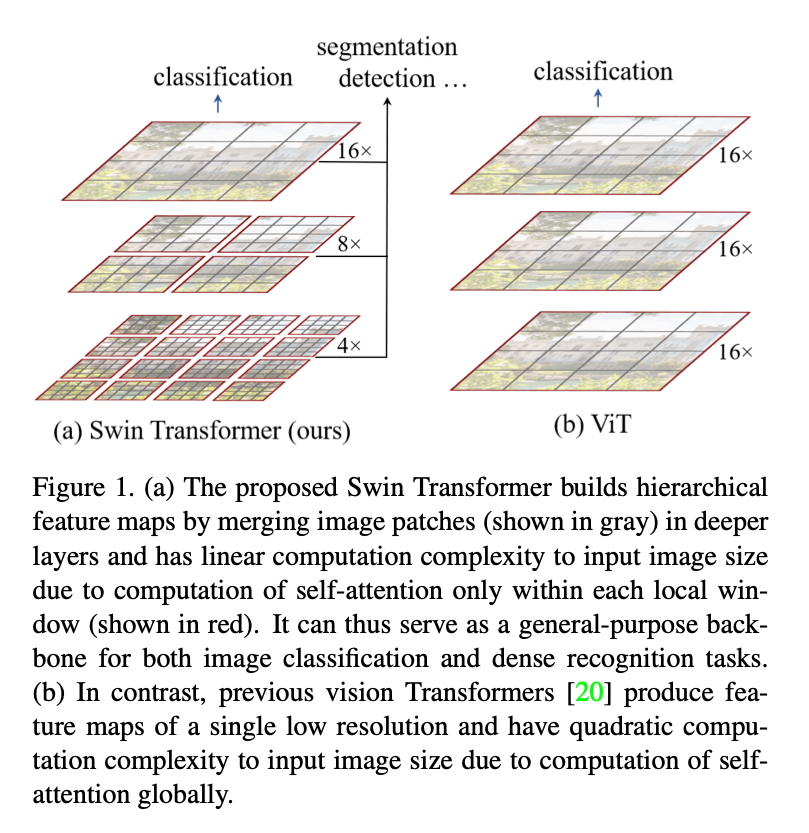
摘要: 本文提出了一种新的视觉 Transformer —— Swin Transformer,能够作为通用视觉主干网络。将 Transformer 从自然语言迁移到视觉领域时面临诸多挑战,原因在于两者差异巨大:视觉实体的尺度变化大,且图像像素的分辨率远高于文本中的字词。为应对这些差异,我们提出了一种 分层式 Transformer,其特征表示通过 滑动窗口(Shifted Windows) 计算而得。滑动窗口方案通过将自注意力计算限制在不重叠的局部窗口内,同时允许跨窗口信息交互,带来了更高的效率。该分层架构能够灵活地在不同尺度上建模,并且其计算复杂度随图像尺寸呈线性增长。凭借这些特性,Swin Transformer 可广泛应用于多种视觉任务:图像分类:在 ImageNet-1K 上取得 87.3 的 Top-1 准确率;目标检测:在 COCO test-dev 上实现 58.7 的 box AP 和 51.1 的 mask AP;语义分割:在 ADE20K val 上达到 53.5 的 mIoU。与此前的最新方法相比,Swin Transformer 在 COCO 上分别提升了 +2.7 box AP 和 +2.6 mask AP,在 ADE20K 上提升了 +3.2 mIoU,充分展示了基于 Transformer 的模型作为视觉主干的潜力。分层设计和滑动窗口策略同样对纯 MLP 架构有益。代码与预训练模型已在 GitHub 开源:https://github.com/microsoft/Swin-Transformer 。
1. Intro
是ViT学习CNN中技术的进一步。注意到ViT的效果和最佳的CNN相比还是有一些差异,作者认为语言模态和视觉模态的差异主要有:
- 尺度差异:视觉元素的尺度变化比语言中的变化显著很多,在目标检测这样的任务中这种差异会很显著,而Transformer-based的工作中token对应的大小是固定的,和这种尺度差异之间有区别;
- 分辨率差异:图像的像素分辨率远高于文本中的token,而语义分割这样的任务需要像素级的密度,的复杂度很难应对这种计算密度。
为了解决这种问题,Swin Transformer分层构建Attention,在不重叠的位置中计算Attention,同时在不同的层中引入不同的尺度,
2. Related Work
- CNN and variants, “虽然 CNN 依旧是大多数视觉应用的核心骨干,本工作强调 Transformer 类架构在视觉与语言统一建模中的巨大潜力 。我们的模型在多项基础视觉识别任务上取得了强劲表现,希望能推动社区向新的建模范式转变。”
- Self-attention based backbone architectures
受 NLP 领域自注意力层与 Transformer 架构成功的启发,一些研究尝试以自注意力层替换 ResNet 中部分或全部空间卷积层。这些方法通常在 像素级局部窗口 内计算自注意力以降低优化难度,在准确率与 FLOPs 的权衡上略优于对应的 ResNet。然而,频繁的内存访存导致其 实际推理时延 远高于卷积网络。与滑动窗口不同,本文提出在相邻层之间平移窗口划分,从而在通用硬件上实现更高效的推理。
- Self-attention/Transformers to complement CNNs
- Transformer based vision backbones
ViT 将 Transformer 直接应用于 非重叠中等尺寸的图像 patch ,在图像分类任务上展现出令人瞩目的速度–准确率折中。尽管 ViT 需要诸如 JFT-300M 这类超大规模数据集以发挥优势,DeiT提出的若干训练策略则使 ViT 在规模较小的 ImageNet-1K 上同样有效。尽管 ViT 在图像分类领域取得了鼓舞人心的成果,其 低分辨率特征图 与 随图像尺寸二次增长的计算复杂度 令其难以作为高分辨率输入或密集视觉任务的通用骨干。有少量工作通过直接上采样或反卷积将 ViT 应用于目标检测与语义分割,但性能相对有限。与本文并行的研究对 ViT 架构进行了改良以提升分类性能;实验证明,即便我们更关注通用视觉任务而非单纯分类,Swin Transformer 在速度–准确率折中方面依旧优于这些方法 。另一项并行工作亦探索在 Transformer 中构建多分辨率特征图,但其复杂度仍与图像面积成二次关系;相比之下,Swin Transformer 的复杂度线性于图像大小,并采用局部操作,符合视觉信号高度相关性的建模需求 。因此,我们的方法在效率与效果上兼具优势,在 COCO 目标检测与 ADE20K 语义分割任务上均取得了 ** 最新的最佳性能**。
3. Method
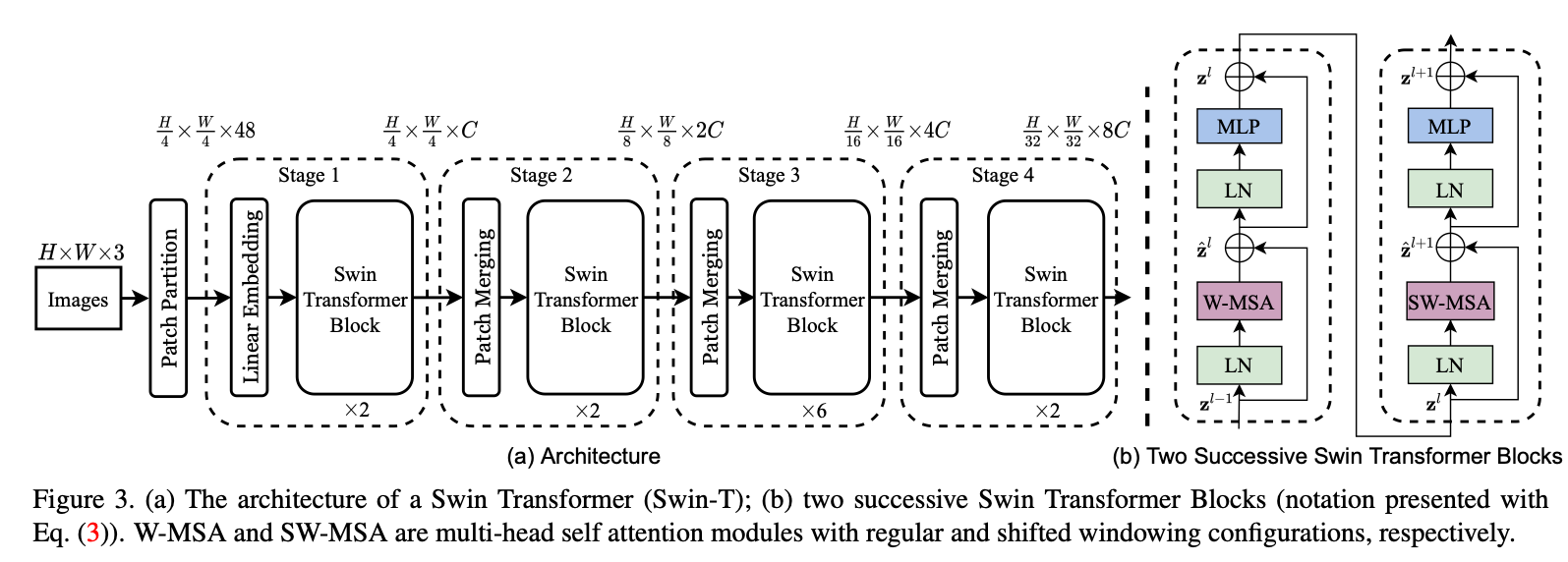
3.1. Overall Architecture
与 ViT 相似,输入 RGB 图像首先通过 Patch Splitting 模块被切分成 非重叠 patch。每个 patch 视为一个 token,其特征为原始像素 RGB 值的串联。文中默认 patch 大小为 ,故 patch 维度为 。接着使用 线性嵌入层 将 48 维特征投影至任意维度 。
随后,对这些 patch token 叠加若干 Swin Transformer Block。线性嵌入层加这些 block 组成 Stage 1,其 token 数保持 。
为获得分层表示,网络越深 token 数越少——在 Patch Merging 层中,每 相邻 patch 的特征被串接并映射:,令 token 数降为 1/4(分辨率 下采样)。随后继续堆叠 Swin block,分辨率固定在 ,构成 Stage 2。同样的模式再重复两次,形成 Stage 3()与 Stage 4(),最终得到 分层金字塔特征。
Swin Transformer Block
用Shifted-Window MSA替换标准的MSA,其余相同。每个Block中包含一个SW-MSA,一个两层MLP,中间GELU,每个子模块前置LayerNorm,后接残差连接。
3.2. Shifted Window Self-Attention
Self-attention in non-overlapped windows
假设图像含个patch,每个patch,则:
可以注意到后者在固定的时候随图像尺寸线形增加。
Shifted window partitioning in succesive blocks
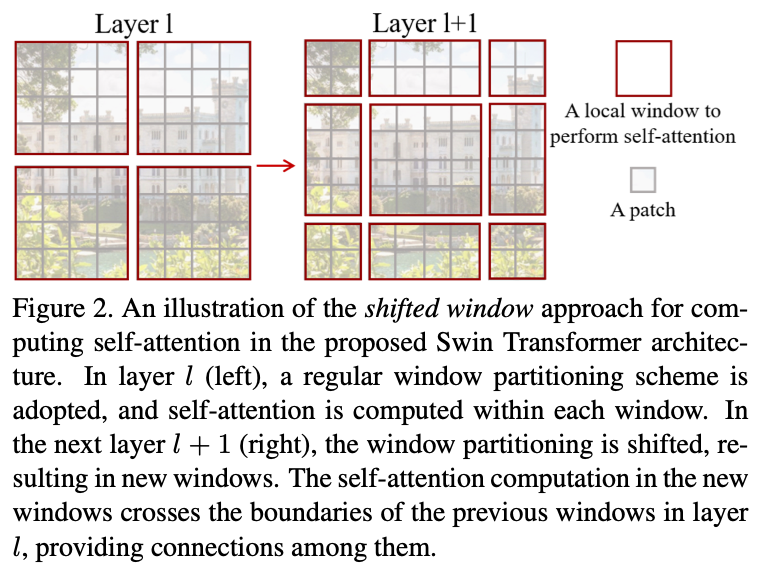
纯粹的non-overlapped windows缺乏窗口之间的信息,Swin-Transformer交替使用shifted window partitioning approach, 每次让patch平移,形成两种不同的window分布模式,分别称为常规窗口(W-MSA)和移位窗口(SW-MSA):
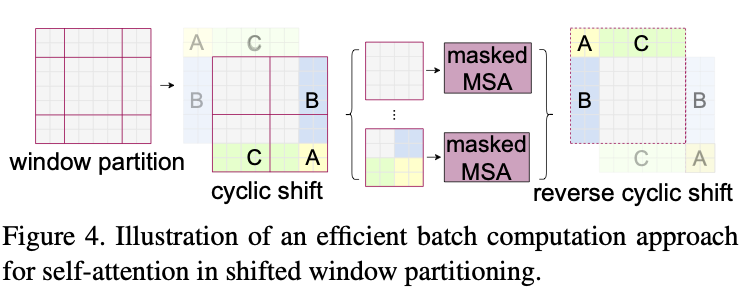
Efficient batch computation for shifted configuration
移位之后窗口数量从增加到,会增加计算量。本文采用cyclic-shift到左上角,再用mask限制注意力到自己的子窗口,从而保持窗口总数不变。
Relative position bias
每个head引入relative postion bias:
轴向位移范围,仅学习的紧凑矩阵,按照位移索引到,实验中显著优于无Bias和绝对位置潜入。预训练得到的可以经过双三次差值迁移到不同的window大小。
3.3. Architecture Variants
- Swin-T: , layer numbers =
- Swin-S: , layer numbers =
- Swin-B: , layer numbers =
- Swin-L: , layer numbers =
Window size, 每个head的维度, MLP的扩张倍率
4. Experiments
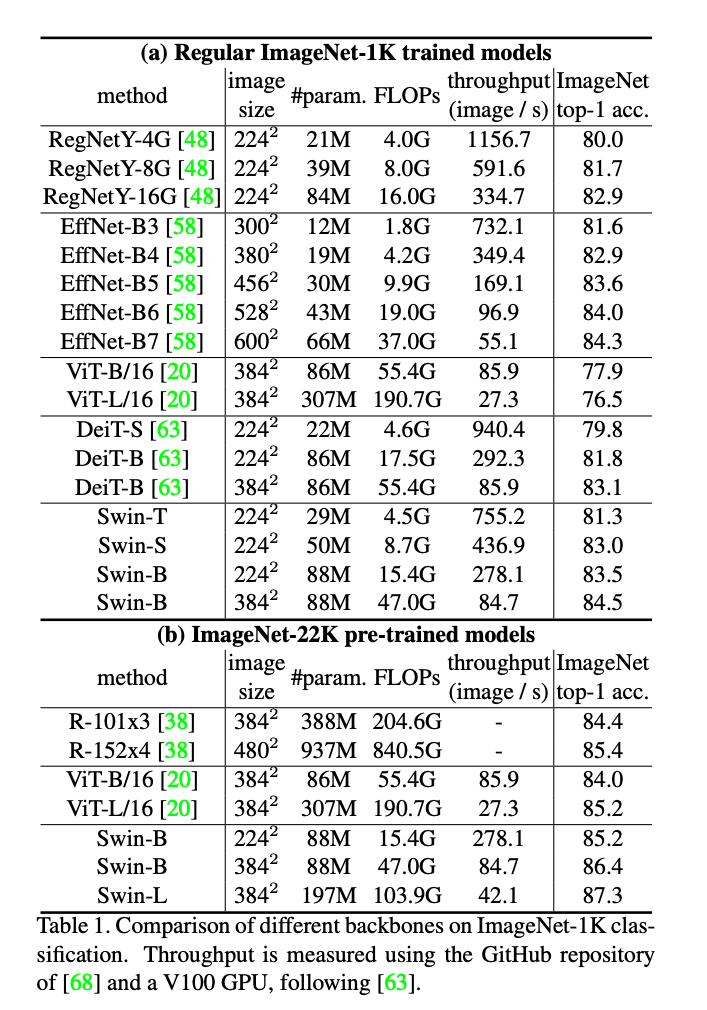
4.1. Image Classification on ImageNet-1k
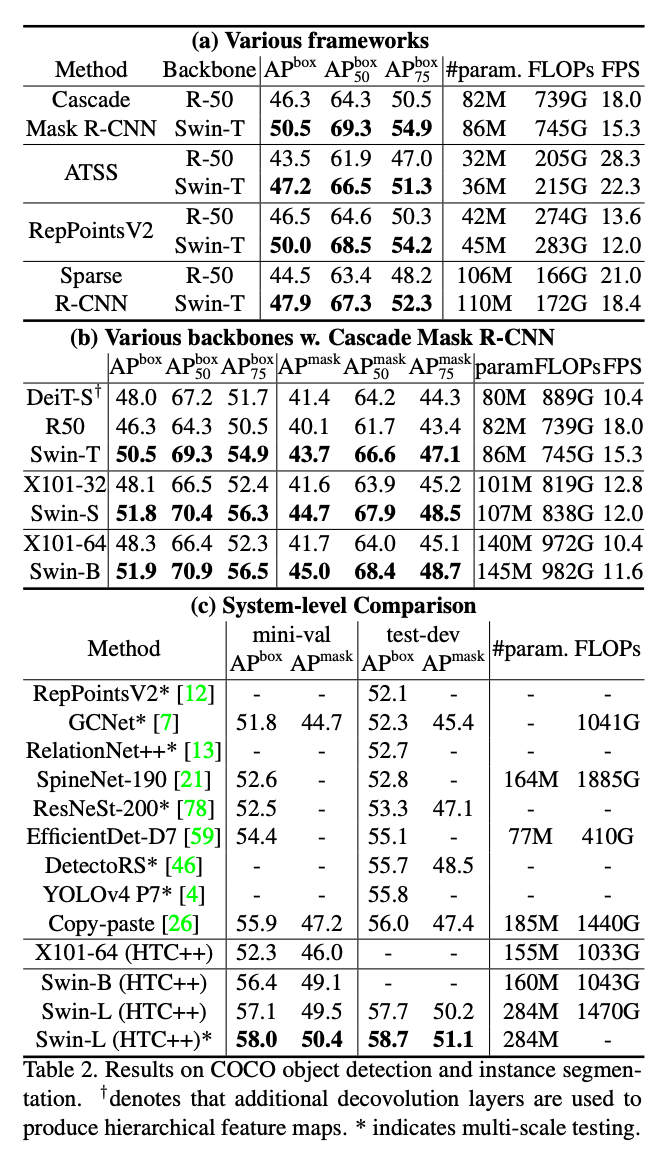
4.2. Object Detection on COCO
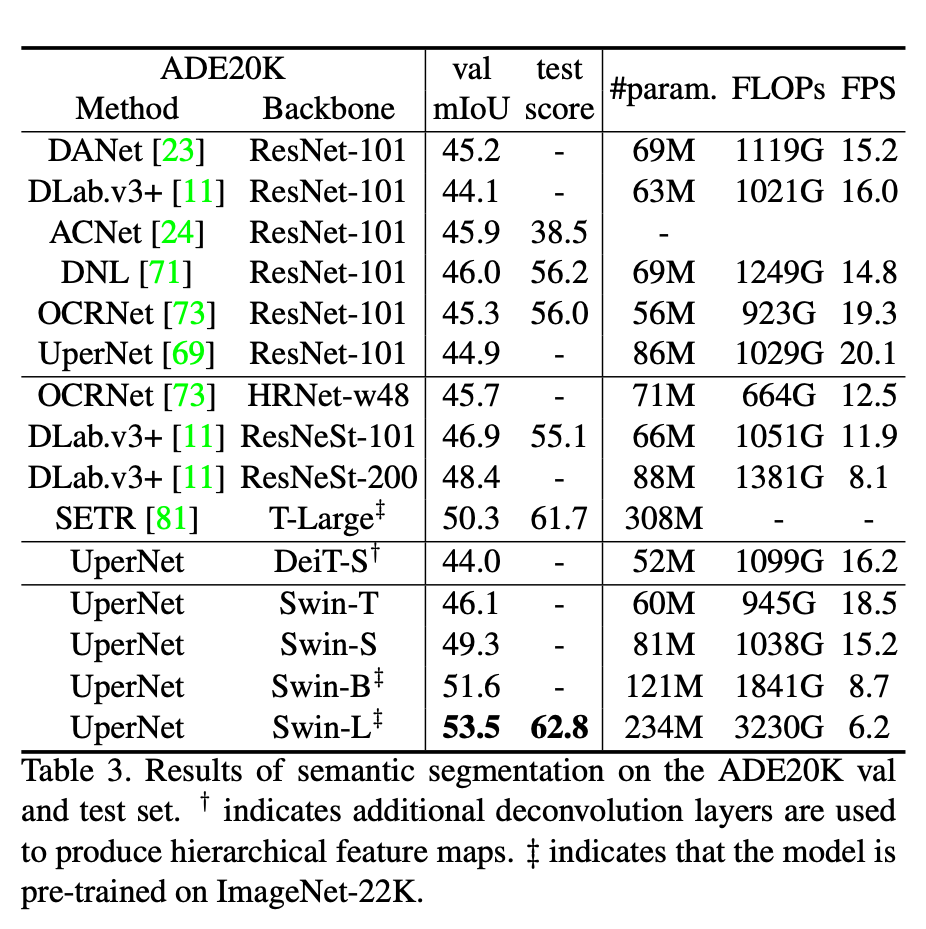
4.3. Semantic Segmentation on ADE20K
4.4. Ablation Study
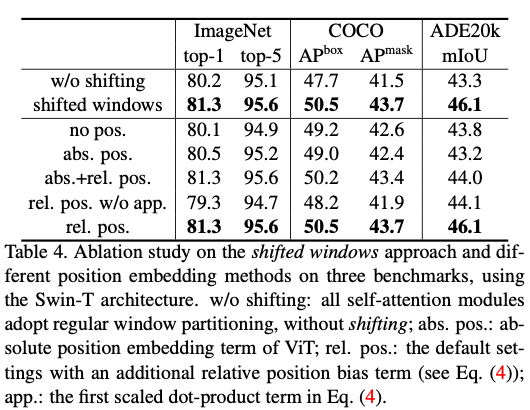
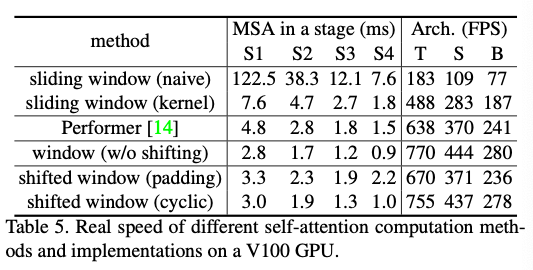
相比而言主要是线性增加的计算量带来的speed up,同时点数也有提升。
5. Conclusion
本文提出 Swin Transformer —— 一种新的视觉 Transformer,能够生成 分层特征表示,其计算复杂度对输入尺寸呈 线性。Swin Transformer 在 COCO 目标检测与 ADE20K 语义分割上均取得 最新 SOTA,显著超越此前方法。我们希望其在多项视觉任务上的优异表现,能进一步推动视觉与语言信号的统一建模。作为核心贡献,移位窗口自注意力 被证明在视觉任务中既 高效 又 有效;未来将探索其在自然语言处理中的潜力。