摘要: 脉冲神经网络是以制作低能耗机器智能为目标的一个活跃的研究领域。与传统的人工神经网络(ANNs)相比,SNNs使用时间脉冲数据和生物可信的神经元激活函数,如LIF/IF来处理数据。然而,SNNs在标准的冯·诺伊曼计算平台上会产生大量的点积运算,导致高内存和计算开销。为此,提出了内存计算(IMC)架构来缓解冯·诺伊曼架构中普遍存在的“内存墙瓶颈”。尽管近期的研究提出了基于IMC的SNN硬件加速器,但以下关键的实施方面被忽视了:1) 由于在多个时间步长上重复模拟点积运算,交叉电阻的非理想效果对SNN性能的影响;2) LIF/IF和数据通信模块等SNN特定组件的硬件开销。为此,我们提出了SpikeSim工具,它可以对映射到IMC的SNNs进行现实性能、能源、延迟和面积评估。SpikeSim由一个实用的单片IMC架构SpikeFlow组成,用于映射SNNs。此外,非理想性计算引擎(NICE)和能源-延迟-面积(ELA)引擎对映射到SpikeFlow的SNNs进行硬件真实性评估。基于65纳米CMOS实现和在CIFAR10、CIFAR100和TinyImagenet数据集上的实验,我们发现LIF/IF神经元模块对总硬件面积的贡献显著(>11%)。为此,我们提出了SNN拓扑修改,这导致神经元模块面积减少1.24倍,总能量延迟产品值减少10倍。此外,在这项工作中,我们对IMC实现的ANN和SNN进行了全面比较,得出结论:与4位ANN相比,较少的时间步长是SNN实现更高吞吐量和能源效率的关键。SpikeSim工具的代码仓库将在此Github链接中提供。
1. Intro
在传统的计算架构上实现SNN同样会因为需要执行大量点积操作导致执行低效、面临内存墙问题。为了解决这一问题,模拟存内计算(analog In-Memory Computing,IMC)也被用来实现SNN。
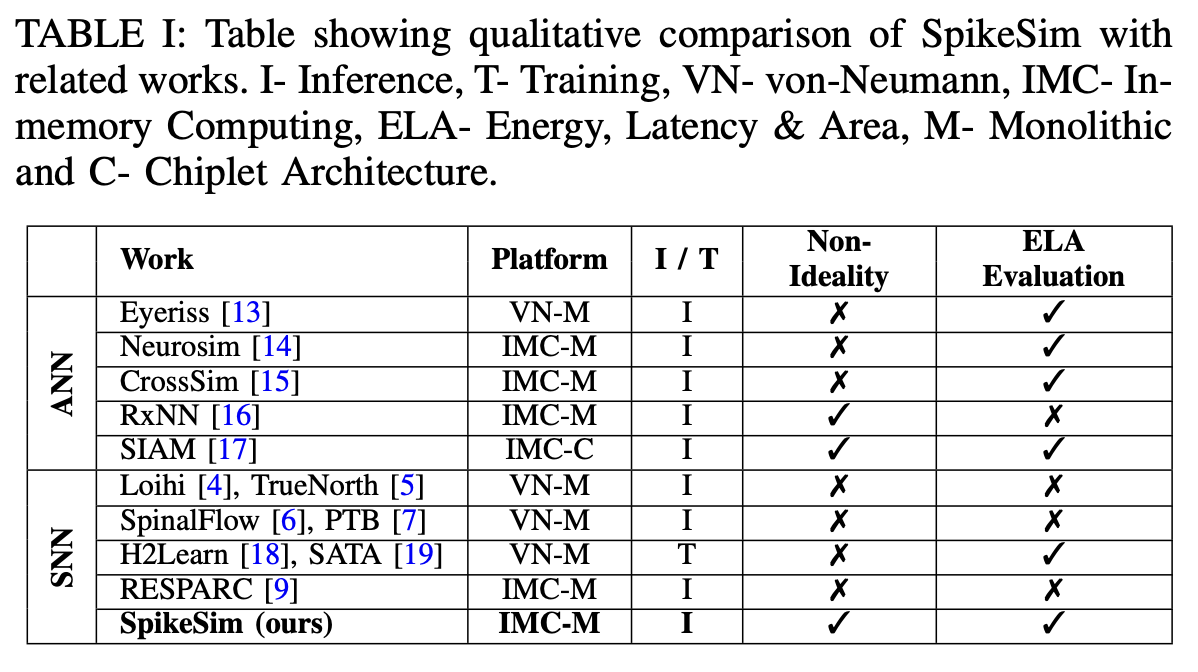
目前的IMC已经有一部分工作评估在IMC上运行ANN了,但是对于SNN这样的工作还存在一些缺陷,因为它们缺乏时间脉冲处理和非线性激活函数(如LIF/IF)所需的关键架构修改。在SNNs的硬件评估平台方面,已经提出了一些工作,用于在数字CMOS平台上基准测试SNN训练。此外,还有研究提出了用于SNN推断的IMC架构。然而,它们缺乏一些实际的架构考虑,如模拟MAC计算中产生的非理想性、数据通信开销等,使得它们不适合进行IMC映射SNNs的全面硬件评估。所有这些在表I中进行了定性比较和对比。因此,在当前文献中,存在SNN算法设计与硬件现实基准测试这些算法的全面评估平台之间的明显差距。
Contribution:
- 本文提出SpikeSIM,对SNN进行端到端的硬件评估工具。SpikeSIM包括一个大型的IMC-based tiled hardware architecture称为SpikeFlow,可以将SNN映射到非理想的模拟crossbar电路上。在SpikeFlow中,我们结合了SNN特有的非线性激活函数,如LIF/IF神经元,并利用二进制脉冲输入数据提出了一个轻量级模块(DIFF模块),以便在不需要传统双交叉阵列方法的情况下促进有符号MAC操作。
- 为了进行硬件现实SNN推断性能基准测试,我们开发了非理想性计算引擎(NICE)。NICE结合了非理想性感知的权重编码,以提高SNNs在模拟交叉阵列上映射时的鲁棒性。NICE利用电路分析方法实现非理想MAC操作,并提供硬件现实的SNN推断性能。此外,我们设计了一个能源-延迟-面积(ELA)引擎,来基准测试SpikeFlow映射SNN的硬件现实能源、延迟和面积。
- 在CIFAR10、100、TinyImagenet上广泛测试了SpikeSIM,并发现神经元模块占用了总芯片面积的显著部分(11 - 30%),这是由于在时间步之间需要存储大量膜电位。
- 在试验中发现,简单的SNN修改就能将神经元模块的芯片面积开销减小1.24倍,并将能源延迟产品(EDP)提高10倍。此外,我们还展示了非理想性感知的权重编码比起传统权重编码,能够提高映射到SpikeFlow架构上的SNN准确性超过70%(针对CIFAR10数据集)。
- 我们比较了映射到交叉阵列上的VGG9 ANN和在CIFAR10数据集上训练的SNNs的性能以及面积和能源分布。我们发现,与ANNs相比,SNNs的神经元模块面积高出约1000倍,且在小时间步(T =3,4,5)值下,与4位ANNs相比,SNNs可以实现相同的性能,并具有更高的能源效率和吞吐量优势。
2. Related Works
2.1. Hardware for ANN Inference
Eyeriss, ISAAC, PUMA, Neurosim, SIAM.
While the above works provide state-of-the-art evaluation platforms for ANN accelerators, they are insufficient for accurate SNN evaluation as they lack critical architectural modifications required for temporal spike data processing and LIF/IF activation functionalities.
2.2.. Hardware for SNN Inference
SpinalFlow: tick-batched dataflow to achieve higher energy efficiency and lower hardware overheads.
RESPARC: analog crossbar-based, higher energy efficiency due to the event-driven communication and computation of spikes. Overlooked the underlying hardware overheads for event-driven communication and the effect pf analog crossbar non-idealities on SNN performance.
3. Background
3.1. Spiking Neural Networks
Leak-Integrate-and-Fire(LIF) neuron formula:
:神经元i,j之间连接的权重;:leak factor。
这种不可微分性意味着需要其他的训练方法,已经提出的方法包括:
- ANN-SNN conversion:先训练ANN,然后利用LIF/IF模拟RELU,将训练好的ANN转化为SNN。可以利用已有的ANN训练相关的技术。
- Surrogate gradient learning:似LIF/IF神经元的反向梯度函数来解决非可微分问题。替代梯度学习可以直接从脉冲中学习,在较少的时间步数内完成。
在Surrogate learning上,关于如何编码输入数据又可以分成Direct Encoding和Rate Encoding两种:
- Rate Encoding利用泊松分布编码,将输入数据转换成随机分布的spike。
- Direct Encoding直接利用从数据中多个time step提取的特征作为输入。
目前看来是Direct Encoding可以用更少的time step取得更好的训练效果。
3.2. Analog Crossbar Arrays and their Non-idealities
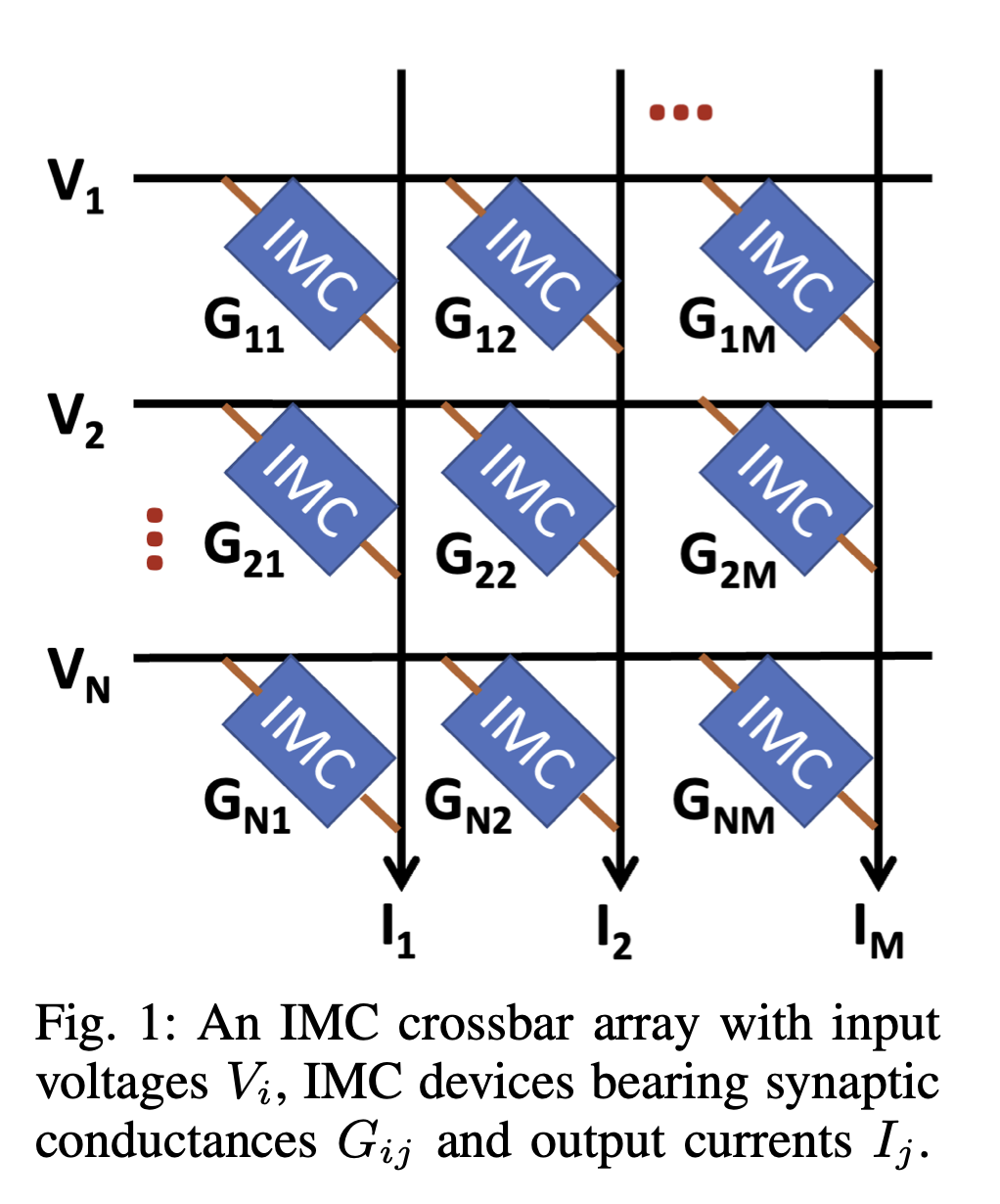
神经网络的激活输入作为模拟电压Vi输入到交叉阵列的每一行,权重则作为突触器件的电导(Gij)在交叉点编程,如Fig1所示。在理想的N×M交叉阵列推断过程中,电压与器件电导相互作用并产生电流(由欧姆定律控制)。
理想情况下,输出是。但实际上,由于寄生电阻或者其他的因素,电导可能和理想中的不同,这会导致实际输出的电流与理想状况下不同,导致某些神经元可能不能正确地产生脉冲,这会导致SNN出现巨大的精度损失。更大的crossbar电路会有更高的“non-idealities”,对应的SNN就会有更高的精度损失。
4. SpikeSIM
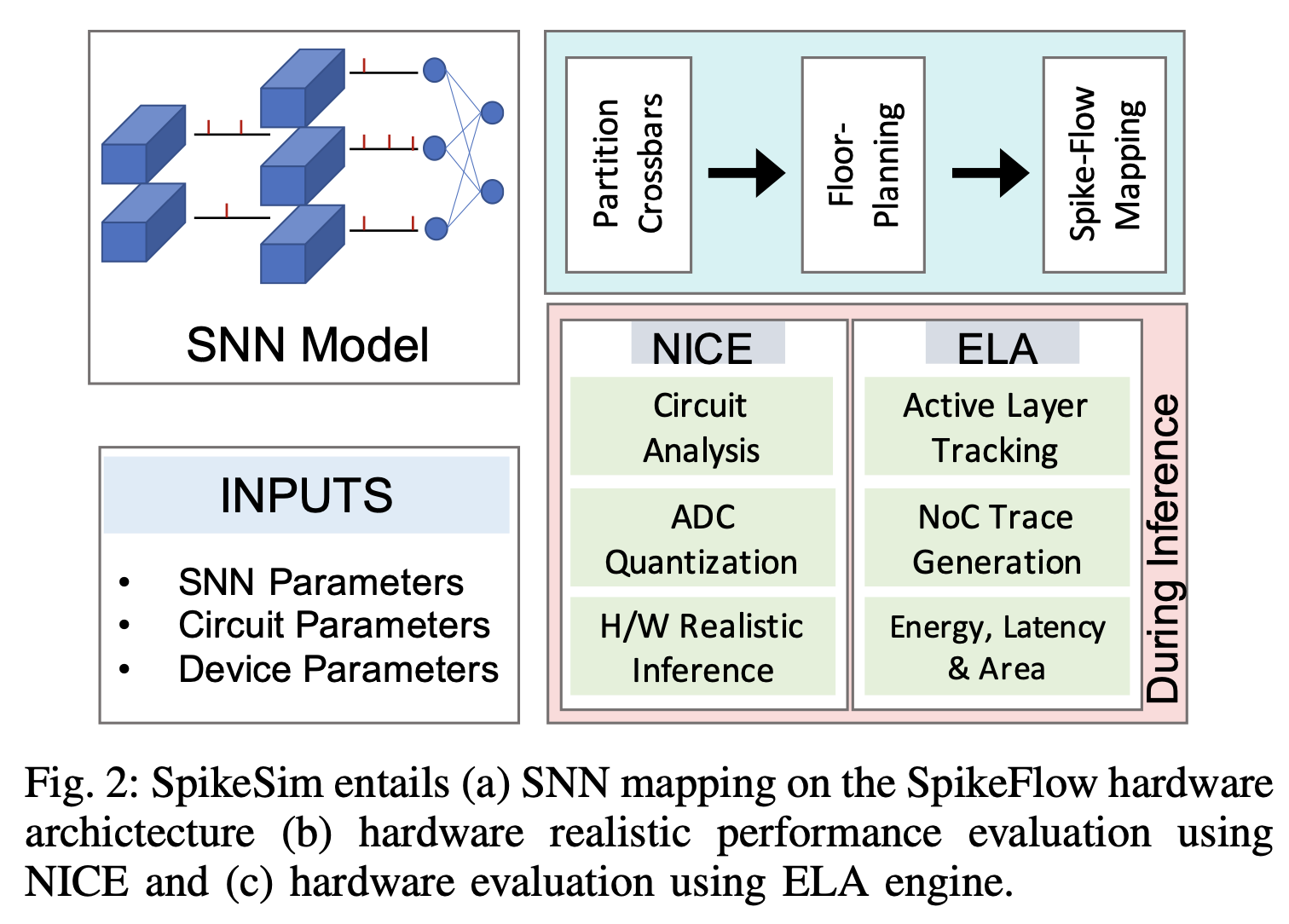
主要分三部分:
- SpikeFlow Mapping:如何把SNN映射到硬件上
- NICE,Non-Ideality Computation Engine:利用包括电路分析和ADC量化的方法分析一个SpikeFlow like的SNN的实际performance
- ELA Engine:计算energy、latency、area等信息
4.1. SpikeFlow Architecture
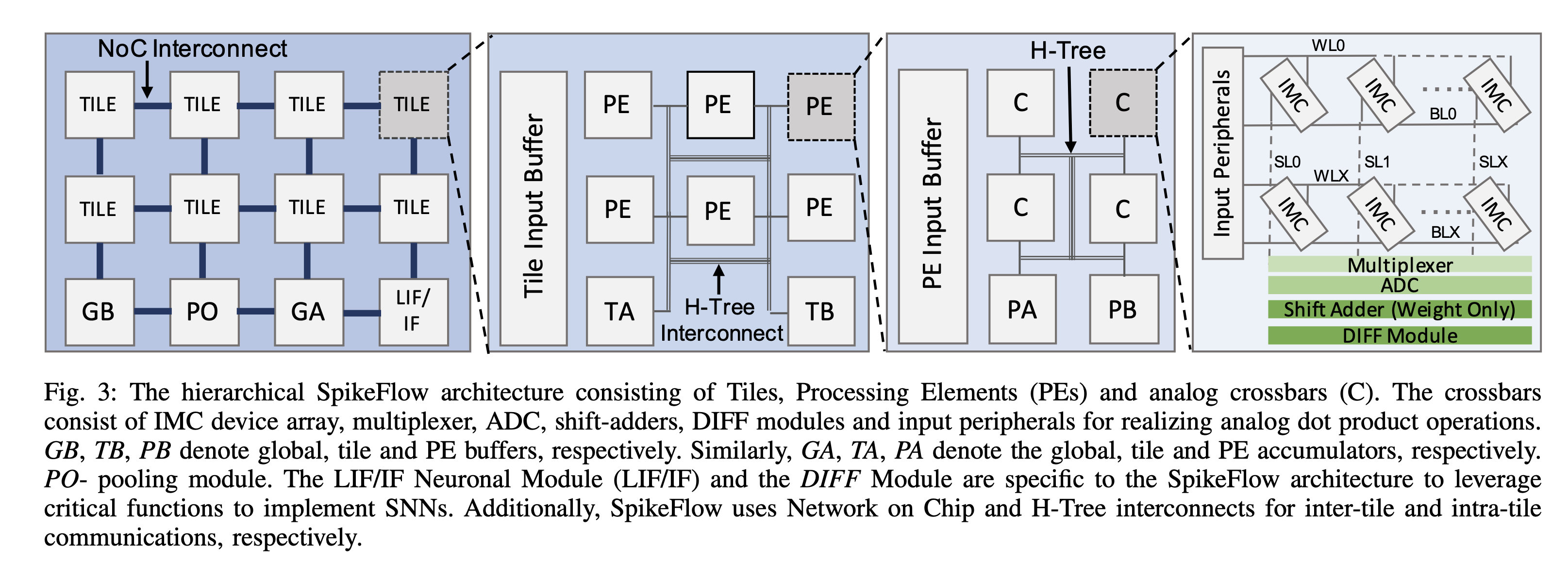
分层设计,顶层是global Buffer,pooling module,global accumulator,IF神经元等,通过NoC和大量TILE互联;一个tile中包含若干H tree连接的PE和input buffer,tile accumulator,tile buffer;PE中包含一个PE input buffer和accumulator,以及多个analog crossbar;crossbar中就是前面的那种电路结构。
- Shift-and-Add circuit are incorporated to support bit-splitting of weights = bit serial?
Typically, crossbars in ANNs require separate Shift-and-Add circuit to support input bit-serialization and bit- splitting for weights. Due to the binary spike input, SpikeFlow only requires shift-and-add circuit to support weight splitting and not input serialization. Additionally, binary spike data allows replacing the traditional dual crossbar approach for performing signed MAC computation with fully digital DIFF modules which reduce SpikeFlow’s crossbar area significantly compared to ANN crossbars.
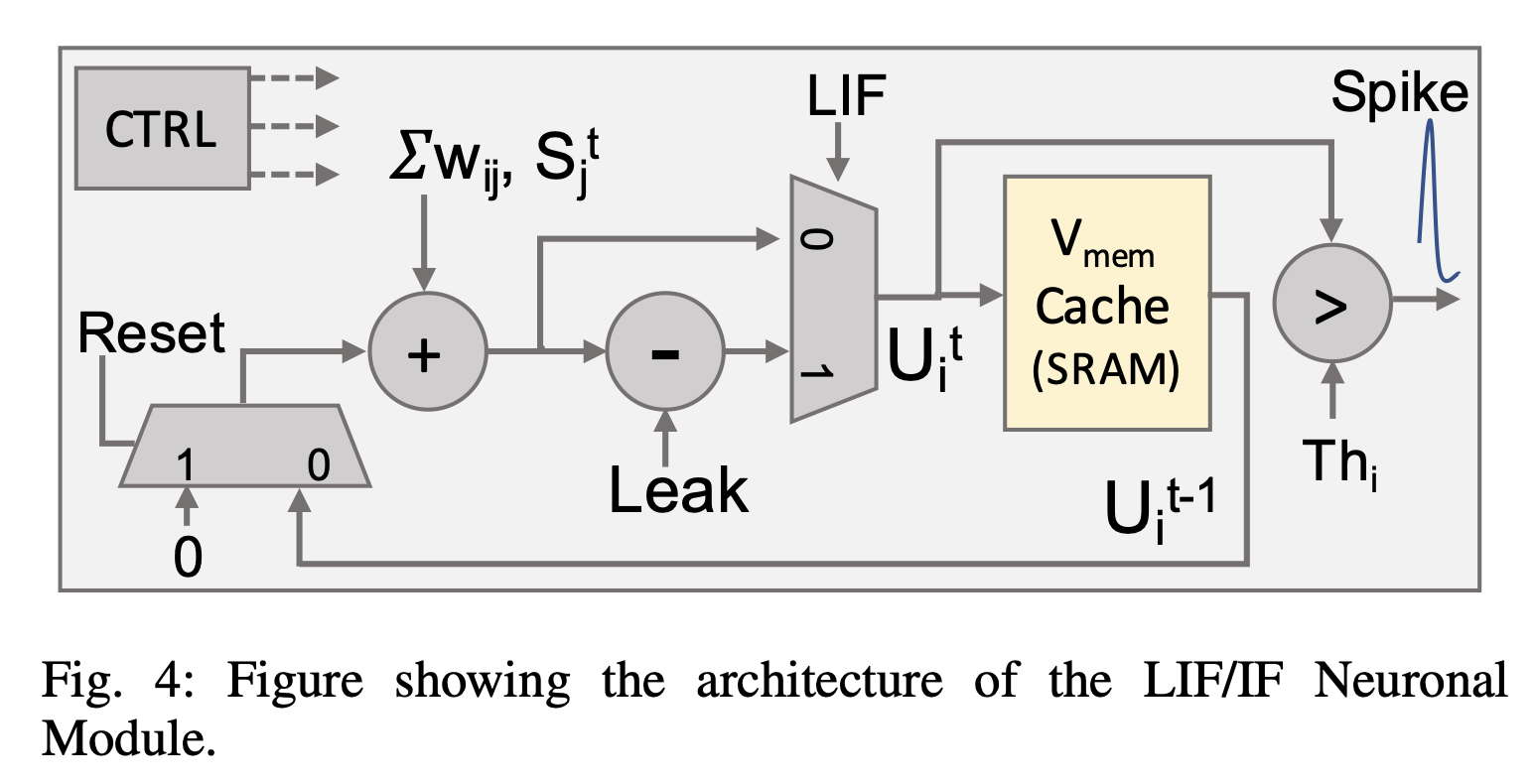
Note, that the Vmem Cache is an SRAM memory required to store the membrane potentials over multiple time-steps. As we will see in Section V-D, has a significant contribution to the overall hardware overhead in SpikeFlow.
Mapping SNNs onto SpikeFLow: mapping strategy like Neurosim for partitioning and mapping the pre-trained software SNN weights.
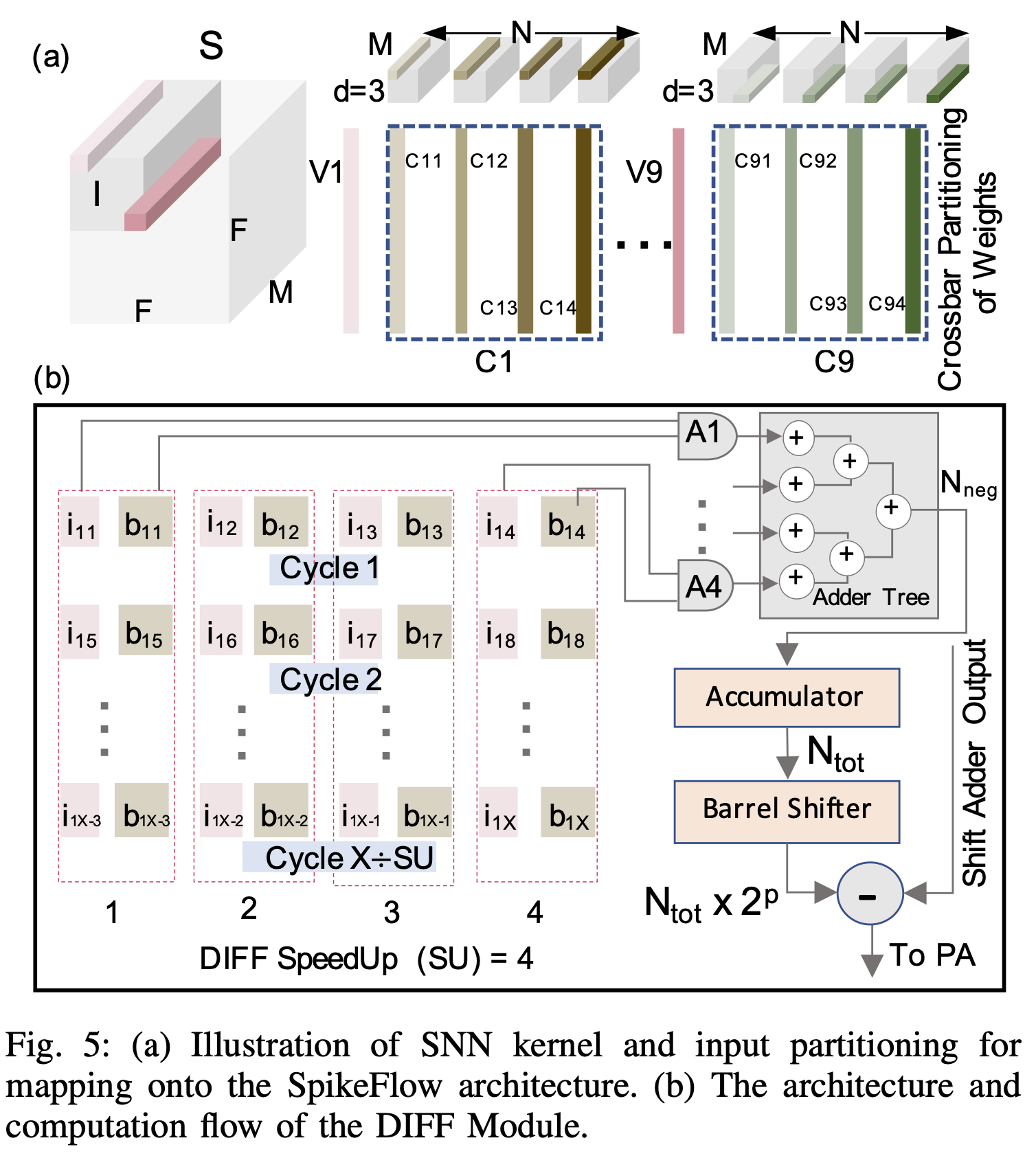
Here, N and M are the output and input channel dimensions, respectively and d is the kernel dimension. The weight kernels are partitioned along the input channel (M) dimension and mapped along a crossbar column. While, the corresponding weights along the output channel dimension (N) are mapped on different columns of the same crossbar. The weights along the d × d dimensions are mapped on different crossbars. Hence, for a d= 3 kernel, 9 crossbars (C1-C9) are required. A similar partitioning is applied to the spike input map S over the M×d×d section. This mapping strategy maximizes input data reuse and minimizes the buffer access.
基本上就是把input kernel展平?
4.2. NICE: Non-ideality Computation Engine
直接把传统的SNN权重部署到crossbar上,会因为crossbar本身的非理想性(比如寄生电阻等)导致实际输出和理想值不同,掉点严重。

主要思想包括两个:
- 将负的权重通过映射到正的部分上,这样会增大整个电路的电阻,减少寄生电阻的产生
- 在计算的时候附加一个正态分布的随机噪声,然后通过调整weight减少噪声对系统输出的影响
4.3. ELA Engine
好像实际上做的事情是一般的Energy&Area Evaluation都会做的
5. Experiment and Result
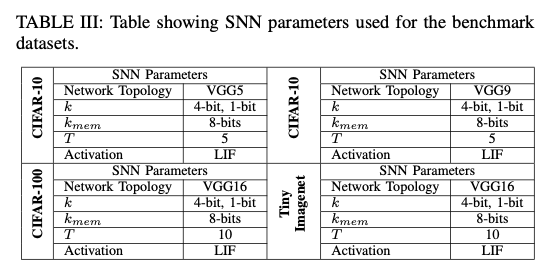
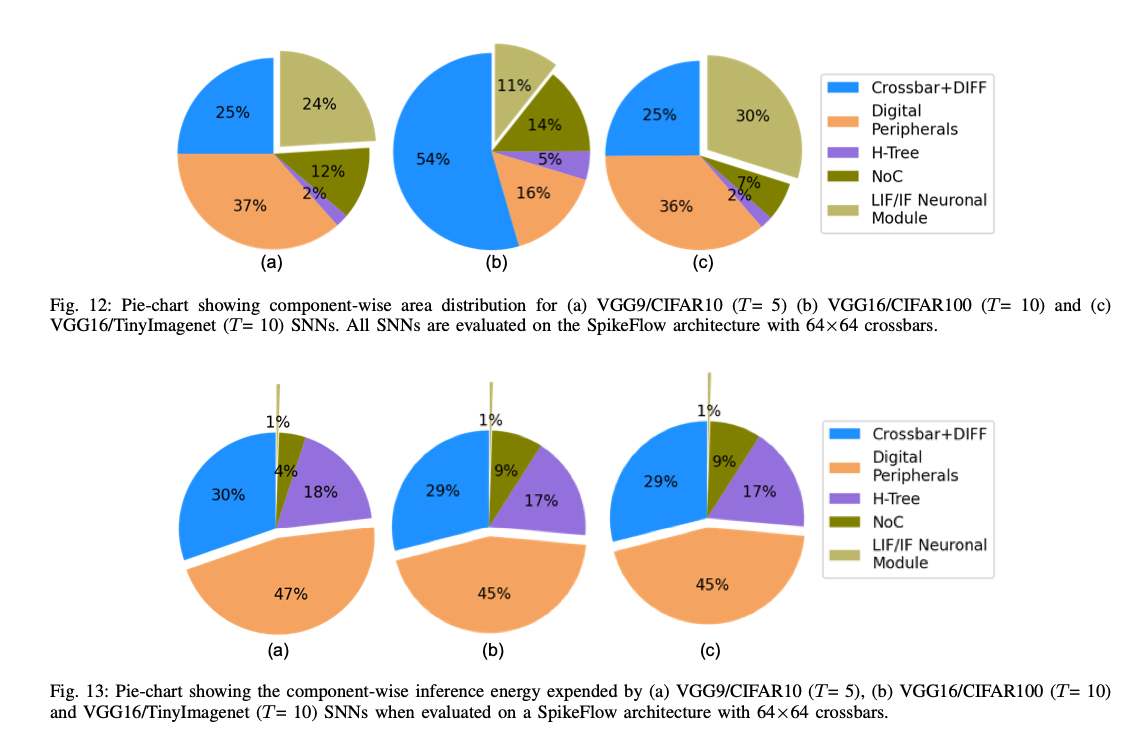
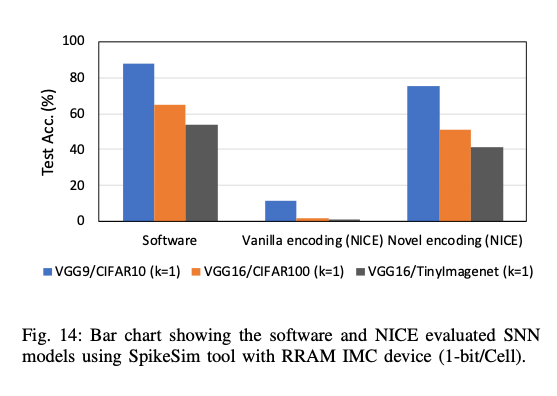
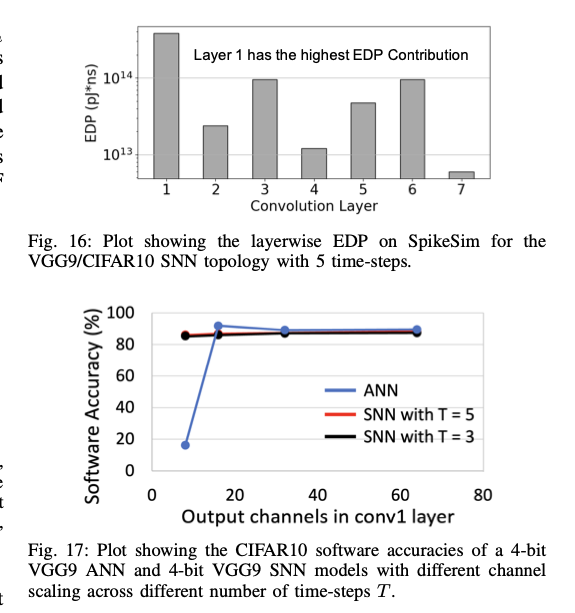
6. Comparison between ANN and SNN
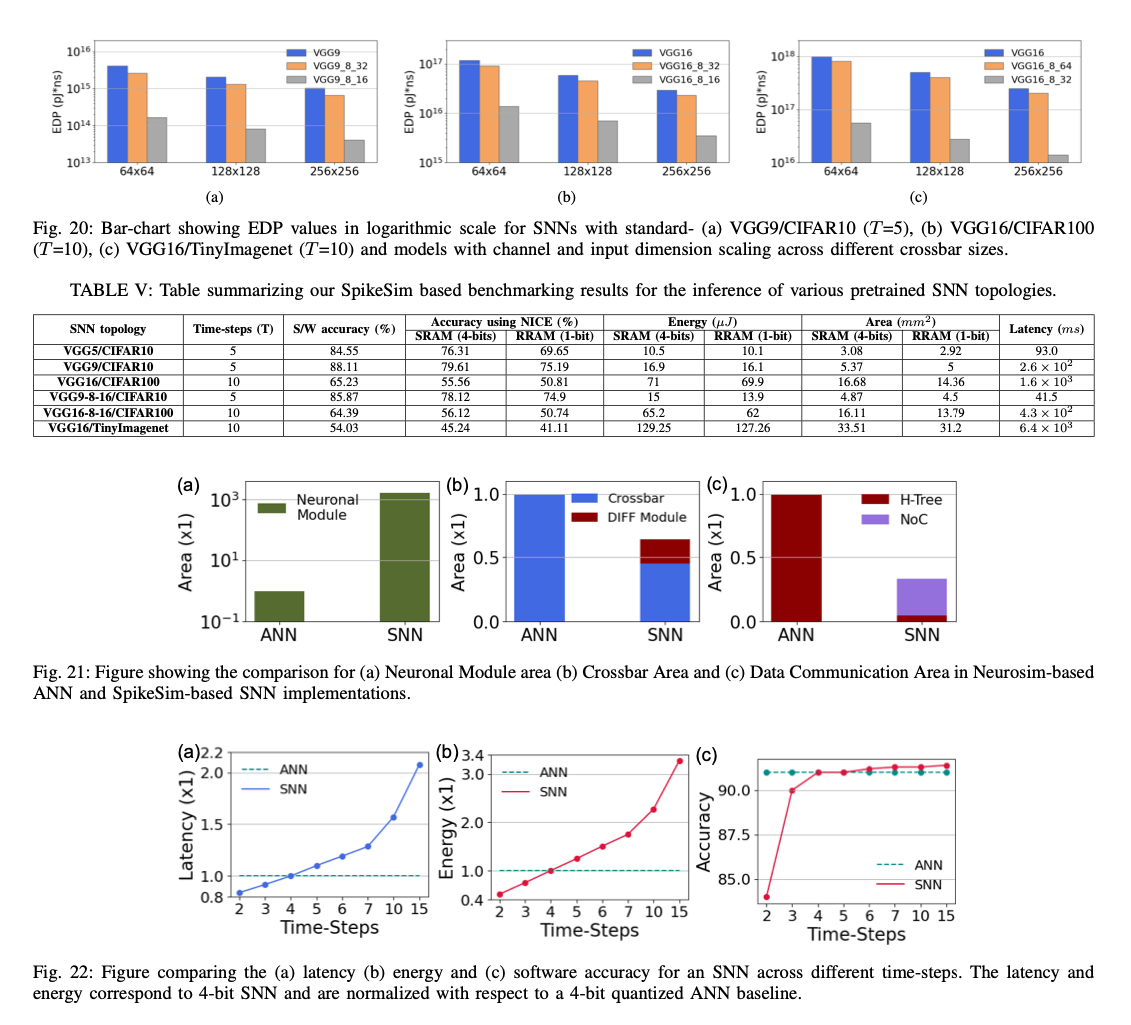
几个重点:
- SNN中的IF模块比ANN的RELU大将近100倍,因为里面的要有SRAM存对应的数据
- 低Time-Step的时候,SNN可以取得更好的latency和energy表现,但是高time step的时候SNN的精度表现才会好