摘要: 时序视频定位(TVG)是视频内容理解中的一项关键任务,要求在视频内容与自然语言指令之间进行精确的对齐。尽管已有方法在这一领域取得了显著进展,但现有方法在应对显著对象的置信偏差和捕捉视频序列中的长期依赖方面仍面临挑战。为了解决这些问题,我们引入了SpikeMba:一种用于时序视频定位的多模态尖峰显著性Mamba模型。我们的方法将脉冲神经网络(SNNs)与状态空间模型(SSMs)相结合,利用它们在处理任务不同方面的独特优势。具体而言,我们使用SNNs开发了一种尖峰显著性检测器,用于生成建议集。当输入信号超过预定义的阈值时,检测器发出尖峰信号,从而生成动态的二进制显著性建议集。为了增强模型保留和推断上下文信息的能力,我们引入了相关槽——可学习的张量,用于编码先验知识。这些槽与上下文时刻推理器协同工作,在动态地保持上下文信息和探索语义相关性之间保持平衡。SSMs促进了选择性信息传播,解决了视频内容中的长期依赖问题。通过将SNNs用于建议生成和SSMs用于有效的上下文推理,SpikeMba克服了置信偏差和长期依赖问题,从而显著增强了细粒度多模态关系的捕捉。我们的实验结果表明,SpikeMba在主流基准测试中持续超越最先进的方法。
1. Intro
TVG Temporal Video Grounding 时序视频定位任务,目标是在一段视频中根据给定的自然语言描述精确地找到与描述相匹配的时间段。
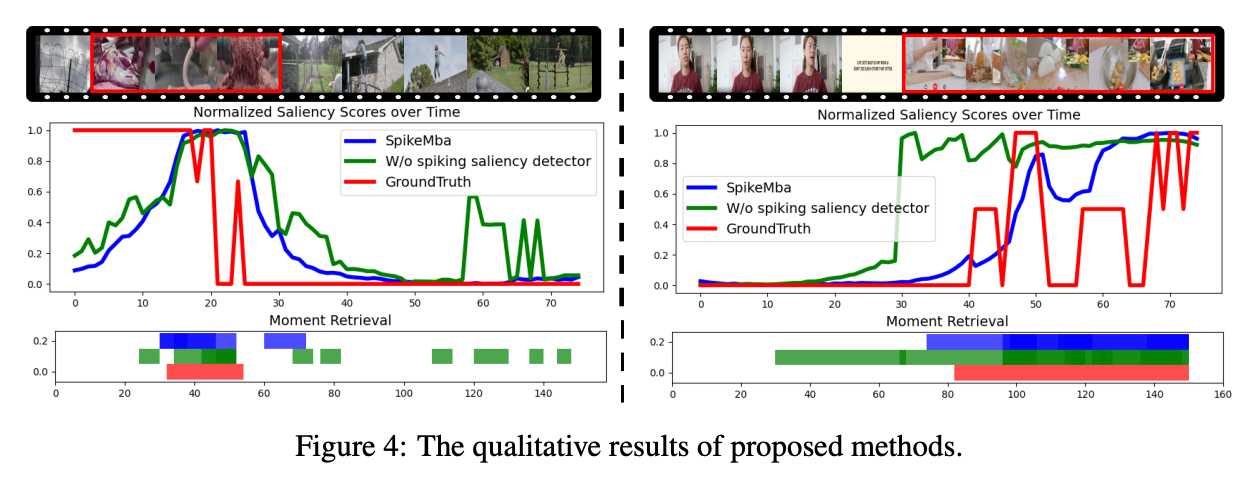
尽管当前的视频内容定位方法表现出显著的性能,但它们在以下几个关键问题上仍然面临挑战:1)显著对象的置信偏差:在复杂的视频环境中,由于显著对象的剧烈变化,模型往往会识别出多个潜在的建议集。这导致对这些对象的过度关注,往往忽略了视频的整体内容。例如,在图1(左侧)中,最高置信度的建议(预测#1)可能只关注门的开启,忽略了接下来狗进入的动作。这表明,尽管次要建议(预测#2)可能更接近视频内容的正确解释,但通常会由于置信度较低而被忽视。2)相关片段的长期依赖性:在视频时序定位中,特别是对于长序列,解决复杂的长期时空关系至关重要。尽管Transformer模型在捕捉长期依赖关系方面表现出优势,但它们往往在每个查询中对每个词和每个视频片段之间进行统一的跨模态交互,这可能忽略了对视频整体动作理解至关重要的片段的选择性关注。
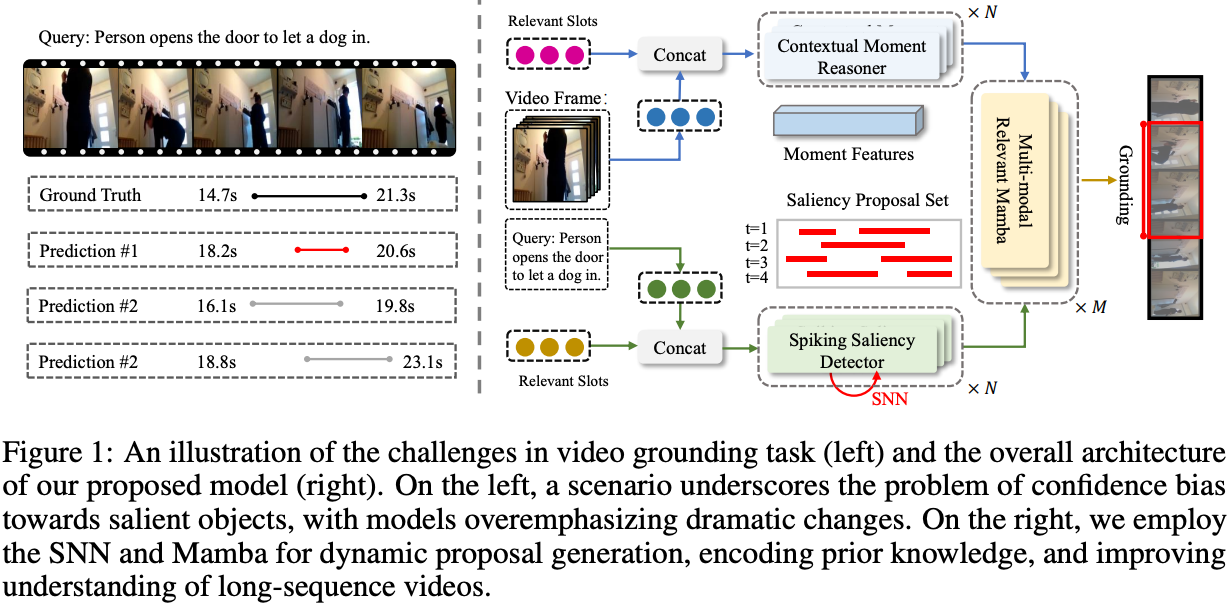
Contributions:
- 我们提出了一种新颖的SpikeMba:用于时序视频定位的多模态尖峰显著性Mamba模型。我们提出了一种尖峰显著性检测器,该检测器利用SNN的阈值机制和生成的二进制序列来有效地探索潜在的显著性建议。
- 为了增强长视频序列中的上下文信息记忆能力,我们引入了相关槽来选择性地编码先验知识。提出的上下文时刻推理器进一步利用动态相关槽来推断上下文语义关联。
- 我们将SSMs纳入选择性信息传播的机制中,基于当前输入有效解决了视频内容中的长期依赖性问题。我们的实验结果表明,SpikeMba在基准数据集上的有效性。
2. Related Work
主要还是说SNN在处理这种时序信息上可能具有一些天然优势。
3. Method
问题:给定一个视频,包含个片段,然后一个文字查询,需要计算每个片段的显著性分数,并识别目标时刻 ,其中 代表中心时间坐标, 代表识别出的时刻的持续时间。
3.1. State Space Model (SSM)
SSM描述线性系统状态随时间的变化,
将函数 映射为,通过隐藏空间。线性系统中的SSM可以表示为:
其中, 、 和 分别对应状态矩阵、输入矩阵和输出矩阵。Mamba模型通过离散化操作近似上述连续系统,利用时间尺度参数将连续参数、转换为它们的离散对应物 、。常用的变换方法是零阶保持(ZOH)方法,可以表示为:
最终,输出通过单一卷积操作向量化:
其中,代表卷积滤波器,代表输入序列的长度。
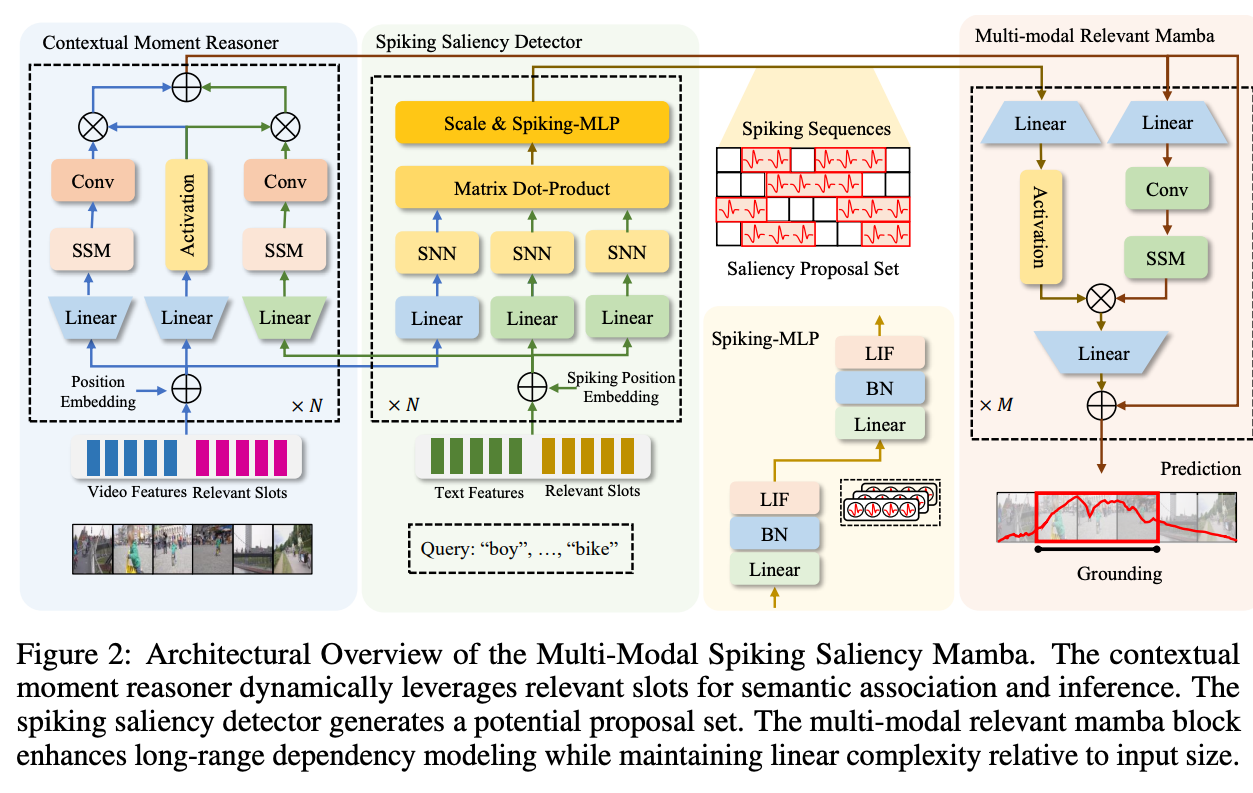
3.2. Contextual Moment Reasoner (CMR)

相关槽是一个可学习的矩阵,连接到原始输入序列或上,形成。CMR通过一系列卷积和Mamba操作提取时空模式,然后通过线性变换调整维度,然后做position embedding保持时间信息。
3.3. Spiking Saliency Detector (SSD)
就是过一个多层的SNN,然后算Attention之后再过一个SNN,就有:
由SNN生成的尖峰序列封装了视频中显著特征的时间动态。这是通过尖峰的时间分辨率实现的,从而能够对视频内容进行细粒度分析。尖峰序列被分析以构建显著性提案集。序列中的每个尖峰都被视为标记显著时刻的候选,尖峰的集合构成了提案集。这个提案集代表当前视频中与文本查询相对应的潜在兴趣时刻,是定位过程的关键输入。
整体架构可以表示为:
其中 表示 LIF 层, 是可学习的线性矩阵, 是缩放因子。利用 SNN 独特的显著性检测特性,提出的 SSD 提供了一种识别视频内容关键时刻的新颖而高效的方法。其生成高时间分辨率尖峰序列的能力,以及与上下文推理机制的集成,确保了视频序列中时刻的准确定位。
3.4. Multi-modal Relevant Mamba (MRM)

多模态相关 Mamba(MRM)结合线性变换和卷积层对处理后的视频和文本特征进行整合。通过分析尖峰序列和上下文增强的多模态特征,MRM 可以预测与文本查询对应的时刻在视频中的时间位置。
“MRM Block”算法处理维度为 的输入词汇序列 和 。它通过一系列变换来增强其在机器学习应用,尤其是自然语言处理中的表示。首先,对两个序列都进行层归一化,以稳定学习过程。接下来进行线性变换,修改它们的特征空间维度为 。变换后的 序列经过 1 维卷积和 激活进一步处理。类似于 CMR 模块中的函数,SSM 用于生成通过与从中导出的门控因子逐元素相乘获得的门控输出 。通过添加变换后的到原始输入 ,得到最终输出 。这确保了算法在捕获和增强输入序列特征的同时,保持与原始数据的连接,表明其设计用于捕捉复杂数据模式的高级深度学习技术。
3.5. Training Strategy
我们在六个 Nvidia V100S GPU 上训练了 SpikeMba 模型。具体而言,我们在 QVHighlights、Charades-STA、TVSum 和 Youtube-HL 上分别设置了批量大小为 64/64/8/8,学习率为 2e-4/4e-4/2e-3/4e-4,尖峰时间步为 8/8/10/10,Mamba block 的数量为 6/6/6/6。训练通过使用权重衰减为 1e-4 的 Adam 优化器进行优化。
损失函数:
- contractive loss 让特征和第个batch标签中的时间对齐
- saliency proposal loss预测显著性输出与真实输出之间的差距
- entropy loss 减小输出中的错误
4. Experiment
QVHighlights、Charades-STA和 TACoS 数据集上的时刻检索任务,以及在 QVHighlights、TVSum和 Youtube-hl数据集上的高光检测任务。
4.1. Comparison with State-of-The-Art Methods
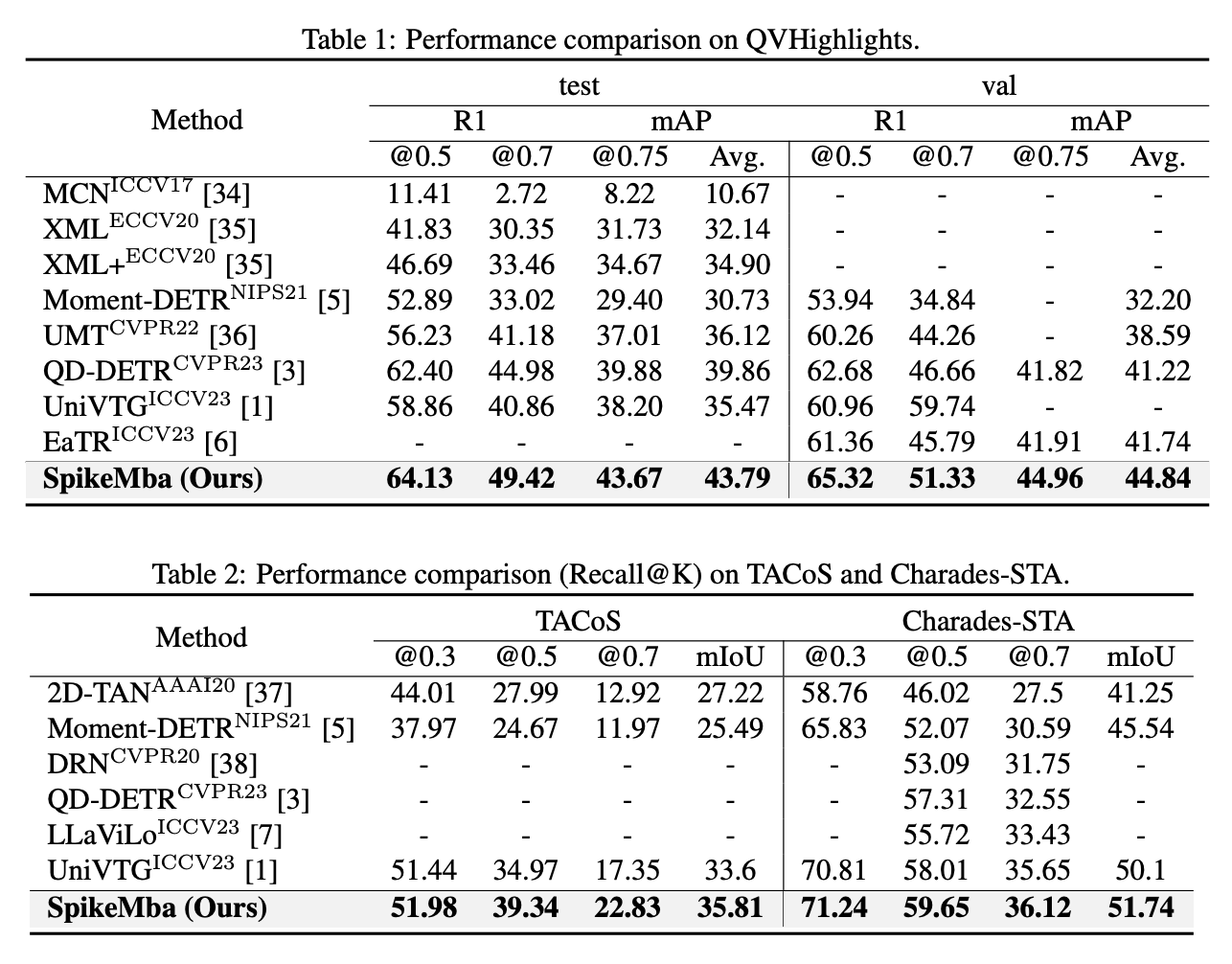
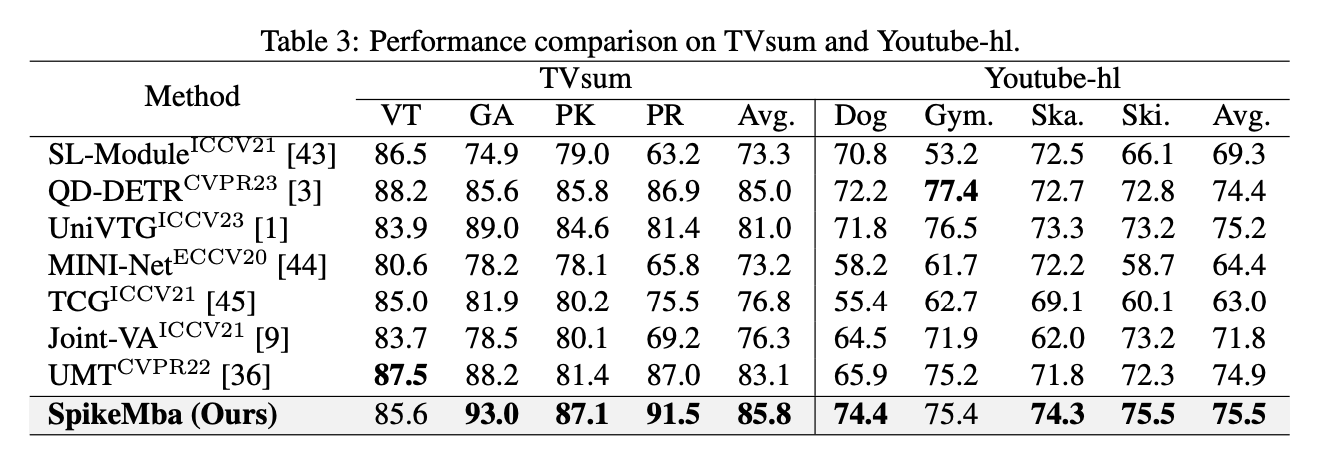
基本全面超越SOTA,论述部分强调的主要是多模态输入和对齐、复杂输入下的稳定性方面的优势。
4.2. Ablation Study
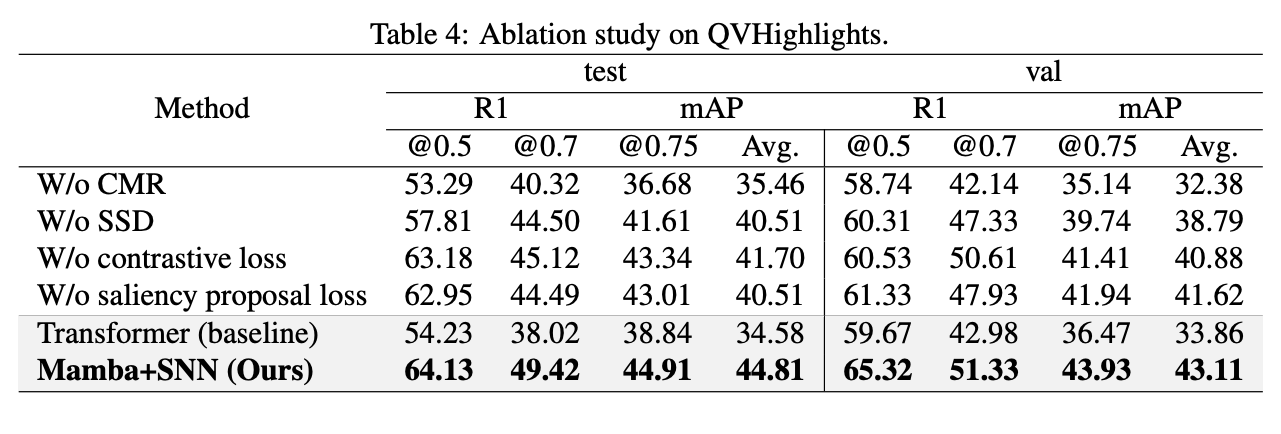
在这个任务上使用SNN + Mamba 效果比Transformer好。
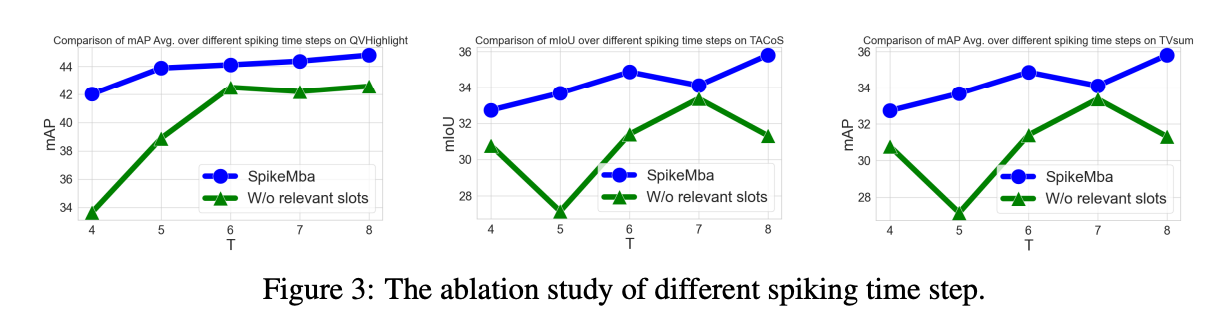
Relevant slot提供了低timestep下的更好的性能,可能可以学习一下。
5. Conclusion
本文提出了一种用于时序视频定位的多模态尖峰显著性 Mamba 模型,该模型结合了脉冲神经网络 (SNNs) 和状态空间模型 (SSMs),以解决置信偏差和长期依赖捕捉等挑战。基于 SNN 的尖峰显著性检测器能够准确识别显著的视频片段,而相关槽和上下文时刻推理器则有效地保留并推断上下文信息。SSMs 通过增强选择性信息传播来进一步优化模型。实验结果表明,SpikeMba 在准确性和效率方面始终优于现有的最先进方法,显示出其在时序视频定位中提升性能的潜力。
局限性 :SNNs 和 Mamba 框架输出的异构性带来了显著挑战,需要更有效的策略来整合这些系统并协调它们的输出。要充分发挥时空显著性检测和长期依赖建模的互补优势,这种集成至关重要。