摘要: 大型语言模型(LLMs)在语言理解、生成与推理方面取得了令人瞩目的成果,并推动了多模态模型的能力边界。作为现代 LLM 的基础,Transformer 以其优良的扩展性提供了强力基线。然而,传统的 Transformer 架构计算开销可观,对大规模训练与实际部署构成了显著障碍。本文综述系统审视了为克服 Transformer 内在局限、提升效率而提出的各类创新 LLM 架构。以语言建模为起点,我们涵盖了线性与稀疏序列建模方法的背景与技术细节、高效的 full attention 变体、稀疏 Mixture-of-Experts(MoE)、融合上述技术的混合式模型架构,以及新兴的 Diffusion LLMs。此外,我们讨论了这些技术向其他模态的迁移应用,并思考其在构建可扩展、资源感知的基础模型方面的更广泛影响。通过将近期研究归入上述类别,本文为现代高效 LLM 架构勾勒出一幅蓝图,并期望据此激发面向更高效、更通用 AI 系统的后续研究。GitHub: https://github.com/weigao266/Awesome-Efficient-Arch
1. Intro
1.1. Backgrounds
LLM在语言理解、多模态处理、复杂推理上都有巨大的进展,然而其特性也引入了巨大的计算需求。Transformer的self-attention机制相比于之前的RNN/LSTM有更好的长程建模能力,但是它同时带来的开销同样也影响了方法进一步扩展到更长的序列长度上。在此情境下,我们必须追问:如何突破 Transformer 的效率“天花板”?”高成本”的“智能”真的是唯一的前路吗?
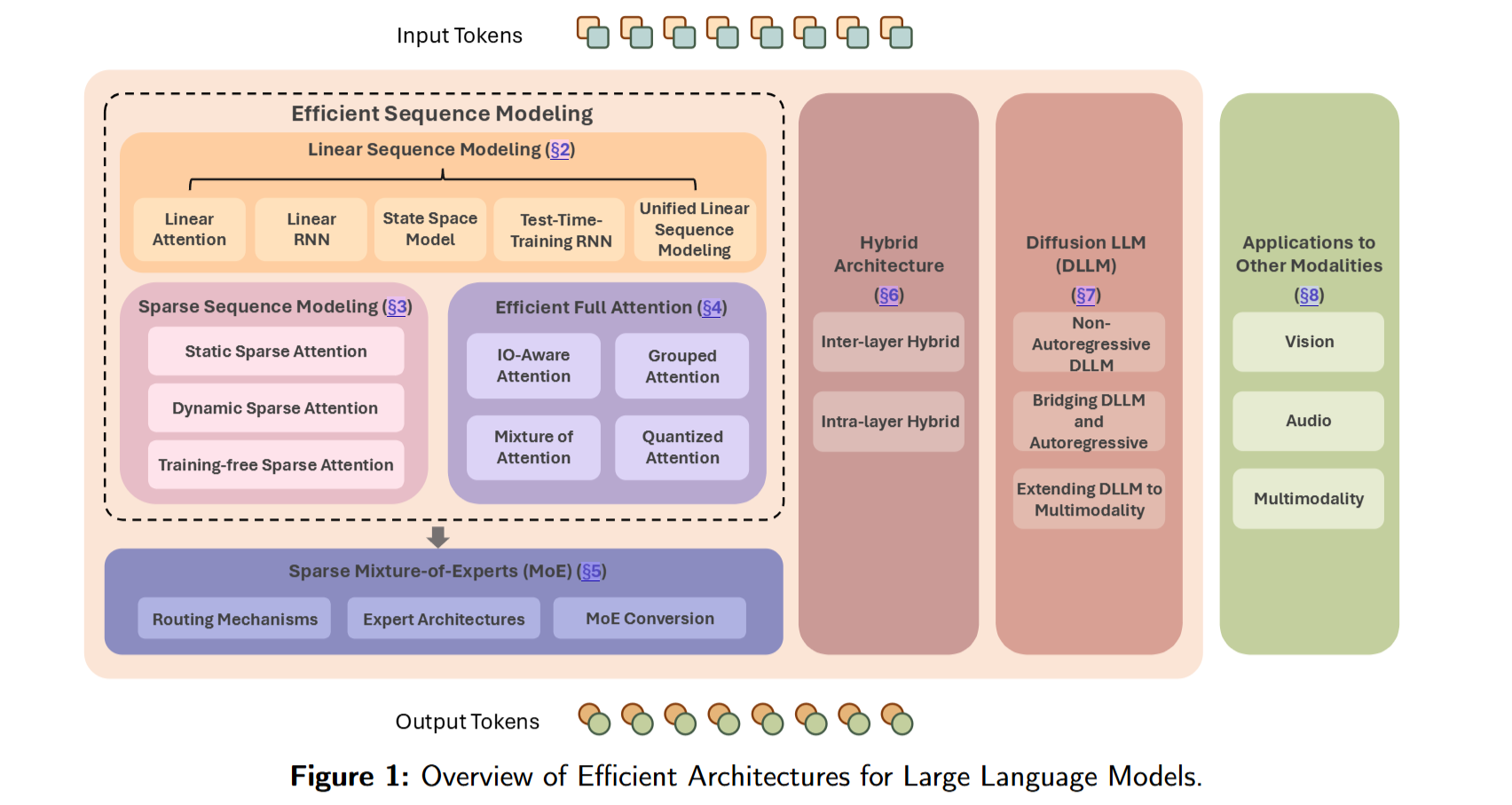
为了应对这些紧迫的挑战,本文综述深入梳理并系统归类社区中常见的所有方法:
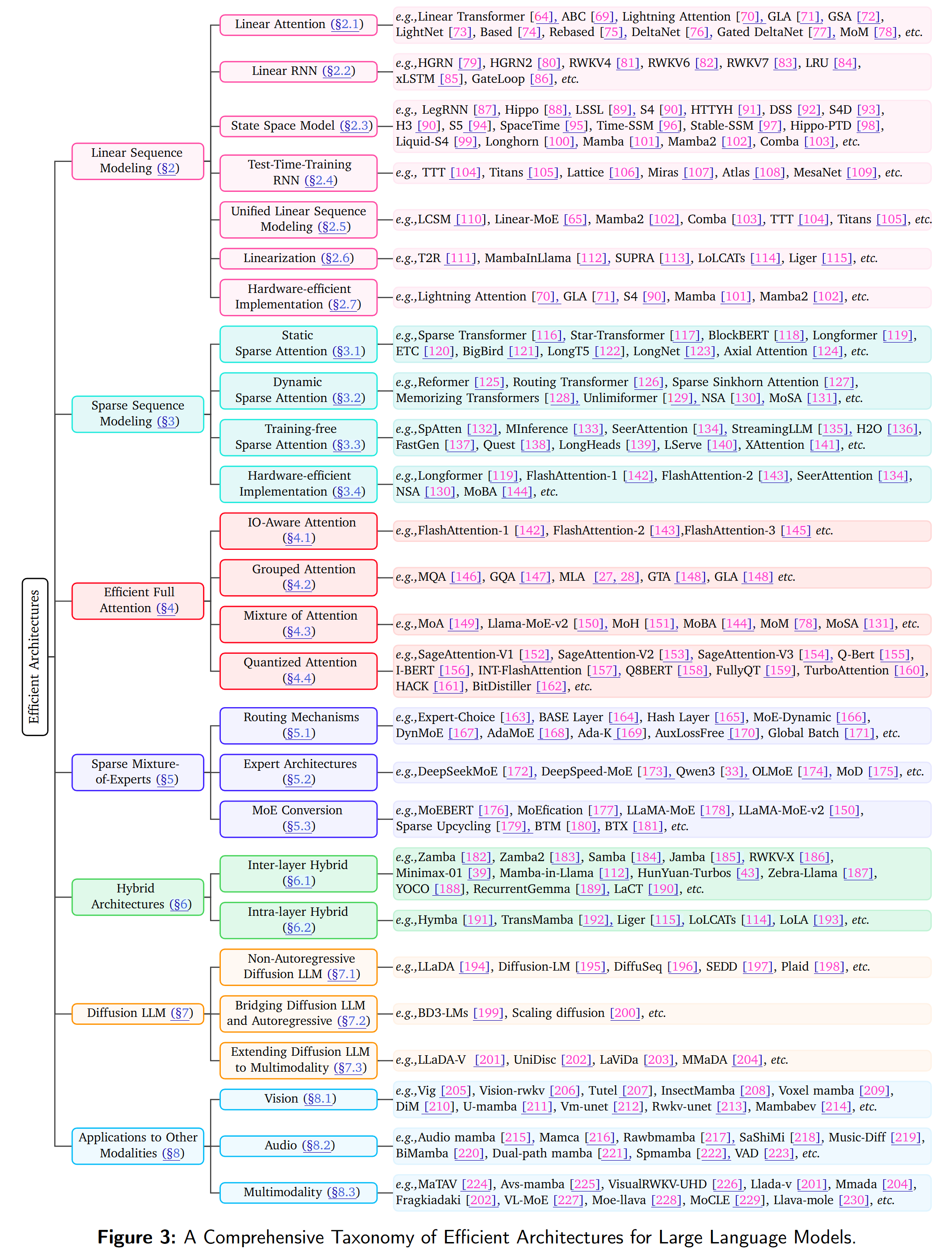
可以概括为:
- Linear Sequence Modeling,通过将self-attention机制改进为复杂度降低推理计算开销,同时推理阶段不再需要存储KV Cache,从而降低部署成本;
- Sparse Sequence Modeling,不再对所有 token 对计算注意力,而是选择性关注注意力图中的一小部分交互,以降低计算与内存需求,同时力求保持性能;
- Efficient Full Attention:保持理论上二次复杂度不变的前提下提升 softmax attention 的效率,例如,Flash-Attention系列为代表的,通过 I/O-aware 的 attention 机制改善访存效率,或通过分组查询机制(如 GQA)压缩 KV cache;
- Sparse Mixture of Experts,MoE系列;
- Hybrid Architectures:将Linear Attention与Full Attention相结合的范式;
- Diffusion LLMs:探索用于语言生成的非自回归扩散模型,为高效且高质量的文本生成提供新的可能。
此外,本文还讨论面向其他模态的应用。
1.2. Position and Contributions
本文从 Transformer 的关键组成出发,更全面、条理化地综述了高效 LLM 架构的最新进展。我们着重归纳其设计原则、性能收益、已知局限与潜在走向。通过对当前成果与新兴趋势的综合,我们期望为研究者与工程实践者构建更高效、更可扩展的 LLM(及更广泛的基础模型)提供支持。
本文的主要贡献:
- 高效序列建模的系统性综述:通过梳理Transformer相关和Linear Attention社区的最新进展,总结他们的设计动机、性能权衡与实现细节,提炼出共性主题,并将其技术追溯到其出发点;
- 更广义的Transformer组件优化:除序列建模外,我们将视角拓展到其他关键子模块,涵盖支持条件计算的稀疏 MoE、在层内或层间融合线性与标准注意力的混合架构,以及基于扩散的语言生成新范式。该更宽视角强调:Transformer 的不同部件都可被重新想象以追求效率;
- 多模态与多领域应用。
2. Linear Sequence Modeling
总体而言,linear sequence modeling可以分为以下四个种类:(1) Linear Attention; (2) Linear RNN; (3) State Space Model; (4) Test-time Training。这四种方法各自源于不同的动机与数学表达。本文除了讨论上述四种方法外,还额外讨论Linearization这一较新的方向,以较低的代价将Full Attention转换为线性架构。
2.1. Linear Attention
首先回顾标准Transformer:
最早的Linear Attention由Linear Transformer这一工作提出,以feature map/Kernel的方式近似替代softmax attention:
取上式即退化为Full Attention。Linear Attention用做近似,此时:
则重排有
令
可以写出上面的式子的递推形式:
通过将改写为,计算避免了显式构造的注意力矩阵,将计算复杂度从降低到。
Softmax Approximation via Feature Mapping
Linear Attention的关键是,Linear Transformer选择:
以确保非负相似度。取的方法还包括
- random feature projection
利用的矩:
令
则
采样个元素可以用来估计期望。
- low rank kernel
选择个元素,近似整体的Kenrel:
本质是对核的列空间做低秩投影。
- focused function
朴素线性注意力的“平滑”权重常不够尖锐(softmax那种“过度自信”的attention score 分布)。做法是让映射带可学习温度/聚焦指数:
- 等。
上面的方法在计算效率上收益显著,但是对full attention的逼近在长上下文检索等任务上仍有不足。Based将Linear Attention和sliding-window attention进行混合;ReBased进一步将扩展到科学系参数的多项式核。同期,还有采用Hedgehog feature mapping模仿softmax尖锐形状的方法、提出输出归一化使训练梯度更加稳定的方法,以及采用归一化指数特征映射的训练稳定方法。
Gating Mechanism in Linear Attention
与 softmax 注意力相比,朴素线性注意力在序列建模能力上常存在明显差距,其中一部分原因在于它依赖累积式记忆更新 ,易产生记忆冲突 并缺乏信息流的动态调节。
早期如TransnormerLLM引入与数据无关的时间不变衰减、引入面向I/O的Lightning Attention、Lightning Attention-2,显著提高效率。RetNet以保留(Retention)机制引入与数据无关的衰减想,改善序列建模。
尽管如此,一个理想的情况显然是,模型能够根据新的输入与现有的记忆进行交互,动态清除不重要的记忆,为新信息腾出空间。GLA用输入驱动的Gating机制提升建模效率;GSA结合bounded-memory control的context aware的Gating机制;LightNet采用加性递归替代多维序列中的”乘性衰减“,实现了基于单次扫描的高效处理。MetaLA从理论上证明了需要一个时变的Gating机制来更好地逼近softmax attention;ReGLA进一步在激活接近饱和时对忘记门加精炼门,提高性能与稳定性。
Delta Learning Rule in Linear Attention
一个有效的序列模型应能删除较弱的 KV 关联以纳入新信息,而且这种删除应取决于新输入与记忆状态的相互作用 。从fast weight programming 视角看,GLA 等线性注意力中的递归隐藏态/记忆,本质上是把输入 query 映射为输出的快权矩阵 ,其更新遵循类似 Hessian 的规则,受记忆容量限制。
因此DeltaNet提出:
支持在推理时进行元学习/在线自适应。据此产生一系列基于 delta 规则的线性序列模型:DeltaNet与 TTT 框架关系密切,把记忆作为可训练分量并用梯度下降更新(为凸显差异,TTT 家族另见 §2.4);为克服 DeltaNet“每步仅更新一个 KV 对”的限制,Gated DeltaNet加入门控以更灵活地控制记忆、快速剔除过时信息;MesaNet融合 Mesa layer,可在推理时动态调节计算成本,使用递归最小二乘(RLS) 进行快权更新,可视为二阶在线学习器,并通过共轭梯度避免矩阵求逆、支持按块并行的硬件高效实现。此外,Comba与 RWKV7 也属于此类(但本文将在 SSM 与 Linear RNN 各节分别讨论,以突出其结构特征与联系)。
Log-Linear Memory in Linear Attention
在Linear Attention和Full Attention之间的一种折中,选择按照对数增长地扩展记忆。Log-Linear Attention给出把固定大小的隐藏态替换为按对数增长的隐藏态集合的通用框架,可在训练达到、推理时的复杂度。PSM与 Attraos则利用 Blelloch 并行扫描 将线性递推扩展至对数尺度。
2.2. Linear RNN
RNN:
其参数量不随时间步增长而变化,可在递归形式下实现线性时间复杂度的序列建模。
传统 RNN 因循环依赖而难以并行训练且效率偏低,限制了对长期依赖的建模与规模化能力。其根因在于隐藏状态的更新包含矩阵乘法与非线性激活,这既带来梯度相关问题,也阻止了(沿时间维的)并行训练。Linear RNN 通过移除(对隐藏状态路径的)非线性来缓解上述问题:部分变体将循环变换限制为逐元素运算以提升效率,另一些则保留结构化或对角化矩阵。
典型的Linear RNN:
如此非线性不再涉及,允许了并行化训练。
HGRN引入:1. 可训练的遗忘门下界;2. 复数隐藏态与复数递归;引入了多种复杂机制提高其表达能力。RWKV4采用了相似的方法,但引入了按通道的指数衰减和token shift进行融合输入。上面的架构设计基本使用维向量作为记忆,而现在的方法逐渐开始采用作为记忆,扩展了记忆容量。
xLSTM以上面提到的的记忆扩展传统LSTM:
HGRN2将记忆更新改为上式,同样扩展其记忆。RWKV6将原来的替换为,获得了多头的矩阵记忆,并引入动态递归:之前的按通道的衰减改为数据依赖的、时变的衰减,实现依赖于LoRA对学习到的base衰减向量进行增广。
至此,Linear RNN与Linear Attention在机翼结构上逐渐趋同,二者都可由向量外积构造矩阵记忆。RWKV7进一步引入基于广义delta规则的动态状态烟花,在推理时对多头矩阵态进行测试时梯度下降式的更新,获得一种在线的、上下文自适应能力。
总的来看,Linear RNN 的初衷是为并行训练优化隐藏态更新;其递归表述已与 Linear Attention 十分接近。尽管二者出发点不同,但正逐步收敛到结构上相似的设计,主要差异体现在记号与具体架构选择上。
2.3. State Space Model
SSM是控制系统中刻画随时间演化的动态系统的经典数学框架。
From Hippo Theory to Continuous-Time SSM
依据Legendre-RNN与HiPPO理论:给定输入函数,一组正交多项式基满足:
以及一个内积概率测度。由此可以延时间维度,将投影到多项式基上:
亦可视为带核函数的谱变换:
根据Time-SMM,通过调整和,可以得到各种不同的积分变换。当取闭式、递推的正交基时,收集各阶系数可以得到一组连续ODE,可导出LSSL、S4等采用的时不变连续时间SSM:
亦可视为一种参数化映射:将输入映射到维潜空间并投影到输出。其中常被视作一种残差连接,实践中亦可省略。
Discretization
由于实践中基本是离散序列,还需要对上面的连续时间参数在步长下离散化为。S4采用:
后续Mamba发现,采用混合离散化更加紧凑高效:
Diagonal SSMs
早期如 S4、LSSL 借助 HiPPO 初始化;但直接递推 SSM kernel 计算量可观。若可对角化,则仅需指数运算对角元。S4用“对角+低秩”结构初始化;DSS将其表为负对角(HiPPO导出的实斜对称矩阵可以做共轭对角化得到一复对角矩阵,过程);S4D进一步经验化为实对角矩阵,并用左半平面控制保证对角元一定全部为负数。H3采用两层SSM:第一层用shift矩阵初始化,第二层用点积求对角参数,从而实现token shift、增强recall。StableSSM、Hipo-PTD探讨更稳定的初始化。形式化地,上面的递推可以写作:
Time-variant (selective) SSM
基于 HiPPO 的初始化虽理论稳健,但系统动力学各时刻相同 ,难以像注意力那样有选择地关注关键信息,表达力受限。
Mamba直接用线性投影从数据中生成SSM参数,抛弃HiPPO初始化,并且将计算化为加速计算。mamba-2进一步将状态矩阵简化为标量,提出chunkwise的硬件友好算法。
近期,收到闭环控制启发,Comba对递归序列建模提出两项改进:
- 用标量+Low Rank矩阵代替Mamba-2的纯粹标量,并以delta rule进行更新,从而提升表达力,本身也形成一种householder变换,引入了监督式的记忆管理;
- 在输出端引入输出校正:以一个可学习的标量连接query & key,保证value的写入是高保真的、并且能够通过query准确地读出。
2.4. Test-Time-Training RNN
尽管Comba、DeltaNet、RWKV7等也可以从SGD角度看作近似的TTT,但是TTT这样的工作给出了更加直接的表达,将模型的状态矩阵看成某种fast weight,并且通过一个可学习的优化器在推理的过程中进行更新。由此,模型不再受限于固定的线性/双线性 kernel,而可借助更高级的优化算法获得更强表达力。
形式上,一般写作一种在线学习的范式:
最初的TTT仍采用基于SGD的更新,deep state采用两层MLP,后续工作一般沿用。Titans引入了一阶动量,可以控制瞬时”惊奇“与长i去记忆;Lattice将信息压缩到有限数量的memory slots中,并且只用与当前状态正交的信息进行更新,从而值写入新的、非荣誉的数据,降低记忆的干扰。Miras设计一种统一的框架,包括:(1)关联记忆结构,(2)注意偏置目标,(3)保留门,(4)记忆学习算法。Atlas采用高阶特征映射扩展记忆容量,提出采用Omega规则与Muon优化器。LaCT进一步以点积替代损失并用large chunk的梯度下降以提升计算效率。

2.5. Unified Linear Sequence Modeling
本文对上面提出的Linear Attention,Linear RNN,SSM和TTT进行一个合并的视角进行整合,聚焦它们的记忆更i性能规则与优化策略。
2.5.1. A Memory Perspective
采用Comba的概念,Linear是指:相对于Key-Value Associative Memory,动力学是线性的。
- Linear Update Rule
与会显式保留全部上下文到 KV cache 的自回归 Transformer不同,Linear RNN 将更高层表征压缩 到定长隐藏状态,以利泛化。从形而上的角度看,这一过渡可视为从“传导式注意力(conductive)”到“归纳式注意力(inductive)”的转变呼应“压缩即智能 ”的观点。
在结构上,它们与能量-基模型(如 Hopfield 网络)及采用 Hebbian 学习的神经系统存在相似性。早期如 Linformer、S4、RetNe 缺乏充分的、数据驱动的记忆管理,性能落后于 softmax 注意力模型。后续以 Mamba、GLA为代表的工作通过投影式门控等动态机制显著改善。
形式化地,这类架构可视为带 KV 关联记忆的线性寄存器系统 :通过可学习 的遗忘门与输入门(记)写入,再以 query 检索读取:
- Bilinear Update Rule
在神经记忆系统视角下,如何有效调节 记忆依然关键。不同于依赖强化式更新的 Hebbian 原则,Delta 学习规则 强调对记忆轨迹的监督式 控制。此类系统对“状态”与“输入”各自线性 ,但由于存在乘积项(如)整体呈非线性;可将其视为一类保持可控性 的特殊非线性系统。一般形式可写为:
其中的双线性项(记作)在 Comba、(Gated)-DeltaNet、RWKV7等模型中出现。或者,在确保状态转移矩阵谱半径小于 1 的约束下,也可采用类似 Lattice中 与 的交互 。在双线性更新下,这些模型可chunkwise parallel在 GPU 上高效计算。
- Nonlinear Update Rule
除早期 LSTM、GRU外,2.4 中的一系列方法(如 TTT)可看作现代非线性 RNN 。它们对“状态记忆”施加非线性运算(例如两层 MLP 记忆中的非线性激活),因此动力学本质上是非线性的。尽管理论表达力更强,但这类方法通常受限于块级并行 ,只能用 minibatch 梯度下降更新,硬件利用率往往很低(<5%)。一种潜在解法是参考 LaCT:采用** 大批量梯度下降,并以 滑窗注意力在批内学习信息,形成 混合式架构**。
2.5.2. An Optimizer Perspective
另一种统一视角来自“优化器 ”,最早由 TTT、Titans与 Test-time Regression提出。我们按目标函数 的不同形式进行归类。
- Local L1 Loss
如RetNet,Mamba,GLA引入的记忆门控,可以看成一种L2正则化
- Local L2 Loss
L1难以直接强制,难以实现精确的KV检索,因此采用L2 Loss:
- Multi-step L2 Loss
Delta-Product在单个时间步 内应用一系列 Householder 变换,将潜在更新视为** 结构化正交算子的组合。对应地,训练目标可被解释为一种 多步 L2**:不仅监督即时转移,也监督多步后的潜在状态。单步 L2 促使模型逼近** 简单反射**(最基础的正交变换),多步 L2 则可由反射组合逼近** 一般正交矩阵**,从而捕获更丰富的线性动力学(如旋转、置换、剪切),在诸如 S5的状态跟踪任务上显著提升表现。形式化地:
- Global L2 Loss
每次更新都考虑全局最优:
对该式给出解析解后,可用两条线性递推 进行快速计算;为进一步提效,采用共轭梯度 在输出处做校正,避免直接求逆。
2.6. Linearization
上面提到的各种方法虽然有各种好处,但是从0开始做训练所需要的算力和资金实在是太多了,因此,Linearization 成为更理想的选择:以更低的训练/微调成本,将** 预训练的 Transformer** 转换为** 线性递归结构**,并恢复(尽量保持)原模型在自然语言理解与生成上的能力。
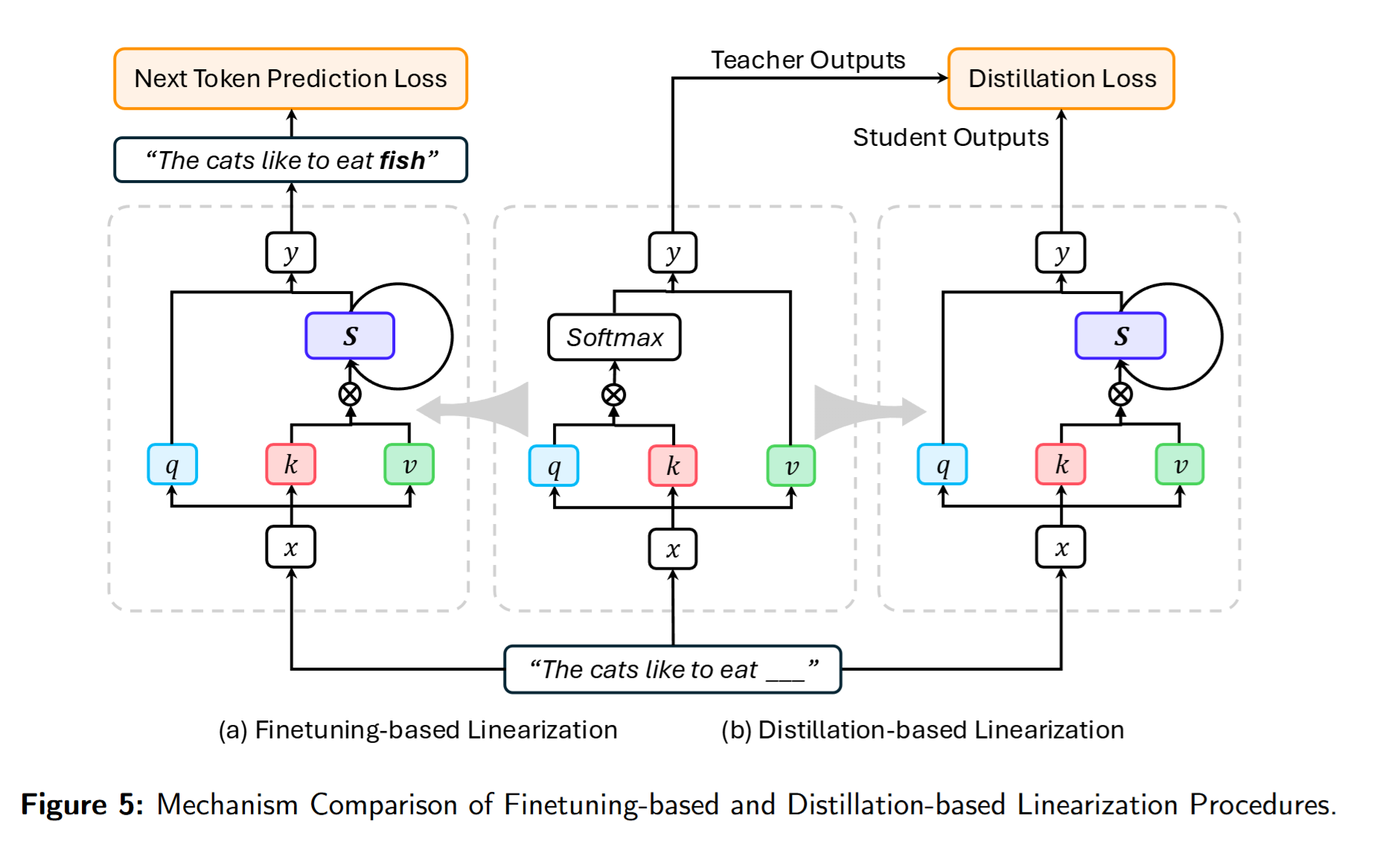
Finetuning-based Linearization
这一路线直接把预训练 Transformer 中的 softmax attention 替换为线性序列建模 ,随后微调以适配新架构,无需借助外部教师模型。Transformer-to-RNN(T2R) 采用“替换-再微调 ”流程,使转换后的 RNN 具备线性时间与常数内存;Mao 系统考察多种更新规则,将自回归 Transformer 微调为 RNN,并提出无需 feature map 的逐元素衰减快权 更新;DiJiang 以加权准蒙特卡洛 实现线性注意力采样,并基于 DCT 核化 大幅降低把 vanilla Transformer 线性化的训练成本;SUPRA 用 GroupNorm 替换 softmax,并以小型 MLP 做 Q/K 的特征映射,将大规模预训练 Transformer 转为 RNN;** Liger则完全 复用原权重、 不引入新可学习参数**,把 Transformer-based LLM 线性化为** 门控递归结构**,从而将线性化简化为** 单阶段端到端训练**,无需蒸馏,显著降低成本。
Distillation-based Linearization
主要是各种蒸馏,将softmax-attention Transformer蒸馏到Linear Attention上。
Linearization in the Era of RL Scaling
随着类 R1 的大推理模型在推理任务上展现优势,一个重要问题浮现:能否通过** 加长 CoT** 的测试时计算来提升** 线性递归模型的推理能力?一个有前景的方向是:利用现有 基于 Transformer 的推理模型**,获得** 线性化 LLM**——既保持强推理,又享受线性序列建模的效率。实践上常采用“** 架构线性化 → SFT → RL**”的流程以增强测试时推理。** Daniele 等从大规模 LLaMA 蒸馏出 纯 Mamba与 混合 Mamba**,考察其测试时可扩展推理;** M1则在 Mamba 架构上构建 混合式大推理模型**,通过对线性化 Transformer 的蒸馏与微调实现。结果表明:** 线性递归架构在支撑 高效、可扩展推理**方面潜力可观。
2.7. Hardware-efficient Implementation
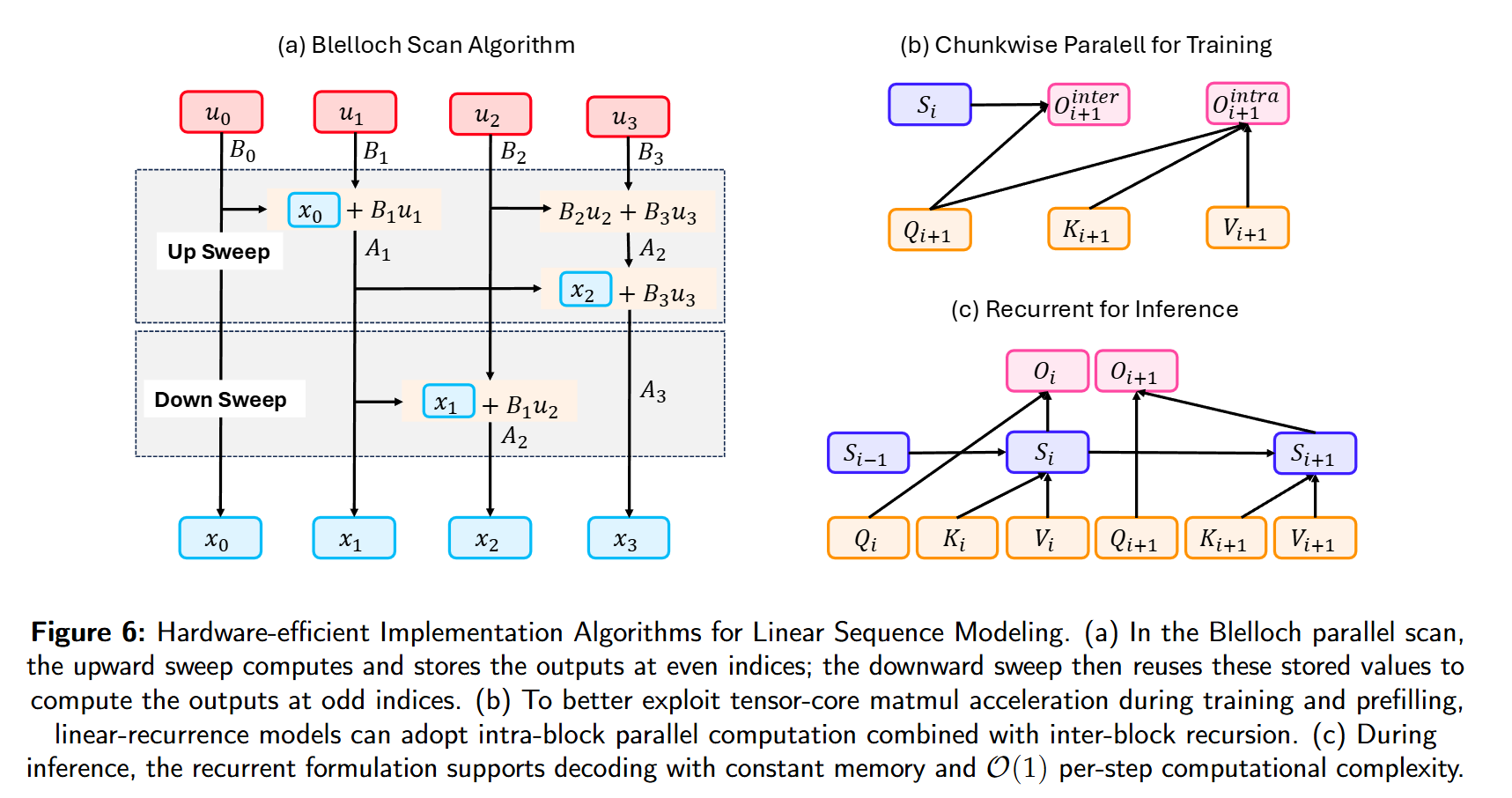
Fast Recurrent
SSM可以改写成卷积,Mamba采用Blelloch Scan算法加速递归。
chunk-wise Parallel
当前硬件对矩阵乘算子的极致优化,使得Linear Attention在短序列上的吞吐有可能低于Transformer。受Flash Attention启发的近期方法,引入了inter-chunk recurrence + intra-chunk parallelism,充分提取计算效率:
开源框架集中在Flash Linear Attention这个库,给各种Linear Attention提供了Triton Kernel。
3. Sparse Sequence Modeling
稀疏序列建模 旨在通过将元素间的交互限制在策略性选择 的子集上来提升处理序列数据的效率。一个典型例子是 Transformer 中的稀疏注意力 :在尽量保持建模性能的同时,缓解传统 full attention 的计算瓶颈。
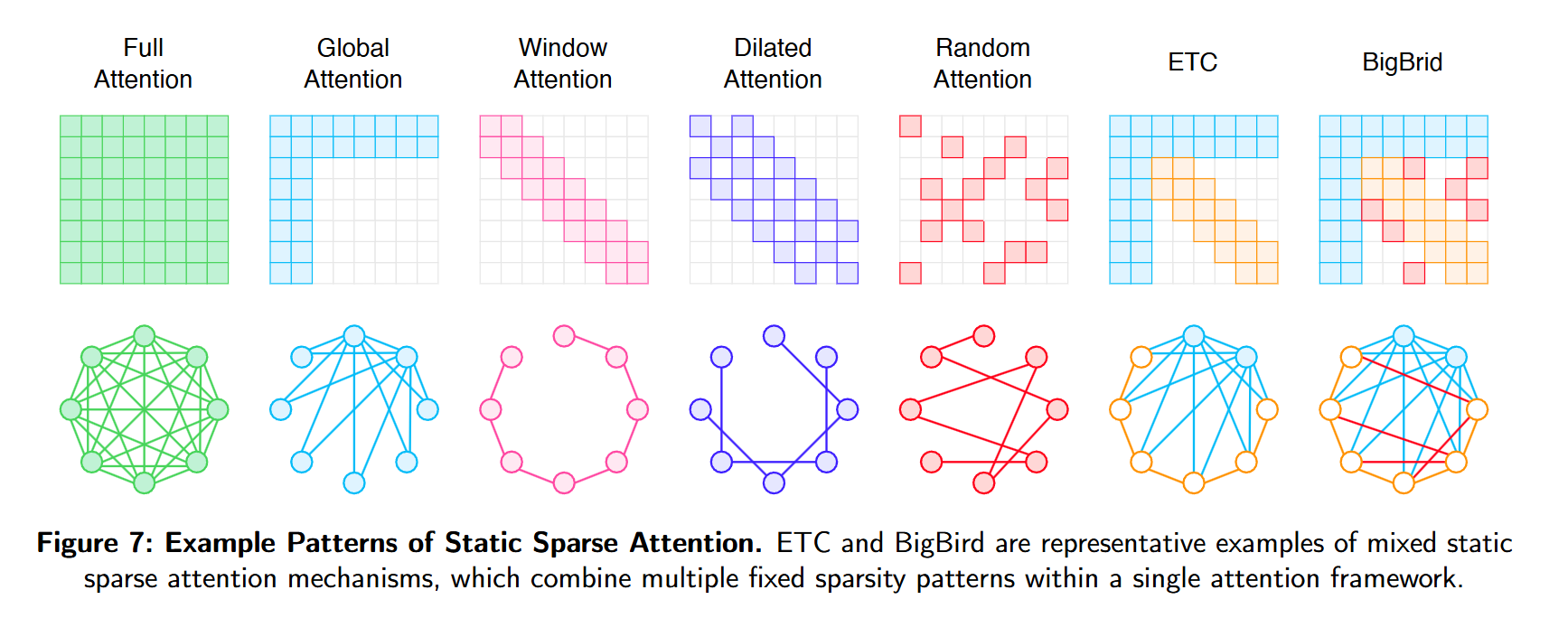
3.1. Static Sparse Attention
常见的模式包括:全局、滑窗、stride、dilated、randome、blockwise,凭借强归纳bias与可扩展性,在训练前涉及、推理时保持不变,从而保证推理的高效性。
早期的 Sparse Transformer首次系统提出这一思路:使用固定的步进与膨胀注意力,使每个 token 以确定性方式同时连接近邻与远端,在近线性计算成本下仍能捕获长程依赖,为后续稀疏模型奠定基础。
在此之上,Star-Transformer采用“径向拓扑”:中央中继节点连接所有 token,外围 token 则在环上进行局部连接;该结构以线性时间维持全局通信,在需要全局结构的任务上表现优良,结构简单高效。
BlockBERT将 BERT 适配到更长序列:将输入划分为定长小块,块内使用稠密注意力、块间仅通过选定关键 token稀疏通信,从而在降低显存开销的同时实现长文档建模,适用于文档分类与问答等任务。 Longformer将滑窗注意力与少量全局 token结合:滑窗处理局部,全局 token 负责跨远距的信息流通。在线性复杂度下,该混合设计在摘要与长上下文 QA 等任务上效果显著。
GMAT注入全局记忆 token 作为信息枢纽,促成长序列不同段落间的交互,且与 Longformer、Sparse Transformer 等结构兼容,改进了长上下文理解表现。
ETC将 token 划分为本地与全局两路;本地路采用滑窗,全局路可关注全序列,并引入段感知注意力与相对位置编码以提升文档级理解。
BigBird将静态稀疏模式泛化为由本地、全局与随机连接构成的小世界稀疏图;该设计保证任意 token 间存在短路径连通,并在理论上具备通用逼近性质;在 encoder-only 与 encoder-decoder 设定下均可有效扩展至长序列,覆盖 NLP 与生物信息学任务。
LongT5 在 T5 基础上通过瞬时全局注意力扩展长文本生成:将局部上下文汇总为临时全局 token,逐层自适应聚合信息,使 encoder–decoder 架构无需依赖稠密注意力即可扩展到更长输入,在摘要与长问答中取得改进。
LongNet提出指数级膨胀注意力:每层的注意跨度按 2 的幂扩张,形成层级式方案,以对数复杂度高效建模最高至十亿 token的序列。
3.2. Dynamic Sparse Attention
与静态稀疏不同,动态稀疏注意力 会依据输入内容自适应 地决定稀疏模式。其目标是在接近 full attention 表达力 的同时,将计算聚焦到动态选取 的少量交互上,从而在长上下文下保留与任务相关的信息,同时最小化计算开销。其演进大致经历了从启发式分组 到更可学习的检索系统 。
早期方法(Transformer-XL,Compressive Transformer,Adaptive Attention Span,Reformer,…)通过分组/聚类 语义相近的 token 来收缩注意力范围。随后,这些方法被Attention with Bounded-Memory Control统一:将上下文视作固定大小 的记忆,并展示诸多先前方法皆是“记忆管理”的特例。其关键创新 ABC-MLP 超越固定启发式,使用** 可学习、具上下文感知的控制器管理记忆,在 效率–精度**间取得更佳折中。
另一条路径不是压缩即时上下文 ,而是引入外部记忆 并通过检索 实现稀疏:Memorizing Transformers 使用 kNN 索引检索相关的过去表示,实现对长期记忆的稀疏访问;** CoLT5提出 条件路由**:轻量路由器挑选一小部分“重要”token 走** 全局注意力**,大多数 token 仅进行低成本本地注意力;** Unlimiformer将此思路用于 交叉注意力**,让预训练模型通过从索引检索相关 keys 来关注** 极长输入**,且** 无需改动权重**。之后,研究重点转向** 显式学习路由与门控**,直接在注意力矩阵上进行剪枝。
最新进展不仅追求理论 效率,更强调工程落地 的真实加速与结构专用化。Native Sparse Attention(NSA) 面向该目标,采用硬件对齐 的分层策略:粗粒度token 压缩 提供全局上下文,细粒度选择 保障局部精确,从而获得显著的实际速度提升 。与此同时,Mixture-of-Sparse-Attention(MoSA) 将流行的 MoE 范式迁移到动态稀疏注意力:把每个** 注意力头视作一个“ expert**”,动态选择少量 token;将节省下的算力** 回投用于训练 更多、且更专长的头,在 相同 FLOPs 预算**下取得更优性能。
3.3. Training-free Sparse Attention
虽然许多稀疏注意力方法面向训练 阶段设计,但也有大量工作专注于推理加速 。推理通常包含两个相对独立的阶段:计算最密集的 prefill ,以及受内存带宽 限制的 decoding 。
Accelerating Prefill Stage
LongLoRA通过Shifted Sparse Attention,只在局部分组内计算注意力,并平移分组让信息在全局流动。MInference观察到,注意力经常呈现少数特别的形状(对角,纵条,…),为这些固定的模式提供了专门的Kernel;Mixture of Attention通过基于梯度的分析为每个head分配不同的sliding window模式,形成了固定的稀疏掩码。
更自适应的做法是在输入相关的基础上动态学习稀疏模式。SeerAttention 在各注意力层增设轻量门控模块;经短暂的自蒸馏后,门控可预测对当前输入最重要的注意力块,在线生成掩码,按需剪枝无关计算,在保持精度的同时显著加速 prefill。其后续 SeerAttention-R在“自蒸馏稀疏”上加入适配自回归解码的关键改动:移除序列级 query 池化,并采用 GQA 风格的共享稀疏模式以提升硬件效率;只需在注意力层插入可学习门控,即可作用于任何预训练 Transformer,无需改动原模型权重。
Accelerating Decode Stage
自回归解码的主要瓶颈是每步加载不断增长的 KV cache 的带宽。研究重点转向裁剪 KV cache,仅保留关键信息。
SpAtten 采用级联 token/头剪枝 (Top-K 引擎逐层移除不重要成分)与渐进式量化 (按需加载低比特)协同减少内存与计算,在不损精度的情况下加速长上下文推理。另一种简单而有效的启发式是利用注意力汇(attention sink)现象 :StreamingLLM 发现初始 tokens 在生成过程中持续获得高关注、对稳定性至关重要;因此仅缓存这些** 汇聚 tokens与一段 最近窗口即可在固定小缓存下处理无限长流。其他方法采用 动态驱逐策略: TOVA持续驱逐注意力分数最低的 token; H2O将驱逐表述为 次模优化**,保留对注意力输出影响最大的“** 重击手**”tokens。** RetrievalAttention在 CPU 端为 KV cache 建立 ** ANN 索引,生成时用** 注意力感知**向量检索取回最相关的一小撮 KV 对,避免 full attention 的计算与访存成本。
更多结构化方案在更粗粒度上引入稀疏:FastGen为每个头做画像(如局部/全局),并施加定制驱逐策略;对局部头更激进地压缩 KV。查询感知方法会在线选择相关上下文块:Quest将 KV cache 划分为页,用轻量打分只取与当前 query 最相关的页;LongHeads让每个头独立选择并关注少量上下文块,在序列上并行检索相关信息。DuoAttention将头分为检索头(长程)与流式头(局部):仅检索头维持完整 KV,流式头用滑窗,从而降内存与延迟;其识别检索头的方法是数据驱动的。ShadowKV将目标大模型的 KV cache 下放到 CPU,同时让一个更小的草稿模型在 GPU 上维持紧凑“影子 KV”;通过推测解码生成候选,目标模型仅从 CPU 拉取必要 KV 做校验,最小化慢内存访问。LServe提出统一的稀疏注意力服务方案:融合块级跳过与查询驱动 KV 剪枝,只保留相关“内存页”,并将一半注意力头改为轻量流式头,同时加速 prefill 与 decoding 而保持精度。PQCache以Product Quantization压缩 KV,将向量维度分组量化到低比特,并引入轻量、可学习“反量化助手”在推理时重建高保真向量。XAttention以反对角线和作为轻量块重要性度量,实现高精度、低开销的块稀疏剪枝,长上下文基准上可达加速并保持精度。
3.4. Hardware-efficient Implementation
FlashAttention-1引入了块状稀疏,通过结构化稀疏进一步降低了访存:
其中是一个块掩码,具体为:
经验上,块稀疏 FlashAttention 相比稠密版本可达 加速,并把序列长度扩展至 64K。FlashAttention-2将其扩展到局部、膨胀与一般块稀疏等结构化模式。
近期 NSA 将三种稀疏机制整合,并以三项策略提升硬件效率。(1)Group-Centric Data Loading :在每个内环中,按 GQA 分组 共同加载该组的全部与对应的稀疏索引;(2)Shared KV Fetching:以连续块的形式顺序加载、到SRAM;(3)Outer Loop on Grid:利用各块的一致inner for loop length,借助triton的调度进行输出。
进一步地,MoBA 以块级可变长度 计算实现动态稀疏 :把序列划分为定长块,并用段长度张量 编码块的选择,将不规则稀疏转化为硬件友好的访问模式;在保留 FlashAttention 优化收益的同时支持自适应路由,对 1000 万 token 、95% 稀疏 场景可达 16× 加速。
4. Efficient Full Attention
4.1. IO-Aware Attention
FlashAttention系列Kernel的核心在于,在保证Softmax Attention的前提下,几乎消除了全部不必要的内存留恋给,在现代GPU上取得了显著的加速。
给定,标准的计算流程:
- 分块读入,计算,将写回HBM;
- 读出,计算,写回;
- 读出,计算,写回。
上面这种三段读出的方法,主要问题包括:
- 和在较大的时候难以一起读入SRAM做计算
- HBM访问更多,上面三个阶段中分别涉及到的内存读写有:
- 读,写
- 读,写
- 读,写
4.1.1. FlashAttention-1
FlashAttention-1 通过优化全局内存 ↔ 片上内存 的数据搬运显著降低内存流量与占用,从而在不做近似 的前提下加速计算并支持更长序列。其做法是将序列分成更小的 query 与 key-value tiles 分块处理:在一次装入共享内存后,用专用硬件完成块间矩阵乘;对每个 tile 执行** 分块 softmax**,维护** 运行最大值与累积和**以保证数值稳定;最终累加按块概率得到输出。
Main Contributions:
- Online Softmax
- Fused Attention,减少了显式地的往返
- Backward复算,用保存的归一化统计重算注意力,以算代存节省了现存。
4.1.2. FlashAttention-2
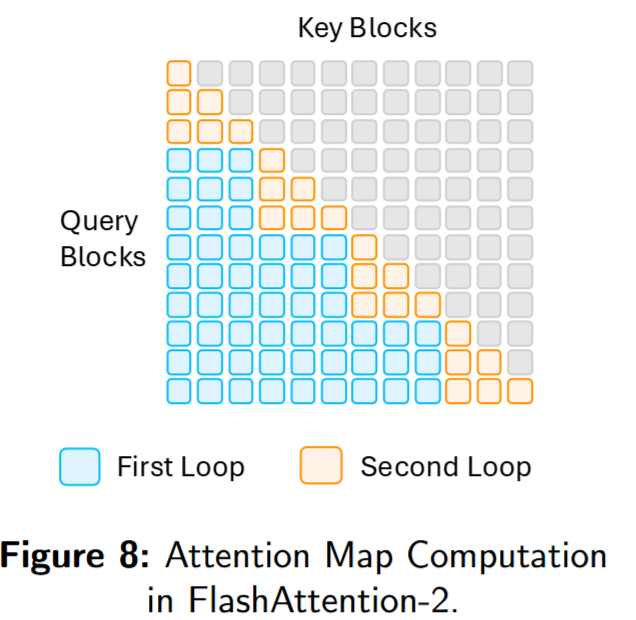
尽管 FlashAttention-1 明显快于标准实现,但其前向仍未吃满设备峰值吞吐,后向更低。瓶颈来自线程块/warp 的不理想分工 与较多非 matmul 操作 ,导致占用率不足与不必要的访存。FlashAttention-2 从以下方面优化:
- 更多matmul:将后续算子融合到Tensor core Pipeline中,减少softmax计算的caching开销;
- Query-Outer, KV-Inner,更好的计算pipeline
- Row-wise computation,对于每一个query,与同一行的所有做计算得到输出,这样形成2-loop的形式:
4.1.3. FlashAttention-3
FlashAttention-3 面向 ** Hopper** 架构,整合两大硬件新特性:** TMA(Tensor Memory Accelerator)** 与 ** WGMMA** 指令。通过** warp 级异步**访存与更高效的矩阵乘,加速注意力关键路径。
- Producer–Consumer 异步 :将 warp 组分为生产者 (用 TMA 预取数据)与消费者 (负责 matmul 与 softmax),形成两级流水并重叠 搬运与计算,减少空转、提升吞吐。
- Matmul+Softmax 交织 :采用双缓冲 ,在计算下一块分数(WGMMA)时并行完成上一块的 softmax,保持计算单元长期满载 、降低等待。
- 块级 FP8 + 非一致处理 :GEMM 与 softmax 全用 FP8 ,并为每块选择独立缩放 以抑制误差累积,相比传统 FP8 核心显著降低数值误差,同时保有低精度的带宽/算力红利。
4.2. Grouped Attention
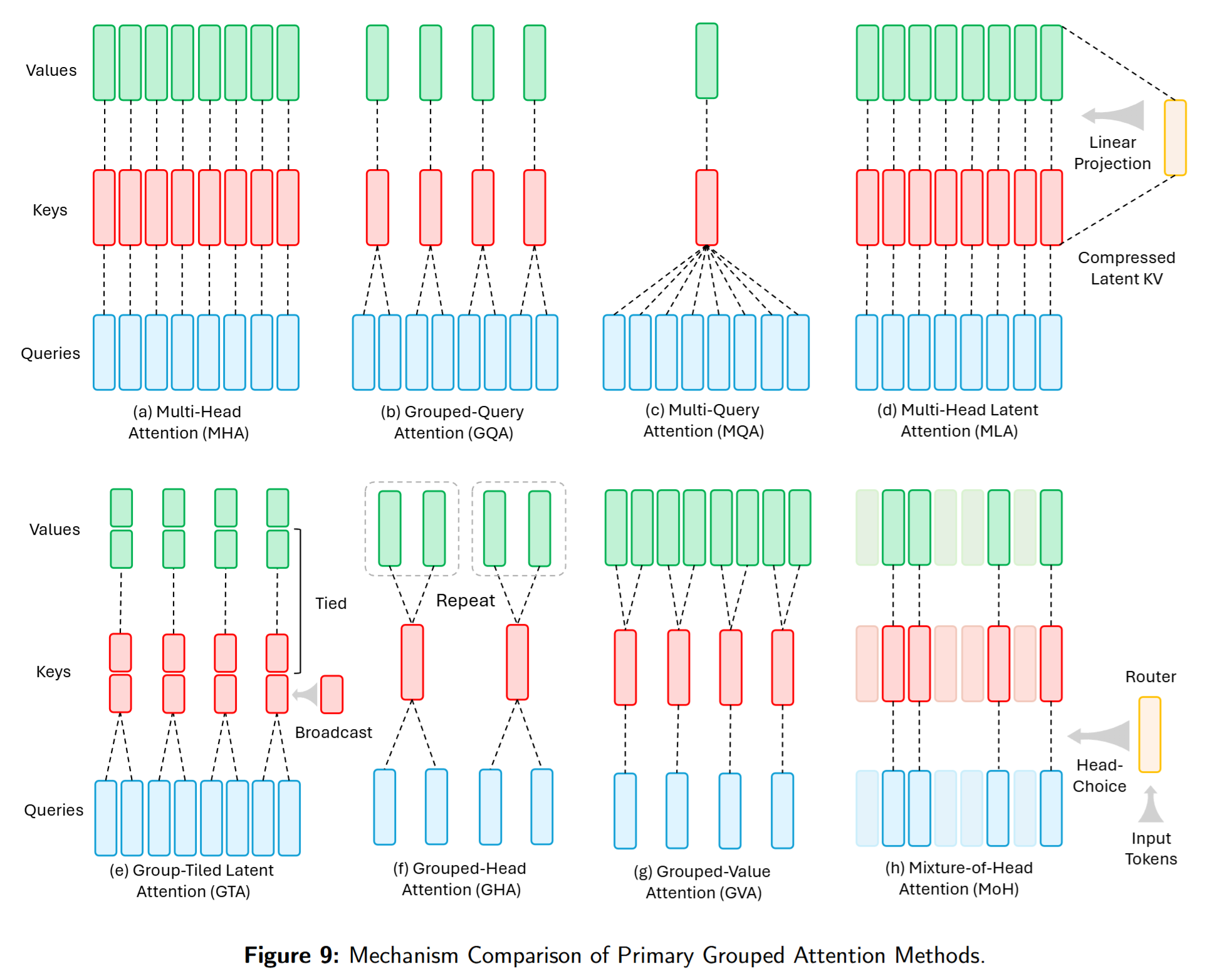
Grouped Attention(含 MQA、GQA、MLA)已在 LLM 训练中广泛采用。其核心是在推理期缩小 KV cache,以更高的内存效率维持性能。
- MQA:多路 query 共享单个K/V 头,显著减小 KV cache、提升自回归解码速度,但有时会带来质量损失。
- GQA:在 MHA 与 MQA 之间取中值:将 query 头分组,每组共享一个K/V 头;质量接近 MHA、速度接近 MQA。其提出的 uptraining 能以小比例原始预训练算力将 MHA 模型转为 GQA/MQA。
- MLA(DeepSeek-V2/V3):将 KV cache 压缩到低秩潜在向量,进一步小于 MQA 的存储;其设计将位置信息与压缩后的 K/V解耦,使得更激进的压缩成为可能。
- GTA / GLA:硬件/内存友好的注意力。GTA 将 KKK 与 VVV 绑定为共享投影并在小组内复用,KV cache 约减半、算强比提升,并对 RoPE 做了精巧处理(非 RoPE 部分用绑定态,小头单独算 RoPE 分量并广播)。GLA 则改进 MLA 的并行性:对潜在 KV 进行分片并分配给不同 query 组本地计算、再合并,避免跨卡重复缓存,在分布式/负载不均时更高效;其定制内核在推测解码上可达对 FlashMLA 2× 的加速。
4.3. Mixture of Attention
将多种注意力策略混合 到同一层的想法始于 MoA :为不同头/层分配异构稀疏模式 ,自动从模式池中选择 head-wise 稀疏,从而在提升吞吐/降低内存的同时扩大有效上下文 。
- SwitchHead 把注意力头视作“专家”,引入路由仅激活子集,注意力计算最高减至 1/8 而不降性能。
- MoH 用软选择 :每个 token 对各头做加权组合,实现部分剪枝 而保持/提升准确度。
- LLaMA-MoE v2 将理念扩展至完整 LLM:对注意力与 FFN 都做结构化专家稀疏,达到与致密 LLaMA 相当的多域性能。
- MoBA 在块级 进行路由:每个 token chunk 动态选择 full 或 sparse attention,不依赖预定义模式,按任务需求自适应分配算力,显著改进长上下文。
- MoM 将 MoE 思想从“注意力层”推广到记忆 :以多路稀疏激活的 memory slots 替代单一共享状态,提升长程召回、降低干扰。
- MoSA 将 MoE 路由细化到token 级 :各头动态选择 top-k 相关 token,在等 FLOPs 下优于致密注意力并显著节省内存。
总体趋势:从固定稀疏 走向可学习路由 ,粒度自 head 逐步细化到 block / memory / token,使注意力更可扩展、高效、任务自适应 。
4.4. Quantized Attention
为在低精度量化 下平衡效率与精度,近年出现了大量硬件平台与量化技术,面向注意力算子也有系统探索。
-
PTQ(后训练量化) :无需再训练,直接将注意力算子转为低比特。
-
SageAttention :将 量化到 INT8 (对异常值做 per-channel smoothing),而 的matmul仍用 FP16 ;首个 matmul 用 INT8、第二个用 FP16,在误差可忽略下将 matmul 速度翻倍 ;其 Triton 内核还融合 RoPE 与量化 。
-
INT-FlashAttention :提供与 FlashAttention 兼容的 INT8 内核:对及 softmax 输入全部做 8bit,整条注意力链在 INT8 中完成,较 FP16 更快、量化误差更小、质量下降轻微。
-
Q-BERT :Hessian 分析下的超低比特量化,均匀 4bit 在 SQuAD 上仅降 0.5% ,而 naive 量化超 11% 。
→ 结论:PTQ 往往量化主干 matmul,并配合缩放/平滑以保真,实现即插即用 的 INT8 推理。
-
-
QAT(量化感知训练) :在训练中嵌入低精度,让模型学会适应。
- Q8BERT :在 8bit (权重与激活)约束下微调,压缩 4× 几乎无损。
- I-BERT :连 GELU/softmax 都以** 整数近似训练,使 RoBERTa 端到端 ** INT8、精度接近 FP16。
- FullyQT :训练时量化所有 matmul(含 softmax 输入/输出),指数近似以** 位移实现,表明 8bit Transformer 可与 FP32 BLEU ** 持平。
-
混合精度 :在注意力内部混用精度以取长补短。
- SageAttention 的范式即:用 INT8 、而用 FP16 。
- TurboAttention / FlashQ :按头独立量化(per-head scale),大多数 matmul 用低精度,同时保留足够精度以压缩 KV。
- 也可按层/按 token 选择:部分层 INT8,softmax 归一化等敏感算子保持 FP16。现代 GPU 的 INT8/FP16 Tensor Cores 可并行,确保吞吐与精度兼得。
-
INT8 融合内核 :除算法外,工程上也出现专用融合核。
- INT-FlashAttention :单个 CUDA 核心接受 INT8 的 与 softmax 输入,在 8bit 中完成所有 matmul/softmax,输出 FP16/FP32。
- SageAttention 的 Triton 内核将量化与 FlashAttention-style 平铺融合,充分利用 INT8 TensorCore MMA。
- HACK 的 prefill 核心:在线量化 并直接送入注意力,不做额外量化/反量化往返。
-
超低比特(<4bit) :
- SageAttention-2 :warp-wise INT4 做,** FP8** 做,并对做 outlier smoothing。
- SageAttention-3 :两次 matmul 都用 FP4 microscaling (按块 FP4 + 每块尺度 + per-token 归一化),将误差控住同时可达 5× 加速。
- BitDistiller :面向亚 4bit 的 QAT 框架,采用非对称量化 与自蒸馏 KL ,使 3/2bit 模型逼近全精度。
- 早期 Q-BERT 也表明:若对层分配 2–3bit(部分层更高),仍可获得可接受精度(如均匀 2bit 在 SQuAD 仍保留 ** 70%,而 naive 2bit 仅 ** 5%)。
5. Sparse Mixture of Experts
稀疏激活的 Mixture-of-Experts(MoE) 能在不增加(或小幅增加)计算量的前提下放大模型容量。与传统集成不同,MoE 由gate与多名experts构成:gate 作为路由器,按输入 token 自适应选择更相关的专家,从而带来更强的鲁棒性。此外,gate 的路由偏好会诱导专家的专长化,并可用于数据集层面的表征。借由稀疏激活,MoE 可在容量上显著扩展并收获更好的任务表现,因而已在众多现有 LLM 中得到广泛应用。
5.1. Routing Mechanisms
对于一批输入,gate函数为每个token 计算派发到各个专家的概率:
最常见的是线性投影+softmax,模型低精度推理的时候router一般需要在FP32下进行计算。变体包括:1. 带非线性激活的FFN;2. sigmoid、余弦相似度取代softmax,缓解表征塌缩和专家竞争。
得到概率之后,常见的做法是直接取Top-K:
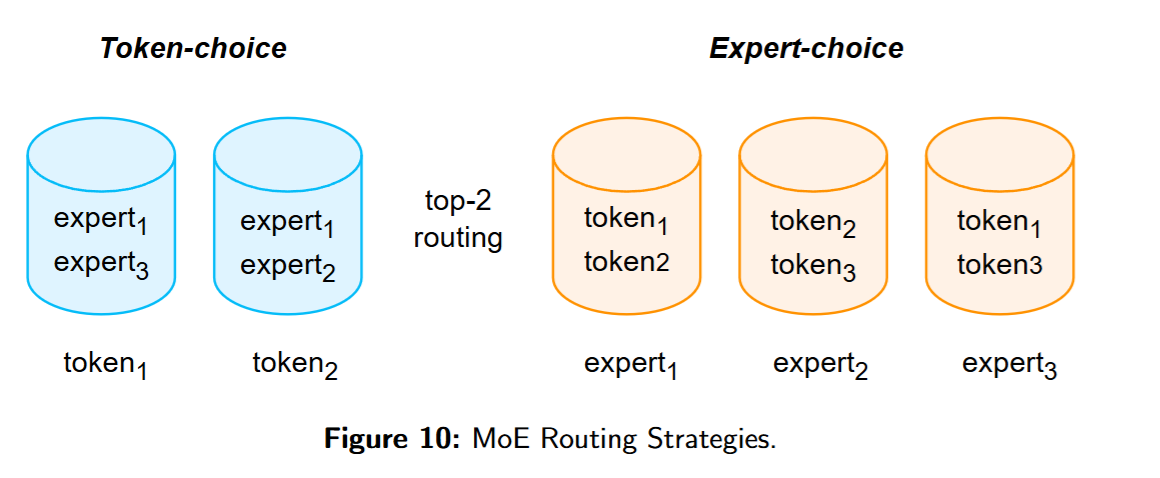
Routing Strategies
现代 LLM 多采用token-choice :如图 10 所示,每个 token 选择其对应的k个专家进行计算。其主要隐患是负载不均 :部分专家被过度选中、部分则稀疏使用,既浪费容量又可能因专家容量上限导致 token 被丢弃。
除 token-choice 外,还可采用 expert-choice:令每个专家在一批 token 中选择其 Top-k tokens。Expert-choice只需把 中 softmax 的维度从 N 改为 T。在上式中则对每个专家选 k 个 token,从而在训练时获得完美负载均衡;该法在 encoder 型模型(如 T5 encoder、ViT)上有效。但对自回归语言建模,专家在每步无法看到整段序列,可能一次接收过多 token 以至于占满容量、挤占未来 token 的空间;因此在 LLM 中使用 expert-choice 时往往需要配套容量估计器或损失约束以预留未来容量。
Adaptive Top-K Routing
近年的一个方向是动态路由:按任务难度/算力需求自适应决定被选专家数 k。常见三类:
- differentiable activation:以 ReLU、sigmoid 等替代“Top-k + softmax”。ReMoE用 ReLU 作为路由激活,激活为 0 的专家被丢弃;因路由完全可微,能随任务复杂度自适应优化。为避免从零训练时全部专家被激活,加入正则以达成目标稀疏度。BlockFFN 亦用 ReLU 以实现token 级 + chunk 级的双重稀疏目标。DynMoE将专家选择表述为多标签分类:计算 token 与各专家表征的余弦相似度,并据阈值选择专家。
- expert activation estimation:直接把 Top-k 改为动态 k。MoE-Dynamic依据置信度阈值 p 选专家:按路由概率降序加入专家,直至累计概率超过 p,从而把固定 Top-k 变为Top-p。Ada-K则训练一个分配器输出“激活专家数量”的概率分布,并从中采样最优 k。
- zero computational experts:引入零/极低计算的“占位专家”。MoE++在固定 k 下引入异构负载均衡:部分 token 被路由到“零专家”而跳过计算以提效。AdaMoE 在标准专家旁引入null experts:路由仍选固定更大的 k,但不同 token 会动态使用不同数量的“真专家”,语义更丰富的 token 使用更多真专家,次要 token 更多路由到 null 专家,从而达成自适应路由。
Load Balancing
Gate load 指路由到每个专家的 token 数。token-choice 易因偏置 gate 而失衡,造成部分专家训练不足、训练等待变长。鉴于现代 LLM 更偏好 token-choice 以适配自回归预测,实现均衡至关重要。
常见做法是在训练目标中加入辅助负载均衡损失 ,与语言建模的交叉熵相加。Shazeer 等 用 gate 重要性(路由概率)的变异系数作为辅助项;为更严格的约束,估计 gate load以兼容反传:
GShared选用一个更简单的辅助:
5.2. Expert Architectures
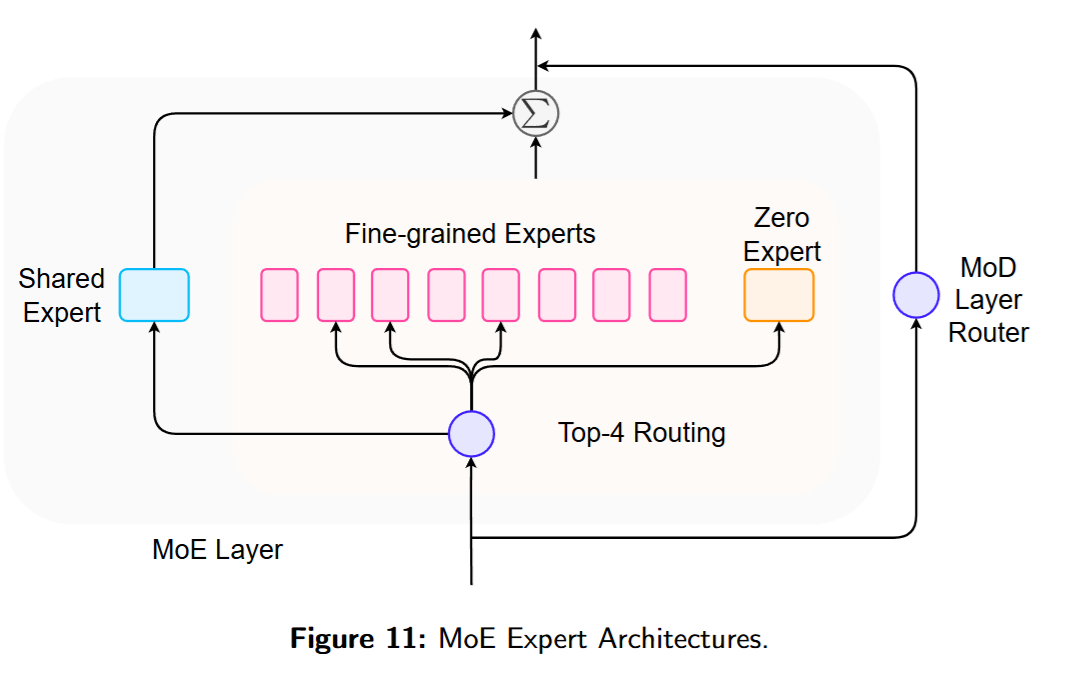
传统 MoE 在 FFN 中引入稀疏,专家一般由若干 FFN block 组成。虽然多场景下效果良好,但在效率、鲁棒性、训练稳定性上仍有提升空间。同时,预训练 MoE 中的专家会自然形成领域/模式专长,这也催生了仅微调任务相关专家的 PEFT 范式,以降低计算开销。如图 11,MoE 层中的专家形态包括:fine-grained experts、shared experts、MoD experts,以及其他异构专家(如零专家)。本节聚焦 FFN 专家。
Fine-grained Experts
用更小的专家大小换取更多的专家数量。
Shared Experts
token 总会被路由到它们。DeepSpeed-MoE通过额外线性投影 + softmax 将 shared 与常规专家的输出加权求和;Qwen2-MoE用线性投影 + sigmoid 计算 shared 的贡献权重并与常规专家输出相加;DeepSeekMoE直接将两者输出相加而不做复杂重加权。
Mixture-of-Depths
除横向的专家并行外,还可从层的纵向视角构造专家。MoD将各层视作专家,并用路由器为每层选择 Top-k tokens,从而显著减少每层的计算量。与 LayerSkip不同,被早期层丢弃的 tokens 仍可能被后续层处理。MoD 与 MoE 正交,可结合形成 MoDE(Mixture-of-Depths-and-Experts)。
Other Special Experts
除常规模块外,还有若干融合“稀疏 MoE”理念的变体:SoftMoE将 tokens 混入soft slots,由专家处理这些 slots,再用输出投影还原 token 表征;MoE++ 在 MoE 中引入 zero/copy/constant 等专家,以自适应控制 Top-k 路由与总体算量;ModuleFormer通过计划式扩容添加新专家且不遗失原有知识;受 PEFT 启发,还可将专家实现为 LoRA 权重以得轻量设计;并可借由专门的专家检索策略将专家数扩展到 百万级。
5.3. MoE Conversion
和Linear Attention之前遇到的问题一样,直接训练一个MoE的模型的开销太大了。因此,转换的方法同样有必要。一般而言转换的方法可以分为:裁剪、复制、合并三种。
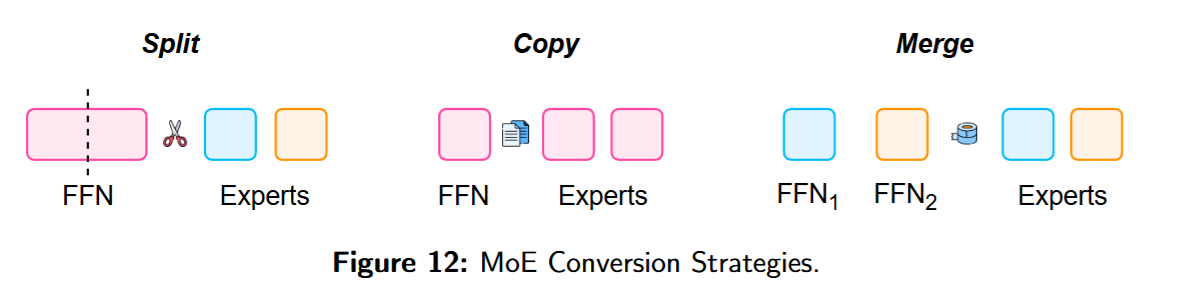
Dense to MoE
MoEBERT 通过拆分基于 encoder 的 BERT 系列来构建 MoE,并提出用重要性分数引导模型适配。MoEfication基于共激活图拆分 T5,得到的 MoE 性能与原 T5 非常接近。LLaMA-MoE则对 LLaMA的 FFN 进行划分,并配合持续预训练与监督微调构建 MoE。除了把致密 FFN 拆成稀疏专家,Komatsuzaki 等提出通过复制现有 FFN并为每层 MoE 初始化新 gate 来扩容量,即 sparse upcycling。面向“纵向”转换,DLO通过扩展层来构建 MoD 专家;MoDification则将致密模型中的若干层转换为 MoD 风格专家:用带阈值 p 的 gate,让超过预设阈值的 tokens 被该层处理。
Sparse Model Routing
除基于模块的 MoE 外,还可通过合并/聚合模型得到“类似 MoE”的结构,以便更好地理解指令并用专长专家生成响应。Branch-Train-Merge(BTM)的思路是:先用领域数据分别训练多 个专家 LM;推理时,根据输入查询的领域类别对这些专家模型进行加权平均得到一个新模型再生成输出。与“合并权重”不同,Branch-Train-Mix(BTX)直接将专家 LM 的 FFN 聚合为 MoE 层,并为每层训练一个新 gate 来动态选择专长专家。
6. Hybrid Architectures
可以看到前面的描述中,Linear Attention遇到的主要问题是精度不够,而Transformer遇到的问题是开销太大。因此,提出混合架构,高效且有效地融合“线性模型的效率”与“softmax attention 的表达力”。
现有混合架构大致分两类:
- Inter-layer Hybrid) :以分层交替的方式,在若干线性序列建模层之间周期性插入 softmax attention 层;多数层仍保持线性复杂度,同时从少量 attention 层获得高表达力。
- Intra-layer Hybrid :在同一层内部 做细粒度融合,将线性序列建模与 softmax attention 进行策略性组合。
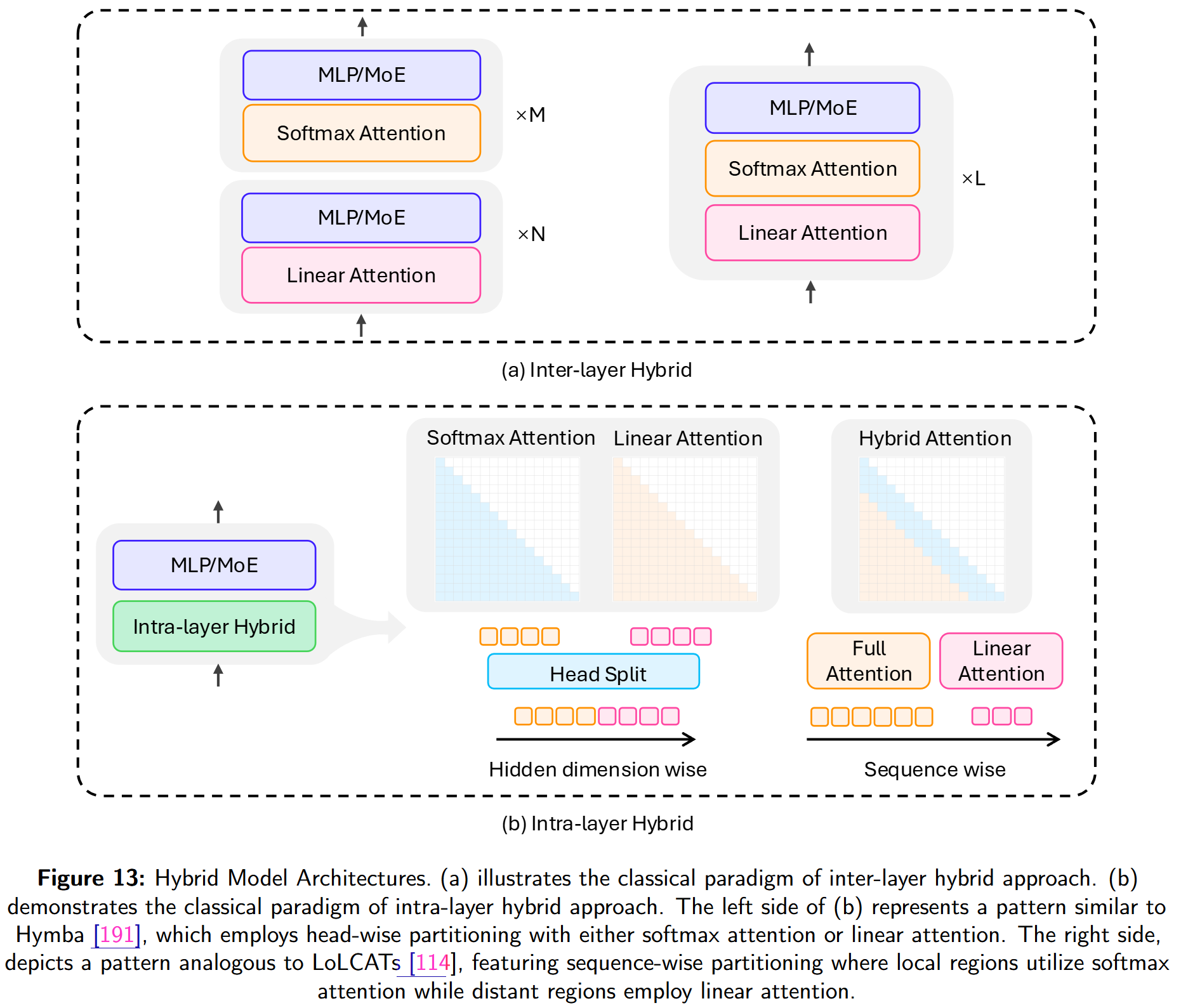
6.1. Inter-Layer Hybrid
层间混合通常按预设比例组合 softmax attention 与线性序列建模层。因其效果可靠、实现简单,已成为混合架构的主流路线。
许多代表性工作建立在 Mamba之上:
- Zamba:基于 Mamba 的 7B 混合 LM,周期性插入一个全局共享 self-attention 块;在通用理解基准上表现接近 Mistral,且训练 token 显著更少。
- Zamba2:升级到 Mamba2,采用两个交替共享注意力块与非共享 LoRA,性能与效率进一步提升。
- Jamba:更大规模(52B)的混合架构,将 Mamba + 标准 attention + MoE 以 7:1 交错;具备强 in-context 能力与高效推理,对 Mixtral 实现 3× 吞吐,支持 256K 上下文且 KV cache 仅 4GB。
- Samba:组合 Mamba + Sliding Window Attention(SWA),完全避开 full attention;zero-shot 可外推至 1M tokens,并以极少微调实现对 256K tokens 的召回。
- Mamba-in-Llama:将预训练 Transformer 蒸馏为 Mamba,并提出注意力 + Mamba的混合版本:复用 Transformer 注意力层的权重初始化 Mamba blocks,随后用多阶段蒸馏保持原注意力能力。
- Hunyuan-TurboS:56B activated(总 560B) 的混合模型,交织 Mamba2 / 标准 attention / MoE,以 Attention-Mamba2-FFN / Mamba2-FFN 的交错结构支持 256K 上下文,在长序列效率与上下文推理间平衡。
- Zebra-Llama:将 Mamba2 与 MLA结合,以最小开销达到 Transformer 级性能;采用 SVD 初始化 + 层蒸馏 与敏感度感知的层替换策略以获得最佳效率。
除 Mamba 体系外,亦有多种与线性注意力、Linear RNN、SWA 的组合:
- RWKV-X:在 RWKV-7的层间战略性地交织稀疏注意力 MoBA(约 25% 的层使用稀疏注意力),在短/长上下文任务上表现强劲;在超长序列时较 full-attention 具更好的解码稳定性与更低延迟。
- YOCO:将 SWA 与标准 attention 结合,提出跨层共享 KV cache:self-decoder 只生成一次 KV,被 cross-decoder 层复用;在长上下文时显著降低内存并提升效率。
- RecurrentGemma:结合 Griffin与 SWA,完全避免全局注意力;在相近规模下匹配 Gemma 的性能,同时在内存与推理效率上更优。
- MiniMax-01:456B-parameter MoE 混合模型,将 Lightning Attention 与标准 softmax attention 结合,高效处理最长至 4M tokens 的序列。
- LaCT:将大块 TTT 与局部窗口注意力结合,以线性复杂度建模全局、仅在局部承担二次代价;支持 1M tokens 的新视角生成与自回归视频扩散等任务。
6.2. Intra-Layer Hybrid
层内混合在同一层融合线性与标准注意力。典型设计包括:
(1) Head-wise split:不同 heads 使用线性或标准注意力;
(2) Sequence-wise split:对不同输入片段使用不同注意力类型。
Head-wise split.
- Hymba是经典的 head-wise 架构:一部分 heads 用 Mamba,另一部分用标准 softmax attention;并引入可学习 meta tokens 进行记忆初始化、SWA + 选择性全局注意力、跨层 KV 共享 等创新。1.5B Hymba 在推理/召回任务上优于 Llama-3.2-3B,且吞吐 3.49×、cache 体积 19× 更小。
- WuNeng将 RWKV-7 的状态驱动机制与 Transformer 注意力结合,通过跨头交互在高分辨率召回与效率之间取得平衡;相较 LLaMA 与 Hymba,在复杂推理与长上下文任务上表现更好。
Sequence-wise split.
- LoLCATs在序列级将 softmax attention 替换为“线性注意力 + SWA”的组合:远端 tokens 用线性注意力、最近 tokens 用局部 softmax 捕获近邻依赖。训练两步走:1. attention transfer 以匹配 softmax 输出;2. LoRA 微调被替换层。仅更新 <0.2% 参数、使用 0.04B tokens,即可把规模至 405B 的模型线性化,并在效率/质量上优于既有混合与次二次模型。
- Liger复用预训练 Transformer-LLM 的key 投影权重构建门控矩阵,将其转为门控线性递归结构(不增加新参数、保留效率);融合 Linear Attention + SWA,以线性时间 + 常数内存达成近似 softmax 的表达力;在 1B–8B 范围内,仅用 0.02B LoRA tokens 即可恢复最高 93% 原性能。
- TransMamba用共享参数与可学习 TransPoint 在标准 softmax 与 Mamba SSM 间动态切换:前段 tokens 走标准注意力以保证精确,后段用 Mamba 做高效远程建模,并用无损 Memory Converter承接;支持至 1.5B 的规模,训练比 Transformer 最快可快 25%,长上下文表现突出。
- LoLA面向线性注意力在长上下文上的局限,整合三套互补记忆系统:低秩线性注意力(高效全局存储)、SWA(精确本地建模)、稀疏全局缓存(保留易受干扰 KV 的高保真表征)。
7. Diffusion Large Language Models
前文介绍的路径都在标准自回归(Autoregressive, AR)范式内通过计算优化提升效率。然而,AR 生成逐 token 输出,推理时的前向次数与序列长度等长,这种顺序依赖 构成了时延的根本瓶颈。
本节介绍近年的 Diffusion LLMs 。与 AR 相比,Diffusion LLMs 通过从噪声/掩码状态逐步去噪 到连贯序列来生成文本。这一生成范式带来若干优势:最显著的是并行解码 ——每个细化步可同时产生多个 token,避免顺序生成显著降低时延。此外,将文本生成表述为在定长画布 上的去噪/补全过程,天然具备更强的可控性 (长度、格式、结构等约束更易满足),而这在标准 AR 下较难。最后,Diffusion LLMs 采用双向注意力 ,每一步都可全局访问并改写上下文,有助于缓解因单向解码引发的诸如 reversal curse 等问题。
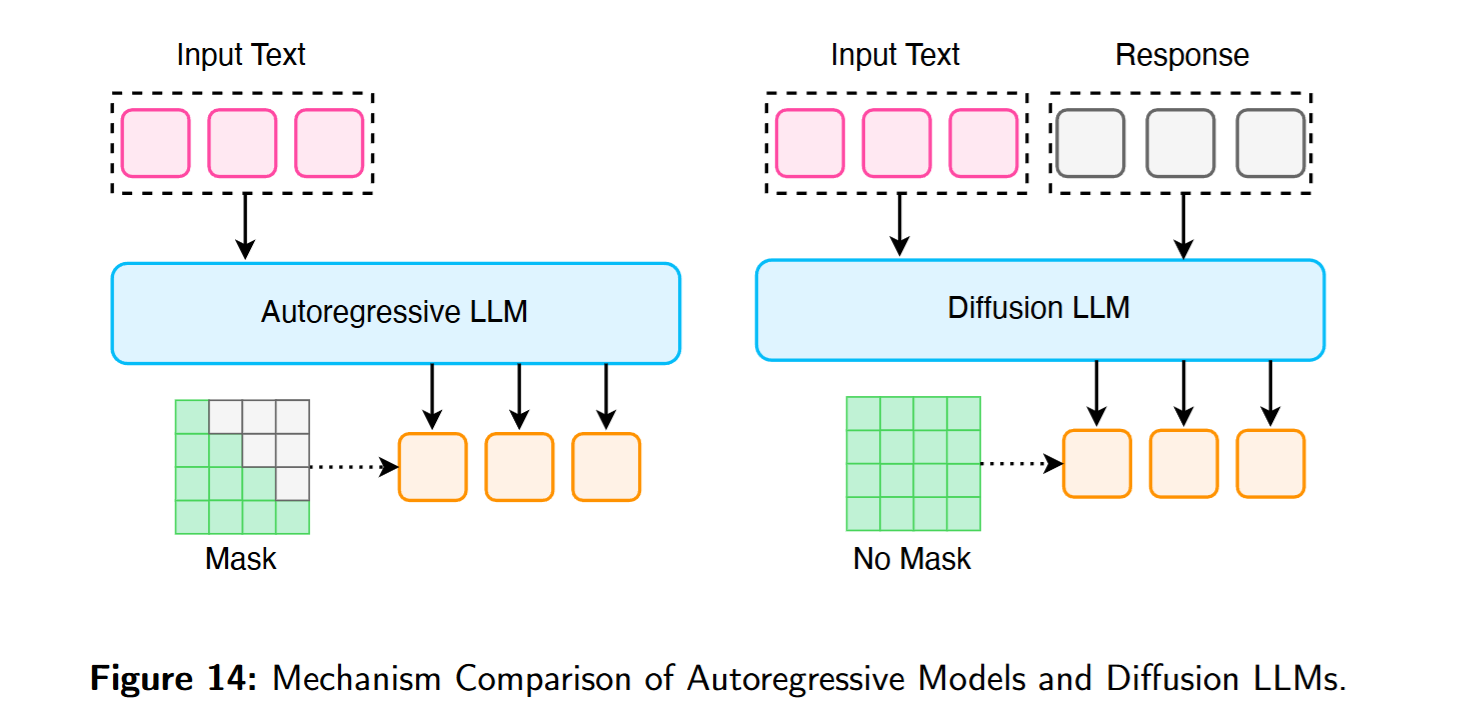
7.1. Non-Autoregressive Diffusion LLM
LLaDA是一款从零训练的非自回归 Diffusion LLM(8B)。其前向过程逐步掩码tokens,反向去噪过程在每一步同时预测所有被掩码的 tokens。
模型分布由预设的前向噪声与可学习的反向生成构成:前向把干净序列转为中间态,其做法是在时间步以独立概率掩码tokens;反向过程训练为从逐步退火到,不断去噪并预测被掩码位置。
核心组件时是参数化的掩码预测其,优化目标:
训练完毕后,采样就是模拟的反向过程。是模型负对数似然的变分上界:
不同于使用固定掩码率 的 BERT,LLaDA 的随机掩码比 是其设计要点。由式 (30) 的 NLL 上界可知,LLaDA 属于真正的生成模型 。这一原则性基础也支撑了诸如 in-context learning 等涌现能力,使其成为主流 LLM 的非自回归 替代方案。 Diffusion LLM 是否能匹敌经 RL 强化的 AR 模型的推理力,一直是开放问题。** d1 框架给出强有力的肯定:它以两阶段让已预训练的掩码式 Diffusion LLM 具备复杂推理——先对 推理轨迹做 SFT,再用新提出的 RL 算法 ** diffu-GRPO。该策略梯度算法面向非自回归特性设计,提供高效的一步对数概率估计,并以** 随机掩码提示作正则。应用于 ** LLaDA-8B-Instruct 时,d1 在数学与逻辑推理基准上相对基线与 SFT/RL 消融均取得显著增益,表明配合 RL 的 Diffusion LLM 也能成为** 强推理者**。
7.2. Bridging Diffusion LLM and Autoregressive
Diffusion LLMs 具备并行生成与更强可控性,但在似然建模上存在挑战,且天然受定长输出约束。近期一个重要方向是融合两者优点。
BD3-LMs在“离散去噪扩散”与 AR 间做插值:把序列按块分段做 AR(对块的自回归),并在每块内部执行扩散去噪。此混合既解除 Diffusion 的定长限制,又显著缓解 AR 的高时延;其做法把 AR 的 KV cache 与块内并行采样结合起来,实现灵活长度与高效推理。
形式化地,设,将其设为个不重叠块、每个块长,联合对数似然按照块级自回归分解:
其中的每一项由Diffusion过程给出:学习去噪模型来反转加噪,马尔可夫链:
去噪函数是一共享的transformer ,块间包含因果掩码。对于给定的block & 因果上下文,模型预测去噪后端的整块:
这样块间自回归、块内并行diffusion,同时还可以兼容之前的KV Cache等各种设计。
训练目标:
是负对数似然的变分上界,由各块的扩散损失聚合得到。
另一条路径由 DiffuLLaMA给出:直接改造大量预训练 AR 模型(如 GPT-2、LLaMA,127M–7B)为文本扩散架构 DiffuGPT / DiffuLLaMA。基于 AR 与 Diffusion 目标的等价/关联,其仅以持续预训练即可完成转换。结果显示,这些模型优于既有 Diffusion LLM,且与对应 AR 基线竞争力相当,而所需训练数据远少于从零训练;同时继承了 in-context、指令跟随等能力,并在“fill-in-the-middle”等非顺序任务上天然占优(无需提示重排)。
7.3. Extending Diffusion LLM to Multimodality
- LLaDA-V:纯扩散式多模态 LLM,采用视觉编码器 + MLP 连接器,将视觉表征映到语言潜在空间,主要依赖视觉指令微调达成对齐;在多模态上有良好表现与数据可扩展性。
- UniDisc:倡导在文本/视觉两域采用统一的离散扩散生成范式:共享架构把文本与图像联合分词到同一词表并使用 full self-attention;在跨模态补全与零样本编辑上表现强,且无需针对这些任务显式优化。
- LaViDa:同样为离散扩散 + 视觉编码器,但聚焦于将扩散模型落地到视觉-语言任务的工程难点:提出“complementary masking”以确保所有输出 token 都参与学习、提升数据效率;“Prefix-Diffusion LLM decoding”以启用 KV caching、高效处理长多模态提示;“timestep shifting”在减少生成步数时提升样本质量,体现扩散在速度-质量权衡与可控性上的优势。
- Dimple:为克服纯离散扩散在多模态训练的不稳定与次优,提出“Autoregressive-then-Diffusion”混合训练:先用 AR 阶段获得稳健的视觉-语言对齐/指令跟随,再切换到扩散式掩码语言建模以恢复并行解码。推理时提出“Confident Decoding”按置信度动态调节每步生成 token 数,以及“Structure Priors”对长度与格式细粒度控制;最终达到与 LLaVA-NEXT等 AR 基线相当的表现。
- MMaDA:提出一类新的多模态扩散基础模型:统一概率框架 + 模态无关设计,无需离散的模态特定组件;配合“混合长 CoT”微调,在多模态间建立一致的 CoT 结构,从而支持冷启动 RL。并提出针对扩散的统一 RL 算法 UniGRPO,在文本推理、多模态理解、乃至文生图等任务上展现出色的泛化。
8. Applications to Other Modalities
8.1. Vision
8.1.1. Image Classification, Detection, and Segmentation
主要是方法迁移,没有很特别的内容?
8.1.2. Image Enhancement, Restoration, and Generation
核心难点仍是把 1D SSM 适配 2D:由此催生了 zigzag、双向处理 等扫描来增强空间上下文。
8.1.3. Domain-specific Applications
8.2. Audio
8.3. Multimodality
9. Conclusion and Future Directions
本文回顾了为克服基于 Transformer 的效率瓶颈而提出的关键架构创新 与优化策略 。我们强调:self-attention 的二次成本与 FFN 的规模增长共同推高了算力与内存需求,尤其在长序列、多模态、多步推理 场景下更为突出。我们将近期方案归纳为七大类:线性序列建模、稀疏序列建模、高效 full attention、稀疏 MoE、混合架构、Diffusion LLMs、跨模态应用 。对每一类,我们梳理核心思想与技术细节,概述代表性工作,并分析其优劣与局限。通过系统化组织这些路径,我们希望呈现清晰全景与其共同应对的挑战。
展望未来,我们提出若干值得探索的方向:
Efficient Architectures Design(高效架构设计)
随着模型不断增大并需在云到边的广泛环境中运行,迫切需要重思核心设计原则:
- 算法-系统-硬件协同设计 :联动为线性/稀疏/full attention 设计优化,尤其面向边缘与专用芯片。
- 自适应注意力机制 :根据输入/硬件状态动态调节稀疏度或算量,在效率与灵活性间更优折中。
- 更强的 MoE 路由 :提升专家利用率、降低通信与推理时延。
- 更大但更高效的模型 :以更高效的内存布局、稀疏激活与通信友好设计扩展参数规模。
- 分层记忆架构 :将本地/短期/长期等多级记忆集成到模型,用于高效存取历史计算与世界知识。
- 高效小模型上边缘 :面向边缘部署的紧凑 LLM/VLM(量化、剪枝、紧凑结构)。
- 非自回归 Diffusion LLMs :在对话、摘要等任务中以并行生成与更快推理逼近 AR 质量。
Applications of Efficient Architectures(高效架构的应用)
除改进核心效率外,另一关键前沿是将这些进步用于拓展模型功能 。面向实时、动态、多模态环境,新的设计优先级包括无限上下文、智能体能力、终身学习、多模态推理等:
- 无限长上下文 :高效模型处理极长/无界上下文,增强 RAG、Agent、推理与多模态长输入。
- 高效 Agentic LLMs :以低延迟支持实时工具使用、规划与多模态推理,驱动敏捷交互型智能体。
- 高效大推理模型 :减少冗余计算,利用轻量逻辑/记忆组件,提升推理任务的可扩展性。
- 高效 VLA(Vision-Language-Action) :高效融合与快速视觉推理支持机器人与交互系统的实时控制。
- 高效全模态模型(Omni-modal) :统一高效地处理文本/视觉/音频/3D 等多模态。
- 统一的理解-生成多模态模型 :在联合感知与生成中输出更一致、语境感知更强。
- 持续适应与终身学习 :支持在线适配新数据流而不灾难遗忘,使 LLM 在长期变化环境中持续演进。