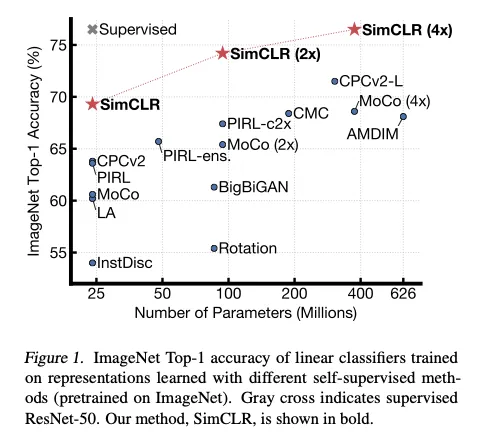
摘要: 本文介绍了 SimCLR——一种用于视觉表征对比学习的简洁框架。我们在不依赖特定网络结构或记忆库的前提下,简化了近期提出的对比式自监督学习算法。为弄清哪些因素使得对比预测任务能够学习到有用的表征,我们系统地分析了框架中的关键组件,并发现:1)数据增强的组合 对构造有效的预测任务至关重要;2)在表征与对比损失之间加入 可学习的非线性变换,能显著提升表征质量;3)与监督学习相比,对比学习在 更大的批量大小 和 更多训练步数 下受益更大。综合以上发现,我们在 ImageNet 上大幅超越了以往的自监督与半监督方法:使用 SimCLR 学到的自监督表征训练线性分类器,可获得 76.5% 的 top-1 准确率——较此前最佳方法提高了 7%(相对提升),并与监督训练的 ResNet-50 持平。当仅使用 1% 的标注进行微调时,SimCLR 取得 85.8% 的 top-5 准确率,使用的标签量比 AlexNet 少 100 倍,却取得更优成绩。
1. Intro
无监督学习视觉表征的主流方法可以分成生成式和判别式两种。本文提出一种对比学习框架SimCLR,通过对比学习来学习视觉表征,在性能上超过了之前的工作。
本文证明:
- 多种数据增强操作的组合能够有效构建有效表征,并且在无监督学习上更加依赖数据增强
- 在表征与对比损失之间加入可学习的线性变换可以提高所学表征的质量
- 使用对比交叉熵的时候归一化嵌入与合适的温度参数都更加有效
- 与有监督学习相比,对比学习在更大的batchsize和更长的训练时间下收益更高
- 与有监督学习相比,对比学习也受益于更深、更宽的网络。
2. Method
2.1. The Contrastive Learning Framework
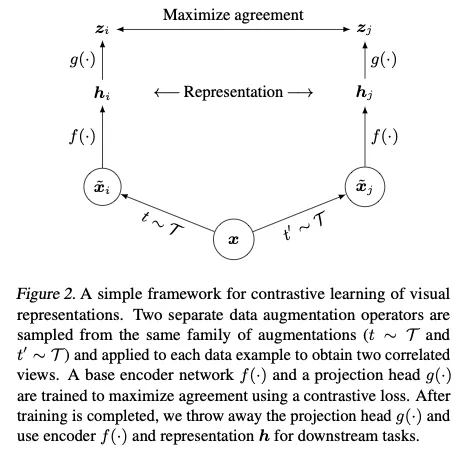
在Latent Space中最小化对比损失,最大化同一个数据样本经过不同增强之后视图之间的一致性来学习表征。主要包括:
- 随机数据增强模块,生成一对样本视为一对正样本,本文的增强方法只取裁剪+缩放,颜色扰动,高斯模糊三种;
- base encoder,从增强之后的样本提取表征,不限制网络结构的选择
- 小型投影头,将表征映射到计算对比损失的空间
- 对比损失函数,给定集合,对比学习任务对一个给定的,需要分类。
对于每个样本采样两种增强视图,这样个sample一共有个数据点,对于一个正样本对而言,还剩下个负样本,
是余弦相似度,则正样本对的loss:

2.2 Training with Large Batch Size
不使用之前的“记忆库”,而是将batchsize设置到256~8192.采用LARS优化器。
采用global batchNorm,因为在Data Parallellim的训练中,BN的均值和方差在设备本地聚合,而正样本对一定在同一个设备上,模型可能利用这种局部信息泄露提高准确率,因此采用global的聚合方式。
2.3. Evaluation Protocol
3. Data Augmentation for Contrastive Representation Learning
“Data augmentation defines predictive tasks”:我们表明,只需对目标图像进行随机裁剪并缩放 即可避免这些复杂性,并产生一系列预测任务(见图 3),其范围涵盖上述两类方法。这一简单设计将预测任务与网络结构等其他组件解耦。通过扩展增强操作并随机组合,可定义更广泛的对比预测任务。
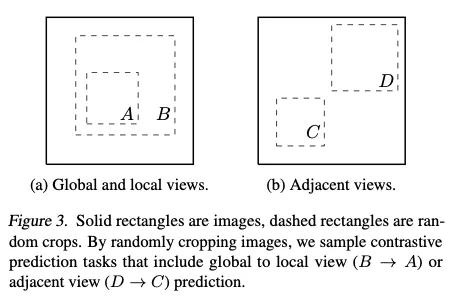
3.1. Composition of data augmentation operations is crucial for learning good representations

为理解单个数据增强及其组合的作用,我们比较了仅使用单一增强或成对组合时框架的表现。由于 ImageNet 图像尺寸不一,我们始终对图像做裁剪并缩放,这使得在缺少裁剪的情况下研究其他增强变得困难。为消除此干扰,本消融实验采用非对称数据变换:始终先随机裁剪并缩放,然后仅对框架中一条分支应用目标变换,其余分支保持恒等(即 )。需注意,非对称增强会降低整体性能,但不应实质改变单个增强或其组合的影响。
图 5 给出了在线性评估协议下,单独及组合增强的结果。可以看到,单一增强不足以学习优质表征——尽管模型几乎能完美识别对比任务中的正样本对。组合增强后,对比预测任务更难,但表征质量显著提升。
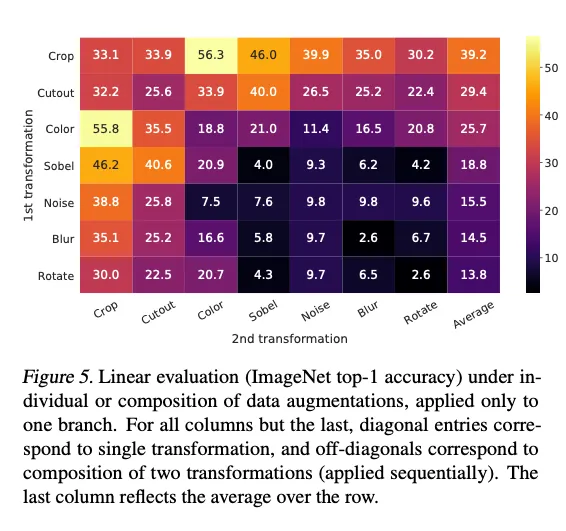
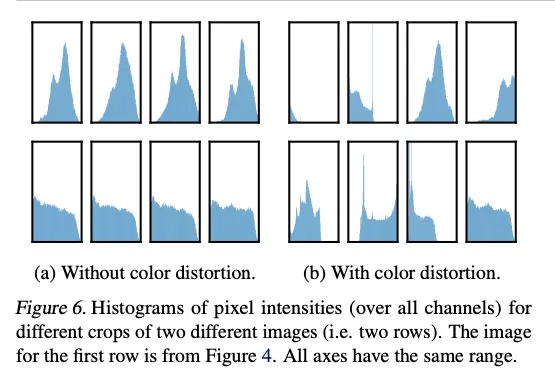
其中一组增强尤为突出:随机裁剪 + 随机颜色扰动。我们推测,仅用随机裁剪时,一个图像的大多数 patch 具有相似的颜色分布。图 6 表明,仅凭颜色直方图即可区分图像,神经网络可能利用这一“捷径”完成预测任务,导致表征泛化性差。因此,必须将裁剪与颜色扰动组合,以学习更具泛化能力的特征。
3.2. Contrastive learning needs stronger data augmentation than supervised learning
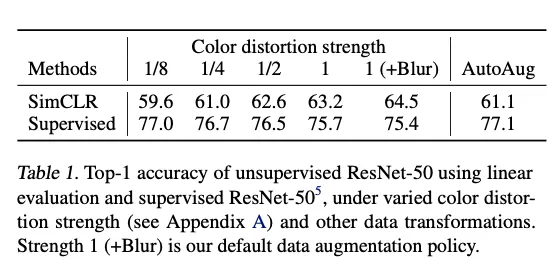
为进一步证明颜色增强的重要性,我们调节颜色增强强度(见表 1)。更强的颜色扰动显著提升 无监督模型的线性评估准确率。在此背景下,AutoAugment(Cubuk et al., 2019)——一种通过监督学习搜索得到的复杂策略——并不优于简单的“裁剪 +(更强)颜色扰动”。当用同一组增强训练监督模型 时,较强颜色增强并未提升,甚至降低其性能。由此实验表明,无监督对比学习比监督学习更依赖强(尤其是颜色)数据增强 。尽管已有研究指出数据增强对自监督学习有益(Doersch et al., 2015;Bachman et al., 2019;Hénaff et al., 2019;Asano et al., 2019),我们进一步展示:某些增强对监督学习无益,却能显著提升对比学习表现。
4. Architectures for Encoder and Head
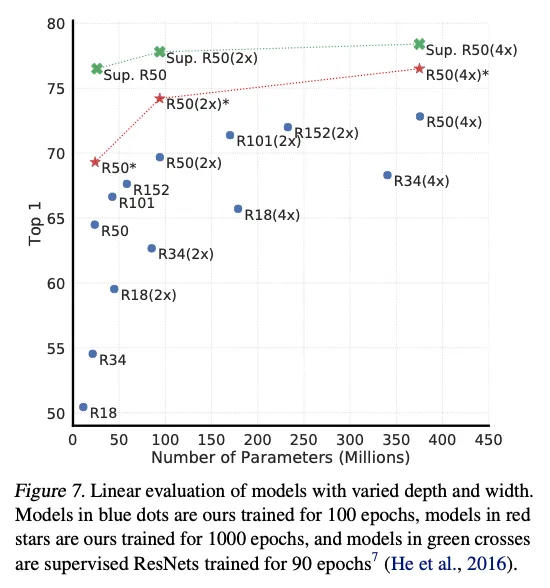
4.1. Unsupervised contrastive learning benefits (more) from bigger models
4.2. A nonlinear projection head improves the representation quality of the layer before it
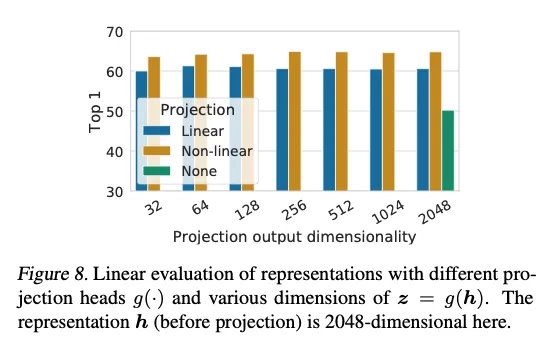
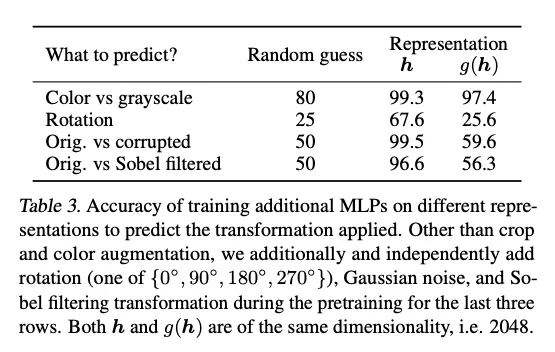
接着我们研究是否需要投影头 g(h)。图 8 给出了三种投影头架构在线性评估 中的结果:
- 恒等映射 (无投影头);
- 线性投影 (若干先前方法采用,Wu 等,2018);
- 默认非线性投影 ——一隐藏层 + ReLU,与 Bachman 等(2019)相似。
结果显示:
-
非线性投影优于线性投影约 3 个百分点 ;
-
远优于 无投影头(提升超过 10 个百分点)。
当使用投影头时,输出维度的不同对结果影响甚微。更重要的是,即使采用非线性投影,投影头之前的层 h 的表征仍比之后的 ** 好**(> 10 个百分点),说明隐藏层 h 比 z 更适合作为通用表征。
推测:之所以要使用 h 而不是 z,可能是因为对比损失会丢失信息。 被训练得对数据变换不变,可能会去除下游任务所需的信息(如颜色、方位)。加入非线性 后,可在 h 中保留更多信息。
为验证该假设,我们用 h 或 g(h) 去预测预训练时所施加的数据变换 。此处设 ,输入与输出维度均为 2048。表 3 显示:h 含有远多于 g(h) 的变换信息.
5. Loss Funcions and Batch Size
5.1. Normalized cross entropy loss with adjustable temperature works better than alternatives

通过梯度可见:
- 归一化 (即采用余弦相似度) + 温度 可对不同样本自动加权,合适的温度有助于模型利用“困难负样本”;
- 除交叉熵外,其他目标函数不会按“负样本难度”加权,因此必须进行 半难负样本挖掘 (Schroff 等,2015):只在梯度中保留那些位于 margin 内、且距离最接近(但仍远于正样本)的负样本。

5.2. Contrastive learning benefits (more) from larger batch sizes and longer training
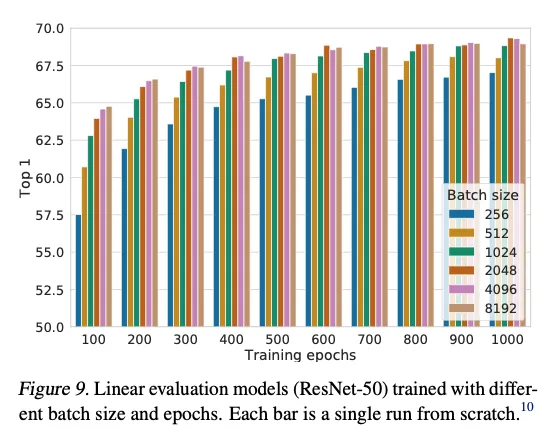
大batch多epoch。
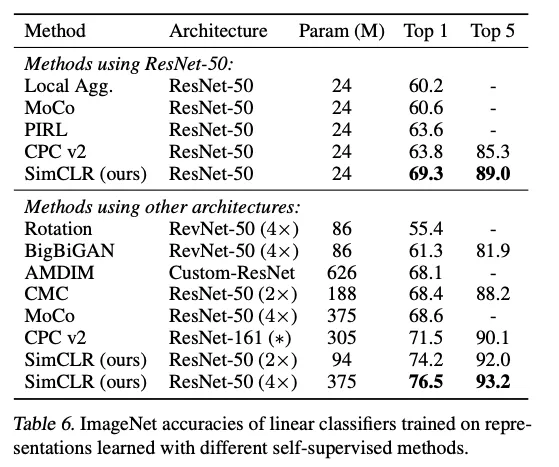
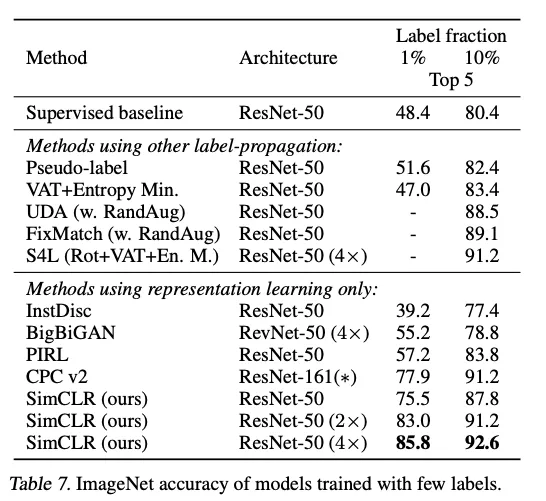
6. Comparison with State-of-the-art
7. Related works
让同一图像在小幅变换下的表征保持一致的思想可追溯到 Becker & Hinton(1992)。我们在此基础上结合了最新的数据增强、网络架构和对比损失。类似的“一致性”思想在其它场景(如半监督学习:Xie 等,2019;Berthelot 等,2019)亦被用于类别标签预测。 人工设计的前置任务。 自监督学习的复兴始于手工设计的前置任务,如相对位置预测(Doersch 等,2015)、拼图(Noroozi & Favaro,2016)、图像上色(Zhang 等,2016)和旋转识别(Gidaris 等,2018;Chen 等,2019)。虽然可通过更大网络和更长训练获得较好结果(Kolesnikov 等,2019),但这些任务依赖一定的启发式规则,限制了表征的通用性。 对比式视觉表征学习。 追溯到 Hadsell 等(2006),这类方法通过将正样本对与负样本对进行对比来学习表征。Dosovitskiy 等(2014)提出将每个实例视为一个类别,用(参数化的)特征向量表示;Wu 等(2018)则提出使用记忆库存储实例类别向量,此思路被多篇后续工作采用与扩展(Zhuang 等,2019;Tian 等,2019;He 等,2019;Misra & van der Maaten,2019)。亦有研究使用 批内样本 取代记忆库进行负样本采样(Doersch & Zisserman,2017;Ye 等,2019;Ji 等,2019)。 近期文献尝试将方法成功归因于最大化潜在表征间的互信息 (Oord 等,2018;Hénaff 等,2019;Hjelm 等,2018;Bachman 等,2019),但 Tschannen 等(2019)指出,成功究竟源于互信息本身还是对比损失的具体形式仍不清楚。 值得注意的是,我们框架的几乎所有组成部分在以往工作中都曾出现,只是实例化方式有所不同。我们的优势并非由某个单独设计决定,而是 多项设计组合 的结果。附录 C 对比了我们的设计选择与先前工作的差异。
8. Conclusion
本文提出了一种简洁的视觉对比表征学习框架(SimCLR)及其实现,并系统地分析了其组件、阐明不同设计选择的影响。通过综合这些发现,我们在 自监督 、半监督 与 迁移学习 任务上大幅超越了先前方法。
与标准的 ImageNet 监督学习相比,我们的做法仅在三点上有所不同:
- 数据增强策略 ;
- 网络末端的非线性投影头 ;
- 损失函数 。
这一简单框架的强大性能表明,尽管近期兴趣爆发,自监督学习仍被低估 。