摘要: 我们提出了一种用于视频识别的 SlowFast 网络。我们的模型包括:(i) 一个以低帧率运行的“慢”路径,用于捕捉空间语义;以及 (ii) 一个以高帧率运行的“快”路径,用于在精细的时间尺度上捕捉运动信息。通过减少通道数量,快路径可以被设计得非常轻量,但仍能学习到对视频识别有用的时间信息。我们的模型在视频动作分类和检测任务上都取得了出色的性能,而这些性能的大幅提升可归功于 SlowFast 概念的引入。我们在主要的视频识别基准(Kinetics、Charades 和 AVA)上达到了最新的准确率。代码已发布在:https://github.com/facebookresearch/SlowFast。
1. Intro
在图像 的识别中,通常对两个空间维度 和 进行对称处理。这一做法由自然图像的统计特性所支撑:在第一近似下,自然图像是各向同性的 —— 所有方向出现的概率都相同 —— 且具有平移不变性。但是,对于视频信号 来说又如何呢?运动是方向的时空对应物, 然而并非所有时空方向都是同等可能的。慢动作出现的概率比快动作更高(实际上,在任意给定的时刻,我们所见世界的大部分都是静止的),这一点已经在人类对运动刺激的贝叶斯解释中得到利用。例如,如果我们在孤立情况下看到一条移动的边,我们会感知到它垂直于自身在移动,尽管从原理上讲它也可能具有平行于自身的任意运动分量(光流中的孔径问题)。如果先验概率偏向于慢速运动,那么这种感知是合理的。如果并非所有时空方向都同等可能,那么我们就没有理由在空间和时间上以对称方式处理信号——然而基于时空卷积的视频识别方法却默认进行了这种对称处理。我们或许可以“分解”架构,使其分别处理空间结构和时间事件。具体来说,我们以识别任务为例进行研究。视觉内容的类别语义通常演变缓慢。例如,挥动的双手在整个挥手动作过程中身份不会改变——始终是“手”;一个人从走路过渡到跑步时,他/她的类别始终是“人”。因此,对类别语义(以及它们的颜色、纹理、光照等)的识别可以较为缓慢地更新。另一方面,相对于主体身份而言,所执行的动作可能演变得快得多,例如鼓掌、挥手、抖动、行走或跳跃。为了有效地建模这种可能快速变化的动作,我们需要使用快速刷新的帧(高时间分辨率)。
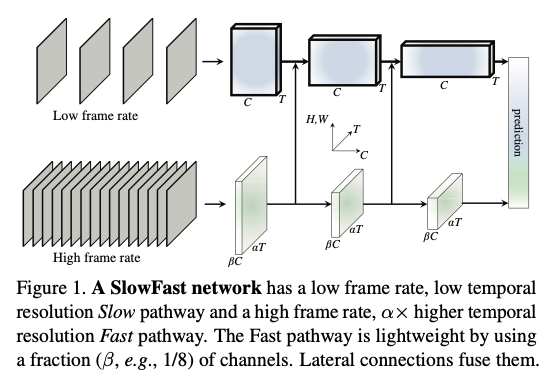
Slow Path提供语义信息,在低帧率下运行,而Fast Path提供运动信息,在高帧率下运行但设计的很轻量。
2. Related Works
- Spatiotemporal filtering, 添加了时间维度上的卷积,但是效果不一定好?
- Optical flow for video recognition, 手工设计一些表示,从方法论上来看这并不令人满意,因为光流是一种人工设计的表示,并且双流方法通常无法与光流分支进行端到端联合训练。
3. SlowFast Networks
SlowFast 网络可以描述为单流架构在两种不同帧率下的运行,但我们使用“路径”(pathway)这一概念来类比其与生物学上小细胞/大细胞路径的对应关系。我们的通用架构包含一个慢路径(见第3.1节)和一个快路径(见第3.2节),它们通过横向连接融合为一个 SlowFast 网络(见第3.3节)。
3.1. Slow pathway
慢路径可以是任意卷积模型,该模型将一段视频剪辑作为一个时空体积来处理。慢路径中的关键概念是在输入帧上使用较大的时间步长 ,即它只处理每隔 帧采样到的一帧。我们研究的一个典型值是 —— 这种刷新速率对 30 fps 的视频来说约等于每秒采样 2 帧。记慢路径采样的帧数为 ,则原始视频剪辑的长度为 帧。
3.2. Fast pathway
- High frame rate, 我们的目标是获得精细的时间维度表征。快路径使用极小的时间步长 (其中 ,为快路径与慢路径的帧率比)。两条路径作用于相同的原始视频剪辑,因此快路径采样 帧,比慢路径密集 倍。我们在实验中的一个典型值是 。
- High temporal resolution features, 快路径不仅具有高的输入时间分辨率,还在整个网络层级上追求高时间分辨率的特征。在我们的实现中,我们在快路径中不使用任何时间下采样层(无时间池化,也无带时间步幅的卷积),直到分类之前的全局池化层为止。这样一来,我们的特征张量在时间维度上始终保持帧,在时间上尽可能保留细节。
- Low Channel capacity
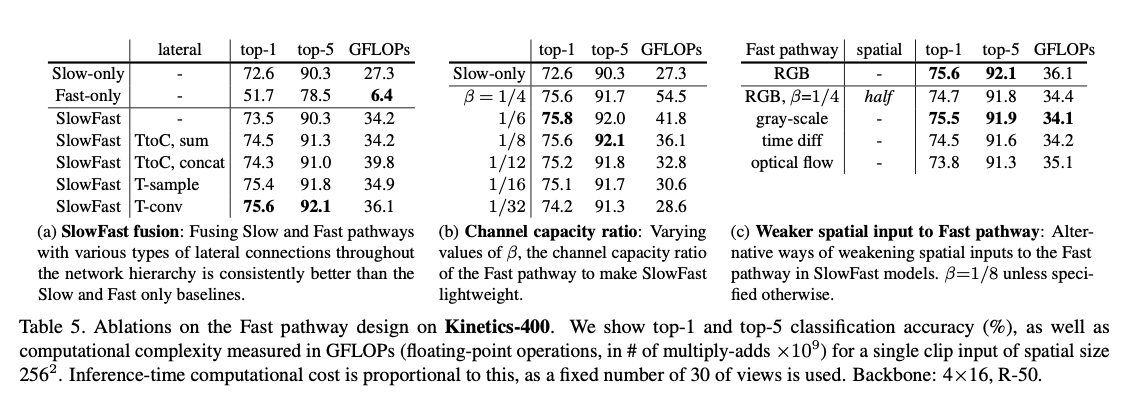
我们的快路径还区别于现有模型的一点是,它可以用显著更少的通道容量仍取得良好准确率。这使得它非常轻量。简而言之,快路径是一个与慢路径类似的卷积网络,但通道数仅为慢路径的 倍。我们在实验中的典型值是。注意,对于同一层,计算量(以浮点运算次数衡量)通常与通道缩放比的平方成正比。这使得快路径在计算上比慢路径更为高效。在我们的实现中,快路径通常只占总计算量的约20%。有趣的是,正如第1节提到的,有研究表明灵长类视觉系统的视网膜细胞中约有15–20%是 M 细胞(对快速运动敏感但不敏感于颜色或空间细节)。
较少的通道容量也意味着表示空间语义的能力较弱。从技术上讲,我们的快路径在空间维度上并没有特殊处理,因此由于通道更少,它的空间建模能力应低于慢路径。我们的模型取得的优异效果表明,让快路径削弱空间建模能力、强化时间建模能力是一种有效的折中。
受上述解释的启发,我们还探索了削弱快路径空间容量的不同方式,包括降低快路径输入的空间分辨率以及去除颜色信息。正如我们将通过实验展示的,这些变体都能够取得良好的准确率,表明降低空间容量的轻量快路径是有益的。
3.3. Lateral connections
在两个path每个stage之间添加一个横向的连接,然后采用一些temporal变换fit两者的维度。只采用单向连接将快的融入慢的,因为双向的效果相似。
3.4. Instantiations
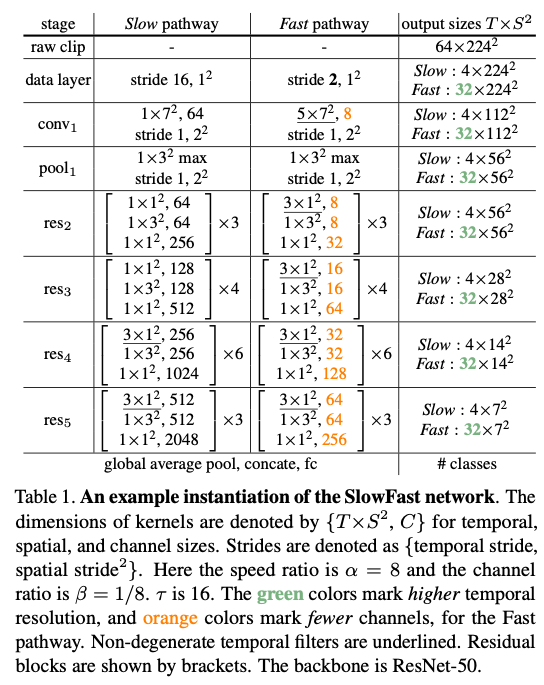
- 横向连接: 我们的横向连接将快路径的特征融合到慢路径中。融合前需要使特征尺寸匹配。设慢路径的特征形状为 ,则快路径的特征形状为。我们在横向连接中尝试了以下变换:
- 时间转通道(Time-to-channel): 将重塑并转置为,即将所有 帧的信息打包到单帧的通道维度中。
- 时间抽样(Time-strided sampling): 每隔 帧简单采样一帧,因而 变为 。
- 时间卷积(Time-strided convolution): 使用一个 的 3D 卷积核,输出通道数 ,时间步幅设为 。
4. Experiments: Action Classification
训练: 我们在 Kinetics 上的模型从随机初始化开始训练(“从头开始”),未使用 ImageNet或其他任何预训练。我们使用同步 SGD 进行训练。详细的训练设置见附录。时间域方面,我们从整段视频中随机采样一个片段(包含 αT×τ 帧),慢路径和快路径的输入分别为 T 帧和 αT 帧;空间域方面,我们将视频或其水平翻转随机裁剪出 224×224 的区域,其中短边长度在 [256, 320] 像素范围内随机采样。 推理: 按照常规做法,我们在视频的时间轴上均匀采样10个片段。对每个片段,我们将较短的空间边缩放至256像素,并裁取3个256×256的区域来覆盖空间维度(参考文献的代码实现,这相当于近似的全卷积测试)。我们对30个视图的 softmax 分数取平均作为预测。我们报告实际推理时的计算量。由于不同论文在时空上裁剪/采样策略不同,为了公平比较,我们报告每个时空“视图”(即一个时间片段加一个空间裁剪)的 FLOPs 以及所使用的视图数。需要指出的是,在我们的设置中,推理时的空间尺寸为256^2(训练时为224^2),并且采用10个时间片段,每个片段取3个空间裁剪(共30个视图)。
4.1. Main Results
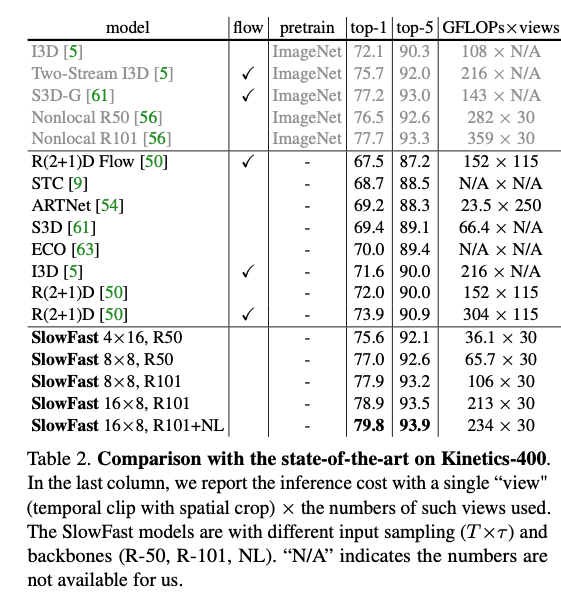
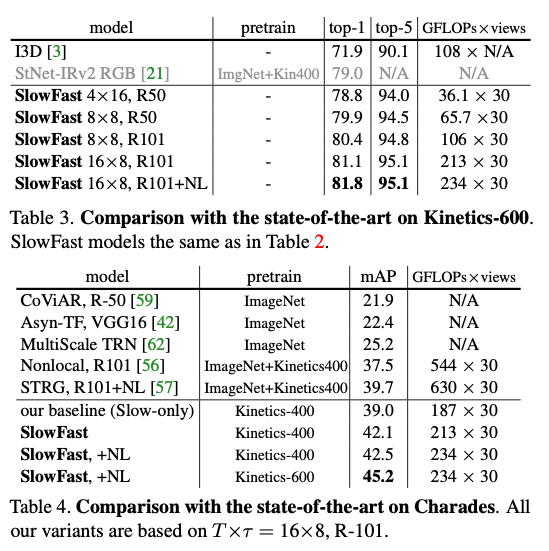
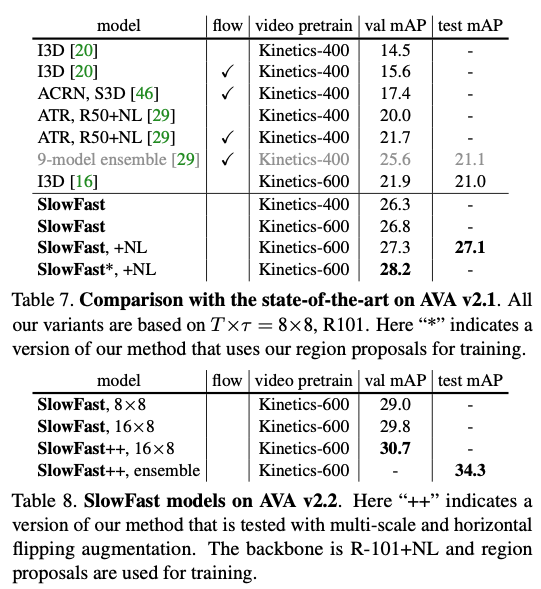
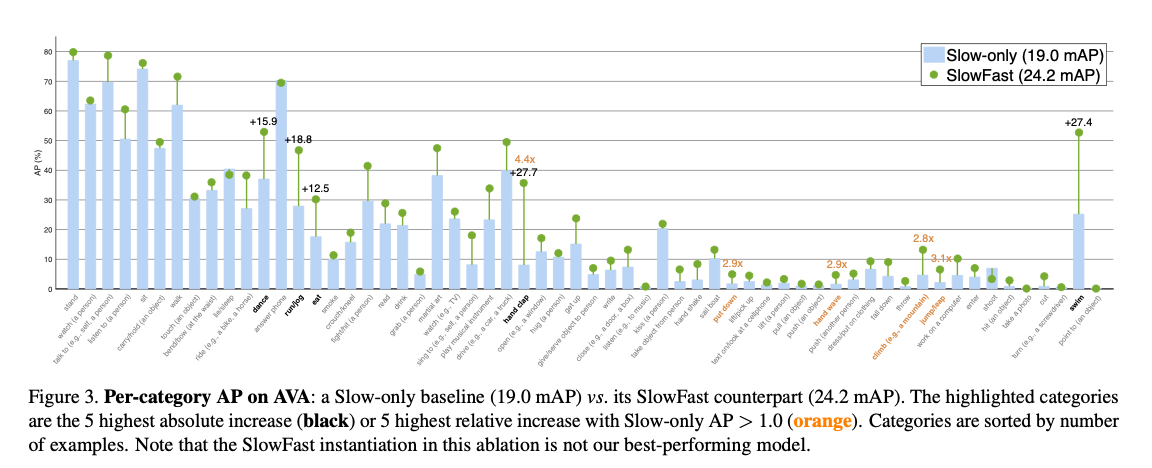
是SOTA + 更低的FLOPS。
4.2. Ablation Experiments

对不同的变体效果都很好。
5. Experiments: AVA Action Detection

6. Conclusion
时间轴是一个特殊的维度。本文探讨了一种在该维度上对速度进行区分的架构设计。该方法在视频动作分类和检测任务上取得了当前最先进的准确率。我们希望 SlowFast 这一概念能够推动视频识别领域进一步的研究。