摘要: 归一化层在现代神经网络中无处不在,并且长期以来被认为是必不可少的。本研究表明,去除归一化的变换器(Transformers)可以通过一种非常简单的技术实现相同或更好的性能。我们引入了动态双曲正切(Dynamic Tanh, DyT),这是一种逐元素操作 ,可作为变换器中归一化层的替代品。DyT 的灵感来源于观察到变换器中的层归一化通常会产生类似于双曲正切函数的 S 形输入输出映射。通过结合 DyT,去除归一化的变换器能够匹配或超越其带有归一化对手的性能,大多数情况下无需调整超参数。我们验证了使用 DyT 的变换器在多种设置下的有效性,从识别到生成、从监督学习到自监督学习,以及从计算机视觉到语言模型。这些发现挑战了传统观念,即认为归一化层在现代神经网络中是不可或缺的,并为深入网络中的作用提供了新的见解。
1. Intro
BatchNorm、LayerNorm等已经非常流行。归一化层之所以被广泛采用,主要是由于它们在优化过程中带来的经验性收益。除了能够取得更好的结果外,它们还可加速并稳定收敛。随着神经网络的宽度和深度不断增加,这种需求变得日益关键。因此,人们普遍认为归一化层对于深度网络的有效训练至关重要,甚至不可或缺。
文章通过观察LayerNorm的行为,发现LayerNorm对输入激活进行缩放,同时压缩极端值,形成一条S形曲线。尝试提出一种Element-Wise的操作:
其中是一个可学习的参数。这个函数的行为和LayerNorm类似并且它无需计算激活统计量便可同时实现这两种效果。
使用 DyT 十分直接,如图所示:我们直接用 DyT 替换视觉或语言 Transformer 架构中的现有归一化层。我们通过实验表明,采用 DyT 的模型可以在广泛的设置中稳定训练并获得较高的最终性能,而且通常无需对原始架构的训练超参数进行调整。我们的工作挑战了归一化层在现代神经网络训练中不可或缺的传统观点,同时也为理解归一化层的性质提供了经验证据。此外,初步测量表明,DyT 可提升训练和推理速度,使其成为面向效率的网络设计的潜在候选。
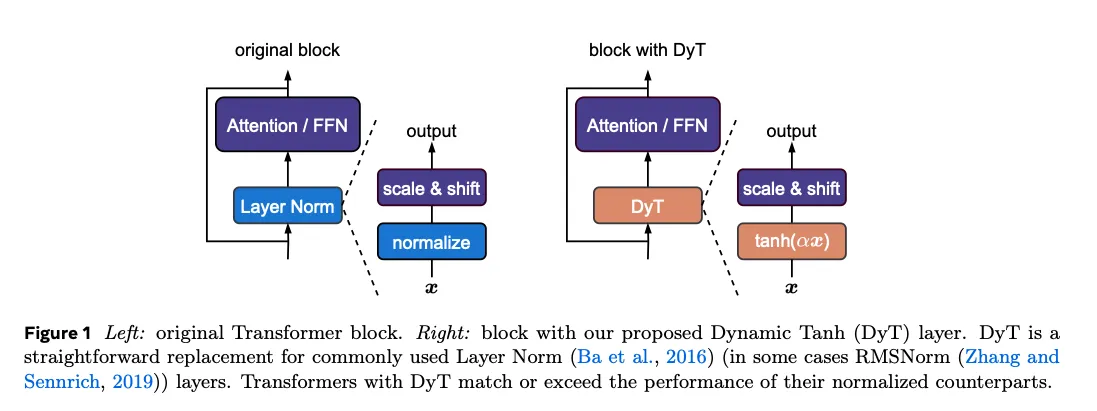
2. Background: Normalization Layers
和 是可学习向量参数,分别起“缩放”和“平移”的仿射作用,使输出可以落在任意范围。 和 表示输入的均值和方差。不同方法主要体现在如何计算这两个统计量,从而使 和 具有不同的维度,并在计算过程中进行广播。
BN在Batch和Token两个维度上计算均值方差:
LN对每个样本、每个Token单独计算统计量:。注意到这种操作计算的开销有些太大了,RMSNorm尝试解决这个问题,令:。本文中对比的Transformer依然采用LayerNorm,但是Llama采用RMSNorm。
3. What Do Normalization Layers Do?
Tanh-like mappings with layer normalization.
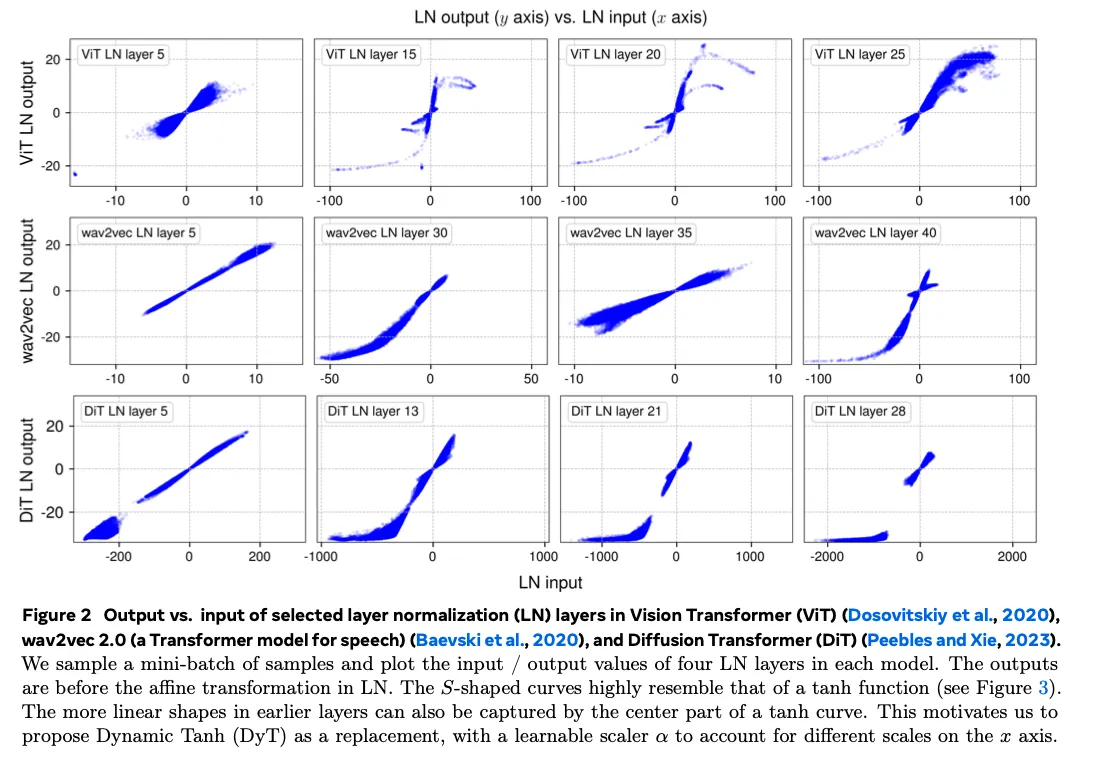
在所有三种已训练模型中,我们对一批样本做前向传播,然后记录每个归一化层的输入和输出张量,即归一化操作前后的张量(不含随后可学习的仿射变换)。由于 LN 保留输入张量的尺寸,我们可以对输入和输出中的元素建立一一对应关系,从而直接可视化它们的映射关系。结果如图 2 所示。
LayerNorm在较浅的层输出几乎为一条直线,但是越深越偏向于函数的S形曲线。在 x 接近 0 的中心区域,大部分(约 99%)数据点保持线性;而对于极端输入(例如在 ViT 中 x 大于 50 或小于 ‑50 的点),LN 会将其压缩到更温和的范围。我们推测,正是这种对极端值的非线性压缩使得归一化层在训练中至关重要。
Ni 等(2024)的最新研究也指出 LN 引入的强非线性提高了模型的表示能力。这种压缩行为与上世纪早期生物神经元在大输入下趋向饱和的现象相呼应。
Normalization by tokens and channels.
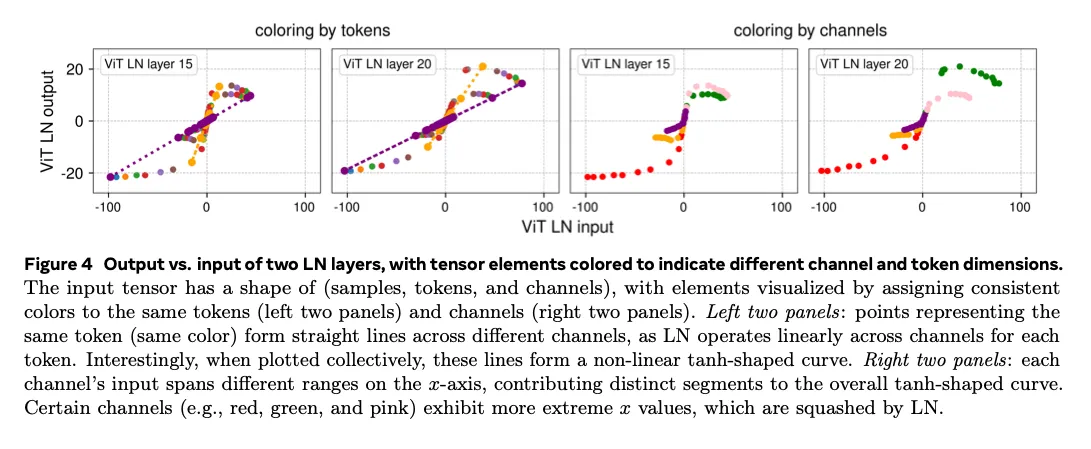
/quo LN 如何在每个 token 上执行线性变换,却整体呈现非线性压缩?图 4 通过给同一 token 或同一 channel 赋予相同颜色直观展示了答案。左侧两幅图显示:每个 token 的所有通道输出都落在一条直线上,但不同 token 的斜率不同,整体组合后便形成 S 形曲线。右侧两幅图显示:不同 channel 的输入范围差异巨大,只有少数 channel(如红色、绿色、粉色标记)出现极端值,并被 LN 强烈压缩。
4. Dynamic Tanh(DyT)
定义:
其中 为可学习标量 ,用以根据输入尺度自动调整压缩范围,与 为与传统归一化层相同的逐通道可学习缩放、平移向量。由于 tanh 本身有界,DyT 在不依赖任何激活统计的情况下即可压缩极端值。
在所有归一化层之后,我们始终将 初始化为全 1 向量,将 初始化为全 0 向量。对于缩放标量 ,除大型语言模型(LLM)外,默认初始化 0.5 已足够稳定有效;第 7 节将对 的初始化做更为详细的分析。除非特别说明,下文实验均采用 = 0.5。
5. Experiments
Supervised learning in vision.
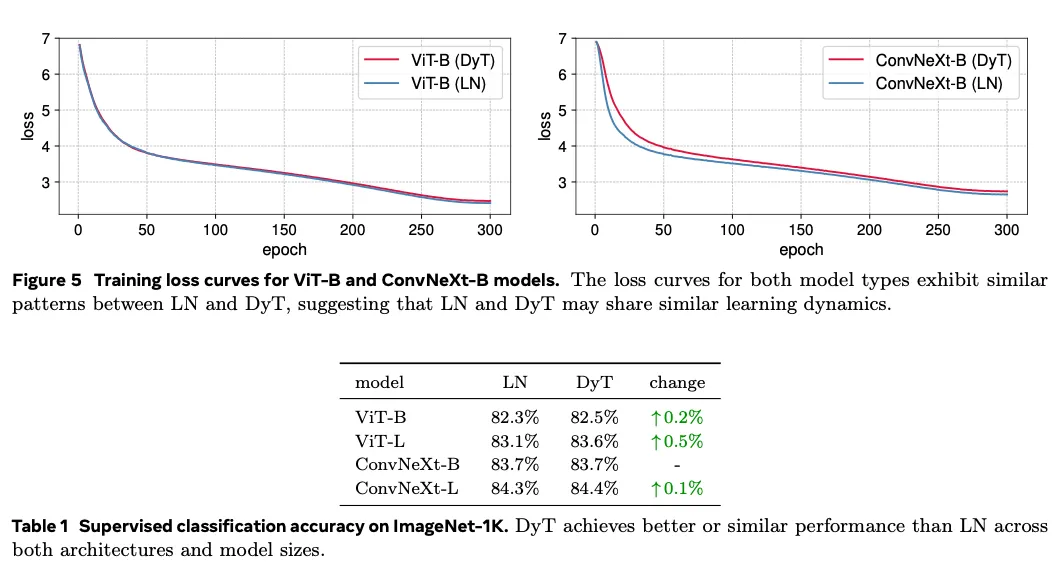
收敛曲线几乎一致,证明没有破坏优化效率。
Self-supervised learning in vision.
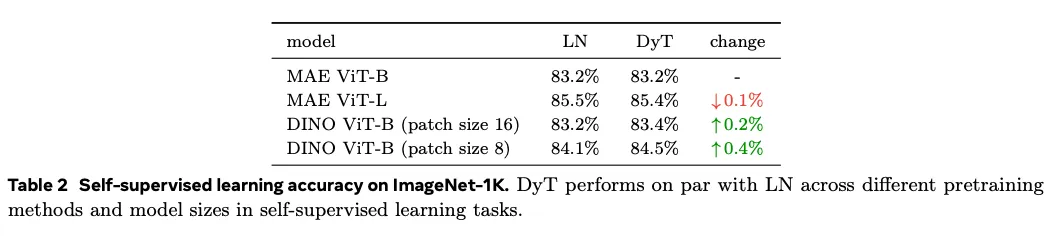
基本持平。
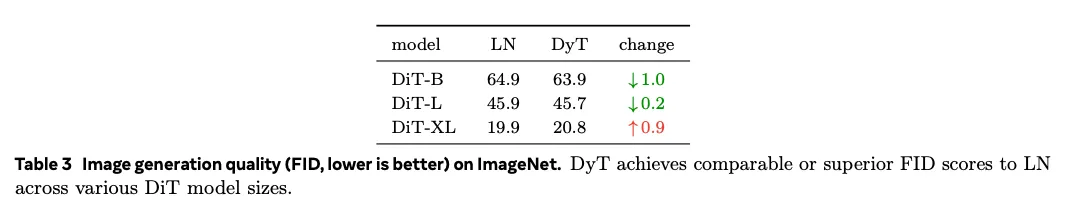
Diffusion models.
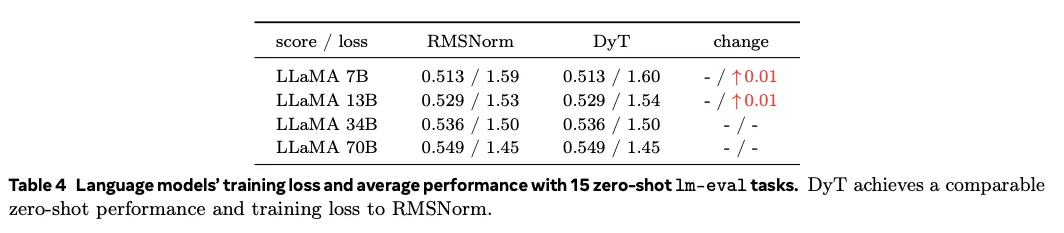
Large Language Models
Self-supervised learning in speech.

DNA sequence modeling.

6. Analysis
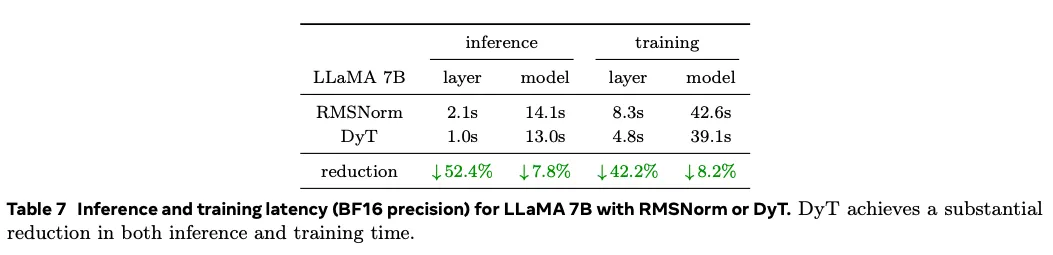
6.1. Efficieny of DyT
与 RMSNorm 相比,DyT 在层级别计算量减少逾 40%,整体模型推理/训练延迟降低约 8%。
6.2. Ablations of and
Replacing and removing .
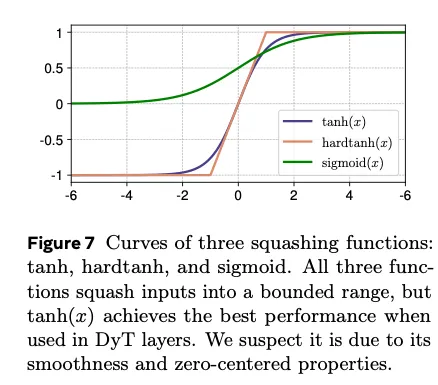
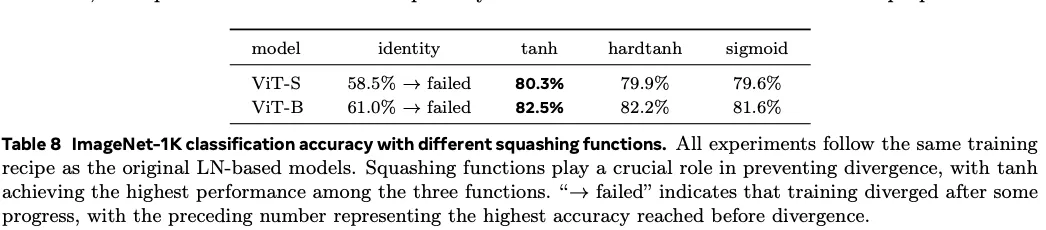
效果都不如.
Removing

6.3. Values of
During/After training
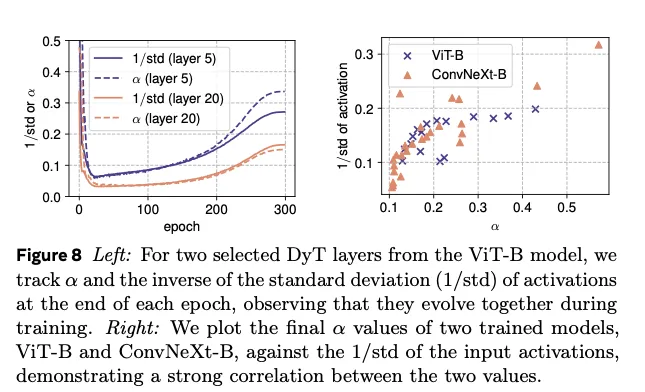
训练中和几乎同步变化,训练结束后和几乎强相关,证明起到的作用类似归一化,但是缺少非线性,需要与结合。
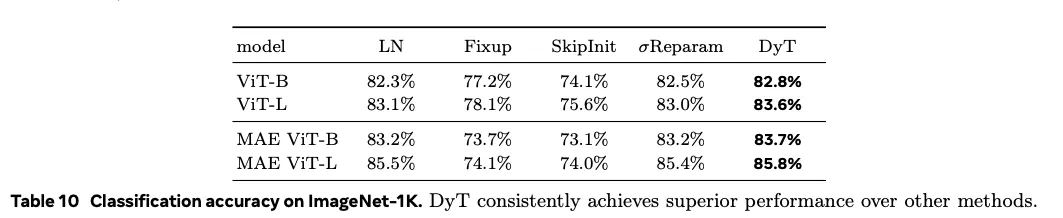
6.4. Comparison with Other Methods
7. Initialization of
DyT 中缩放标量的初始化值(记作 α₀)通常不会显著提升性能,唯一的例外是大型语言模型(LLM)训练 。
7.1. Initialization of for Non-LLM Models
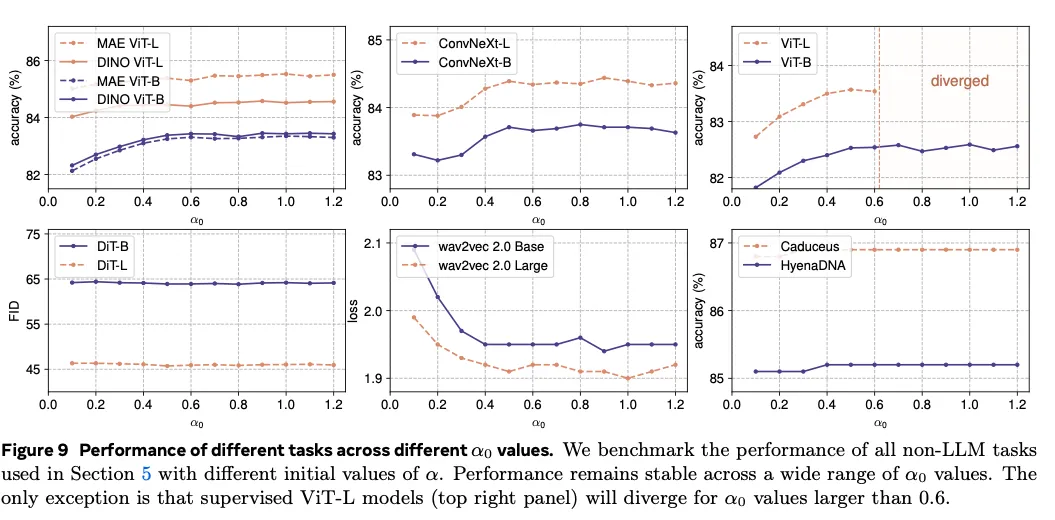
综合实验可知:
- 模型越大或学习率越高,所需 越小;
- 若使用较大的 ,需要相应调低学习率以维持稳定。
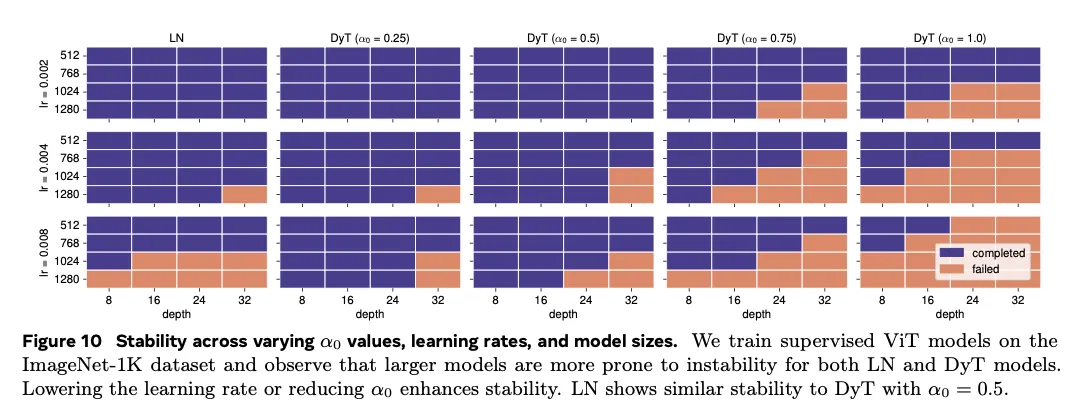
7.2. Initialization of for LLMs
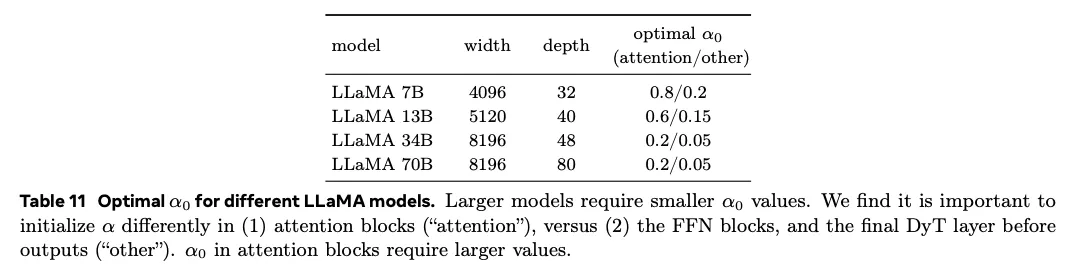
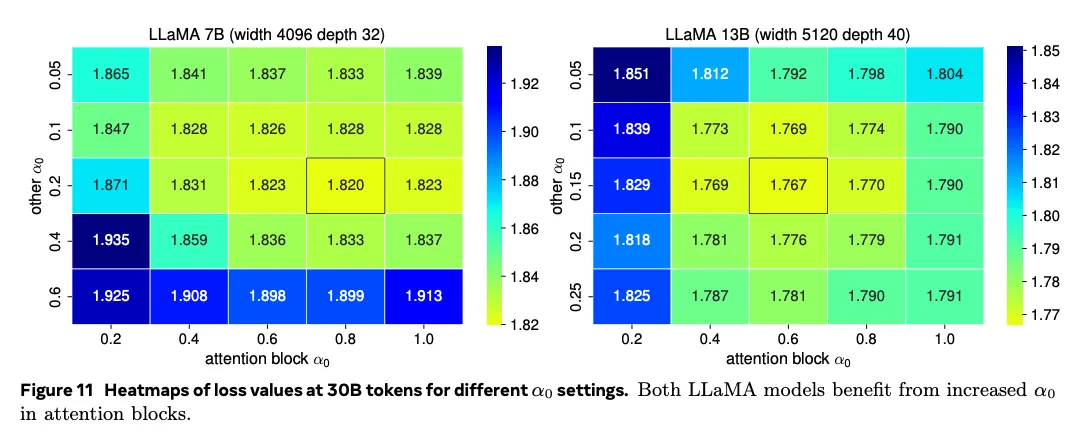
两点结论:
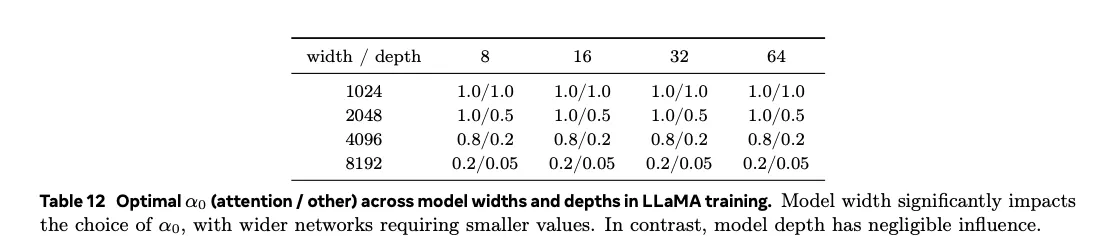
- 网络越宽, 越小;
- 注意力块需更大 ,而 FFN 块及输出前 DyT 则用更小效果更佳。
从热力图可以看到:提高Attention Block里的 明显降低训练损失。
进一步实验发现,模型宽度是决定 的主要因素,而深度影响甚微。网络越宽,需要的越小,且注意力与其他位置差距越大。
8. Related Work
归一化层机制 大量工作研究了归一化层通过不同机理提升模型性能,例如:稳定梯度流、降低初始化敏感性、抑制异常特征值、自适应学习率以及平滑损失景观等。
Transformer 中的归一化 随着 Transformer 兴起,对层归一化的研究增多;近期工作揭示 LN 强非线性可增强表示能力,并表明调整 LN 在块中的位置有助于收敛。
去归一化训练 已有研究尝试通过特殊初始化、权重重参数化或训练技巧在不使用归一化层的情况下稳定训练深网,如 Fixup、SkipInit、σReparam、Adaptive Grad Clipping 等。与这些方法相比,DyT 无需额外训练技巧,仅替换一行代码即可获得可比或更优性能 。
9. Limitations
我们在网络上进行实验,使用 LN 或 RMSNorm,因为它们在 Transformers 和其他现代架构中很受欢迎。初步实验表明,DyT 在经典网络如 ResNets 中直接替代 BN 存在困难。尚需更深入地研究 DyT 是否以及如何适应具有其他类型归一化层的模型。
10. Conclusion
本文表明,现代神经网络(尤其是 Transformer)不必依赖传统归一化层也能稳定、高效训练。我们提出的 Dynamic Tanh(DyT)仅用一个可学习标量 与 tanh 函数,即可复刻归一化层的两大核心作用:
- 通过 学习全局尺度;
- 通过 tanh 非线性压缩极端激活。
在广泛任务和模型规模上,DyT 均匹配或超越含归一化层的基线,并带来可观的计算加速。我们的发现挑战了“归一化层不可或缺”的传统观念,并为理解这一基础组件的机理提供了新视角。
做Element-Wise操作代替LayerNorm对SNN来说还是一个比较重要的性质的,因为ElementWise的操作可以异步的做,不需要全局同步。但是文章基本没怎么提到这个特点,因为传统ANN还是不太关心这种粒度的异步问题。另外文章里面提到替换BN的效果不好:

我们推测,ConvNet 深层中频繁插入的 BN 更精细地控制了各层特征分布,而 DyT 仅依靠一个全局缩放标量 α 与 tanh 压缩,尚不足以替代 BN 在每一层执行的细粒度标准化功能。未来的改进方向可以包括:
- 降低 BN 使用频率 :在 ConvNet 中减少 BN 层,或改用如 GroupNorm 的替代方案后再尝试 DyT;
- 增强 DyT 表达能力 :为 DyT 引入按通道或按层的多尺度参数,而不仅仅是单一标量 α;
- 结合训练技巧 :探索权重归一化、自适应梯度裁剪等手段,帮助 DyT-ConvNet 获得更稳定的梯度流与更好的收敛性能。
要彻底理解 DyT 与 BN 在梯度传播、特征分布动态以及收敛速度上的差异,还需要更系统、更细致的后续研究。