摘要: 脉冲神经网络在多种视觉任务中已表现出与人工神经网络相当的性能,同时具备更优的能效。然而,现有基于 SNN 的 Transformer 主要聚焦于单幅图像任务,强调空间特征,而未能充分利用 SNN 在视频视觉任务中的效率优势。本文提出了一种高效的脉冲驱动视频 Transformer——SpikeVideoFormer,其时间复杂度为线性 。具体而言,我们设计了脉冲驱动汉明注意力(Spike-Driven Hamming Attention, SDHA),在理论上实现了从传统实值注意力到脉冲驱动注意力的无缝转换。基于 SDHA,我们进一步分析了多种脉冲驱动的时空注意力结构,并确定了一种在保持线性时间复杂度的同时,能为视频任务提供优异性能的最优方案。SpikeVideoFormer 在视频分类、人体姿态跟踪和语义分割等多种下游视频任务上展现了出色的泛化能力与高效率。实验证明,与现有 SNN 方法相比,我们在后两项任务上取得了超过 15% 的性能提升;同时在保持与最新 ANN 方法相当精度的情况下,效率分别提升 ×16、×10 和 ×5。
1. Intro
主要讲SNN的Energy Efficiency来自于加法&稀疏。注意到现在的SNN主要是做单帧的静态输入,但是一直在claim SNN具有时空数据敏感的特征,因此认为SNN应当适合视觉任务。
SNN迁移到Video Task上的主要Challenge:
- 现在的Spike Attention集中沿用ANN中的点乘操作,不一定能够刻画Spike之间的相似性(见下图,比如两个Spike Seq之间因为Spike错开而形成0,但两者不一定就完全不相关);
- 这些Attention都是Space上的而不是Temporal上的。
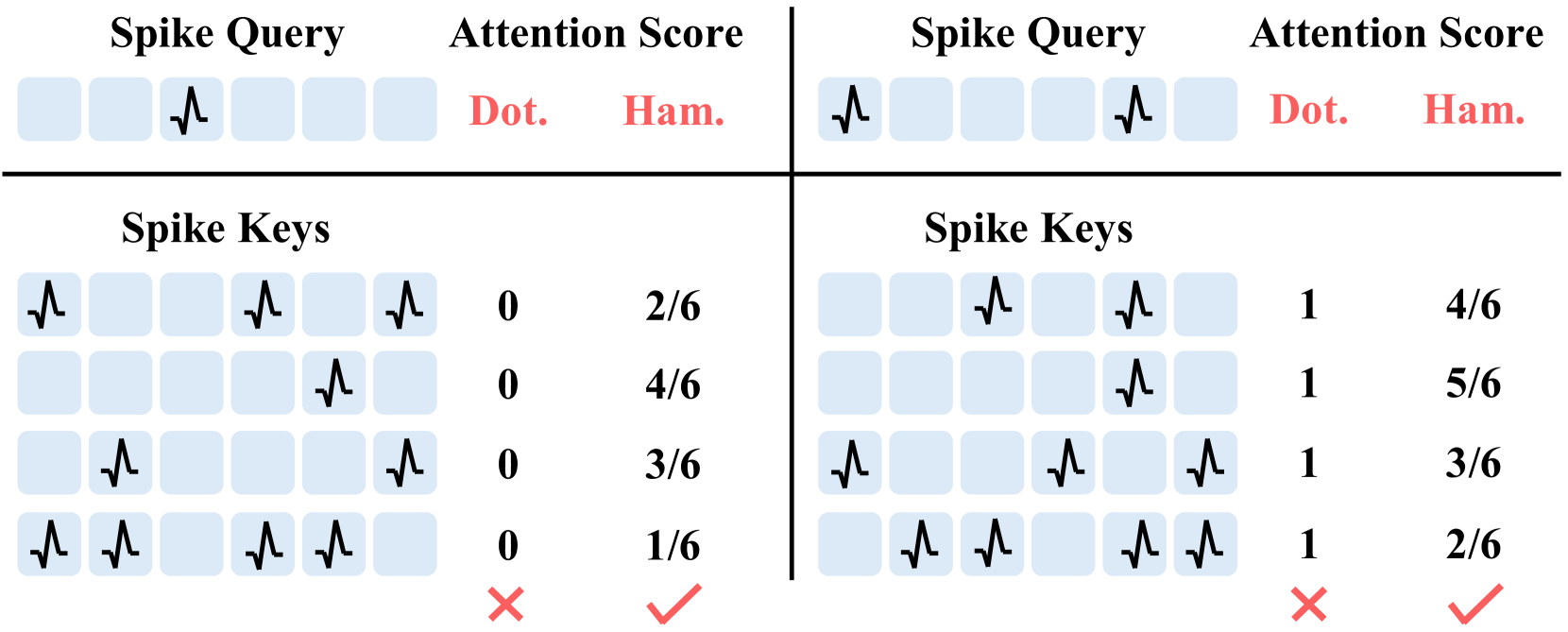
为了解决这个问题,文章的核心是提出了一种基于汉明距离的注意力机制,然后考虑汉明相似度存在浮点计算、不可微分、非线性复杂度问题,又对这种注意力机制进行了改造。
2. Related Works
- CNN based SNN, 主要是BPTT,但是在超大规模上CNN有自己的固有问题,精度上不去
- Transformer based SNN, 前面说的那些问题,Spike模式错开导致不好用传统的Attention
- SNN in Vision Tasks, 主要是静态的
- Video Transformer,一种做法是直接把T也当一个batch,另一些做法是发明新的T Window + Time Attention
- Visual Cognitive Neuroscience,注意力、动机、情绪与预期等因素如何塑造视觉感知和认知,提的这一些论文不知道和主题有什么关系,凑字数?
3. Method
3.1. Spiking Neuron Model
用的LIF,记作
3.2. Spike-Driven Video Transformer
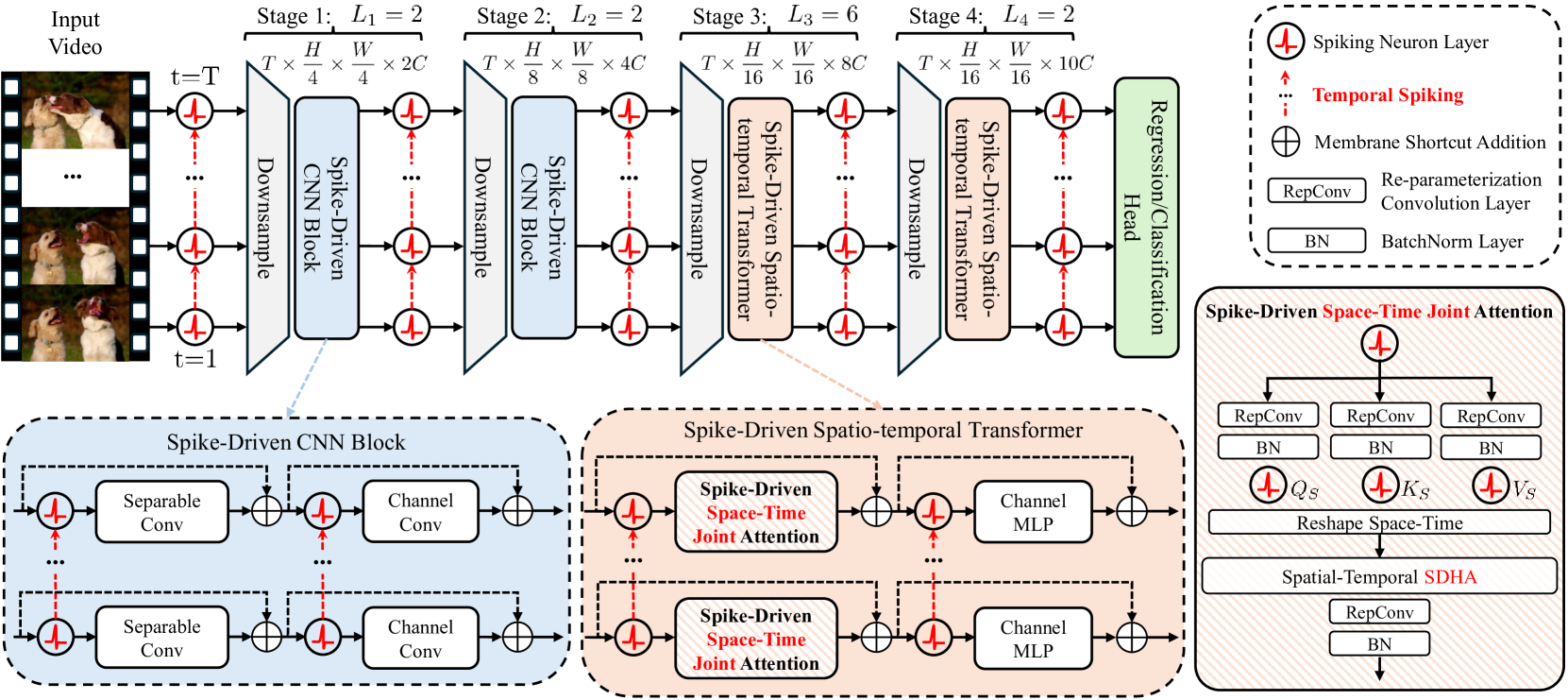
原始采样,首先经过下采样 + Spike化,变成,其中的每一个Conv Module实际上都包括一个DS Conv + 一个通道卷积:
:Point-wise卷积;:Depth-wise Seperatable卷积。
得到一个的输出,然后送入Spike-Driven Spatiotemporal Transformer:
是重参数化卷积。
3.3. Spike-Driven Hamming Attention (SDHA)
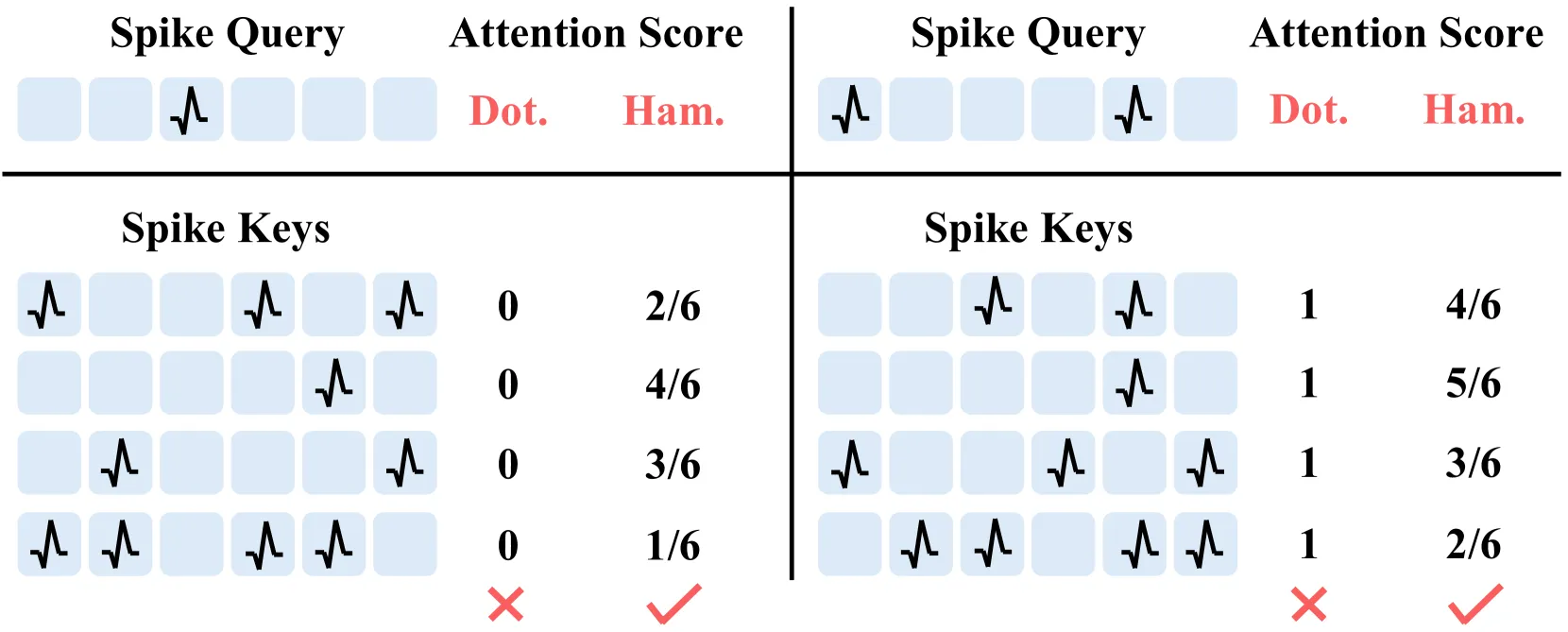
脉冲查询向量与脉冲键向量在使用 点积 与 归一化汉明相似度 时的注意力分数直观对比。查询向量某位为 0 时,点积会忽略对应键向量的该位,导致四个差异极大的键向量得到相同得分,暴露出点积对二值脉冲向量相似度刻画的不适用性。
Spike-Driven Self-Attention (SDSA)
是带有scaled threshold 的LIF Neuron。
然而,点积并不适合作为脉冲注意力中的相似度度量 。具体来说,当脉冲查询向量中含有零元素时,点积会无差别地忽略脉冲键向量对应位置的元素,容易造成特征消失或混淆。为直观展示这一问题,我们在图 2 中给出了两个示例:点积为四个差异显著的脉冲键向量得出了完全相同的分数。这说明SDSA所采用的点积无法准确反映两个二值脉冲向量之间的相似性。此外,式 (3) 中的阈值缩放因子只能凭经验设定,缺乏保证训练稳定性的明确指导。
Proposition 3.1: JL Lemma on Binary Embedding
设有:
分别是实数域上的Query和Key向量,对应的Binary Embedding为:
定义为:
投影矩阵:
给定任意且
有:
- 表示概率
- 是有限训练集中可能出现的Query/Key组合的总数
- ,满足连续且单调
- 是归一化汉明相似度
- 是余弦相似度。
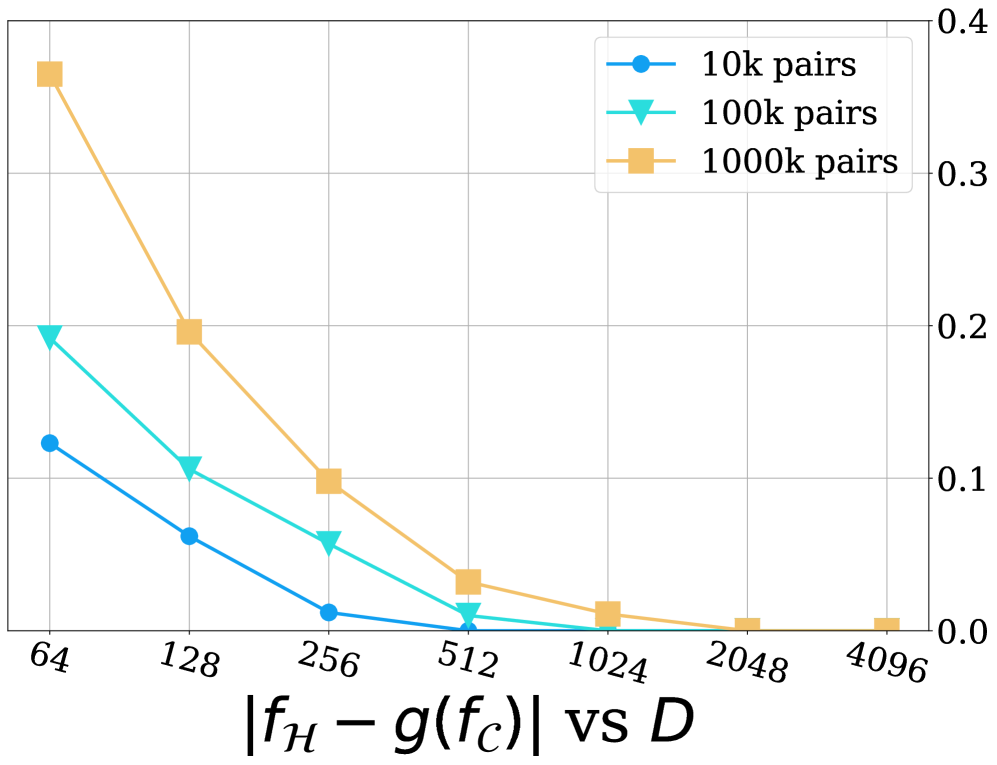
上面的定理实际上证明了,在channel size 足够大的时候,汉明相似度以高概率逼近,而是传统的余弦相似度。由于是连续且单调的,它相当于保持了原有的key-query之间的相似度排序。
进一步的实验证明:
Computational Efficiency Design
直接使用的做法的问题:
- 引入了浮点运算
- 有指示函数,不可微分无法反向传播
- 随着token增长,计算的复杂度不是线性增加的
为了解决上面的问题,将重写为:
则:
或者
可以把吸收到神经元的阈值中,用移位处理的计算,这样推理过程中不存在乘除法的计算。
3.4. Space-Time Spike-Driven Attention Designs
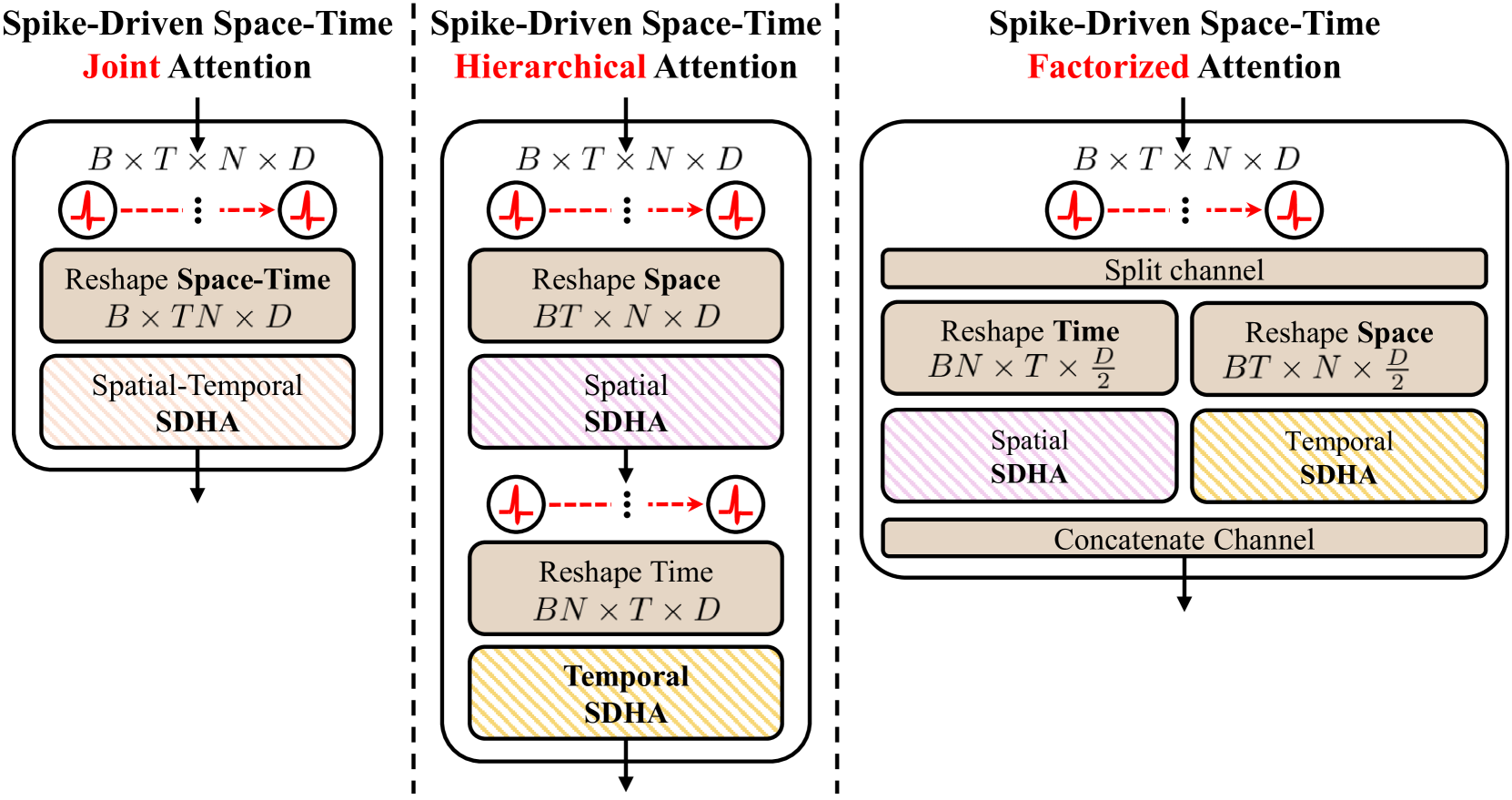

ANN领域典型的做法如上。SpikeVideoFormer采用联合注意力机制,将feature变成然后整个打进Transformer。
4. Experiments
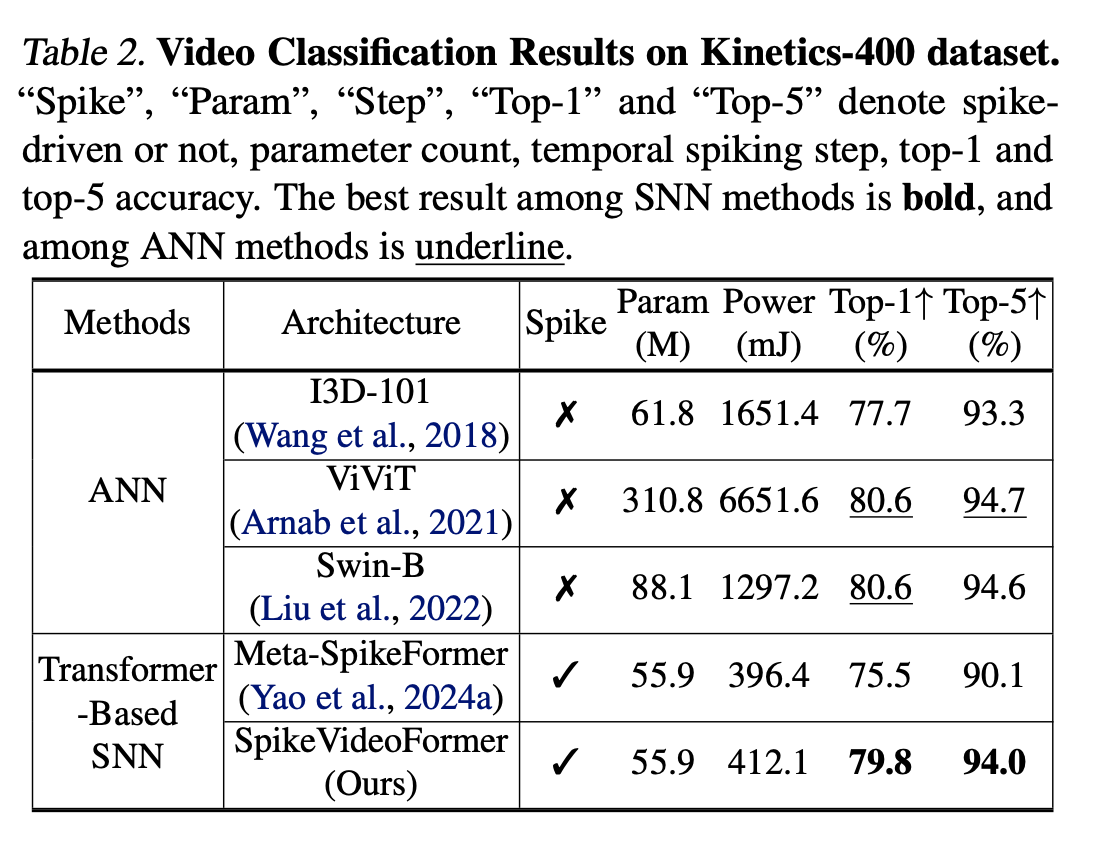
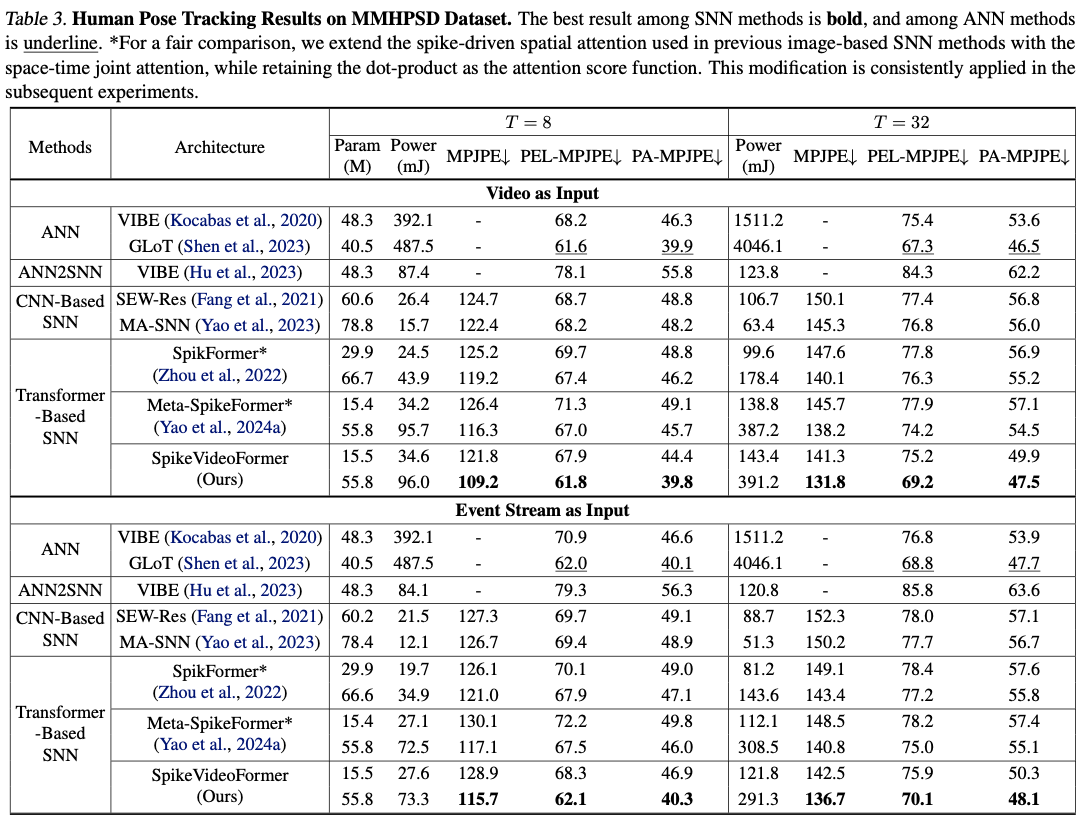
在Video Classification, Pose Estimation , Video Semantic Segmentation上做。
推理时间
在 A6000 GPU 与 AMD EPYC 7543 CPU 上测试批量为 1 和 1000 的视频平均耗时:
- GLoT(ANN,二次 attention)当 T:8→32 时,时延 303→2972 ms(9.8×)
- VIBE(ANN-GRU)时延 264→1335 ms(5.1×)
- 本方法(SNN,线性 attention)时延 235→1087 ms(4.6×)
边缘部署
SNN 仅使用加法运算,更适合神经计算芯片部署,可显著降低功耗和时延。在 AMD Xilinx ZCU104 上,ANN 推理性能为 691.2 GFLOPs/s,而 SNN 可达 5529.6 GFLOPs/s(8× )。在 45 nm 工艺下,ANN 乘法运算消耗 4.6 pJ,SNN 加法运算仅需 0.9 pJ(5.1× 节能)。
这个energy和latency都是怎么测出来的?在神经模态芯片上部署又是什么硬件?

4.2. Ablation Study
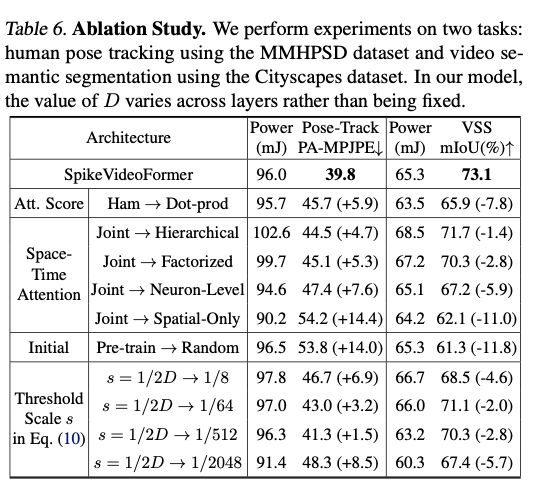
注意力分数函数
将提出的 汉明注意力 换成 点积注意力 ,两项任务的性能均大幅下降:姿态跟踪下降约 15 % ,VSS 下降约 10 % 。功耗虽略有降低,但原因在于点积的掩蔽效应减少了注意力后的脉冲率。
时空注意力机制
将 联合时空注意力 替换为 层次 或分解注意力 ,两项任务均出现明显性能退化,主要因为无法充分捕获全局时空特征。这与视频生成领域的最新发现一致。
仅使用 神经元级时间编码 (Neuron-Only,不在时间域做注意力)时,性能有所下降但仍可接受;若完全去掉时间编码(Spatial-Only,每个时间步重置膜电位),性能急剧下滑,说明 SNN 内在的时间编码能力至关重要。
模型初始化
使用 ImageNet-1K 预训练权重 可显著提升下游效果:PA-MPJPE 改善 26 %+ ,mIoU 提升 19 % 。
阈值缩放 s
先前工作固定 s=1/8。如表 6 所示,固定 s 的表现普遍劣于本文提出的其中 D 随层级变化,可自适应不同通道宽度,效果更佳。
5. Conclusion
本文提出了 SpikeVideoFormer ——一款高效的脉冲驱动视频 Transformer,专为在视频视觉任务中充分发挥 SNN 优势而设计。通过引入 汉明注意力 与 联合时空注意力 ,SpikeVideoFormer 在视频分类、人体姿态跟踪和视频语义分割三大任务上刷新了现有 SNN 的最佳成绩,并在保持精度的同时,相比最新 ANN 方法显著提升了能效。此外,其线性时间复杂度 O(T) 进一步展示了该 SNN-Transformer 在大规模视频处理中的潜力。未来,我们计划将 SpikeVideoFormer 扩展为更大规模的脉冲骨干网络,支持更广泛的视频任务,如视频理解与生成等。