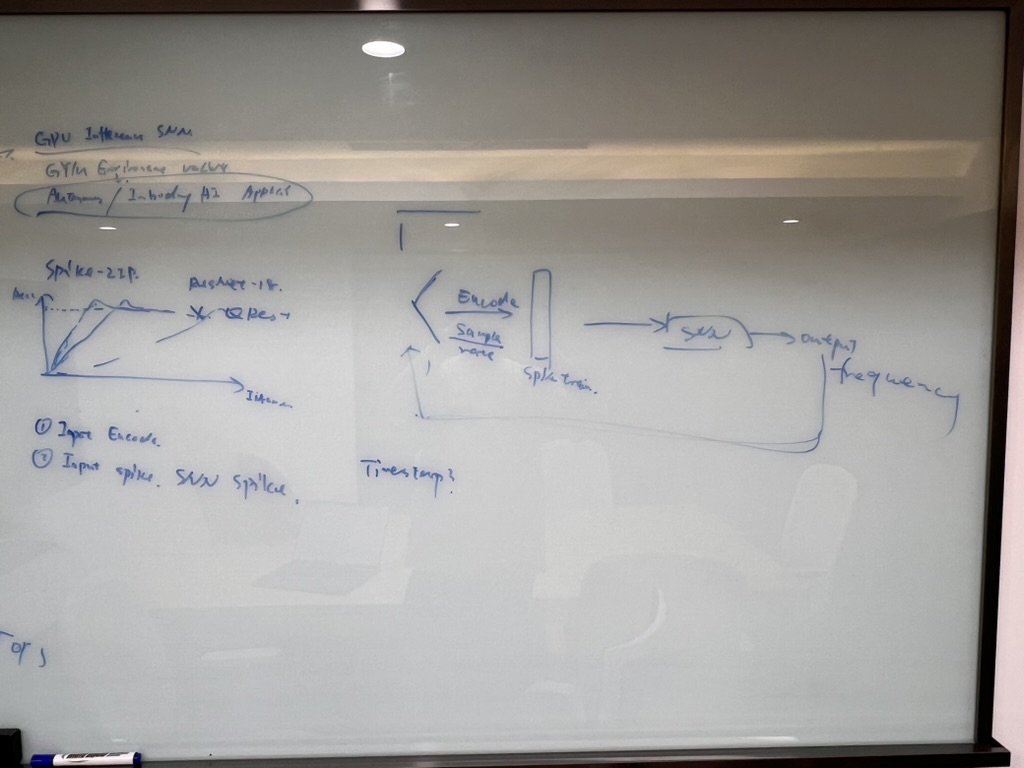
验证SNN在OpenAI Gym这样的时序输入下,”First Arrival Control”的latency低于传统ANN的这个insight是否能立住。