摘要: 存内计算(Compute-in-memory,CiM)已成为缓解冯·诺依曼机器中高数据传输成本的一种引人注目的解决方案。CiM可以在内存中执行大规模并行的通用矩阵乘法(GEMM)运算,这是机器学习推断中占主导地位的计算任务。然而,将内存重新用于计算会带来关键问题:1)使用何种类型的CiM:鉴于存在多种模拟和数字CiM,需要从系统角度确定它们的适用性。2)何时使用CiM:机器学习推断包含具有各种内存和计算需求的工作负载,很难确定何时使用CiM比标准处理核心更有益。3)在哪里集成CiM:每个内存级别具有不同的带宽和容量,这影响了CiM集成所带来的数据传输和局部性优势。在本文中,我们探讨了关于ML推断加速中对于CiM集成这些问题的答案。我们使用Timeloop-Accelergy对 CiM 原型进行早期系统级评估,并包括模拟和数字原语。我们将 CiM 集成到 Nvidia A100 类基线架构中不同层次缓存记忆体,并针对各种 ML 工作负载进行数据流优化。我们的实验结果显示,CiM 架构提高了能源效率,在 INT-8 精度下达到了比已建立基线低 0.12 倍的能耗,并通过权重交织和复制获得了多达 4 倍的性能增益。所提出的工作为使用何种类型的 CiM、以及何时和何处最佳地将其集成到缓存层次结构中以加速 GEMM 提供了见解。
1. Intro
目前的传统计算架构(CPU,GPU)都有“内存墙”的问题。存内计算可以解决内存墙的问题,但是目前现代的计算设备上有多级存储设备,存内计算的方法也有很多,本文关于存内计算的What,When,Where的问题。
- What:什么样的存内计算,digital or analog?
- When:在什么样的workload下存内计算,这里探讨的主要是GEMM的形状
- Where:在哪一级cache or memory下存内计算?
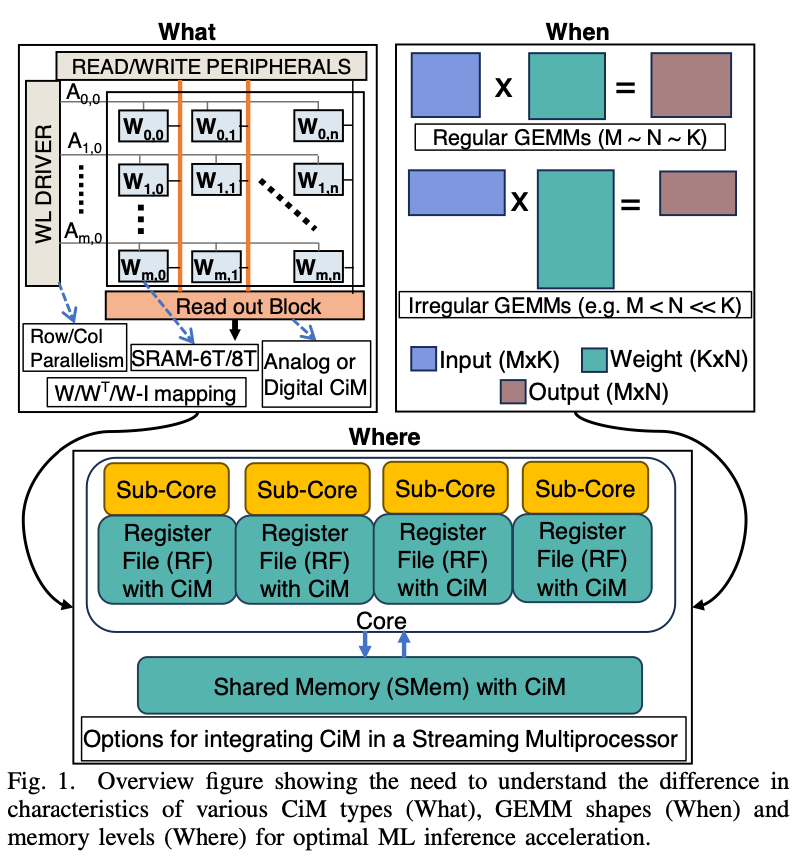
The main contributions of the work can be summarized as follows:
- An analytical evaluation of SRAM-based analog and digital CiM primitives at RF and SMem levels in an Nvidia-A100 like baseline architecture.
- Optimizing the performance and energy efficiency gains from CiM by finding optimal dataflow for a given CiM architecture and GEMM shape.
- Detailed answers to the questions on what, when and where to CiM for various GEMM shapes from energy/performance perspective.
2. Related Works
Duality Cache & MLIMP关注了where问题然后提出了一个task scheduler,但是在CPU上做的;Livia研究最小化data movement,关注irregular data access applications,目前的ML方向GEMM+其他算子总体来讲都比较有规律;To-Pim-or-Not提出一个将任务分配在PIM和常规计算之间的党员,但是只关注了DDRM系统。
3. Background
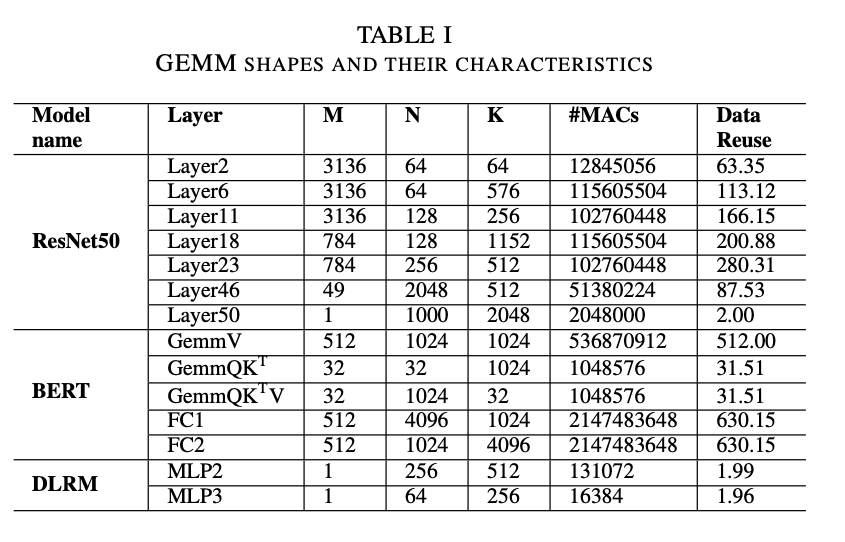
3.1. Importance of GEMMs in ML Workloads
conv = im2col + GEMMs, transformer = GEMMs + attentions, …
3.2. SRAM based Compute-in-Memory Primitives
种类很多,SRAM本身的结构(6T,8T,10T,。。。)到存内计算实现的位置(crossbar or 外部加一片buffer做计算类似polymorpic)有很多种,各有各的特点。
It iIt is also worth mentioning that different CiM macros might impose certain dataflows at the macro level due to their unique compute nature.
3.3. Dataflow Optimization in Cache Hierarchy
假设每个数都只从main memory中存取一次,计算的次数是。根据dataflow的不同,实际上的observed data reuse有可能达不到这么高。
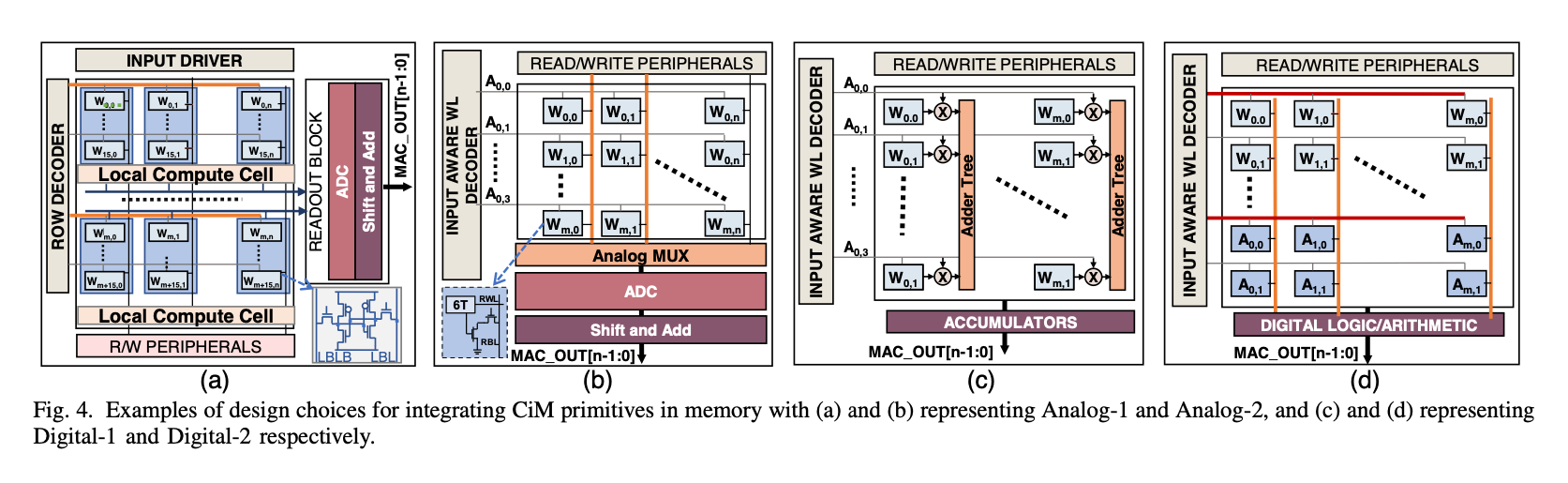
4. CiM Architecture Construction
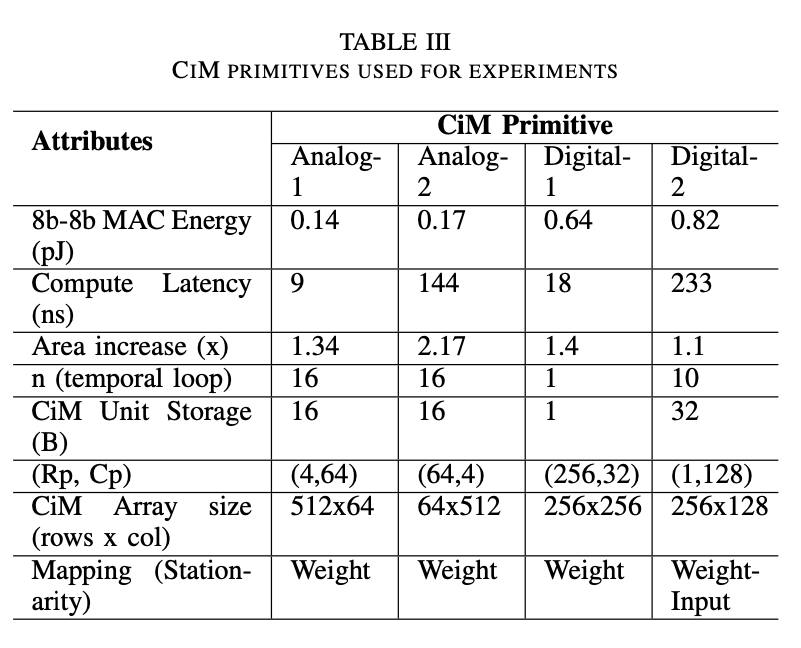
实验在Timeloop-Accelergy Framework上完成。在下面四种不同的存内计算结构做了实验,前面两种是模拟的,后面两种是数字的。假设都跑1GHz。
(a): consists of 4 banks, each with 4 blocks of 128x64 SRAM6T cells. It employs a transpose mapping technique, feeding inputs to multiple columns. This configuration results in 256 (4x64) CiM units, each with 128b (16x8b) storage. Each unit can perform an 8b-8b MAC operation in 9 cycles, processing 2b inputs and activating 8 rows of weight bits simultaneously. However, due to the limited number of ADCs shared per bank, the temporal loop factor for this primitive is set at 16.
(b): features a re-configurable ADC design with 8 arrays, each array (64x64) storing a different bit of weight and having 4 ADC outputs per compute cycle. This design results in 256 (64×4) CiM units, each capable of performing 8b-8b MAC in 144 cycles, including bit-serial latency and scaling adjustments from 65nm to 32nm. Each CiM unit contains 8×(64÷4) weight bits which are computed in sequence due to ADC limitation. This primitive has lower energy per compute but suffers from higher area overhead due to the re-configurable nature. (c): employs a fully digital design, feeding inputs into each row and executing a MAC operation at every column using an adder tree. Here, each CiM unit computes 1 8b-8b MAC by combining weight bits stored in 8 columns. The adder tree reduction incurs an area overhead and results in a compute latency of 18 cycles.
(d): a design where both inputs and weights are mapped to the same column. This configuration allows each CiM unit, comprising a single column, to perform approximately 10 8b-8b MAC operations. However, each operation requires 233 cycles, at- tributed to multiple additions involved in the process. Despite a small area overhead, the compute parallelism is limited here due to the allocation of some array bits in a column for output reduction.
其他具体数据:
5. Evaluation
5.1. Experiment Setup
硬件见4;
GEMM workloads,全都在INT8下:
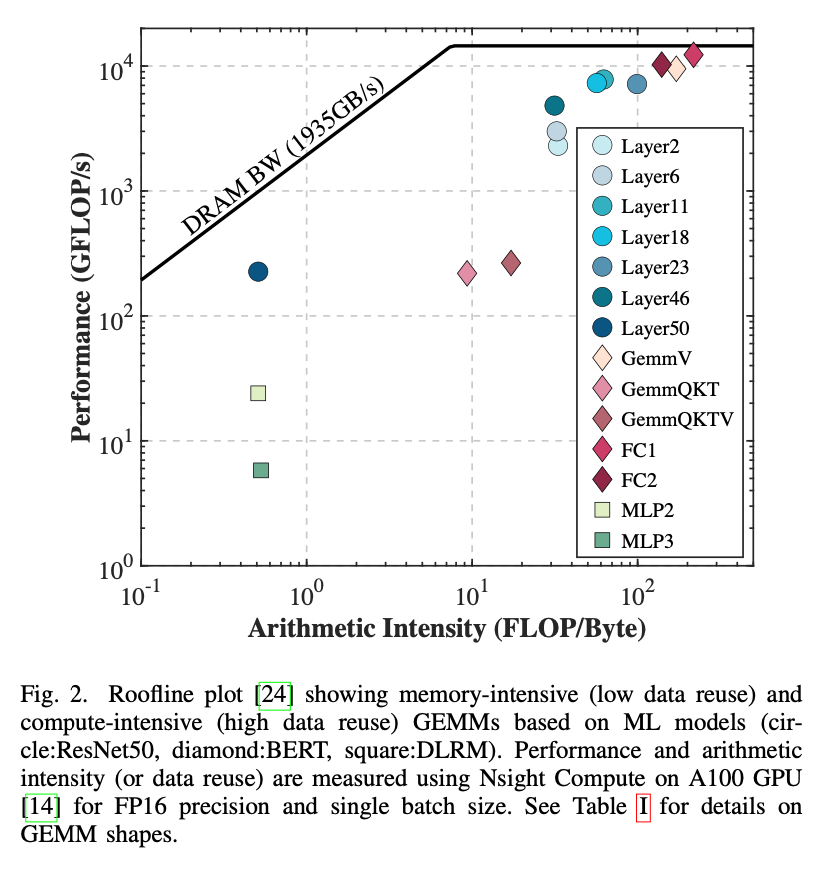
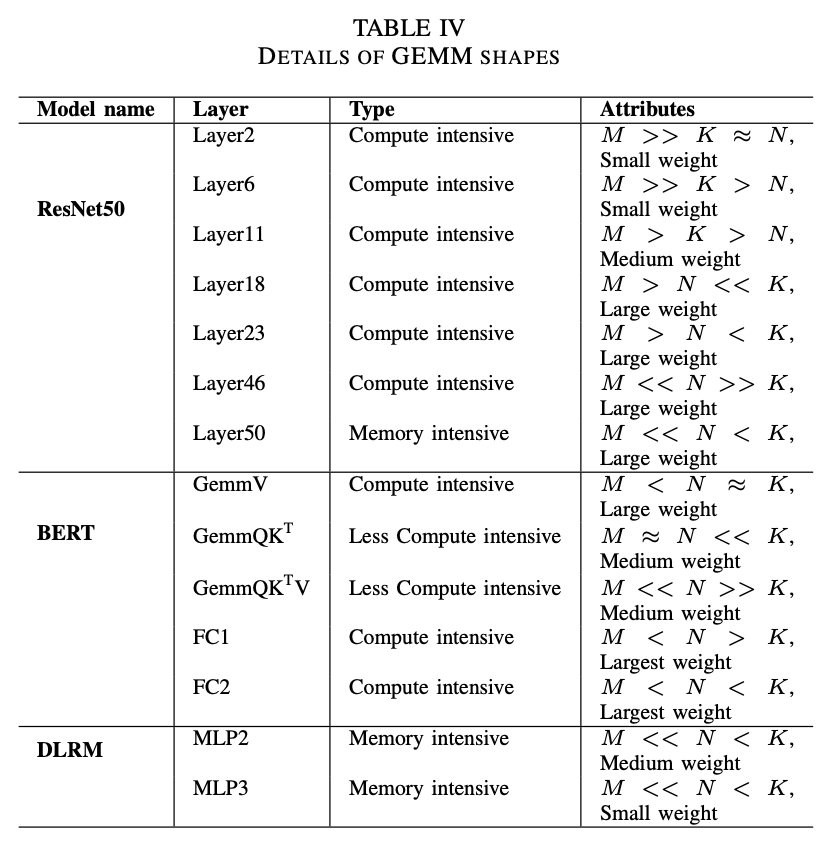
对比baseline是A100的一个SM,所以把HBM的带宽也砍到10%。
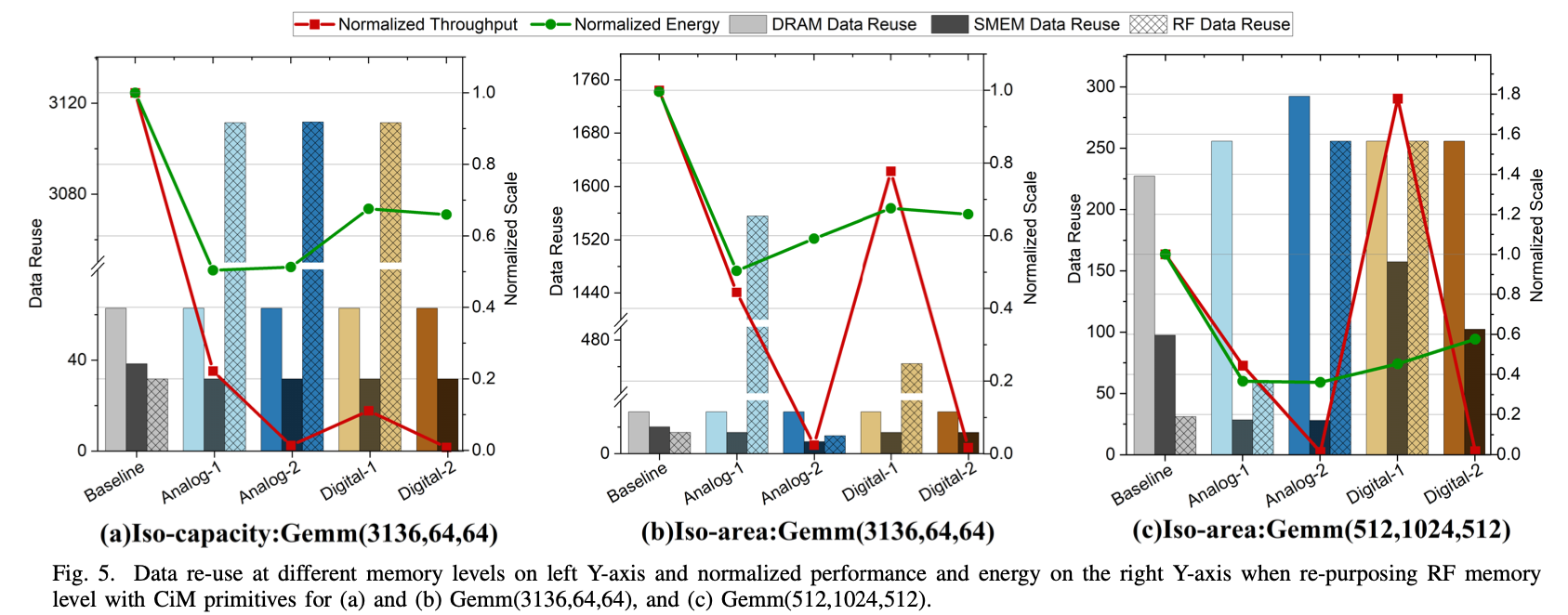
5.2. Impact of Dataflow
一些结论:
…, with iso-capacity constraints, it is not possible to achieve the baseline throughput due to limited parallelism. the number of duplications are limited by the number of CiM units and the memory capacity of the upper memory level which broadcasts the inputs to CiM units.
5.3. Results on Performance
What:
This implies that the ability to exploit full row and column parallelism is more important, in CiM design, for throughput than achieving lowest possible latency.
When:
…the maximum performance from CiM primitives does not go beyond baseline for memory-bound layers because limited data reuse.
Where:
the maximum observed throughput at RF level is significantly greater than that observed at SMem level.
5.4. Results on energy consumption
What:
No clear winner among Cim primitives. Primitive with the highest TOPS/W may not necessarily be the most energy-efficient when main memory is taken into perspective.
When:
the energy benefits from CiM primitives are maximized when there are high number of partial sum reductions.
Where:
one CiM primitive maybe more suitable for given memory level depending on the primitive design and GEMM shape.
5.5 Discussion and Future Work
-
performance benefits are decided by the compute latency and compute parallelism
-
energy benefits depend on memory accesses and compute cost

6. Conclusion
我们在GPU架构的片上缓存内存中集成了存算一体化(CiM)技术。我们的实验提供了关于CiM加速通用矩阵乘法(GEMM)工作负载的全面分析,这些工作负载基于机器学习(ML)推理任务,在这样的系统上进行。具体来说,基于等面积的分析评估得出以下结论:
关于性能方面,数字型CiM基元在大多数GEMM形状上比基线实现更高的性能(GFLOPs),这得益于全行/列并行处理和低面积开销。相比之下,尽管模拟基元没有达到数字型CiM的高性能水平,但它们在能效方面表现出色,仅消耗基线能源的0.12倍。数字基元紧随其后,最佳能源节省为基线的0.22倍。CiM在能效和性能上的这种权衡可能对GPU有利,尤其是在它们以降低频率运行以管理功耗的情况下。
关于何时的调查表明,计算密集型层,具有高数据重用率和较大的K(> M)值的层,从CiM在性能和能效方面受益最大。例如,BERT模型中的全连接(FC1,FC2)层。相反,计算密集型的GEMM,在数据重用率低和较小的K(<< M)时,通常会与基线相比实现更高的吞吐量,但使用CiM时能源方面有优势。我们分析中的ResNet50的初始层,如Layer2和Layer11就是这样的例子。同样,偏斜的GEMM在K >> N的情况下表现出能量减少和可比的吞吐量,但当K << N时,性能下降。内存受限的GEMM,如ResNet50和DLRM中的全连接层,仅在CiM下显示出能源优势,而没有吞吐量提升。
此外,有关位置的发现表明,在集成CiM时,内存容量的重要性超过了内存层次结构中的级别编号。较高的内存容量可能导致由于权重复制而性能提升。通过减少内存访问次数,更高的内存容量也略微带来更多的能源效益。然而,CiM的特性,如映射约束和计算延迟,仍可能限制高内存容量带来的性能和能源效益。
总之,这项工作对存算一体化原始设备在片上内存层次结构中的能源、面积和性能之间的权衡进行了全面评估。我们认为,我们的工作在理解基于SRAM的CiM缓解能源问题同时实现可比性能的潜力方面提供了关键见解。反过来,我们的方法有助于优化基于CiM的架构,以用于机器学习推理。