摘要: 稀疏性正成为探索效率和可扩展性的最关键维度,尤其是在深度学习模型变得越来越大和复杂的情况下。毕竟,深度学习所借鉴的生物神经网络本质上是稀疏且高效的。我们提倡通过一种称为带稀疏属性张量(Tensor-with-Sparsity-Attribute, TeSA)的新抽象来实现端到端的模型稀疏性,该抽象增强了默认张量抽象,而后者基本上是为密集模型设计的。TeSA使得可以在整个深度学习模型中指定、前向传播和反向传播稀疏属性和模式(例如,用于剪枝和量化),并用于创建高度有效、专门化的操作符,同时考虑不同稀疏模式在不同(感知稀疏)硬件上的执行效率。最终形成的SparTA框架能够容纳各种稀疏模式和优化技术,与七种最先进(稀疏)解决方案相比,在推理延迟方面提供1.7倍至8.4倍的平均加速,并具有更小的内存占用。作为一个端到端模型稀疏框架,SparTA促进了稀疏算法以探索更好的稀疏模型。
1. Introduction
Unfortunately, deep learning systems are not yet effective in exploiting sparsity: the increase in sparsity might not translate into actual gains in efficiency for a variety of reasons. First, the computation kernels for general sparse operations remain far from optimal. For example, cuSPARSE, the CUDA library for sparse matrix operations, has been shown to underperform cuBLAS, its dense counterpart, even when the sparsity of the matrices reaches 98%. Second, as DNN computation usually takes multiple stages, the sparsity pattern might vary significantly across stages, making it hard to develop sparsity-aware optimizations for end-to-end gains. Finally, any effective sparsity-aware optimization might involve additional support across the vertical stack, from the deep learning framework, compiler, optimizer, operators and kernels, and all the way to hardware. Insufficient support at any of the layers could lead to inefficiency.
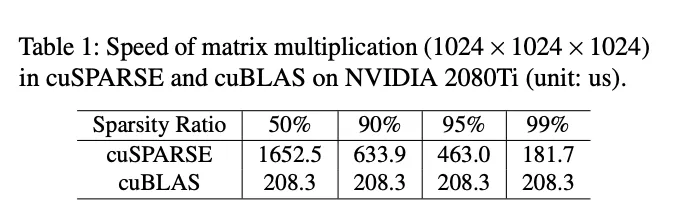
- 稀疏算子本身的实现不够好,cuSPARSE比cuBLAS还慢;
- ANN推理的过程中稀疏的模式可能发生变化,设计一种end2end的稀疏优化方法比较困难;
- 整个稀疏的设计需要在整个推理/训练的流程上面做支持,任何一环不好都可能导致整体的效率很差。
sparTA希望把稀疏性作为“first-class citizen”,提出一个叫做Tensor-with-Sparsity-Attribute,TeSA的抽象。
2. Background and Motivation
The myth of FLOPs: 现在的模型稀疏化之后讲的也都是“不掉点”,一般用FLOPs下降多少多少来反映自己的剪枝的能力,但实际上模型的FLOPs数和模型实际在inference的过程中究竟能有多少加速其实并不对等,有的时候做了剪枝加上稀疏算法之后,推理的延迟反而更高了。另一方面,很多稀疏加速的工作只针对一整比较general的稀疏编码(比如行压缩)做加速,但实际上会错过很多inference过程中产生的其他稀疏模式,降低了对稀疏的利用率。
The diminishing end-to-end returns: 有的工作比较侧重于优化一些特定的算子,但是这种算子放进一个完整的模型的时候,整个模型的稀疏模式实际上会变得相当复杂,比如下图:
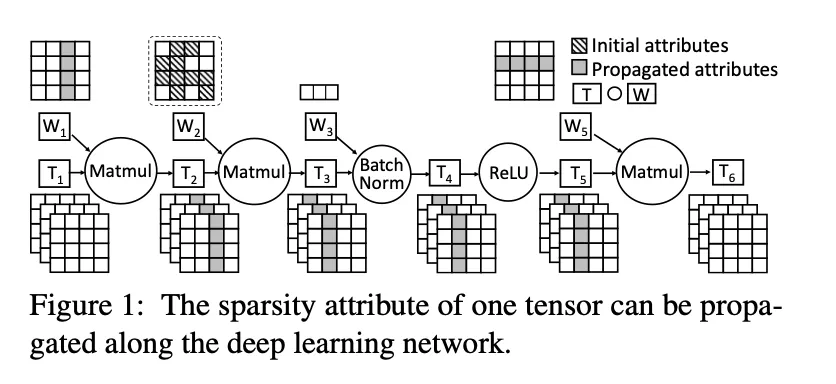
是一个非结构化稀疏的tensor,它的稀疏模式会传播到上下游所有的kernel中。比如,如果把的第二列剪掉,那的第二列也一定是全0。这种稀疏传播的模式不是局限在一个Kernel中的,因此针对一个Kernel做的工作实际上就缺乏这种优化。
3. SparTA Design
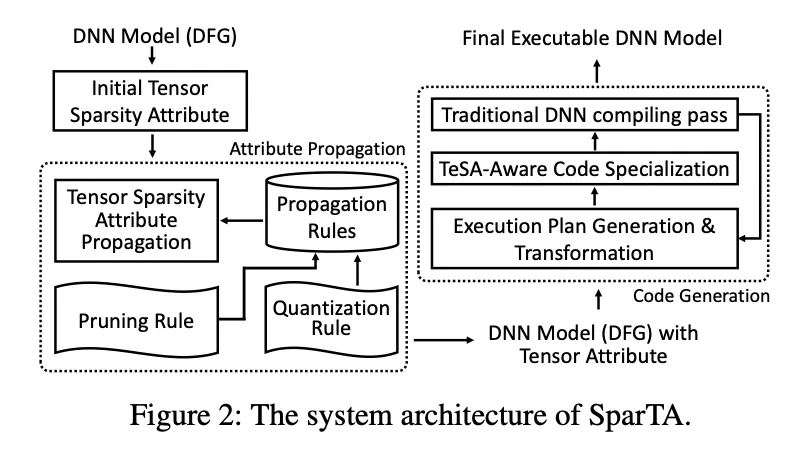
SparTA的核心是TeSA抽象,它在现有张量抽象中增加了稀疏属性。
DNN加载的时候首先有一个初始的稀疏模式,然后SparTA根据稀疏传播等方法进一步优化和剪枝,多次执行上面的流程之后再生成高效的end2end的代码。
3.1. The TeSA acstraction
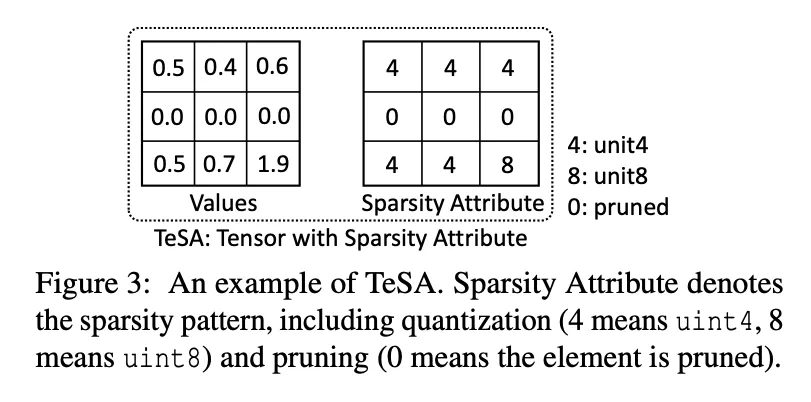
给每个Tensor添加一个额外的Tensor专门用来描述稀疏性和量化,但是这个tensor只在编译阶段存在,不会带来实际的runtime latency overhead。
3.2. Sparsity Attribute Propagation

Intra-operator propagation: 如果某个kernel的输入/输出的TeSA属性被更新了,那就要根据特定的规则更新与它相关的其他Tesnro的TeSA属性,一直迭代直到所有的TeSA属性都不再变化。有的更新是双向的,有的更新是单向的,取决于算子的类型。
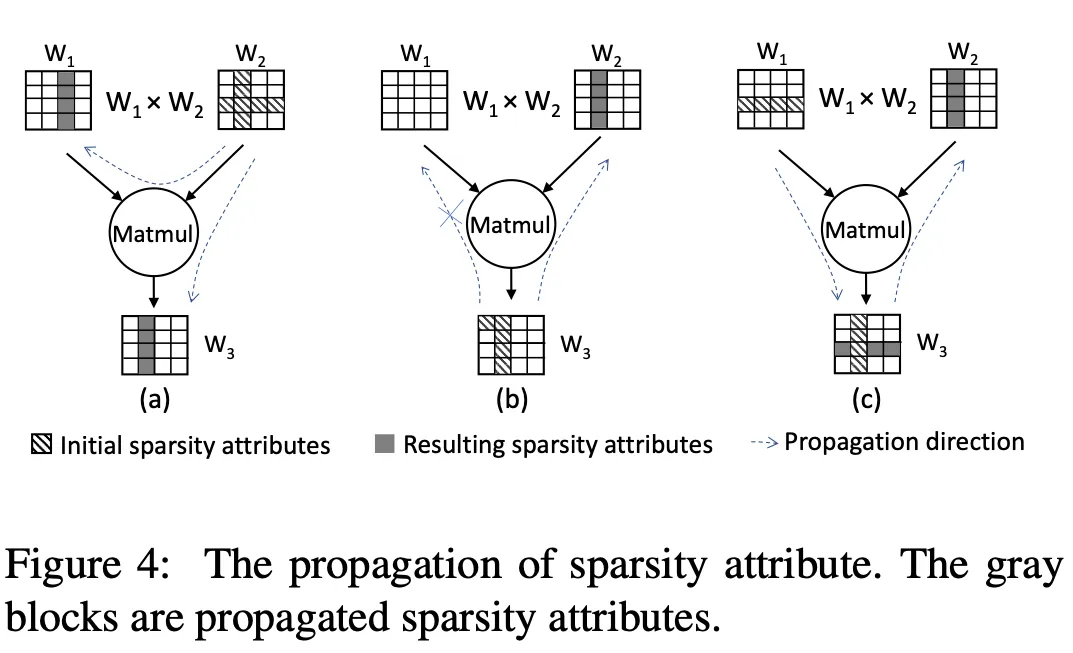
而对于量化类型的传播则不太一样,如果一个kernel的输出是低精度的,但是输入的精度很高,那么输入的张量则有可能可以替换成更低精度。
Pruning rule: 剪枝的过程也取决于operator的计算逻辑(比如或者,对应的剪枝传播方法就不一样)。SparTA定义了一套“TeSA代数“,将element-wise的操作映射为一个由两种元素组合而成的集合:
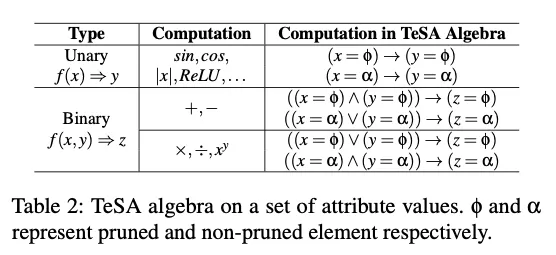
也支持添加自定义规则。
SparTA还支持通过概率传播来处理黑盒/复杂算子,称为张量扰动(Tensor Scrambling)。假设该算子已有稠密版本,将某个元素设为0,然后随机赋值其他元素,运行并统计输出为0的元素,重复多次,将输出始终为0的认为是这个设为0元素对应的需要剪掉的元素。很依赖于编译期间用来校准的数据?而且如果kernel非常复杂/规模非常大,这种剪枝方法的耗时就会非常高,对于现在的LLM workload可能不实用?
由于稀疏不仅从输入传播到输出,还可以反向传播,SparTA利用AutoGrad机制实现这种反向传播。假设某个op具有输入和输出,则反向传播的时候包含和梯度。根据AutoGrad的性质,与有相同的TeSA(包括形状和性质),则可以像前面那样传播TeSA属性。

Quantization rule: 在量化的时候如果碰到了输入bit高于输出bit的情况下,就降低一个tensor的精度,然后根据calibration数据做微调,然后检查输出和原op输出的MSE,一直持续这个过程直到精度的下降高于可接受threshold。这样做会不会速度很慢?
3.3 Code Generation with TeSA
完成了TeSA属性的传播之后,稀疏的模式可能会变得很复杂,处理起来会很困难。SparTA将具有复杂稀疏模式的张量分块成多个具有更简单稀疏模式的张量,然后重写对应的执行模式。
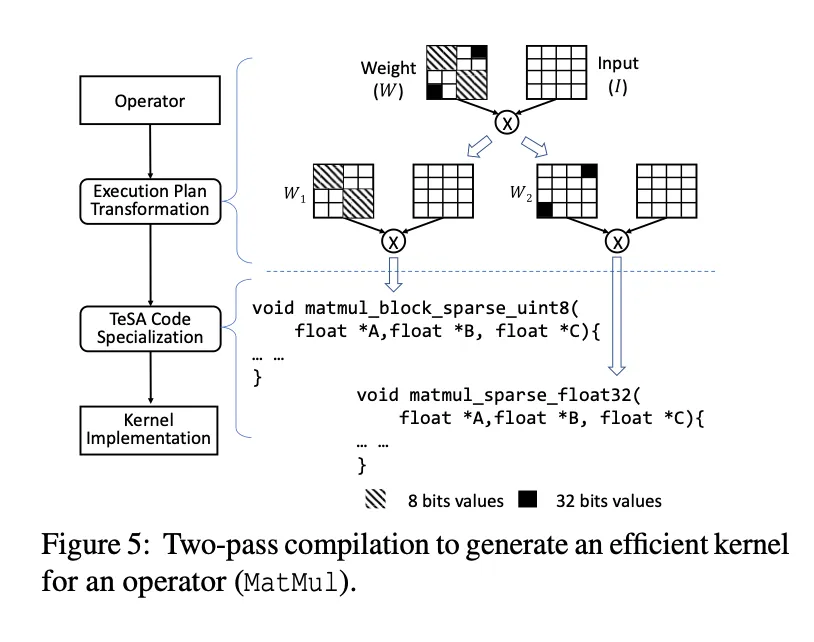
Exucution-plan transformation: 将复杂的稀疏模式转换为“规则的稀疏“:TeSA中一个Tensor只呈现出一种类型的量化属性和一种block size的剪枝属性。

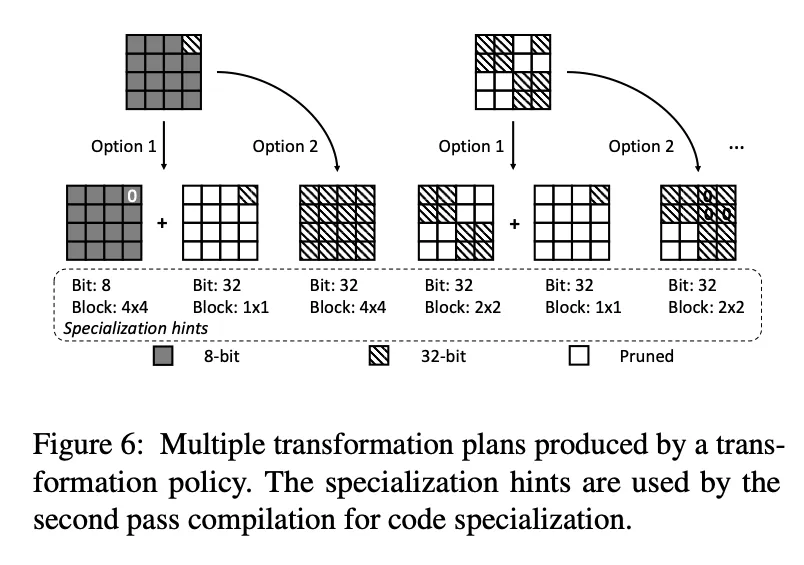
这个搜索的过程可能会有多种可选的模式,SparTA会遍历每一种,并且寻找寻合适的一种,如下图所示,这两个block都有多种不同的粉个方法。
TeSA code specialization: 第二个编译pass给每个op进行Kernel内部的代码优化。前一轮生成的Specialization hints可以指导这一步是否使用特定的硬件命令(比如GPU上的DP4A 8Bit乘加指令)。SparTA利用现有的DNN编译器给块内稠密的op直接生成稠密的kernel。
SparTA首先从稠密的DNN算子开始,根据前面生成的block大小做tiling。考虑到中间有些块可能完全是空的,引入了一种“dismantle”(拆解)原语,用来消除这些完全空的块,并进行循环展开。这个流程是从最外层循环开始的。
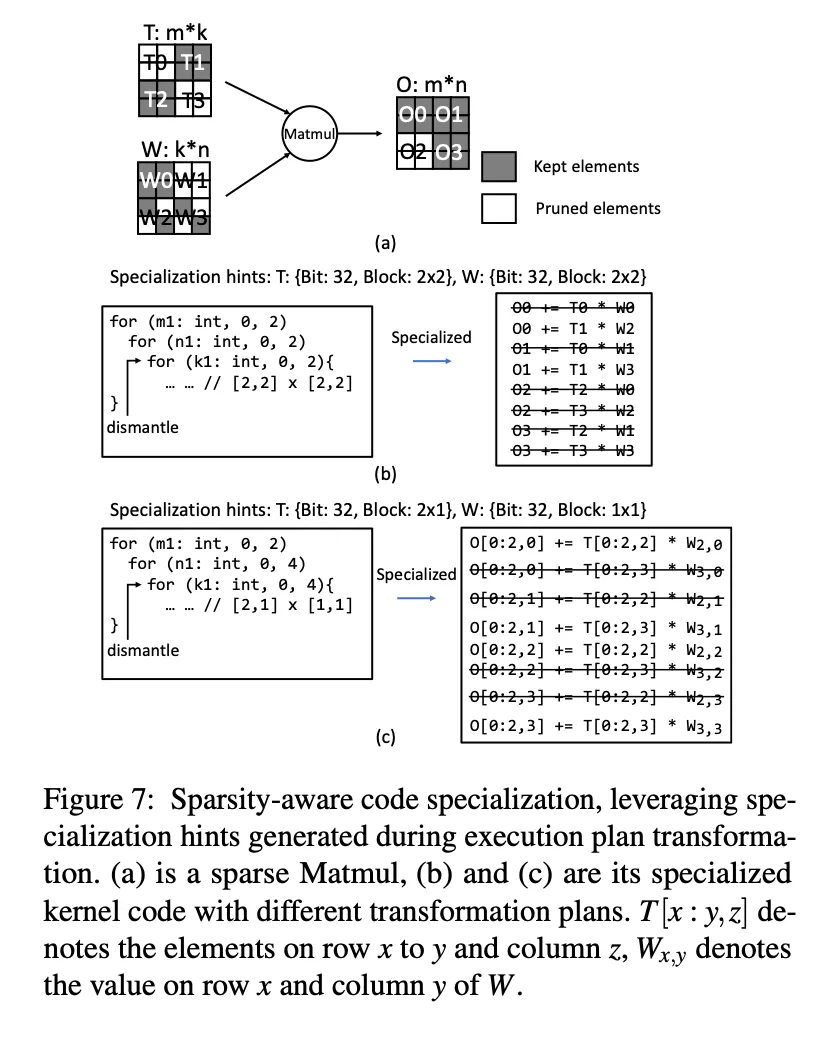
而对于量化过的算子,这个过程需要从最内层循环开始,不断使用硬件支持的指令替换内部的操作和对齐。
整个过程像当于是先做算子的划分,把难以优化的、复杂的大算子,划分成相对而言比较规则的、小的算子,然后在通过指令替换、循环展开等各种功能优化这些小的算子。
4. Implementation
基于Rammer实现,Rammer原生不支持稀疏。TeSA每个元素有2Byte,7bit记录位宽,4bit标识格式(uint, float32, bf16…),剩下的保留。位宽为0的元素认为被剪掉了。为了做前面的覆盖和分块,SparTA需要估计不同block size的性能,使用dense的情况下不同的block size测算不同的kernel latency,然后除以block数量,可以计算得到“单位block开销”。
5. Evaluation
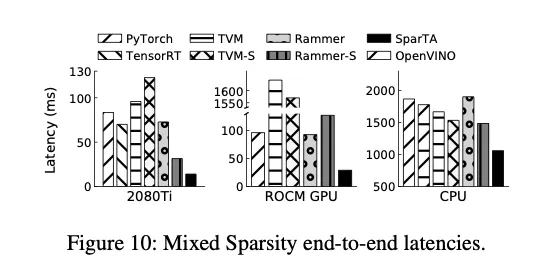
- SparTA significantly reduces the inference latency of sparse DNN models with less memory consumption. The speedup is up to 10.6x, 5.0x, 7.5x, 20.1x, 5.8x, 5.6x, 1.7x over PyTorchJIT, TensorRT, TVM, TVM sparse2, Rammer, Rammer sparse3, and OpenVINO (CPU), respectively. The average speedup is 3.8x, 2.6x, 4.2x, 8.4x, 3.0x, 3.2x, 1.7x.
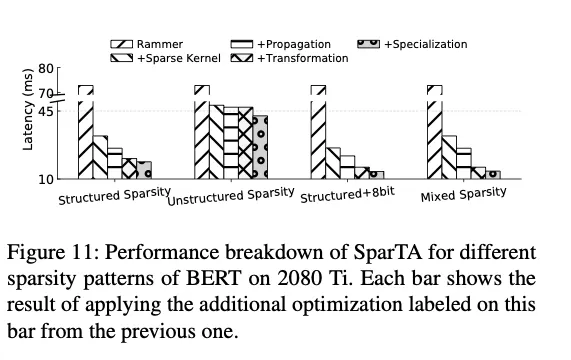
- Sparsity attribute propagation increases the end-to-end sparsity ratio by up to 39.7%. With execution plan transformation and code specialization, SparTA can achieve up to 6.7x speed up over the state-of-the-art sparse kernel implementation for a sparse DNN operator (e.g., Matmul) with complex sparsity patterns.
- SparTA facilitates the development and exploration of sparse DNN models, producing DNN models with lower inference latency and/or higher accuracy.
- SparTA 显著降低了稀疏 DNN 模型的推理时延并减少了内存消耗。
- 通过传播稀疏属性,模型的整体稀疏度最多可提升 39.7%。
- SparTA 有助于开发和探索稀疏 DNN 模型,带来更低的推理时延和/或更高的准确度。
5.1. End-to-End Experiments
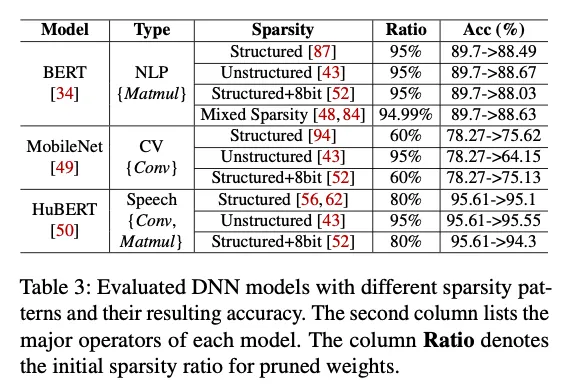
- Structured:按row/col/channel剪枝;Unstructured:按element剪枝;
- 量化是对其他所有元素量化;
- “Mixed Sparsity”:先Structured+8Bit剪枝,然后对于一些已经剪掉的元素,用32B量化+Unstructured重新处理;
对比对象:PyTorch1.7+JIT, TensorRT v7.2, OpenVINO, TVM, Rammer, Rammer + (cuSPARSE, taco, Sputnik, hipSPARSE, MKL Sparse LA), TVM + Sparse…。
在2080Ti, AMD Radeon VII和Intel Xeon Silver4210CPU上跑实验。
5.1.1. SparTA on CUDA GPUs

结构化稀疏的模式下,优势主要来源于:
1. 稀疏传播提高了稀疏度
2. 稀疏转换的tiling效果更好非结构化稀疏的模式下,上面的优势带来的提升更大。
TensorRT支持用硬件指令处理8B量化,在结构化稀疏+8B量化下效果很好。
5.2. Sparsity Attribute Propagation
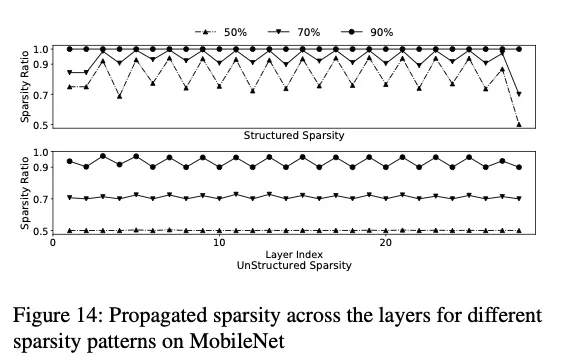
稀疏传播提高了稀疏度,注意到由于MobileNet是DS Conv和Dot Conv交替出现,OP的稀疏传播能力不同,出现了稀疏度的锯齿状变化。
稀疏传播基本在结构化稀疏上比较好,在非结构化稀疏上效果一般,因为非结构化稀疏的剪枝已经剪得很厉害了,再剪模型直接没了。
Interestingly, when the original sparsity ratio is 90%, after propagation the sparsity ratio becomes 100%, which explains the anomaly that, although there are 10% filters left on each convolution (before propagation), the model’s accuracy is similar to a random image classifier.
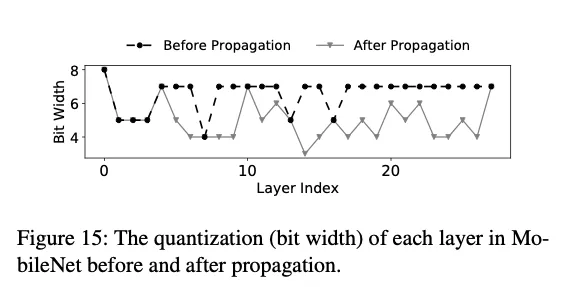
From another point of view, our propagation rule for quantization is complementary to the search algorithm (e.g., reinforcement learning, simulated annealing) on quantization bits. A proper combination of them could improve search efficiency, which is an interesting future work.
5.3. Efficient Code Generation with TeSA
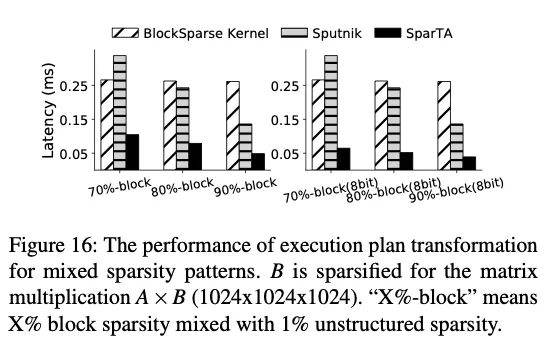
在矩阵乘上和BlockSparse(自己实现的32*32块稀疏OP)和Sputnik做对比,主要还是块状稀疏的浪费问题。
SparTA还能选取合适的block利用GPU上的Sparse Tensor Core做计算。
5.4. Augmented Model Sparsity Exploration
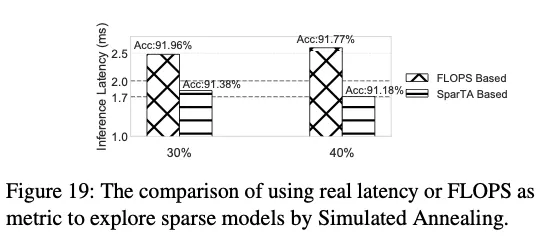
使用FLOPs作为剪枝的目标不能真实反映模型的推理速度,用Latency更好(对于降低latency/推理开销而言)。
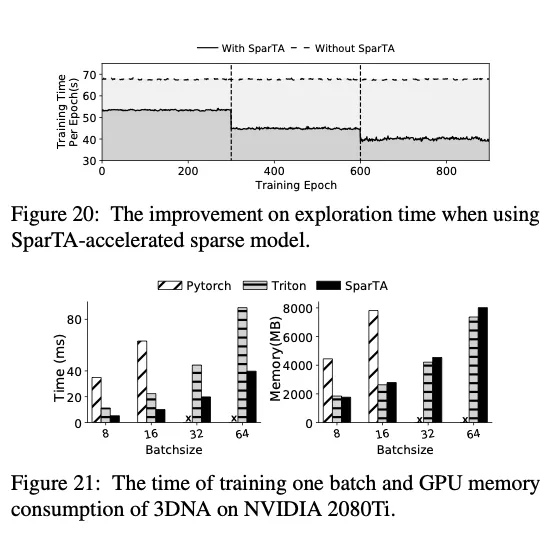
5.5. Accelerating Sparse Model Training
6. Related Works
Sparsity support in DNN frameworks and compilers: 重点是捕捉稀疏模式,面向DNN整体做代码生成,比只采用一个简单的Kernel/用户提供的稀疏模版效果更好。
Sparsity acceleration of DNN models: 更高效的数据格式,重点还是减少访存。
Sparsity exploration on DNN models: 剪枝,…
7. Conclusion
SparTA采用了一种原则性的系统方法来建模深度学习中的稀疏性,中心是新的TeSA抽象。SparTA旨在适应丰富的稀疏模式,端到端地工作并跨越整个堆栈,以支持稀疏模式的传播和利用这些模式的优化,并利用编译器技术和硬件支持,所有这些都在一个可扩展的框架中。SparTA不仅可以促进优越的稀疏引起的加速,还可以在统一框架内首次加速模型稀疏创新。