0. Main
人脑在完成一系列复杂任务的同时只需要2W左右的功耗,而电脑实现的简单的目标分类都需要约250W能耗。目前的神经网络和人脑的原理有相似之处,但实际上相差甚远。今天,算法设计师们正在积极探索(特别是“学习”)脉冲驱动型计算的优缺点,去推动有可扩展性、高能效的“脉冲神经网络”(spiking neural networks ,SNN)。在这种情况下,我们可以将神经形态计算领域描述为一种协同工作,它在硬件和算法域两者中权重相同,以实现脉冲型人工智能。我们首先强调了“智能”(算法)方面,包括不同的学习机制(无监督以及基于脉冲的监督,或梯度下降方案),同时突出显示了要利用基于时空事件的表征。本文讨论的重点是视觉相关的应用任务,例如图像识别和检测。然后我们将探索“计算”(硬件)方面,包括模拟计算、数字神经运动系统,它们都超越了冯·诺依曼(数字计算系统的最新架构)和芯片技术(代表了基本的场效应晶体管设备,它们是当下计算平台的基础)。最后,我们将讨论算法的硬件协同设计前景,说明算法具有用于对抗硬件漏洞的鲁棒性,可以实现能耗和精度之间的最佳平衡。
1. Algorithmic outlook
按照神经元的功能,将神经网络分为三个代际。第一个代际称为McCulloch-Pitt感知机,执行阈值运算然后最终输出0或1;第二代中基于sigmoid、RELU等方法引入了非线性,使得网络可以表征更加复杂的特征、设计为更加复杂的结构和更加深的网络。SNN就是第三代神经网络,因为其中还包含了时间信息。SNN是事件驱动的,同时输入只有0和1,减少了点积运算,能耗和计算量都很低。
SNN的目前面临的问题包括:
1. SNN具有不可导的性质,没有办法通过目前的梯度下降的方法进行反向传播的训练,无法受益于目前已经很成熟的相关研究;
2. 目前基于脉冲的数据很少,目前常见的数据都是基于静态数据集(CIFAR,ImageNet),没有一个很好的benchmark来评估符合现实条件的SNN性能;2. Learning in SNNs
2.1. Conversion-based approaches
对于一个特定结构的神经网络,用某种算法将它映射为SNN的连接结构+各种权重,使得它们具有类似的输出。优点是不用考虑SNN不连续的训练问题等,可以利用目前已经存在的DNN的训练算法。缺点是直接通过转化的方法不好处理类似tanh之类的函数(常见的spike neuron一般只能处理正值,会丢弃负值),同时这种转化总是会造成精度的下降的。最近的工作还会在训练DNN的时候加入一些约束,使得这些DNN在转化为SNN之后能够更好地保持原有的性能。第三个问题是转化过来的SNN的推理time step都很高,有的需要几千个time step才能推理出结果,这样会造成能耗的升高。
2.2. Spike-based approaches
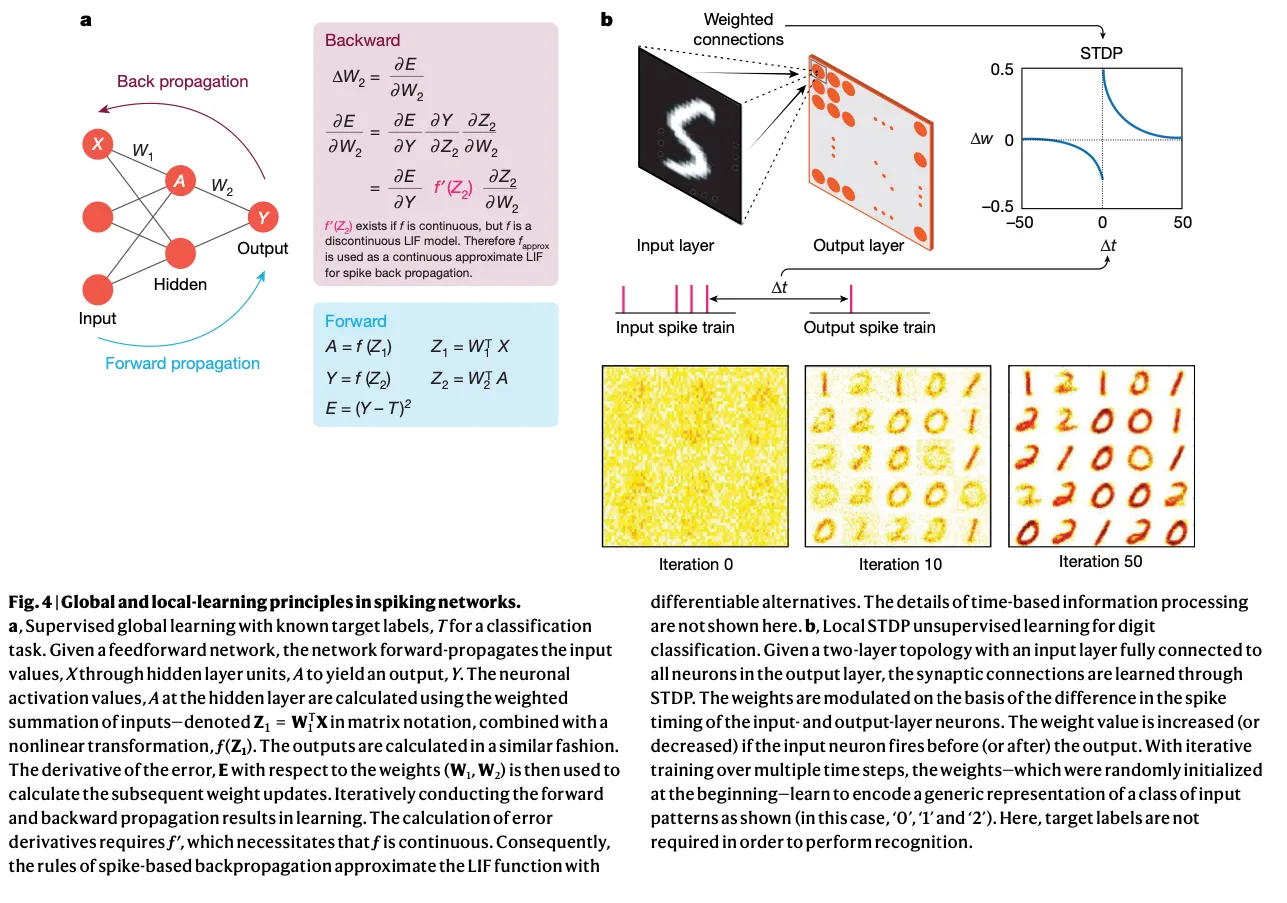
“Two main directions”: 无监督和有监督。
有监督:
Most works that rely on backpropagation estimate a differentiable approximate function for the spiking neuronal functionality so that gradient descent can be performed. However, supervised learning—although more computationally efficient—has not been able to outperform conversion-based approaches in terms of accuracy for large-scale tasks.
无监督:
This architecture turns out to be more brain-like, as well as suitable for energy-efficient on-chip implementations.
如果SNN变深,训练的时候深层的网络spike的概率越来越小,解决方法是local-global训练,layer-wise训练,但是精度一般,不如conversion。
2.3. Implications for learning in the binary regime
主要是介绍了一下Binary/Ternary NN这种超低量化的兴起,看起来能和SNN结合,但是具体的工作还是“remains to be seen”
3. Other underexplored directions
3.1. Beyond vision tasks
SNN理论上更适合处理天然有时序的数据,比如robotic中的传感器数据等。
3.2. Lifelong learning and learning with fewer data
目前的DNN在持续学习的能力上很差,学习了一个任务就会忘掉之前的任务,但是人不是这样的,SNN与人相似之处让人期待它的持续学习能力。
3.3. Forging links with neuroscience
从神经科学中学到的结构与neuron对这个领域可能会有新的启发。
4. Hardware outlook
4.1. The emergence of neuromorphic computing
1980s,Carver Mead
4.2. The advent of parallel-processing GPUs
GPU不能事件驱动,能耗太高
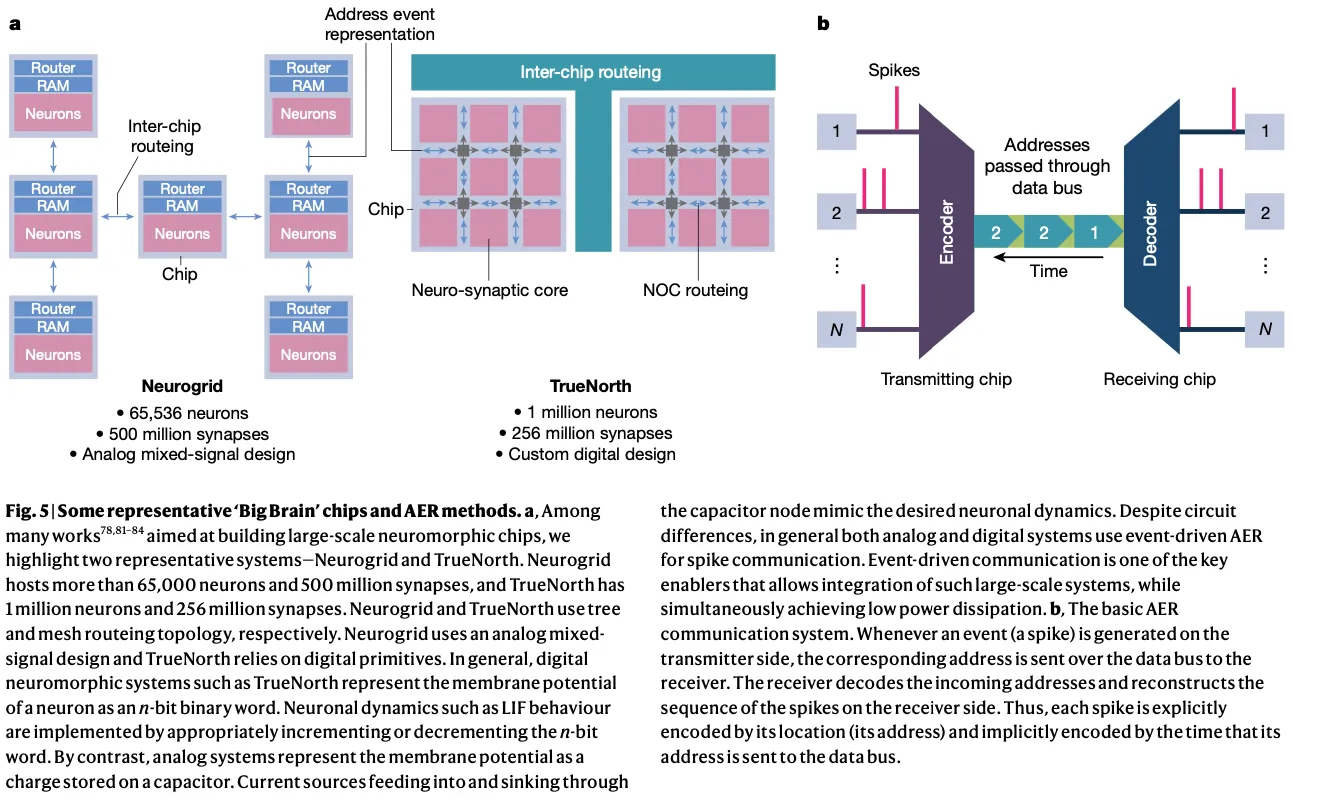
4.3. The “Big Brain” chips
Neurogrid,TrueNorth等,总体特点:
- Asynchronous address event representation.
- Network-on-chip.
4.4. Beyond-von-Neumann computing
晶体管慢慢接近了物理极限,同时传统的冯诺依曼架构逐渐遇到了内存墙等问题。但是SNN可以受益于crossbar、忆阻器等新技术实现新的超越冯诺依曼的计算模型。
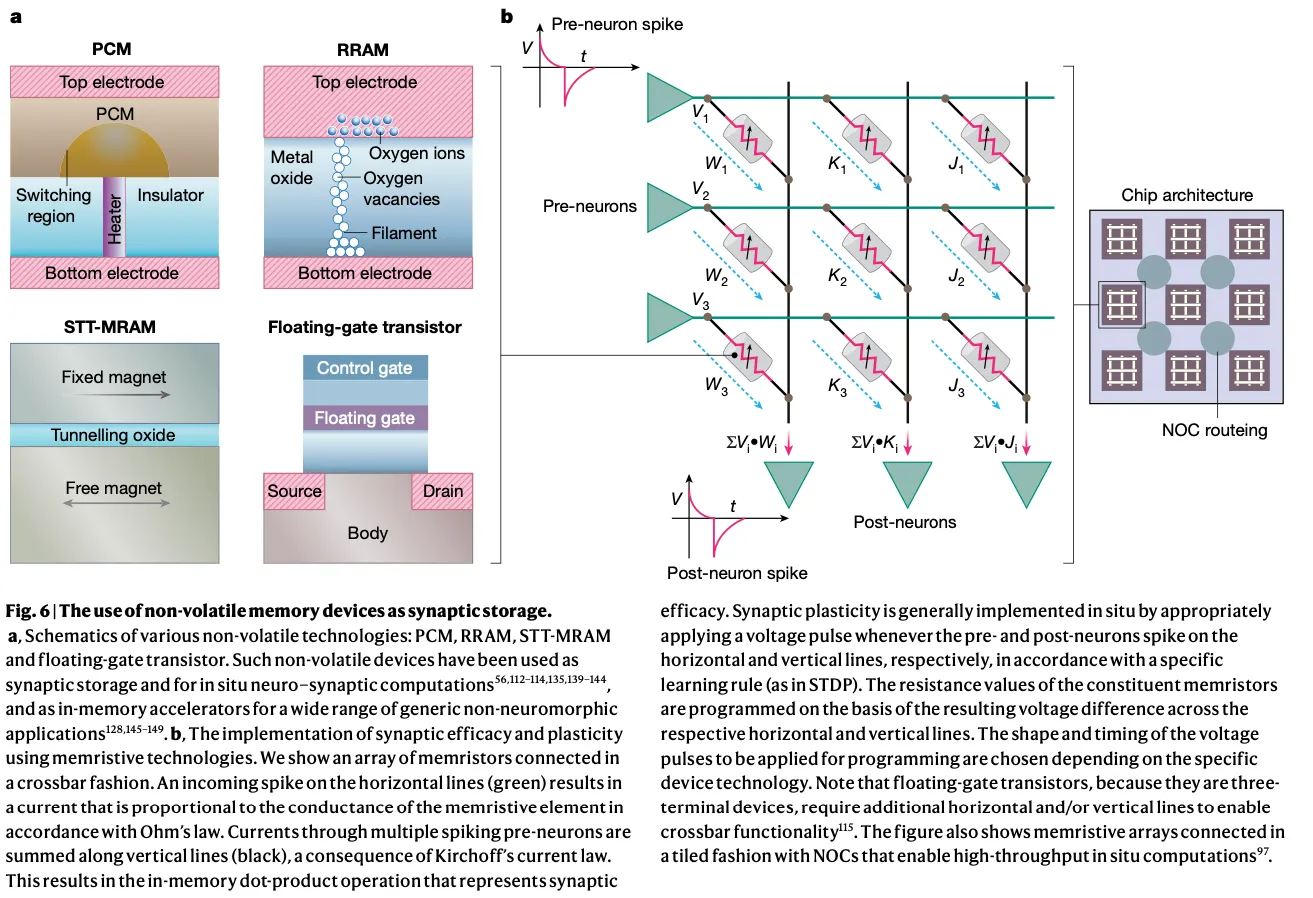
Non-volatile technologies
忆阻器类的新器件,可以根据历史信息改变自己的电阻值,然后根据欧姆定律可以在原地实现计算。
- 电阻随机存取存储器RRAM,相变存储器PCM和自旋转移矩磁随机存储器STT-MRAM等
- 浮栅晶体管
问题主要在于非理想型、本身具有一定的随机性导致写入不可靠、需要的能耗相对高等问题。
Silicon (in-memory) computing
就是各种传统的存内计算
5. Algorithm-hardware codesign
5.1. Mixed-signal analog computing
传统的纯模拟计算搜到噪声太大,最近的部分方案引入数字-模拟的混合方案,包括近似模数转换器等,旨在降低能耗的同时减少引入的模拟电路部分对准确度的影响。
5.2. Memristive dot products
基于忆阻器电路的点乘,收到非理想效应影响太大。
5.3. Stochasticity
使用类似STDP的随机局部学习的方法更新权重,实现随机二值SNN。认为STDP学习中的timestep维度提供了额外的准确度。可以尝试与基于梯度下降的方法结合,更好地利用硬件上的随机性。
5.4. Hybrid design approaches
包括计算数据的重要性驱动隔离、混合精度计算、将传统硅存储器重新配置为按需存内近似加速器、局部同步和全局异步设计、局部模拟和全局数字系统。