摘要: 大型语言模型(LLM)表现出色,但能耗巨大。本文提出一种为英特尔神经形态处理器 Loihi 2 量身适配的MatMul-free LLM 架构。我们的做法利用了 Loihi 2 对低精度、事件驱动计算以及有状态(stateful)处理的支持。基于 GPU 的HAQ模型表明:一个 370M 参数的免矩阵乘模型可以在不损失精度的情况下完成量化。依据初步结果,与在边缘端 GPU上运行的基于 Transformer 的 LLM 相比,我们报告吞吐量最高可达 3×,同时能耗降至 1/2,且可扩展性显著更好。进一步的硬件优化将继续提升吞吐量并降低能耗。这些结果展示了神经形态硬件在高效推理中的潜力,并为能够快速、低成本生成复杂长文本的高效推理模型铺平道路。
1. Intro
Loihi 2 针对序列式处理、逐元素递归、低精度算术与权重稀疏做了优化,而这些正是Matmul-free模型的特征。本文作为一个进行中的工作(work-in-progress),介绍了如何将 Zhu 等(2024)的Matmul-free LLM适配并部署到 Intel Loihi 2,为神经形态计算与最先进高效 LLM之间架起一座桥梁。
2. Model Architecture
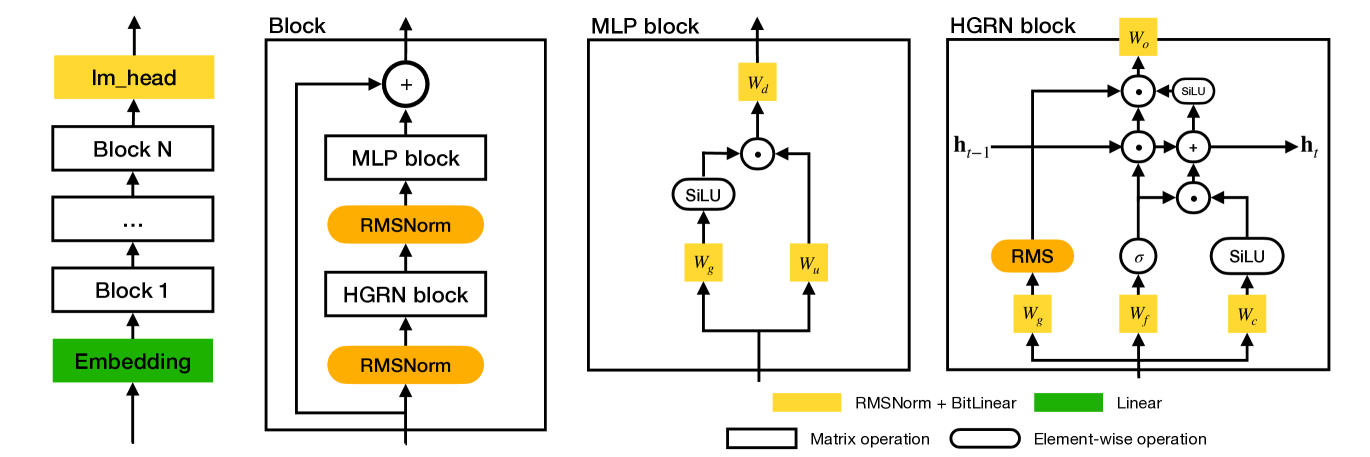
模型370M参数,weight是ternary的,通过ternary weight + 特殊层的设计,将所有的matmul替换为加法、位移和element-wise op。Token Mixer与Channel Mixer交替堆叠。
BitLinear Layer将一个Ternary线性变换和一个RMSNorm相结合,保证activation的数值稳定性:
是逐元素乘,是对三值weight1与input的累加/聚合运算。使用三值权重天然带来突触级稀疏性;在全部三值权重矩阵上,370M的 Matmul-Free 模型有的权重幅值为零。
Matmul-Free版本的GLU:
Token Mixer MLGRU代替传统Transformer,将之前的GRU变体中所有的Linear层替换为上面的:
初状态下。
3. Model Adaptation for Loihi 2
Quantization of weights and activations
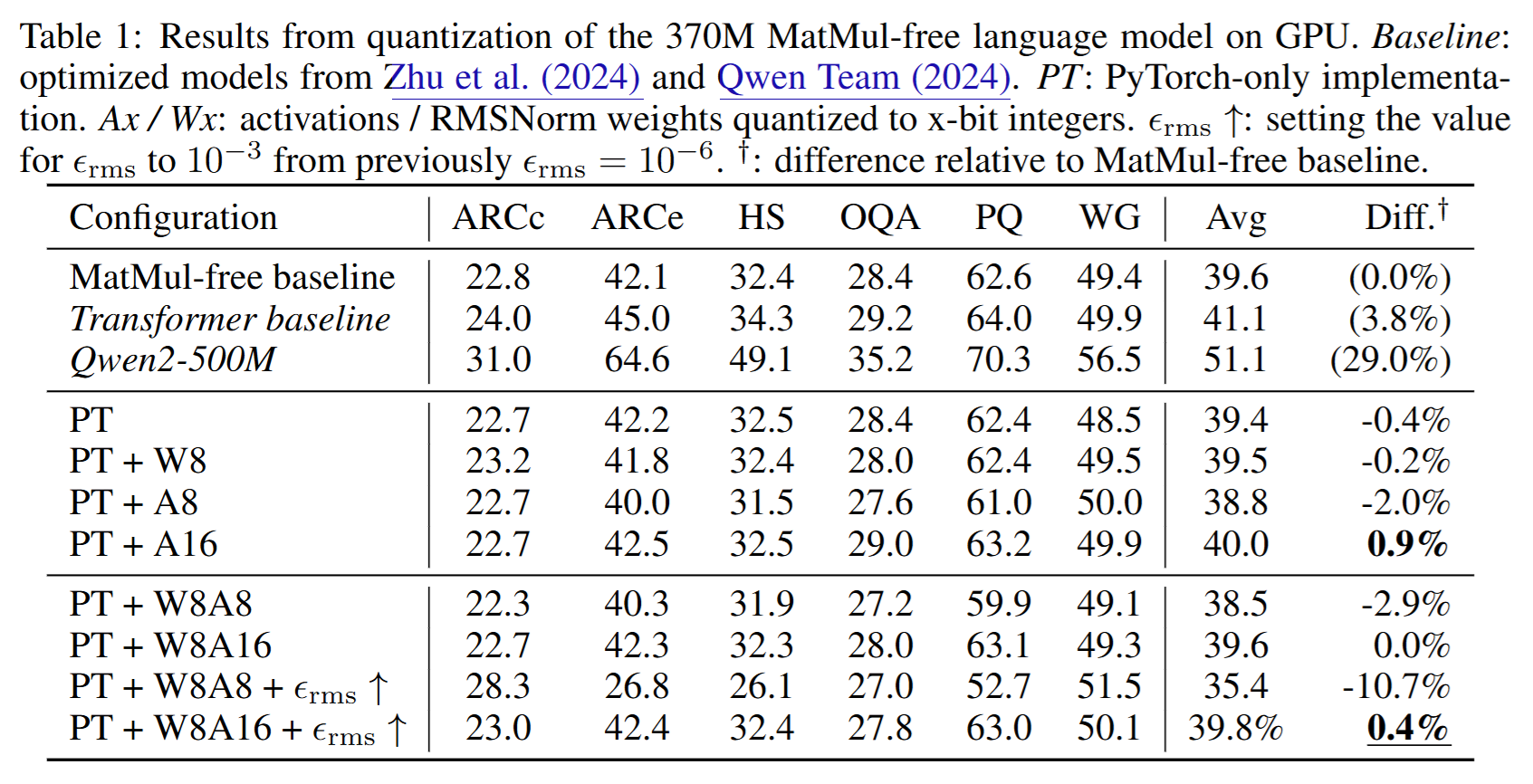
性能比不过Qwen2-500M,但是声称scale up之后是可以的?
在做量化的时候用简单的PyTorch写法代替GPU-optimized Triton Kernels,“以便更容易量化”,可能是方便暴露更多信息?注意到数值积累误差带来了的性能变化。
Fixed-point implementation
注意到和的”inverse-square-root”两个操作不是int上的,对于提供了一个LUT作为近似,对于实现了一个定点数上的快速
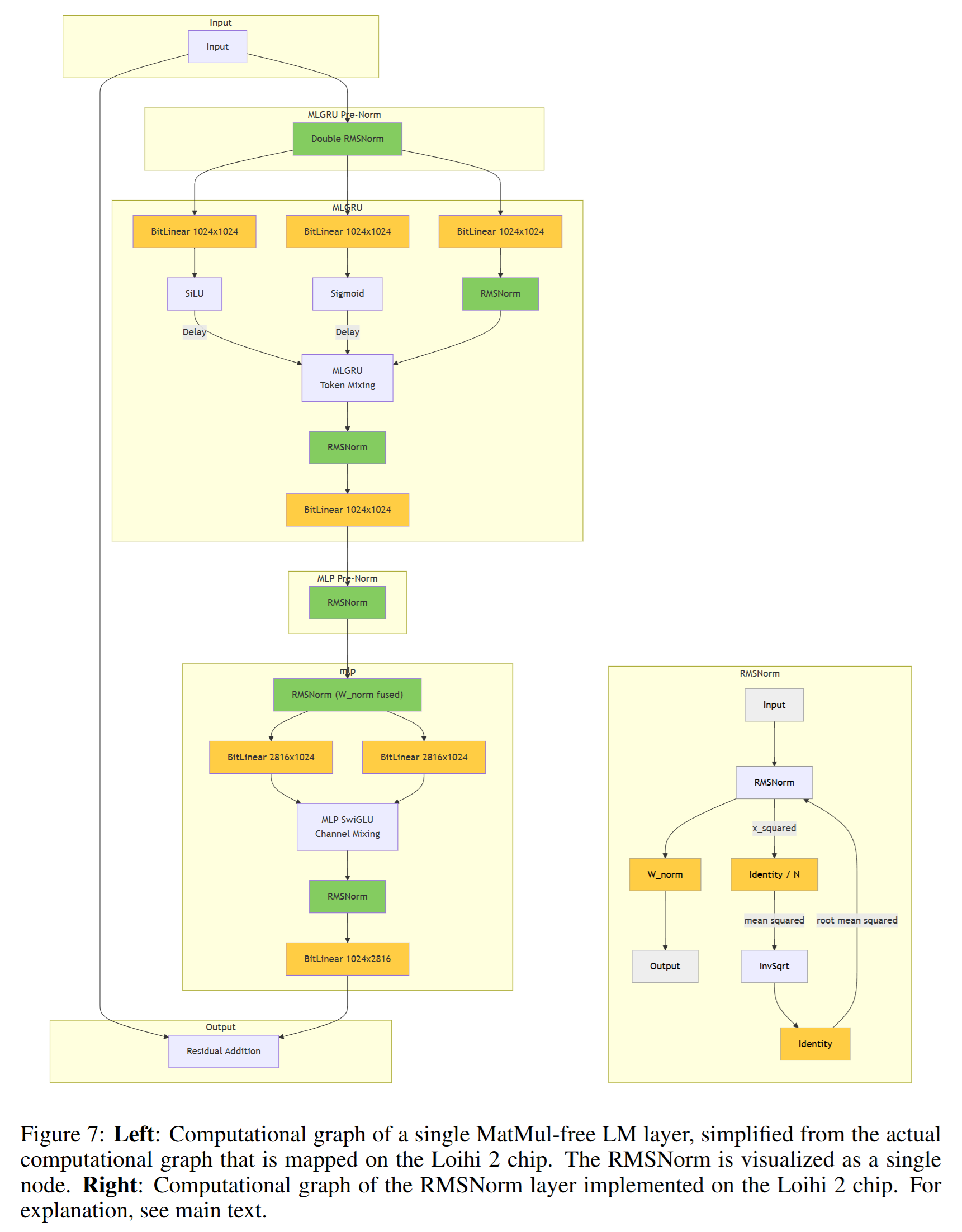
Mapping the model to Loihi 2
在 Loihi 2 上,模型被表示为由神经元组成、通过突触互联的网络。每个神经元由一个简单的microcode 程序实现,异步地在每颗 Loihi 2 芯片上的 120 个 neuro cores 之一上执行,随后其输出通过突触连接传递给其他神经元。系统通过在所有 neuro cores 间的barrier synchronization来维持全局时间步。由于每个神经元只维护自身状态,诸如对一个激活向量求平方和这类聚合运算必须由专门的神经元完成——它们从对应层内的所有神经元接收输入。
4. Results
Note: All current comparisons are performed with FP16 baselines on non-Loihi hardware.
这是啥意思?到底是部署了还是没有部署?
我们将 Loihi 2 上 370M 的 MatMul-free 模型的估算性能,与运行在 NVIDIA Jetson Orin Nano 上的 Transformer 基线进行对比。选择 Jetson Orin Nano(8GB) 作为对比平台的原因在于:它代表了最前沿的边缘 AI 设备,配备 1024 CUDA cores、32 Tensor cores,最大功耗 15W,非常契合能效敏感应用的基准需求。Orin Nano 专为与神经形态硬件相似的边缘部署场景设计,从而可在相近的应用环境下进行公平对比。
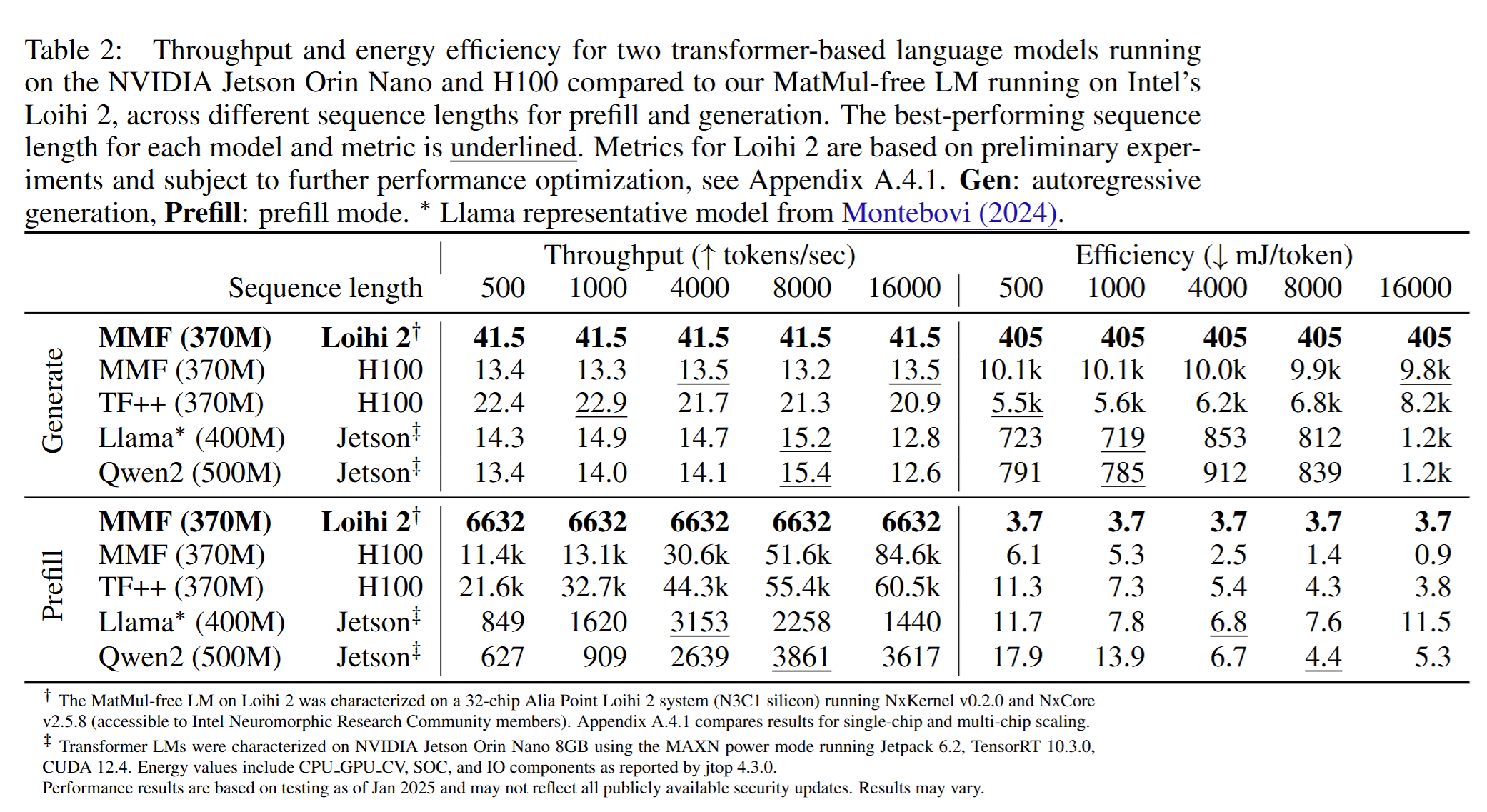
单Batch,考察Prefill & decode两个阶段的吞吐。两个阶段的吞吐和能效都更好,但现在即不知道它的实验究竟是在哪里做的,同时又是把效果未知的Linear Attention和传统Transformer做对比。
时延特性对边缘交互式应用尤为重要。我们的实验显示,在batch size = 1(边缘部署的典型设置)下,Loihi 2 上的 MatMul-free 在 500-token 输入上的首 token 时间(TTFT)降低 6.6×(Loihi 2 上 99ms vs Jetson 上 Llama 风格模型的 659ms)。由于我们的方法线性缩放而 Transformer 为平方级,该优势会随序列长度扩大。对于语音助手或移动聊天机器人等实时应用,这种时延降低可直接带来更灵敏的用户体验,同时显著降低能耗。
这个说法之后写论文的时候可以学一下。
5. Conclusion
我们展示了如何利用神经形态原则 与协同设计(co-design)构建高效 LLM 。通过将 MatMul-free 架构与 ** Intel Loihi 2** 融合——利用** 有状态计算、 极致量化与 算子融合**——我们构建出一个** 370M-parameter** 的强力模型,显著** 提升吞吐并 改善能效**。实验表明,** Loihi 2** 的** 固有并行性与 低功耗处理可转化为 可观**的吞吐与能效增益。
我们方法的关键创新 包括:(1)首次在神经形态硬件 上演示现代 LLM 架构,为** 高效边缘 AI** 奠定路径;(2)一种** 硬件感知量化方法,在支持 定点计算的同时 保持精度**;(3)** MatMul-free** 架构的** 全新 microcode** 实现,充分利用 ** Loihi 2** 的** 异步、事件驱动范式;(4)面向神经形态计算的 自定义算子融合技术,包括我们提出的 双 RMSNorm** 推导。不同于以往只针对某些** 神经原语的做法,我们的工作显示: 完整且具竞争力的 语言模型可以被 重构以充分利用神经形态硬件的独特特性, 同时保持性能**。
在硬件层面,结果表明神经形态处理器 有潜力成为可扩展高效推理 的平台;未来体系结构可与模型创新协同设计 ,进一步突破性能边界 。我们的方法为自适应语言处理 提供了一条有希望 的路径,而无须承担传统 LLM 所带来的高昂能耗 。鉴于需要长链式思考展开 的推理模型 日益重要,高效、高吞吐 的自回归生成 比以往任何时候都更关键。我们的设计在该模式下尤为突出,进一步为更快速、更高效 的可扩展基础模型 铺平道路。
有点无语,大晚上把人喊出来就是这么个事情吗.jpg
PS:看Appendix发现他们的模型其实已经部署到了芯片上了,只是embedding & unembedding部分没做出来,导致前面各种性能测试上还是在GPU上测的。
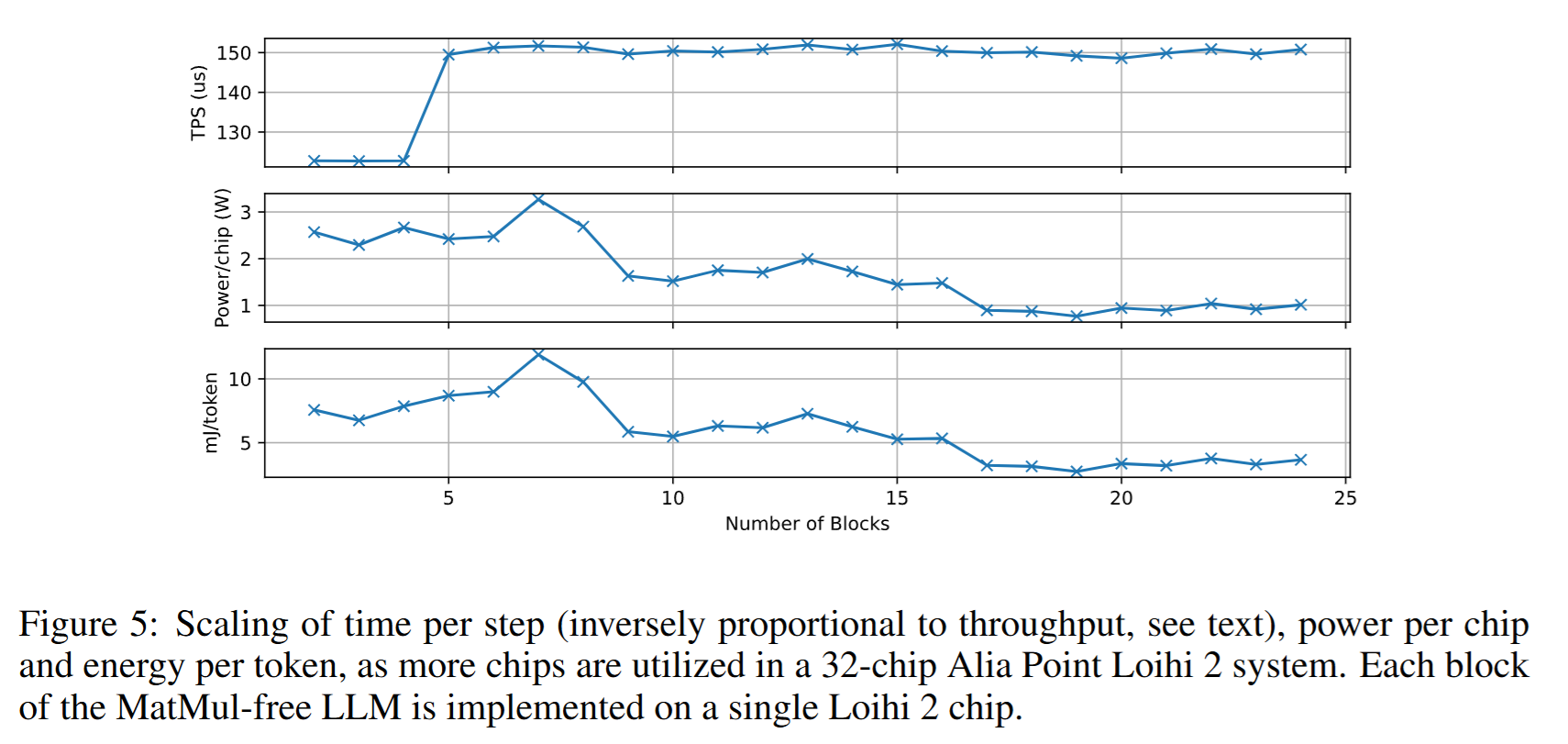
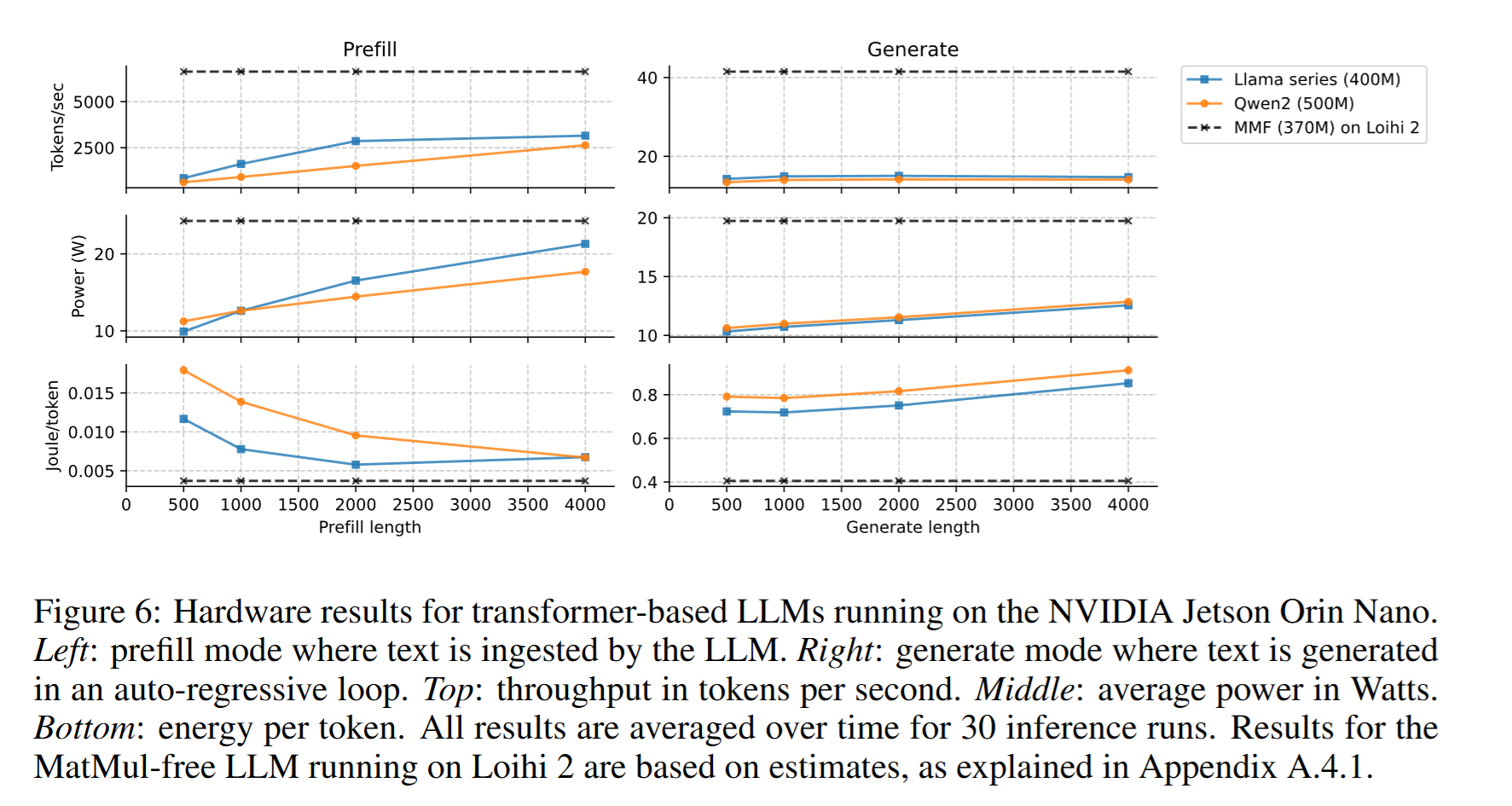
但看下来感觉就是一个普通的,把Loihi 2当成一个Dataflow架构的芯片在用,里面的各种什么类脑啊什么的都是蹭一下,没有什么很特别的东西。并且各种什么Ternary量化是怎么做的之类的都没讲。难怪只是个workshop。
需要注意的是,这种突触稀疏性并不能节省内存,因为1024×1024三元矩阵的稀疏编码比密集编码占用约7.5倍的内存。然而,零权重确实可以通过跳过计算来节省能量。
有点没理解?Ternary Weight和稀疏不一定相关?同时它采用稀疏编码之后的内存开销显著更大了?
Footnotes
-
原文此处注释: ↩