摘要: 脑启发的脉冲神经网络(SNN)因其相较于传统人工神经网络(ANN)的高效性而备受关注。目前,ANN到SNN的转换方法可以使用卷积神经网络作为骨干架构来生成SNN,在计算机视觉(CV)任务中以超低延迟(例如,8个时间步长)实现与ANN相当的准确性。尽管基于Transformer的网络在CV和自然语言处理(NLP)任务中已经实现了普遍的精度,但基于Transformer的SNN仍然落后于其ANN对应物。在这项工作中,我们介绍了一种新颖的ANN到SNN的转换方法,称为SpikeZIP-TF,通过这种方法,ANN和转换后的SNN完全等效,因此不会造成精度下降。SpikeZIP-TF在ImageNet数据集的CV图像分类任务中实现了83.82%的Top-1准确率,在NLP数据集(SST-2)上实现了93.79%的准确率,均高于最新的基于Transformer的SNN。代码可公开获取: https://github.com/IntelligentComputing-Research-Group/SpikeZIP-TF 。
1. Introduction
基于BPTT(Back-Propagation Through Time)的直接训练方法,目前因为梯度估计的不准确,导致训练出来的SNN和ANN之间的精度仍然存在差距。
Conversion base的方法可以利用ANN训练中得到的参数,在低latency的情况下还能保证on par的精度。但是转换的方法在transformer上遇到的问题是,像softmax、layernorm、Attention这样的操作很难构建一个等价的SNN表达。
Contributions of SpikeZIP-TF are summarized as follows:
- We propose an ANN-SNN conversion method called SpikeZIP-TF that builds the equivalence between the activation-quantized Transformer-based ANN and SNN by supporting the SNN-unfriendly operators of ANN (e.g., softmax and layernorm) in converted SNN.
- SpikeZIP-TF deals with both the CV and NLP tasks by converting the quantized vision Transformer (ViT) and Roberta to SNN and achieves the state-of-the-art accuracy than competing Transformer-based SNNs.
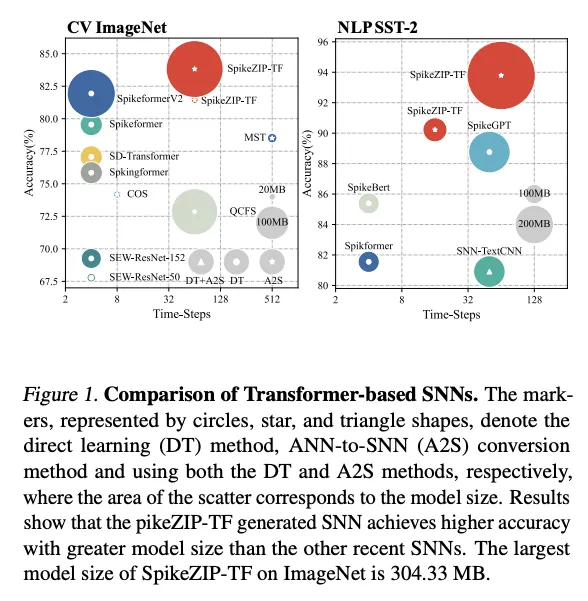
2. Background and Related Works
Spiking Neurons: IF和RELU之间的相似性让IF在ANN2SNN这样的模式中非常常见,但是仍然存在会累积的误差。最近的ST-BIF可以进一步接近Quantized RELU的等价性。但是它和Transformer中的量化激活函数仍然有差距。
Learning Methods of SNN: 直接训练和转换。
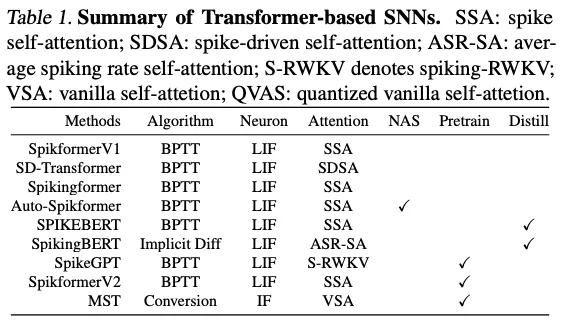
Transformer-based SNNs: 一个嵌入层做embedding,一些transformer层,然后一个契合任务的head。SNN的工作如SpikeGPT,SPIKERBERT、SpikingBERT。
The limited adoption of A2S methods in Transformer-based SNNs stems from the challenge of establishing mathematical equivalence between operators in quantized Transformer-based ANNs and SNNs. In SpikeZIP-TF, we address the operator equivalence challenge by introducing a novel spiking equivalence self-attention (aka. SESA). Additionally, for softmax and layer-norm, we employ a differential algorithm to design their equivalent spiking forms. By integrating our spiking operators, SpikeZIP-TF establishes equivalence between quantized Transformer-based ANNs and SNNs.
3. Methods
3.1. Dynamics of Neuron

量化的方程:
假设,,,则neuron就和上面的量化过程等价。
3.2. Transformer-based SNN in SpikeZIP-TF
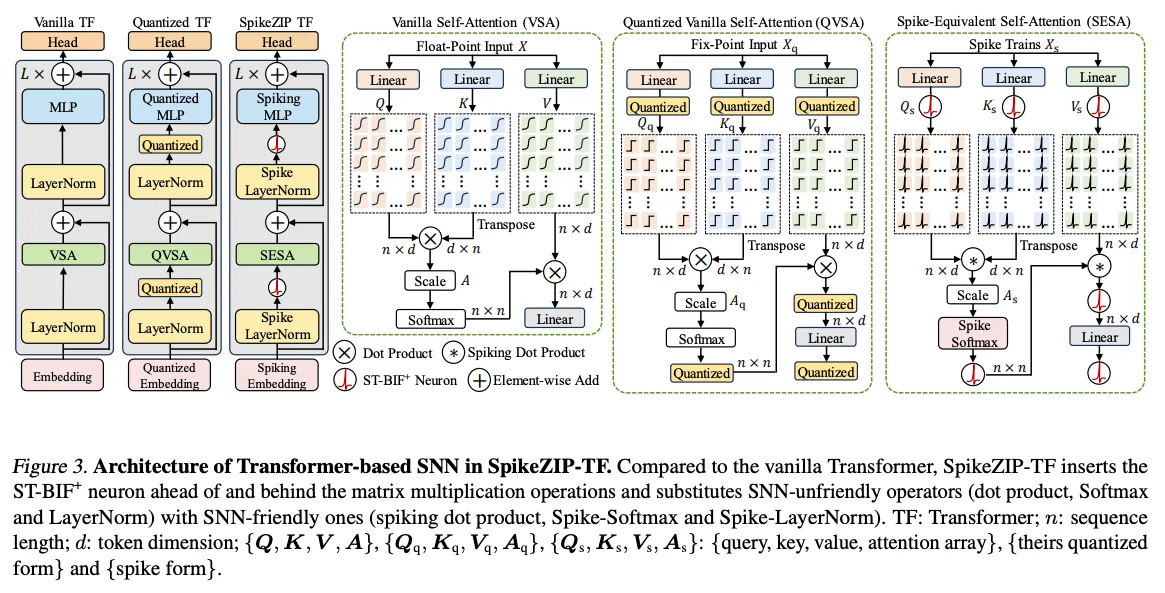
3.2.1. Architecture Overview
Given a target Transformer-based ANN and to obtain its SNN counterpart, we conduct the following procedures:
- 在矩阵乘算子之前和之后都做量化,获得一个量化过的transformer,参考I-BERT等之前的工作;
- 做QAT的时候,量化方程被替换为 Neuron,使得矩阵乘的输入和输出都是spike形式的;
- 将SNN-unfriendly的算子(Softmax,LayerNorm,dot product)替换成SNN-friendly的算子(Spike-Softmax,Spike-LayerNorm,spiking dot product)
3.2.2. Embedding & Head For SNN
之前有的工作是在嵌入层之后接Neuron,但是这篇工作选择让embedding输出膜电位。(参考工作:Masked spiking transformer. ,Spikformer v2: Join the high accuracy club on imagenet with an snn ticket.)就是直接把embedding层得到的结果作为后面的Neuron的初始状态。
3.2.3. Spike-Equivalent Self-Attention(SESA)
2 principle:
- Ensuring that the accumulated output remains equivalent to quantized vanilla self-attention;
- aligning with the computing paradigm in SNN.
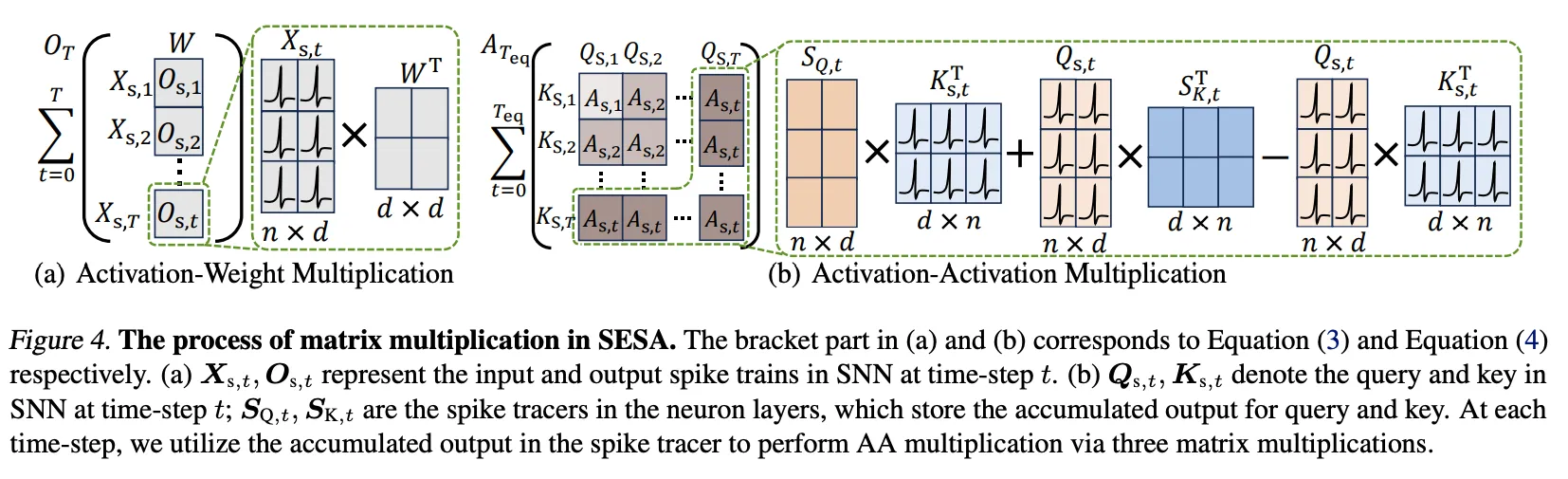
有两种乘法,Activation * Weight的和Activation * Activation的。
AW乘法:
每个timestep都把结果累加到中;
AA乘法:
处理的是这样的两个从weight中获得的spiking结果,最终得到最后的Activation。
3.2.4. Spike-Softmax & Spike-LayerNorm
是softmax或者layernorm。做法就是对所有的timestep做累加,做对应的算子操作,然后做差分。
3.3. Complexity Analysis

4. Experiments
4.1. Experiments Setup
Vision Benchmarks.
Various vision datasets are adopted for evaluation. 1) static vision datasets, including CIFAR10/100 and ImageNet. 2) neuromorphic vision dataset: We evaluate SpikeZIP-TF on CIFAR10-DVS. CIFAR10-DVS is a neuromorphic event-stream dataset with 10 distinct classes, which is created by leveraging the dynamic vision sensor (DVS) to convert 10k frame-based images from CIFAR10 dataset into 10k event streams. For ImageNet, we apply the pre-trained
Vision Transformer-Small/Base/Large (aka. ViT-S/B/L) as the source ANN. For CIFAR10/100 and CIFAR10-DVS, we utilize the pre-trained Vision Transformer-Small (aka. ViT-S) as the source ANN.
NLP Benchmarks.
Various natural language understanding (NLU) datasets are evaluated, including English (MR, Subj, SST-2, SST-5) and Chinese (ChnSenti, Waimai). For NLP tasks, the Roberta-Base/Large (aka. Roberta-B/L) is chosen as source ANN owing to its high accuracy in NLP benchmarks.
4.2. Results Comparison
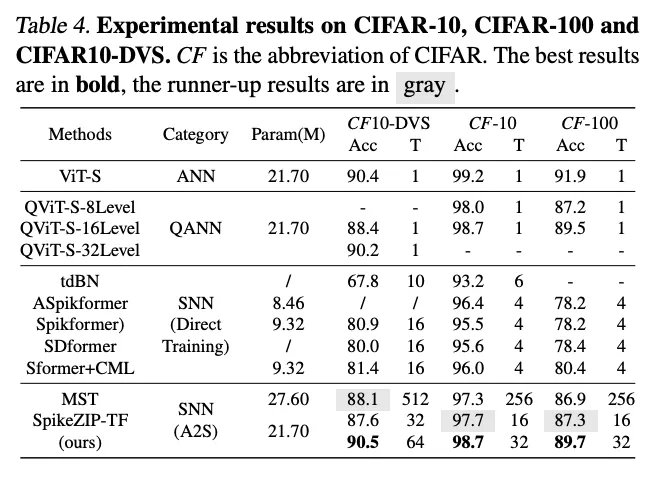
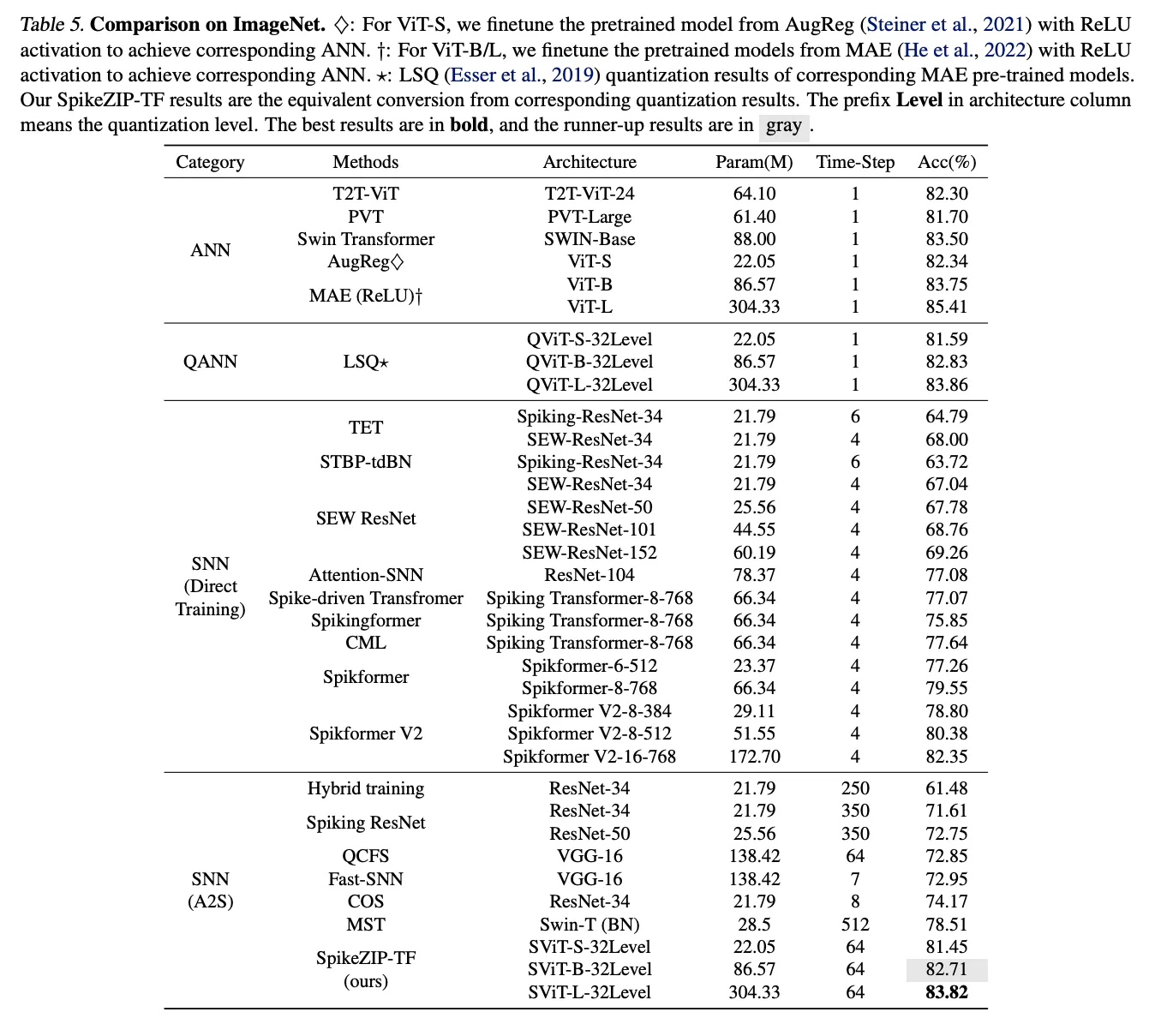
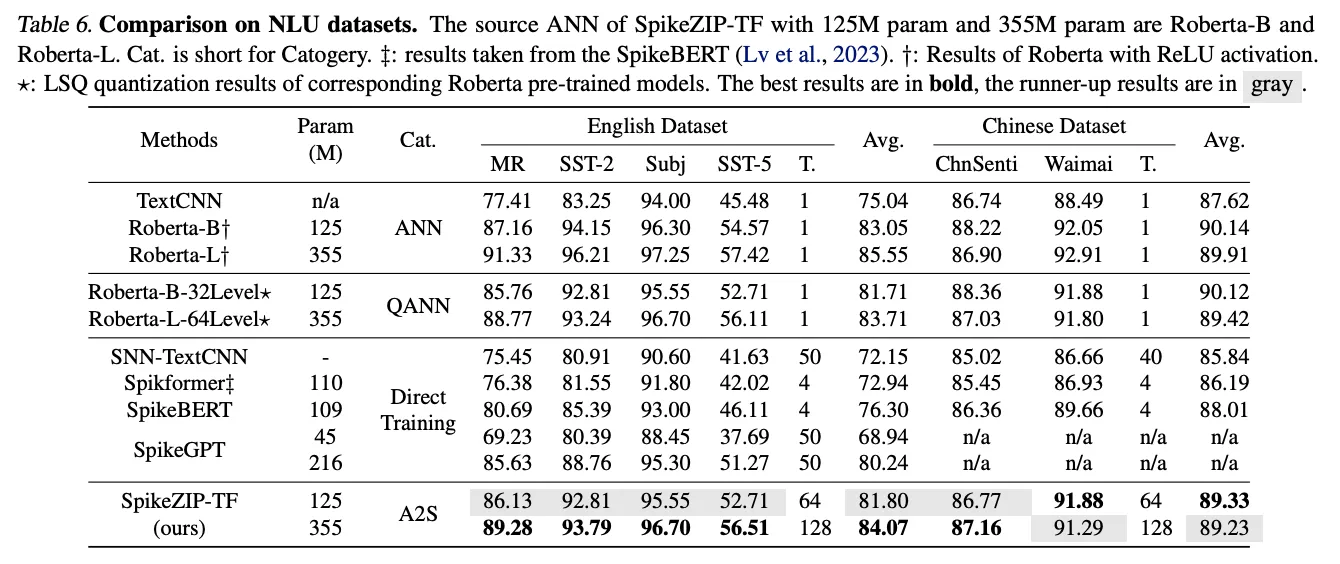
有效,相比直接训练的方法参数更少,timestep更低,训练成本更低。
4.3. Training Cost Analysis
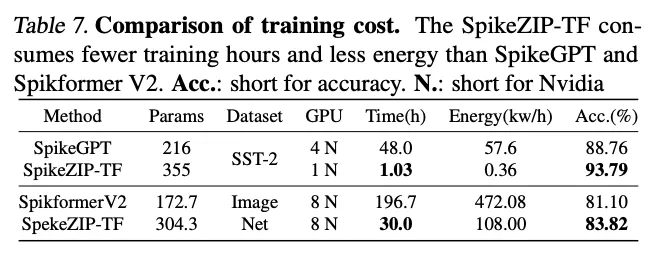
远低于之前方法的训练耗时和资源需求量,能够取得更高的精度。并且可以直接利用已经训练好的ANN,跳过预训练环节,因为只用做QAT的训练。
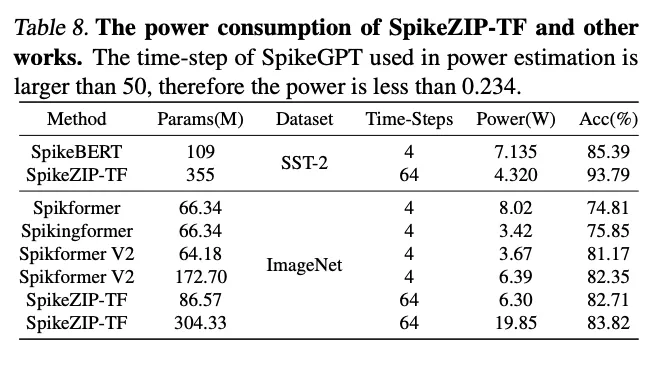
4.4. Power Estimation on Neuromorphic Hardware
能耗的公司可以用
来估计。
4.5. Ablation Study
Accuracy vs. Time-Steps
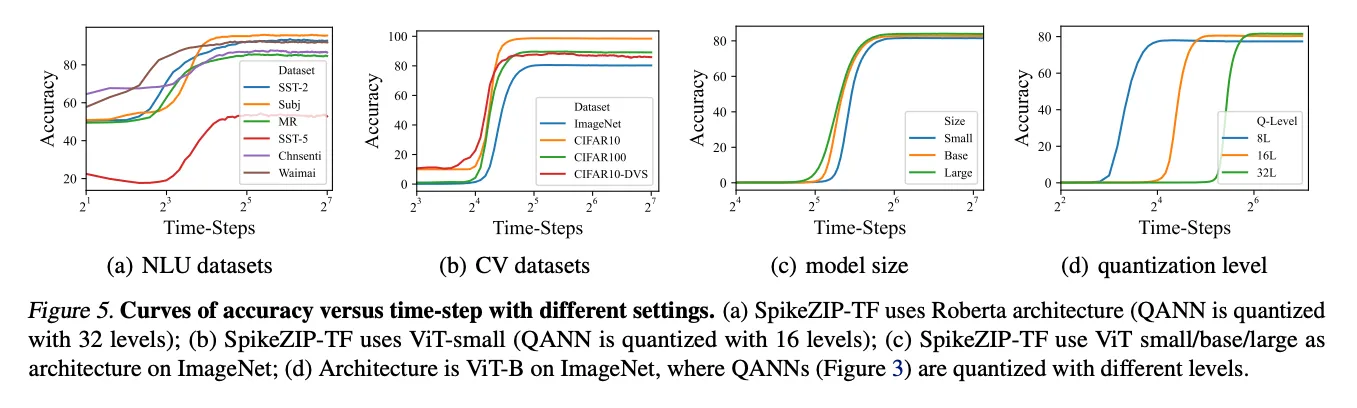
在timestep大于一个值之后,准确率显著提高了,因为SpikeZIP-TF 需要几个时间步数来累积其输出。在更复杂的数据集上,这个值更大;在更大的模型上,这个值更小;在更高的量化位宽上,这个值反而会更大。但是更低的量化位宽又会导致更低的精度,在latency和精度之间也要做出选择。

5. Conclusion
We anticipate to extend our SpikeZIP-TF on direct learning methods, which
is expected to reduce training cost and achieve promising performance under ultra-low inference time-step.