摘要: 目前的Transformer模型在生成一分钟视频方面仍然存在困难,因为自注意力层在处理长上下文时效率较低。诸如Mamba层等替代方案,因其隐藏状态的表达能力较弱,难以处理复杂的多场景故事。我们实验了测试时训练(Test-Time Training, TTT)层,其隐藏状态本身可以是神经网络,因此具有更强的表达能力。将TTT层添加到预训练的Transformer中,使其能够从文本故事板生成一分钟的视频。为了验证这一概念,我们基于《汤姆和杰瑞》卡通制作了一个数据集。与Mamba 2、Gated DeltaNet和滑动窗口注意力层等基准方法相比,TTT层生成的影片更加连贯,能够讲述复杂的故事,在100个视频的人类评估中,领先34 Elo点。尽管如此,结果仍然存在一些伪影,可能与预训练的5B模型能力有限有关。我们的实现效率也可以进一步优化。由于资源限制,我们仅对一分钟的视频进行了实验,但该方法可以扩展到更长的视频和更复杂的故事。示例视频、代码和注释可在以下网址获取:https://test-time-training.github.io/video-dit

1. Intro
目前的Video Transformer基本还是只能生成单一场景的短视频,时间基本集中在10-20秒,导致没有办法生成复杂的故事。
视频生成长度主要受制于上下文,Transformer的平方复杂度对生成视频的挑战非常大,尤其是动态视频,因为上下文难以通过tonkenizer压缩。一分钟的视频有超过30万个token,使用self attention的模型生成1分钟的视频开销比20个每个3s的视频大11-12倍。
为了解决这一问题,最近有很多RNN-Like的线性注意力模型被提出用于尝试代替Trasnformer,但是暂时还没有用在长视频生成这一领域。
本文基于一个只能在8-16FPS下生成3秒短视频的预训练Diffusion Transformer CogVideo-X 5B,在其基础上加入TTT层,并对模型进行微调,从而实现了从文本脚本生成一分钟长视频。训练中,self attention层仍然只作用在3s的片段上。即便如此,在仅有初步优化的系统下,我们的训练依然需要约相当于 256 张 H100 GPU 训练 50 小时的算力。 在数据方面,我们基于《猫和老鼠》卡通整理了一个约 7 小时的视频数据集,并辅以人工脚本。与通用视频数据集相比,这个数据集聚焦于多场景、长时长且运动丰富的复杂叙事 (因为这是目前最亟需进步的方向),而对视觉逼真度的要求相对低一些(业界对此已有较多成熟研究)。我们希望,这种在特定领域里提高长上下文生成能力的研究,未来可以迁移到更通用的视频生成场景中。
2. Test-Time Training Layers

2.1. TTT as Updating a Hidden State
所有 RNN 层都需要用一个固定大小的隐藏状态(hidden state)来压缩过去的上下文信息,这两者之间存在取舍:固定大小的隐藏状态使得每一步计算输出只需常数时间,但可存储的信息也相对有限。而 TTT 的核心思路是:能不能让隐藏状态的容量更大,比如像机器学习模型一样去记忆大量训练集的方式?
做法:把历史的所有token视为一个无标签的数据集,把隐藏状态视为一个机器学习模型的参数,在处理下一个token时,自监督地更新:
其中是自监督损失,是学习率。输出可以写作:
一个最简单的自监督目标是恢复,比如先把做一些遮照或者损坏,然后要求恢复,就可以有:
模型在重建的过程中学习图像的特征。总的来讲,TTT层在Test time前向传播的过程中,也对test样本进行训练。
2.2. Learning a Self-Supervised Task for TTT
TTT的关键就变成,如何设计一个合适的自监督目标。前文提到的文献的方法的做法避免手动设置mask或其他类似的策略,尝试采用端到端的方法。首先引入一个可学习的Low Rank投影映射,的到损坏后的输入,同理,想要恢复的标签也是另一个投影,有:
为了生成输出token还引入:
只在inner loop中更新,对三个的训练和学习都在外部训练,类比QKV。
2.3. TTT-MLP Instantiation
将上面的inner loop模型实际实现为一个两层的MLP,保留LayerNorm和残差连接,就有:
称为TTT-MLP。
3. Approach
从总体上讲,我们的思路就是在预训练好的 Diffusion Transformer 中插入 TTT 层,然后在长视频上做微调。要想让这个思路落地,需要做一系列设计选择。
3.1. Architecture
Pre-trained Diffusion Transformer.
用CogVideo-X 5B作为起点,因为很难直接从头开始训练一个超大规模的Video DiT。
Gating
如果一个刚初始化好的TTT直接放在预训练模型里面,它可能会直接破坏掉原模型的输出导致什么都学不到无法优化,因此还需要添加一个可学习的Gating机制:
然后把初始化成0.1,设为可学习,保证初期比较小。
Bi-direction
Diffusion 模型是非因果的,即生成第帧可以同时利用过去和未来的信息。但是RNN like的结构本身是因果的,因此借用一种常用的“双向”技巧,定义一个翻转操作,和:
这样顺序和原来保持一致,但是内部的TTT Layer是反着看了一遍序列的。
Modified architecture

CogVideo-X 里,每个 Transformer block 里都交替存在“自注意力层”和“MLP 层”。我们只修改其中的“自注意力层”模块,使其在自注意力计算后,增加双向的 TTT,并通过门控融合。
3.2. Overall Pipeline
Scenes and segments
我们将一个完整视频拆分为多个场景,每个场景再由一个或多个3秒的段落构成。原因是:
- 预训练模型 CogVideo-X 本身只能一次性生成 3 秒;
- 在《猫和老鼠》动画中,大多数场景时长至少 3 秒;
- 做多阶段训练时,3 秒 segment 也是一个合适的基本单元。
Formats of text prompts
推理阶段,用户可以用以下三种不同精细度的文本格式来描述要生成的一分钟视频(从简到繁):
- 格式 1 :5-8 句话概括整段剧情;
- 格式 2 :大约 20 句话,基本上一段话描述 3 秒片段,可选地对场景做一些标注;
- 格式 3 :非常详细的脚本(storyboard),每一个 3 秒片段用 3-5 句话描述。并用
<scene start>和<scene end>来明确标出场景边界。
训练时我们只用格式 3——因为它最详细、也最方便训练;在推理时,如果用户只写了简短描述(格式 1/2),就调用 Claude 3.7 Sonnet 把它们扩展为格式 2,再扩展到格式 3。
From text to sequences & Local attention, global TTT
对于原来的视频ViT,是把文本和视频token拼在一起,让Transformer生成。本文的方法来说,是每三秒的文本和噪声token拼在一起,最后把所有的输出拼起来组成完整的时序。因为如果还是用self attention处理整个序列的话,开销就太大了。
3.3. Fine-Tuning Recipe and Dataset
Multi-stage context extension
做长视频生成最常见的思路是分阶段扩展上下文长度。我们也采用同样思路:
- 先用 3 秒片段微调整个预训练模型,让它适应《猫和老鼠》这种卡通域;此时 TTT 层和门控参数是随机初始化的,学习率较高;
- 然后在 9 秒、18 秒、30 秒、63 秒长度的视频上依次微调,只有 TTT 层、门控以及自注意力参数会更新,学习率也更低,以避免“灾难性遗忘”预训练阶段学到的通用知识。
Super-resolution on original videos
我们收集了 1940-1948 年出品的 81 集《猫和老鼠》,每集约 5 分钟,总计 7 小时左右。原视频的分辨率较低,我们先用视频超分模型把它们统一到 720×480 的分辨率,以提升视觉质量。
Multi-stage dataset
我们让标注员先将每集拆分成多个场景,再从中切分 3 秒 segment,然后给每个 segment 写一段描述文本,这样就得到阶段 1 的微调数据:大量 3 秒片段和对应脚本文字。
在后续阶段,为获得 9 秒、18 秒、30 秒和 63 秒训练样本,我们直接把相邻的 3 秒片段拼起来,并把脚本文本也拼接,标出场景边界。同样保存为格式 3。
3.4. Parallelization for Non-Causal Sequences
因为不好并行,所以考虑mini batch的方法:
也就是在mini batch内部是不更新的,完成了整个mini batch后再更新,这样不更新的时候内部是并行的。
3.5. On-Chip Tensor Parallel
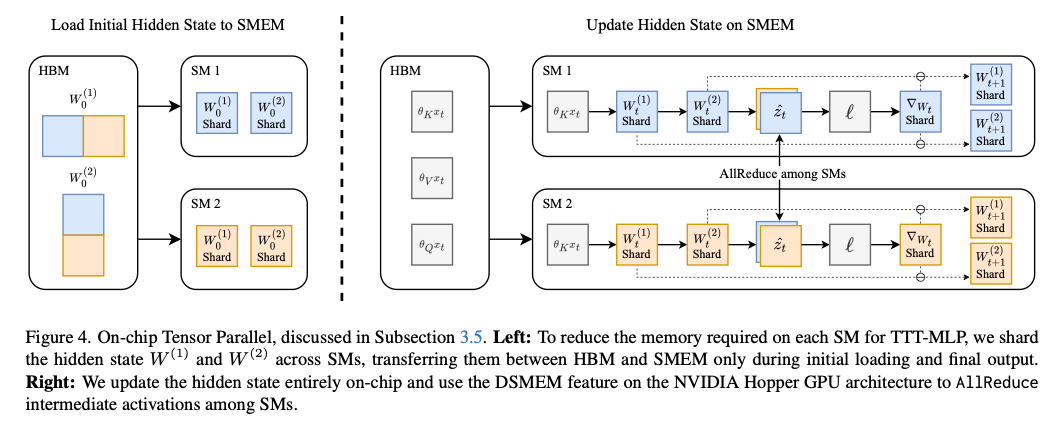
要在 GPU 上高效实现 TTT-MLP,需要巧妙利用 GPU 的分层内存结构。NVIDIA GPU 上的所有 SM 共享一个大的全局显存,每个 SM 又有少量但速度极快的片上存储。若在计算过程中频繁读写 HBM,会显著拉低速度。
Mamba 或 Flash Attention等方法使用内核融合来尽量把数据留在 SMEM,只在开始与结束时读写显存。但对于 TTT-MLP,由于它的隐藏状态量级太大,单个 SMEM 放不下。
为此,我们借鉴了Tensor Parallel的思路,将在多个 SM 之间切分。每个 SM 只存放对应的那部分参数,并在需要时做 AllReduce 合并,过程使用 NVIDIA Hopper 架构里的 DSMEM(Distributed Shared Memory)功能。
4. Evaluation
我们在多个维度上对 TTT-MLP 与五个基线方法做了人类评价,基线都保证在长序列上是线性复杂度,包括:局部注意力(local attention)、TTT-Linear、Mamba 2、Gated DeltaNet、以及滑动窗注意力层。
4.1. Baselines
除了局部注意力外,所有基线方法都基于相同的预训练 CogVideo-X 5B,通过第 3.1 节所述方式插入各自的 RNN 结构或注意力,并做微调,总参数量都是 7.2B。它们的区别在于 RNN 或注意力层的具体实现:
- Local attention(局部注意力) :不改任何结构,保留原有 3 秒内的自注意力。
- TTT-Linear :将内环模型 ff 简化为线性层,即隐藏状态仍通过内环更新,但不包含非线性。
- Mamba 2 :一种现代的 RNN(线性注意力变体),其隐藏状态是一个矩阵,比 TTT-Linear 大约大 4 倍,但比 TTT-MLP 小约 2 倍。
- Gated DeltaNet :在 Mamba 2 和 DeltaNet的基础上做了更优的更新规则。
- Sliding-window attention(滑动窗注意力) :限制自注意力的窗口大小为 8192 个 token(对应约 1.5 秒)。
4.2. Evaluation Axes and Protocol
我们从 MovieGen的六个指标里选取了与本任务相关的四个,并让人工标注员对每一对视频进行盲测对比 (pairwise preference),以保证评价更公平。这四个指标是:
- 文本符合度(Text following) :视频与脚本中描述的情节和要素是否契合。
- 动作自然度(Motion naturalness) :角色动作、表情、物理规律(如重力)等是否违和。
- 美学质量(Aesthetics) :整体的视觉吸引力,包括色彩、灯光、摄像机效果等。
- 时间一致性(Temporal consistency) :在场景内以及场景之间,角色、背景和物体的连贯性如何。
评价方式:
- 我们先由 Claude 3.7 Sonnet 生成 100 个文本脚本(格式 1→2→3),每个脚本都可以生成一段 63 秒的视频。
- 用上面所提的 6 个模型(含 TTT-MLP 和 5 个基线)分别去生成视频,总计 600 段。
- 将每个脚本所对应的 6 段视频两两配对,并随机抽取一个指标,让标注员在不知道视频来源的情况下,对该指标进行“二选一”比较。
标注员招募于 prolific.com,要求:
- 居住在美国;
- 以英语为母语;
- 18-35 岁;
- 至少提交过 100 个任务且通过率 ≥ 98%。
4.3. Results

-
TTT-MLP 提升了 34 分 Elo 分值
相较于第二名,TTT-MLP 平均领先 34 分,说明在一分钟的视频上,TTT 层有明显优势。
在 Chatbot Arena 里,GPT-4 比 GPT-3.5 Turbo 高 46 分,GPT-4o 比 GPT-4 Turbo 高 29 分,所以 +34 分算是一个相当可观的提升。
-
用户在评价时最看重的几项:场景一致性、动作连贯性
从表中可以看出,TTT-MLP 在时间一致性 上尤为突出(+38),在动作自然 上也显著好于对手(+39)。

18-second elimination round
在表 1 中,“局部注意力(Local Attention)”和 TTT-Linear 没有出现,因为我们在最终 63 秒评测前做过一次18 秒视频的预选排位 ,局部注意力和 TTT-Linear 表现较弱,被淘汰。
Limitations
-
短上下文时 TTT-MLP 不占优
在 18 秒测试中,Gated DeltaNet 平均排名第一,比 Mamba 2 和 TTT-MLP 分别高 27 与 28 分。这说明在中等长度(18 秒,约 10 万 token)时,矩阵隐藏状态的 RNN(如 Gated DeltaNet、Mamba 2)可能更高效也更准确。
-
速度仍有差距
虽然我们对 TTT-MLP 做了片上并行等优化,但它在推理和训练上的速度依然不及 Gated DeltaNet 和 Mamba 2。图 6 展示了在 63 秒视频上,相对“局部注意力”需要的时间倍数:
-
Full Attention: 生成或训练时间是局部注意力的 11× / 12×;
-
TTT-MLP: 2.5× / 3.8×;
-
Gated DeltaNet: 1.8× / 1.8×。
因此 TTT-MLP 尽管远优于全局注意力,但仍慢于其他 RNN。
-
-
视频伪影
TTT-MLP 尽管能生成看起来连贯的卡通故事,但仍存在各种伪影(artifact),如图 7 所示:边界处的角色变形、对重力建模不足导致角色“飘”、灯光和相机运动不够准确等。这些问题并非 TTT 特有,其他方法也会出现。我们怀疑根源是底层预训练模型(CogVideo-X 5B)本身的能力有限。如果用更大的视频扩散模型做预训练,可能得到更好的物理与视觉逼真度。
5. Related Work
有一些“故事生成”工作针对一段文本,分段生成若干图像或视频,但通常需要额外组件以在段与段之间保持一致性,和我们的方法(通过统一模型处理长序列)有所区别。
6. Future Work
我们认为可以从以下方向继续改进:
-
更快的实现
虽然我们已经做了片上并行等优化,但目前的 TTT-MLP 内核在寄存器溢出、异步指令调度等方面还不够极致,未来可以进一步改进实现细节来提升效率。
-
更好的集成方式
本文仅使用了一个“自注意力后 + 双向 TTT + 门控”的简单方案。或许可以设计更优雅、更高效的架构,把 TTT 层与预训练模型融为一体。此外,也可以在自回归或其他类型视频生成模型中尝试 TTT 的集成方式。
-
更长视频,乃至更大的隐藏网络
我们的方法可以自然地推广到更长的视频,关键是能否让 TTT 的隐藏网络本身拥有更大容量。例如把 ff本身做成一个 Transformer 而不是两层 MLP,以存储更丰富的上下文信息。
感觉这里的TTT其实主要是被用来做帧间的信息迁移的,local信息还是用self attention全部覆盖,segment之间用TTT传递信息,这种做法还蛮有道理的。这个模式不知道怎么改到SNN上面比较好,过一段时间尝试一下做一做SNN Fast Weight?