摘要: 卷积神经网络在视频数据上的推理需要强大的硬件才能实现实时处理。鉴于连续帧之间的固有连贯性,视频的大部分区域通常变化很小。通过跳过相同的图像区域并截断无关紧要的像素更新,理论上可以显著减少计算冗余。然而,这些理论上的节省在实践中难以实现,因为稀疏更新会破坏计算的一致性和内存访问的连贯性,而这两者对于实际硬件上的高效运行至关重要。 借助DeltaCNN,我们提出了一种稀疏卷积神经网络框架,可以通过逐帧的稀疏更新在实践中加速视频推理。我们为所有典型的CNN层提供了稀疏实现,并在整个网络中端到端地传播稀疏特征更新——且不会随着时间累积误差。DeltaCNN无需重新训练即可应用于任意卷积神经网络。 据我们所知,在实际场景下,我们的方案是首个能够显著超越密集基准实现(cuDNN)性能的方案,在准确率仅有微小差异的情况下达到了高达7倍的加速。我们的CUDA内核和PyTorch扩展已经发布在GitHub(https://github.com/facebookresearch/DeltaCNN)。
1. Intro
CNN模型越来越大,设计一些降低开销的做法,比如DW卷积、量化、剪枝等。最近有一些新的工作,通过重用前一帧中未变化的区域的计算结果,可以降低计算成本而不影响计算准确率。
一些做法是,直接截断小幅度变化,但是在GPU这样的硬件上效果很差,因为这会涉及到大量的条件分支语句和非连续方寸。
Contribution:
- 我们提出了DeltaCNN ,这是第一个在所有层(包括卷积、池化、激活、上采样、归一化等)从输入到输出均以稀疏方式访问数据的CNN稀疏推理框架。DeltaCNN无需重新训练,仅需对网络进行少量修改即可适用于任意现有CNN模型。
- 我们设计了一种新的GPU计算内核 (使用掩码和缓存),解决了稀疏神经网络在内存带宽和控制流方面的问题。我们开源了据我们所知首个支持稀疏输入和稀疏输出的CNN算子GPU实现。
- 我们首次在GPU上证明了利用数据稀疏性加速CNN推理的可行性 :在三种不同GPU硬件上,对于目标检测和人体姿态估计的三个网络,我们实现了最高达7倍的加速。
2. Related Work
- Efficient Video CNN architectures,“双路径”,关键帧上执行精细的计算,而非关键帧走另一条FLOPs数不那么高的路径;
- Sparsity in videos,差分帧输入可以提高稀疏性:

一些工作通过截断相对小的输入/输出,cache住之前的input/output feature,然后定期密集更新一次,获得稀疏性与精度的保障。
3. Method
3.1. Delta value propagation
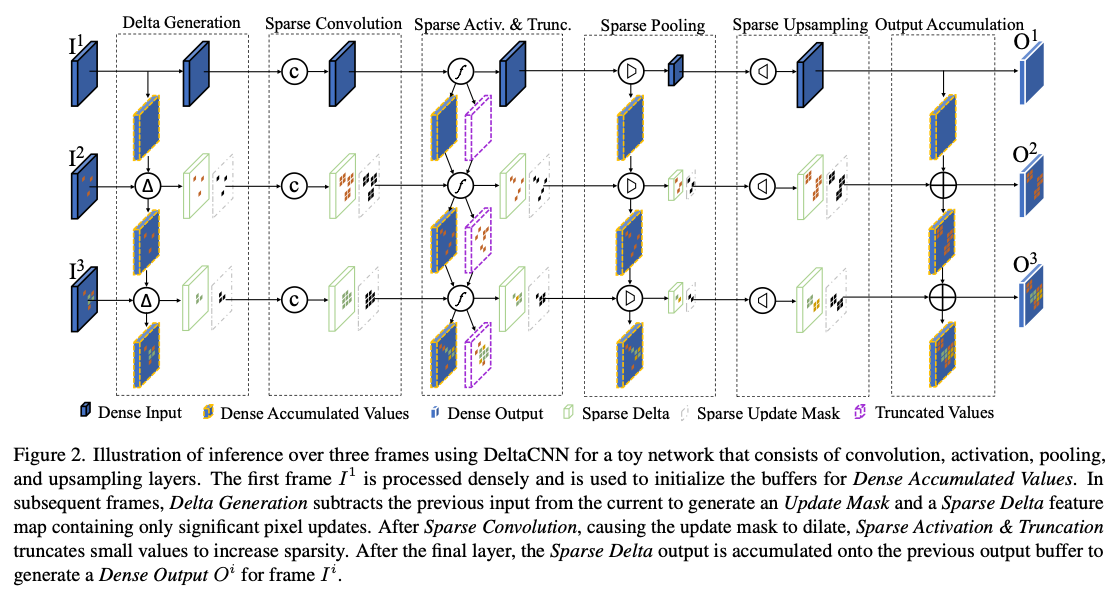
对于Linear的layer直接做差分输入得到差分输出,对于非线性的layer需要维护一个自己的历史input,得到前面的差分输入之后累加再输入到非线性层中。
设置一个截断稀疏,如果就直接截断不更新,而就更新,然后在buffer中存储累积值:
这种截断的误差会逐渐累积,因此还要引入第二个buffer存储自上次更新以来,累计的被截断的数值,当需要更新的时候,实际上是:
把历史截断的信息还原回去。通过这种技术,DeltaCNN仅需第一个初始帧以密集模式处理,此后便可无限期地应用稀疏更新而不会随着时间累积误差。
3.2. Design considerations for GPUs
通用GPU允许在多核设备上执行任意代码。然而,理论上减少指令数常常无法直接转化为高效的GPU代码。不一致的执行路径和不连续的内存访问模式可能导致明显的性能下降。在GPU上实现高性能卷积的关键在于优化内存访问并生成局部连续的控制流。
Update mask
存储的时候还是按照dense的存储,更新的时候让delta feature和一个update mask一起传递,每一层首先检查mask中,现在要load的tilie是否是全0的,然后再决定要不要跳过这个tile的数据加载和计算。不管是否跳过这个tile,都会更新下次使用的mask。同时,由于可以直接通过mask跳过全0的tile,对应的feature map实际上不需要被初始化为0.
Memory considerations and tiled convolutions
优化 2D 卷积常见方法是分块处理 :把整幅图像切成若干 tile,每个 tile 由一个 CTA(cooperative thread array)合作完成。这样即可在片上缓存输入特征和卷积核,多次复用。tile 大小需要在“减少内存访问”与“提供足够并行度”之间权衡:tile 越大,内存复用越好,但占用的片上资源越多。
Per-tile sparsity vs. sub-tile sparsity
早期稀疏卷积研究大多关注少做乘法(FLOP 减少),但在墙钟时间上收效甚微。原因是:在像素级别做稀疏判断会引入大量条件跳转和离散内存访问,省下的运算时间往往抵不上控制流和访存开销。
我们采用tile 级稀疏 而不是像素级稀疏。如果一个 tile 里哪怕只有一个像素被激活,也必须加载整块所需的所有卷积核并产生多像素输出,代价几乎与全部激活相同。举例:假设 tile 大小为 5×5 输出像素,卷积核 3×3、通道数 256,对应输入窗口 7×7。单个 CTA 就要加载 12 544 个输入特征、589 824 个卷积核参数,并做 14 745 600 次乘法。只要有任何输入非零,大部分访存仍是必要的;真正能省的只是部分乘法。
Control flow simplification
卷积涉及输入、权重、输出三方。若编译期能确定它们在寄存器中的映射,执行效率最高。若在 tile 内对每个像素做条件跳转,需要不断加载掩码、比较并跳转,指令数激增,性能急剧下降。为避免细粒度跳转,我们提出三种模式的混合内核 :
- Skip :若整 tile 无激活像素,直接跳过所有加载与计算;
- Dense :若激活像素 ≥ 5(最多 64),当成稠密卷积处理,完全无条件跳转;
- Very Sparse :若激活像素为 1–4,使用特制稀疏内核:
- 先从更新掩码收集激活像素的坐标列表;
- 仅在这几个坐标循环,不用再重复检查掩码;
- 只加载当前 tile 必要的卷积核权重。
在极端情况下(例如只更新左上角一个像素),可把内存传输压缩到 1/8 ,因为只需加载会影响左上角输出的那部分权重。关于 tile 内稀疏的利弊,作者在补充材料中有更深入的评估。
3.3. Truncation of insignificant updates
我们对每一层的 ϵ 逐层(由前向后)自动调参,调参时仅使用训练集中的一个小子集。对某层,从一个很小的 ϵ 开始,如果在当前阈值下网络总损失依旧低于允许误差上限 ,就继续增大 ϵ。换言之,我们让每一层对整体误差“承担同等份额”。找到使损失首次逼近上限的 最大阈值 后,就把该层的 ϵ 固定,再转到下一层继续同样过程。实验表明:若在阈值搜索期间出现准确率反而提升 的情况,需要把这种提升钳制住,否则会在小样本上过拟合。
3.4. Implementation
我们的目标不仅是加速卷积层,而是让整张网络都受益。因此,让尽可能多的运算以稀疏方式执行是关键。DeltaCNN 为当前 CNN 中最常见的层都提供了稀疏实现,包括:卷积、批归一化、池化、上采样、激活函数,以及张量拼接和逐元素加法。我们发布了 CUDA 核函数(可直接替换 cuDNN)与 PyTorch 扩展模块。研究者只需把原来的 PyTorch 层换成 DeltaCNN 版本,即可在 不改模型结构、重用原有权重 的前提下获得稀疏推理加速。
4. Evaluation
训练结束后,我们尽可能将卷积层与批归一化层进行融合,以提升基线模型和 DeltaCNN 两者的性能。对 DeltaCNN 而言,仅首层和末层处理稠密数据:首层将稠密视频输入转换为稀疏增量特征,末层则把增量特征累积回稠密输出。

在所有实验中,我们随机选取多段训练序列(每段 100 帧),并使用自动调优的 ϵ 阈值(见 3.3 节)计算所有帧的平均损失。全网允许的最大损失增幅设为 3%,各层仅可占用其中一小部分误差预算。对输入视频(已按 ImageNet 颜色范围归一化)所用的首个截断阈值,我们提高阈值以抑制背景噪声,同时保持对关键运动的敏感度(Human3.6M 设为 0.3,MOT16 与 WildTrack 设为 0.5)。随后,将得到的掩码向外膨胀 7 个像素,以纳入邻域内的细微变化。图 4 对比了“较大阈值+膨胀”与“较小阈值、不膨胀”的效果。
在Jetson Nano, 1050, 3090上跑实验。
5. Results
5.1. Human pose estimation
5.2. Object detection
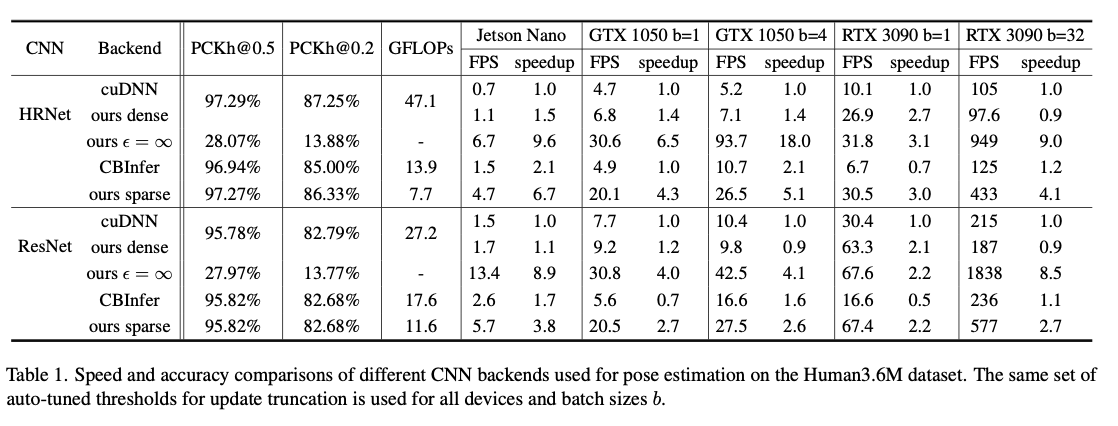
对 HRNet 的逐帧和逐卷积核细粒度评估显示:在卷积层中,平均仅 6% 的输入像素被更新;只有 16% 的 tile 被实际计算,使 FLOPs 减少 84%,即便要读写额外缓冲区,整体内存传输仍降至 21%。
5.3. Additional evaluations
- Improved stability, 由于会截断,模型对噪声的过敏反应降低了,减小了模型推理中出现的大幅度波动;
- Treshold analysis, 分析自动调好的阈值可洞察各层贡献或对输入敏感度。在 EfficientDet 中,EfficientNet 主干的某些分支在首帧后完全关闭,因为帧间变化对结果无影响。EfficientNet 的 Squeeze-and-Excitation 分支先做全局平均池化,仅剩单像素;其两次卷积与激活对后续特征做缩放。几秒钟序列内全局平均几乎不变,因此在该分支的首个截断层就截掉所有更新。
- Overhead, 见表1,可以看到即使在dense模式也没有比cuDNN的模型慢多少,证明并不需要达到多少多少的稀疏度才能开始有收益;
6. Discussion
我们的评估表明,DeltaCNN 能在几乎不损失精度的情况下加速视频推理。由于 DeltaCNN 的额外开销远小于以往方法,它既能加速计算量大的 CNN,也能加速 FLOPs-高效的轻量 CNN;既适用于更新稀疏的数据集,也适用于更新密集的数据集;同时兼容低端和高端 GPU。通过阈值调节,可在保持精度 的前提下获得适度加速,或在轻微降低精度 的情况下获得更大加速。DeltaCNN 甚至能在相同帧率下提高预测精度,因为它让更大的网络成为可能。 分块卷积 我们的卷积按 tile 处理,输入中单像素的更新会触发整块 tile 的计算。与 CBInfer 相比,这降低了对非结构化稀疏的节省,因为 CBInfer 能按输出像素控制稀疏度。不过,正如 CBInfer 作者所述,帧间更新往往具有结构性;像素级稀疏主要用于加速更新区域的“光环”部分,这仅占更新像素的一小部分。同时,我们的方法在稠密推理上达到最新水平,使我们即便在 MOT16 与 WildTrack 等高度密集场景中也能加速。 局限 时域稀疏 CNN(包括 DeltaCNN)的主要限制是只在固定摄像头 输入下效果最佳。即便轻微摄像机移动,也会导致几乎稠密的更新,至少影响前几层。后续分辨率较低的层通常能截掉部分更新,但整体加速仍会下降。 另一缺点是显存开销随批大小线性增长。与 RRM、Skip-Convolutions 和 CBInfer 相比,DeltaCNN 仍可减少约 20% 缓存需求。但在低端设备上,显存仍可能成为瓶颈。如设备内存不足,可对部分激活层停用增量截断,以减少 缓冲,但代价是更新密度增大。
7. Conclusion
本文提出了 DeltaCNN——一种加速视频输入 CNN 推理的方法及其实现。就我们所知,DeltaCNN 是首个实现端到端稀疏帧更新传播并在实践中获得加速的方案。凭借针对 GPU 优化的设计,我们既超越了稠密推理的最新框架,也领先现有稀疏实现。由于卷积核心对稀疏性无感,且加速通过完全跳过 tile 获得,不引入显著处理开销,我们的方法可迁移到其他 CNN 加速平台和处理器。
8. Appendix
8.1. Effcient convolution on GPUs
Tiling for Memory Reuse
用更大的tile换取更好的复用,比如如果是33卷积,移动到下一个窗格的时候实际上有六个像素的feature是可以复用的,而如果tile取的是33,就需要用特殊的实现来zigzag处理等。但是更小的tile意味着更有可能直接跳过,更少的资源占用等,所以需要权衡。
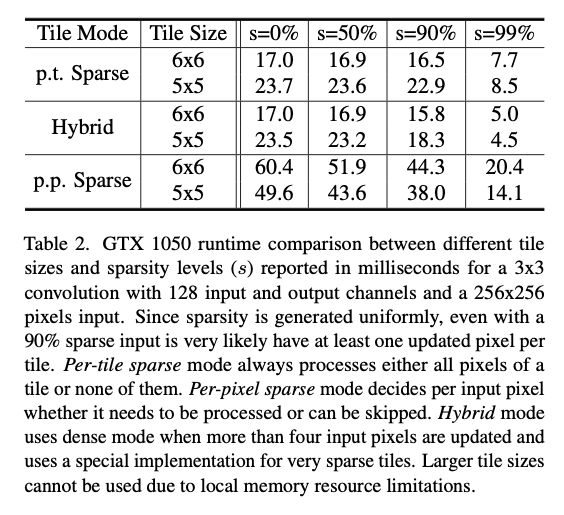
可以看到per pixel sparse的运行速度在所有tiling size和所有sparsity上都比per tile sparse慢。
Memory Layout for Bandwidth Reductions
因为需要per pixel的访问,用传统的NCHW的格式读不够连续(per pixel访问要读一个pixel的不同channel的信息),所以换成NHWC。
Floating Point number Inaccuracies
理论上,增量可无限次叠加;然而在实际浮点运算中,若输入是巨大的累计值或极小的增量,两者混用会产生微小差异。对 HRNet + Human3.6M,我们在数千帧序列里未见问题;但在 EfficientDet 中,即使用负阈值做稠密推理,也观察到误差随时间累积。我们建议每隔几百帧,或在视频切换时,重置增量与累计缓存,以清除浮点误差。
8.2. Threshold tuning ablation study
把threshold发到模型里 + 用sigmoid代替threshold,训练出来效果也没有什么很高的提升,但是训练时间加长很多。